Step FunctionsでGlueのジョブフローを作る
"Glueの使い方的な③(CLIでジョブ作成)"(以後③と書きます)で書いたように、現在Glueのジョブスケジュール機能は簡易的なものなので、複雑なジョブフロー形成には別のスケジューラーが必要になる場合もあります。
例えばGlueのクローラーとGlueジョブもそれぞれにスケジュール機能があり統合したジョブフローを作ることがGlueだけでは出来ません(例えばクローラーを実行し終わったらジョブを実行するとか)。今回はサーバーレスなジョブフローのサービスであるStep Functionsを使って、クローラーを実行し正常終了したら後続のジョブを実行するというフローを作ってみます。
全体の流れ
- Glue処理内容
- StepFunctionsの処理内容
- 前準備
- Step FunctionsでStateMachine作成
- 実行
Glue処理内容
"Glueの使い方的な①(GUIでジョブ実行)"(以後①と書きます)で実行したものと同じクローラーとジョブを使います。入力データも出力結果も①と同じです。
今回行うのはGlueクローラー処理が終わったら次のGlueジョブ処理開始というジョブフロー形成です。
あらためて①のクローラーとジョブの処理内容は以下の通りです
クローラーの内容
入力のCSVファイルからスキーマを作成します
ジョブの内容
"S3の指定した場所に配置したcsvデータを指定した場所にparquetとして出力する"
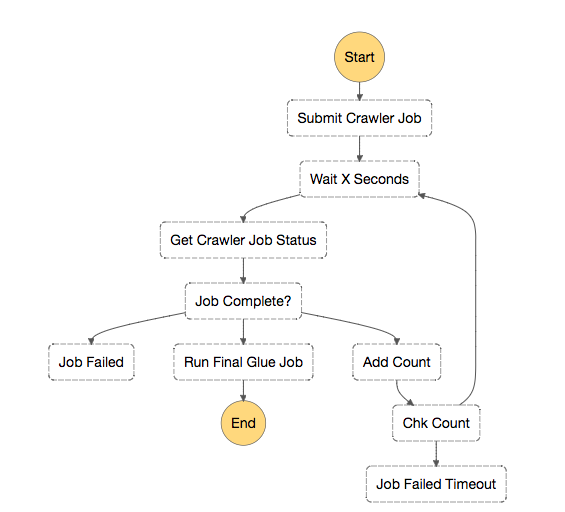
Step Functionsを使ったジョブフローの内容
図の四角をStep Functionsでは"State"と呼びます。処理の1単位と思ってください。
ジョブフローは以下のような形です。
Stateごとに流れを説明します
- "Submit Crawler Job"でLambdaを使いGlueクローラーを実行
- "Wait X Seconds"で指定時間待つ
- "Get Crawler Job Status"でLambdaを使いGlueクローラーの状態をポーリングして確認
- "Job Complete?"で状態を判定して結果によって3つに処理が分岐
- 失敗なら"Job Failed"エラー処理
- 終了なら"Run Final Glue Job"でLambdaを使い後続のGlueジョブを実行
- 処理中なら"Add Count"でLambdaを使いカウンタをインクリメント。
- "Add Count"の後"Chk Count"でカウンタをチェックし3回以上になっていたら"Job Failed Timeout"でタイムアウト処理、3未満なら"Wait X Seconds"に戻りループ処理
前準備
①と同じです
今回使うサンプルログファイル(19件)
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,1,JP,2017,12,14,12
android,11112,1,FR,2017,12,14,14
iphone,11113,9,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
入力ファイルをS3に配置
$ aws s3 ls s3://test-glue00/se2/in0/
2018-01-02 15:13:27 0
2018-01-02 15:13:44 691 cvlog.csv
ディレクトリ構成
in0に入力ファイル、out0に出力ファイル
$ aws s3 ls s3://test-glue00/se2/
PRE in0/
PRE out0/
PRE script/
PRE tmp/
ジョブのPySparkスクリプト
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
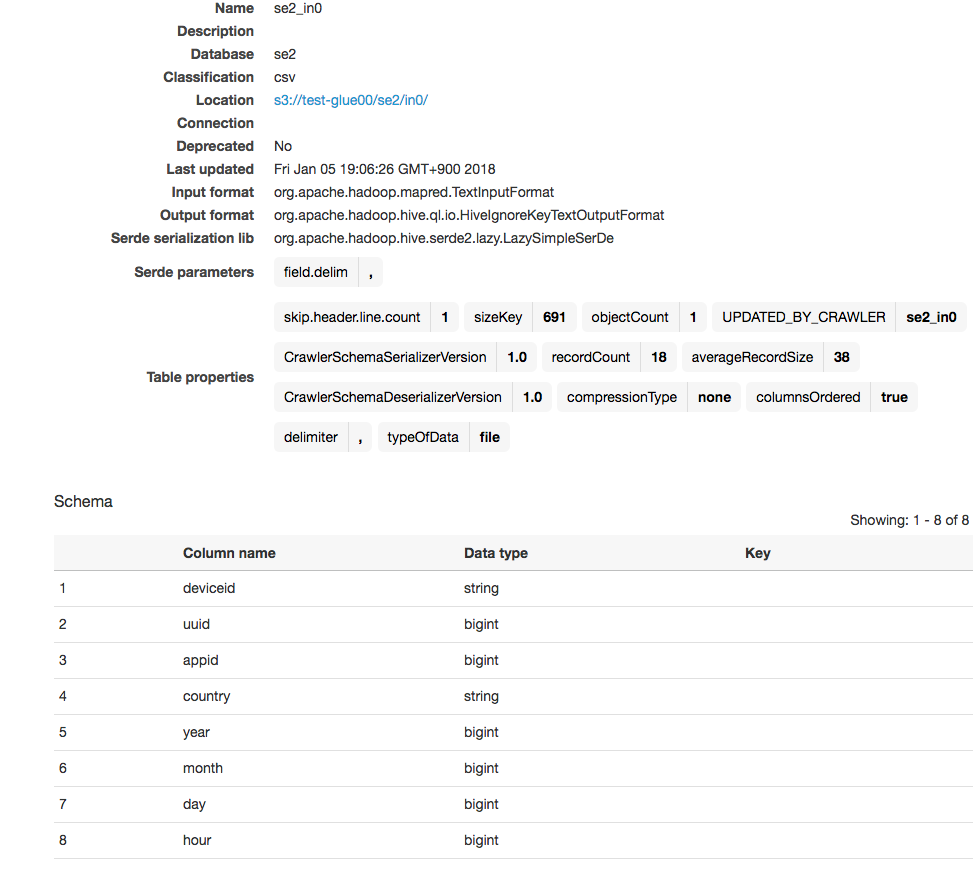
入力のCSVデータのスキーマ
クローラーによって作成されるスキーマ
StepFunctionsでStateMachine作成
StepFunctionsは一連のジョブフローをJSONで定義しこれを"StateMachine"と呼びます。
StateMachine内の処理の1つ1つの四角をStateと呼びます。処理の1単位です。
このJSONの記述はASL(AmazonStatesLanguages)と呼ばれStateTypeとしてChoice(分岐処理)やWait(待ち)やParallel(並列実行)などがJSONだけで表現出来ます。またTaskというStateTypeからはLambdaやアクティビティ(EC2からStepFunctionsをポーリングする)を定義できます。前述の通り今回はLmabdaを使います。
マネージメントコンソールからいくつかあるテンプレートを元に作ることも出来ますが、カスタムでJSONを一から作ることもできます。
新規StateMachine作成画面
"Author from scrach"で一からJSON作成

"Template"を選ぶとASLのStateパターンのいくつかのテンプレが選べます

左側の"コード"部分にJSONを書き、右側の"ビジュアルワークフロー"の部分にJSONコードで書いたフローがビジュアライズされます

StateMachine
今回のStateMachieのJSONは以下です。
内容は前述の通りです。
※[AWSID]のところは自身のAWSIDと置き換えてください
{
"Comment": "A state machine that submits a Job to Glue Batch and monitors the Job until it completes.",
"StartAt": "Submit Crawler Job",
"States": {
"Submit Crawler Job": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:[AWSID]:function:glue-test1-cr1",
"ResultPath": "$.chkcount",
"Next": "Wait X Seconds",
"Retry": [
{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 120,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
]
},
"Wait X Seconds": {
"Type": "Wait",
"SecondsPath": "$.wait_time",
"Next": "Get Crawler Job Status"
},
"Get Crawler Job Status": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:[AWSID]:function:glue-test1-crcheck",
"Next": "Job Complete?",
"InputPath": "$",
"ResultPath": "$.response",
"Retry": [
{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
]
},
"Job Complete?": {
"Type": "Choice",
"Choices": [{
"Variable": "$.response",
"StringEquals": "FAILED",
"Next": "Job Failed"
},
{
"Variable": "$.response",
"StringEquals": "READY",
"Next": "Run Final Glue Job"
}
],
"Default": "Add Count"
},
"Add Count": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:[AWSID]:function:glue-test1-addcount",
"Next": "Chk Count",
"InputPath": "$",
"ResultPath": "$.chkcount",
"Retry": [
{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
]
},
"Chk Count": {
"Type": "Choice",
"Choices": [{
"Variable": "$.chkcount",
"NumericGreaterThan": 3,
"Next": "Job Failed Timeout"
}],
"Default": "Wait X Seconds"
},
"Job Failed": {
"Type": "Fail",
"Cause": "Glue Crawler Job Failed",
"Error": "DescribeJob returned FAILED"
},
"Job Failed Timeout": {
"Type": "Fail",
"Cause": "Glue Crawler Job Failed",
"Error": "DescribeJob returned FAILED Because of Timeout"
},
"Run Final Glue Job": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:[AWSID]:function:glue-test1-job1",
"End": true,
"Retry": [
{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
]
}
}
}
Lambda
今回使うLambdaは4つです。流れも振り返りながら見ていきます
書き方はいろいろあるし今回はエラーハンドリングも甘いのであくまでも動きのイメージをつかむための参考程度にしてください。最後のGlueジョブの実行についてはジョブの終了判定とかはしてないです。
"Submit Crawler Job"
GlueのAPIを使ってクローラーのStartを行う
# coding: UTF-8
import sys
import boto3
glue = boto3.client('glue')
def lambda_handler(event, context):
client = boto3.client('glue')
response = client.start_crawler(Name='se2_in0')
return 1
"Wait X Seconds"
Waitで指定秒数待つ
"Get Crawler Job Status"
GlueのAPIを使ってクローラーのステータスを取得します
# coding: UTF-8
import sys
import boto3
import json
glue = boto3.client('glue')
def lambda_handler(event, context):
client = boto3.client('glue')
response = client.get_crawler(Name='se2_in0')
response = response['Crawler']['State']
return response
"Job Complete?"
Choiceで取得したステータスが、"READY"なら正常終了、"FAILED"なら失敗、それ以外は実行中の分岐処理
"Job Failed"
ステータスが失敗なら
FailでStepFunctionsをエラーさせます
"Run Final Glue Job"
ステータスが正常終了なら
GlueのAPIを使ってジョブをStartします
# coding: UTF-8
import sys
import boto3
import json
glue = boto3.client('glue')
def lambda_handler(event, context):
client = boto3.client('glue')
response = client.start_job_run(
JobName='se2_job0')
return response['JobRunId']
"Add Count"
クローラーがまだ実行中なら
カウンタにインクリメントします
# coding: UTF-8
import sys
import boto3
import json
glue = boto3.client('glue')
def lambda_handler(event, context):
chkcount = event["chkcount"]
chkcount = chkcount + 1
return chkcount
"Chk Count"
choiceでカウンタが3未満か3以上かをチェックします
"Job Failed Timeout"
Failでカウンタが3以上だった時のエラー処理
"Wait X Seconds"
3未満の場合はここに戻りループ処理
実行
Step Functionsを実行
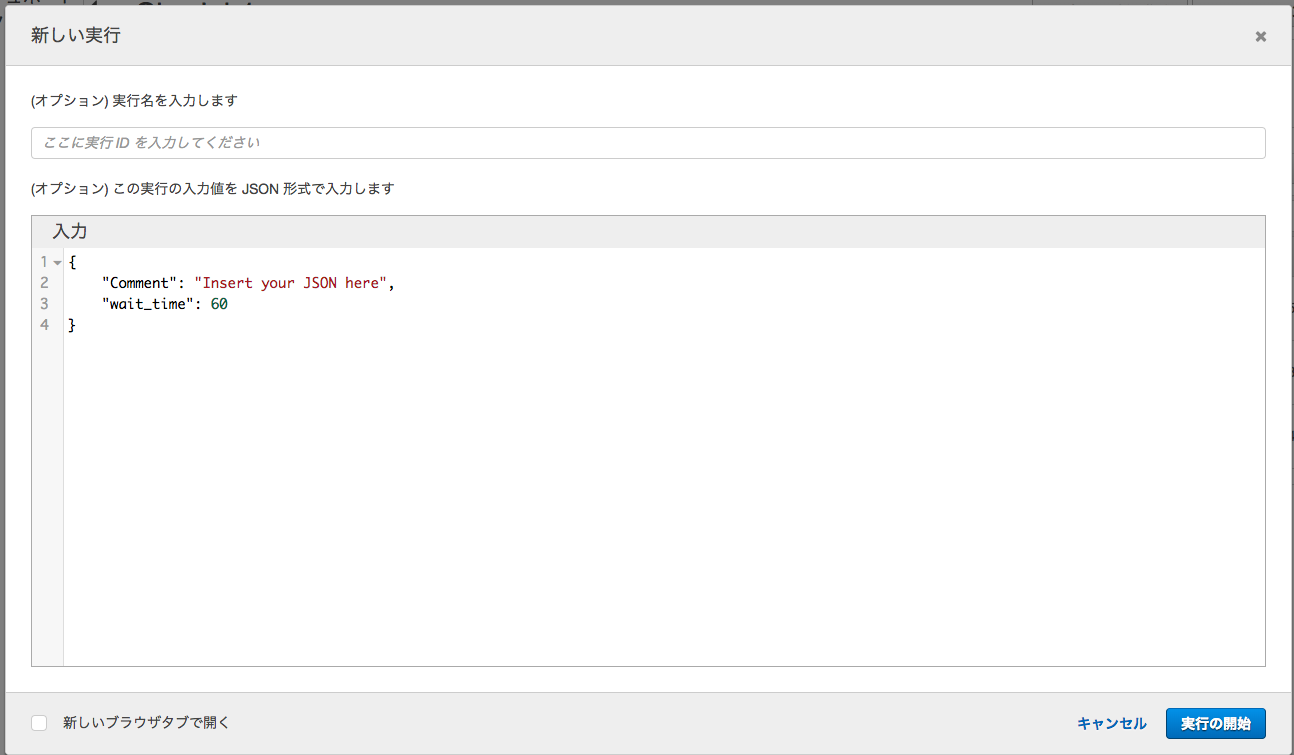
作成したStateMachineを選び"新しい実行"をクリック

JSONに引数を入れて"実行の開始"をクリック
今回はJSON内で使う変数で"wait_time"を60秒で待ちの時間として入力しています
実行状況

CloudWatchイベントでスケジュール
あとは上記で作成したStateMachineをCloudWatchイベントでCRON指定すれば定期的実行されるジョブフローの完成です。This is Serverless!

その他
今回はクローラー実行後にジョブ実行というシンプルなフローでしたが、Step Functionsは並列度を替えたり引数の受け渡しをしたり、さらにLambdaでロジックを書くことができるので自由度高く複雑なフローの作成が行えます。Glueとの相性はいいのではないでしょうか?
JSON部分も30分もあれば学習完了というカジュアルさがありLambdaを使ってAPI操作で様々なAWSの処理を繋げるのにはとてもいい印象です。
かなりシンプルな処理だったのですがコードがやや多い印象で、より複雑な処理になると結構大きいJSONになりそうで、JSONなのでコメント書けないとか少し大変な部分が出て来るのかもしれません。
バージョン管理を考えるとCliでの処理で運用したほうが良さそうですが、こういったサービスはGUIでの良さもあるのでどちらに比重を置いた運用がいいかは考慮が必要かもです
本文中で使ったカウンタのステート情報はDynamoDBなどに入れた方が良いかもです。
マイクロサービス化しやすいので、極力本来の処理のロジックをLambda側にやらせてそれ以外のフロー処理(分岐とかカウンタインクリメントとか)をJSONで書くのがいいと思います。今回カウンタはLambdaでやってしまいましたが。
ログはCloudWatchLogsに出ます
To Be Continue
TODO
参考
StepFunctions BlackBelt資料
https://www.slideshare.net/AmazonWebServicesJapan/20170726-black-beltstepfunctions-78267693
StepFunctionsの基本的な使い方
https://dev.classmethod.jp/cloud/aws/first-aws-step-functions/
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f
StepFuncionsの入力引数(inputpath,parameters)
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/input-output-inputpath-params.html
StepFunctionsのResultpath
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/input-output-resultpath.html