GUIによる操作でGlueジョブを作って実行する
ジョブの内容
"S3の指定した場所に配置したcsvデータを指定した場所にparquetとして出力する"
ジョブ名
se2_job0
クローラー名
se2_in0
se2_out0
全体の流れ
- 前準備
- クローラー作成と実行、Athenaで確認
- ジョブの作成と実行、Athenaで確認
- 出来上がったPySparkスクリプト確認
前準備
ジョブで使うIAM role
以下のポリシーを付与した任意の名前のロールを作っておく。今回はtest-glueという名前にした。
・AmazonS3FullAccess
・AWSGlueServiceRole
Glueとの信頼関係も設定しておく
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
※権限は必要に応じてより厳しくしてください。今回は検証のため緩めにしてあります。
今回使うサンプルログファイル(19件)
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
S3に配置
$ aws s3 ls s3://test-glue00/se2/in0/
2018-01-02 15:13:27 0
2018-01-02 15:13:44 691 cvlog.csv
ディレクトリ構成
in0に入力ファイル、out0に出力ファイル
$ aws s3 ls s3://test-glue00/se2/
PRE in0/
PRE out0/
PRE script/
PRE tmp/
クローラー作成と実行、Athenaで確認
ジョブ作成の前に、こちらもGlueの重要な機能の1つであるData CatalogのCrawlerを作成して動かしていきます。
クローラはデータをスキャン、分類、スキーマ情報を自動認識し、そのメタデータをデータカタログに保存する機能です。これを使って入力となるサンプルデータのスキーマを事前に抽出してデータカタログにメタデータとして保存します。Athena、EMR、RedshiftからもこのGlueのデータカタログを使えます。Hive互換のメタストアです(Hiveメタストアのマネージドサービスと思ってもらえればいいと思います)。
基本的な操作はGUIを使って行えます。
AWSマネージメントコンソールから、Glueをクリックし、画面左側メニューの"Crawlers"をクリックし、"Add crawler"をクリック
クローラーの名前入力
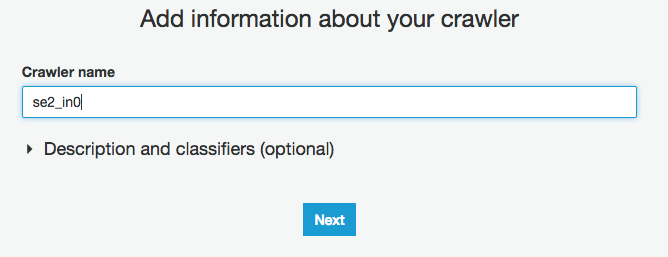
S3にあるソースデータのパス入力(今回はS3に配置してあるデータが対象)
そのまま"Next"
"Choose an existing IAM role"にチェックを入れ、IAM roleをプルダウンからtest-glueを選択する
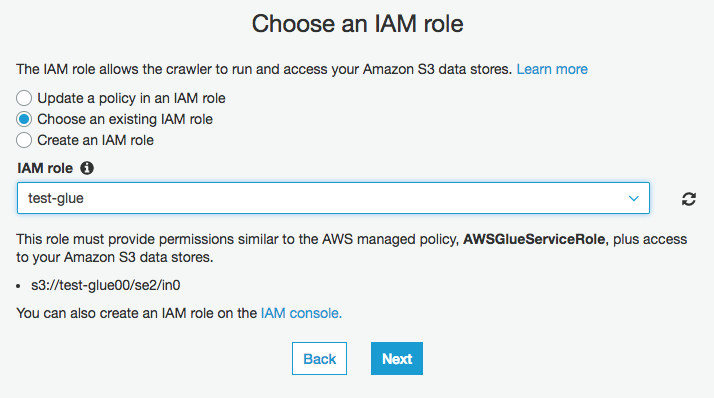
"Run on demand"にチェックを入れ"Next"(今回のクローラーはスケジュールせずに手動実行とする)
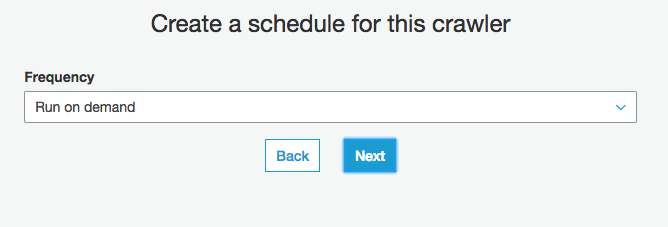
スキーマ情報を保存するDatabaseを選択、既存のものがあればそれでもいいし、なければ下の"Add database"でdatabase作成しそれを選択
Prefixは作成されるテーブル名の先頭に付くもの。見分け分類しやすいものにしておくと良いと思います(現状テーブルにtagとかつけられないので)
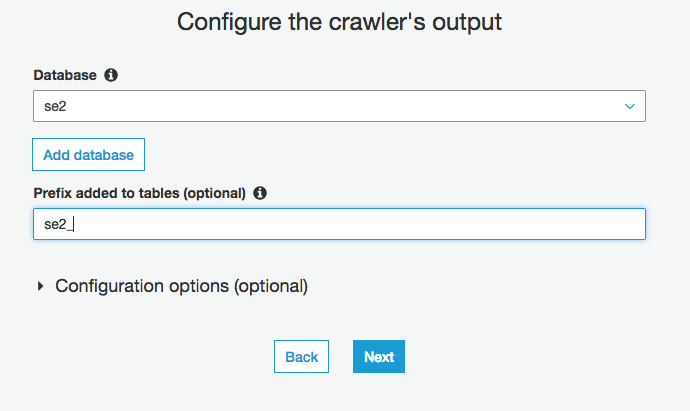
クローラー実行
対象のクローラーにチェックを入れ、"Run Crawler"をクリック
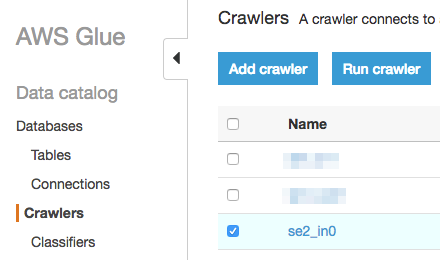
テーブルが出来上がる
"se2_"のPrefixが付いた"se2_in0"のテーブルができています。"in0"は指定した"Include Path"の一番下のディレクトリ名です。指定した"Include Path"(ソースデータがあるS3のパス、画像の"Location"の部分に表示されている)の配下のディレクトリは自動でパーティションとして認識されます。今回は配下にディレクトリはありませんのでパーティションも作成されません。
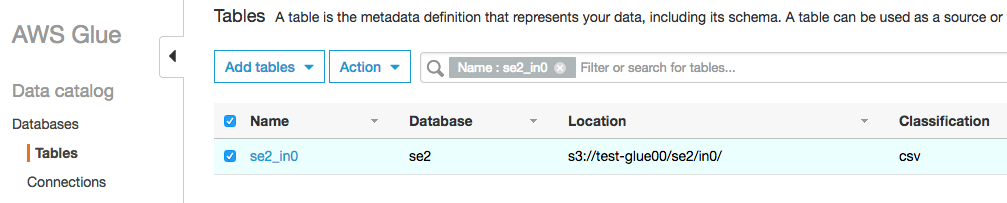
テーブルの内容を確認するとスキーマが自動で作成されています
実データ配置場所のLocationがs3://test-glue00/se2/in0
Table名のNameが、prefixのse2_とInclude Pathで指定したs3://test-glue00/se2/in0の一番下のディレクトリのin0でse2_in0
Schemaを見るとuuidやappidなどがbigintで数値型になってます、文字列型がよければここでも修正できます。
今回は一旦このまま進めます
※本来はClassifierでいい感じにしたほうがいいと思う

画面右上の、"View properties"でメタ情報をjsonで見れます。"Compare versions"でテーブルの過去のバージョンを比較して見れます。"Edit schema"でスキーマを更新できます。
テーブルはバージョン管理されていて過去のバージョンと差分を比較して見ることはできますが過去のバージョンに戻す機能は現在はありません。
【上記誤りでした。訂正します】
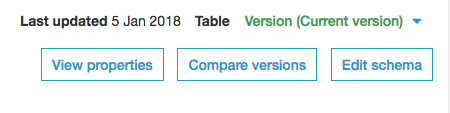
テーブルはバージョン管理されていて過去のバージョンと差分を比較して見ることはでき、過去のバージョンに戻すこともできます。戻し方は画面右上のバージョンをクリックし戻したいバージョンの番号をクリック、"Edit schema"をクリックし"Save"をクリックすると選択したバージョンに戻った状態となります。
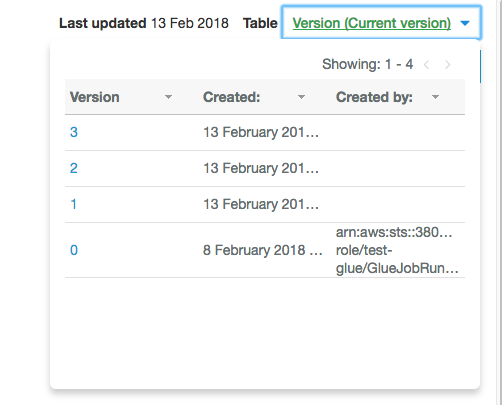
【↑誤りを修正したため時間が他の画像と異なってます】
"Veiw properties"をクリックするとテーブルのDDLを確認できます。
今回の入力データの1行目にフィールド名情報が入っていました。1行目をデータとみなさないための設定で"skip.header.line.count:1"が自動で入っていることも確認できます。

AthenaからもGlueのData Catalog使えます
Athenaから同様のテーブルとスキーマの内容が確認できます。Athenaがスキーマ情報にGlueのデータカタログを使ってることがわかります。画面右上にもGlue Data Catalogへのショートカットもありますね。
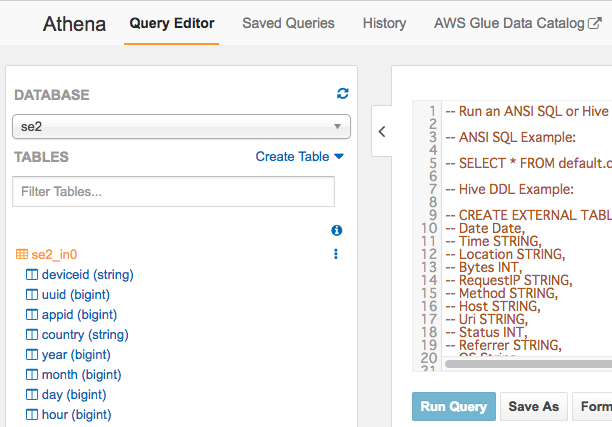
もちろんクエリ実行もできます。
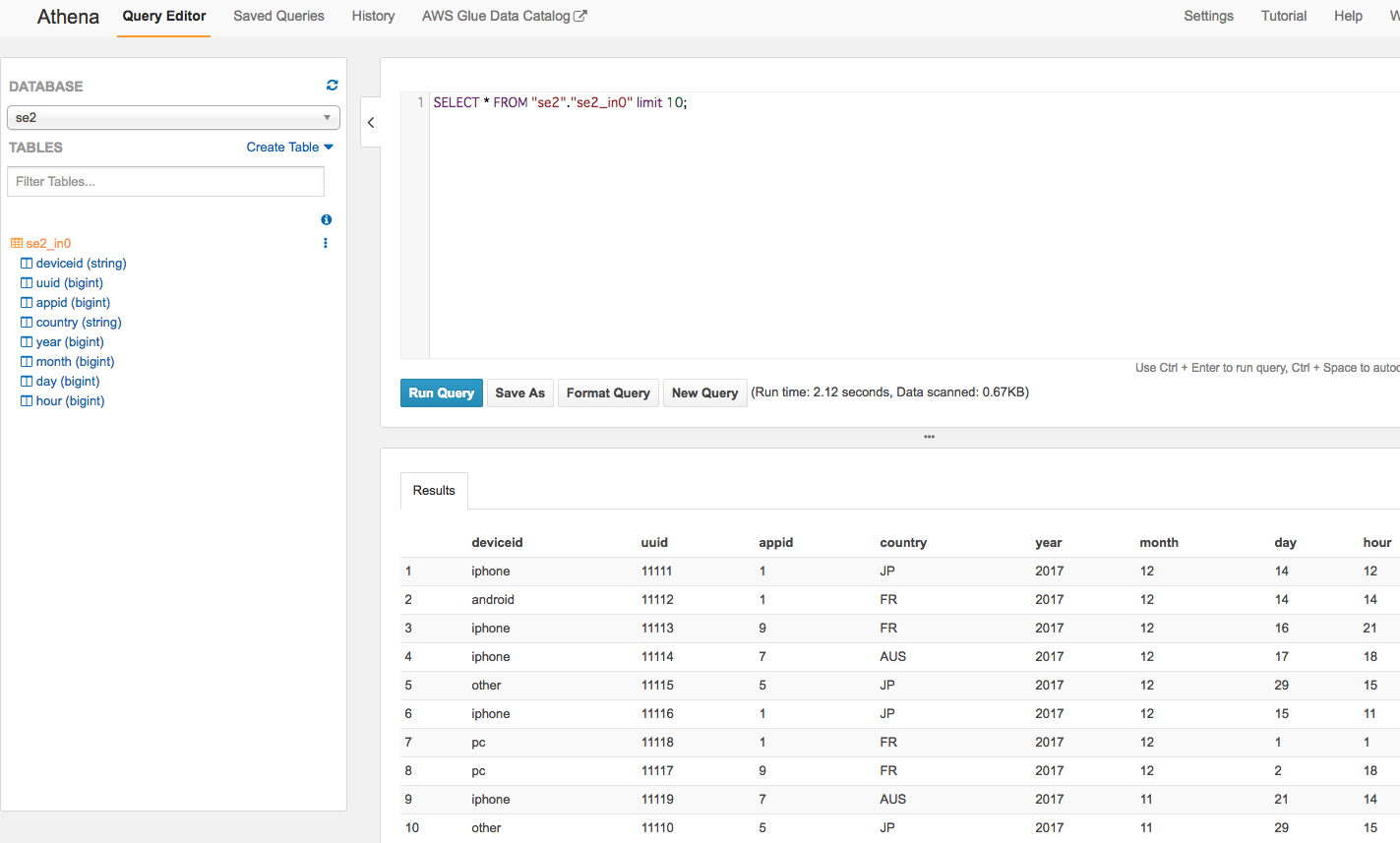
ジョブの作成と実行、Athenaで確認
今回のようなジョブであれば、基本は画面ポチポチするだけです
Glueのメニューから"ETL"の"Job"をクリックし、"Add job"をクリック
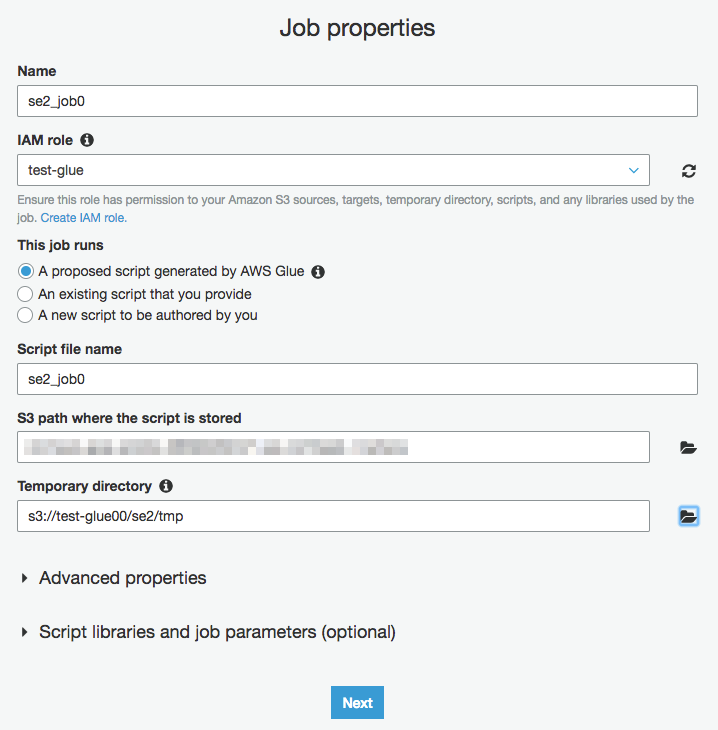
"Name"にジョブ名を入れ、"IAM role"はクローラーでも使ったロールを指定、"Temporary directory"は任意の場所で構いません。
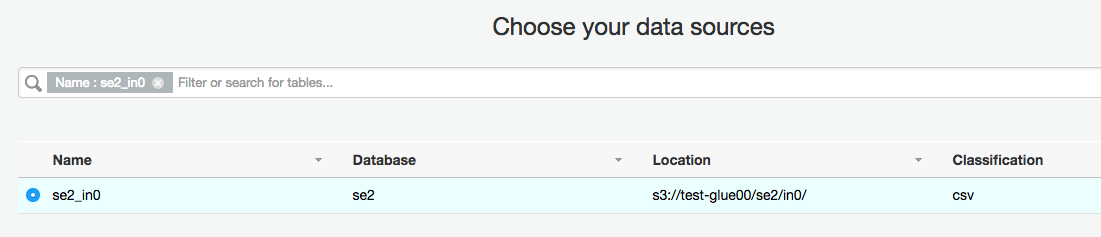
ソースデータとなるテーブルを選択。(先程作成したテーブルをクリック)
ターゲットとなるテーブルは作成していないのでここで作ります。
今回は、保存先のData storeは"S3"、出力ファイルフォーマットのFormatは"Parquet"、出力先のパスのTargetPathは"任意の場所"を指定
※圧縮も選べます
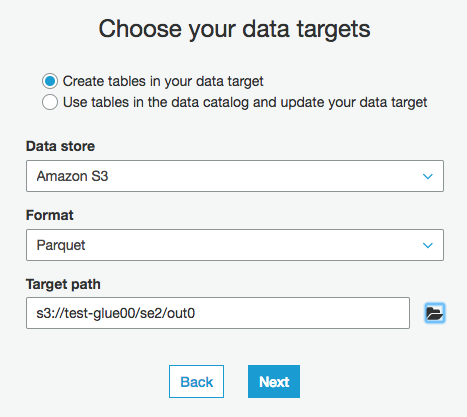
ソースデータとターゲットデータのマッピング変換ができます。いらないカラムを出力から除外したり、カラムの順序を変えたり、"Data Type"をstring,long,intなどに変えたり、新しいカラムを追加してそこに出力させる(カラム名を変える時に使えそうです)などができます

次にサマリがでますので問題なければ"Finish"をクリック
ジョブの実行
作成したジョブにチェックを入れ、"Action"から"Run job"をクリック
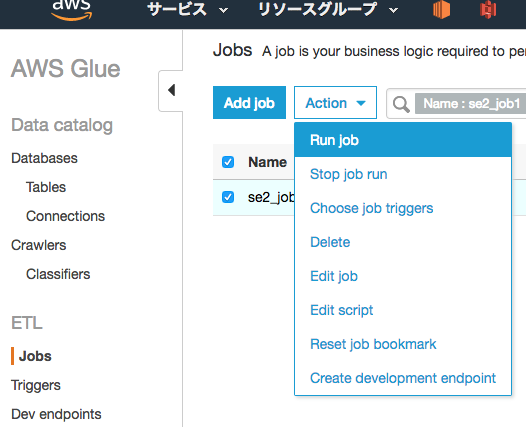
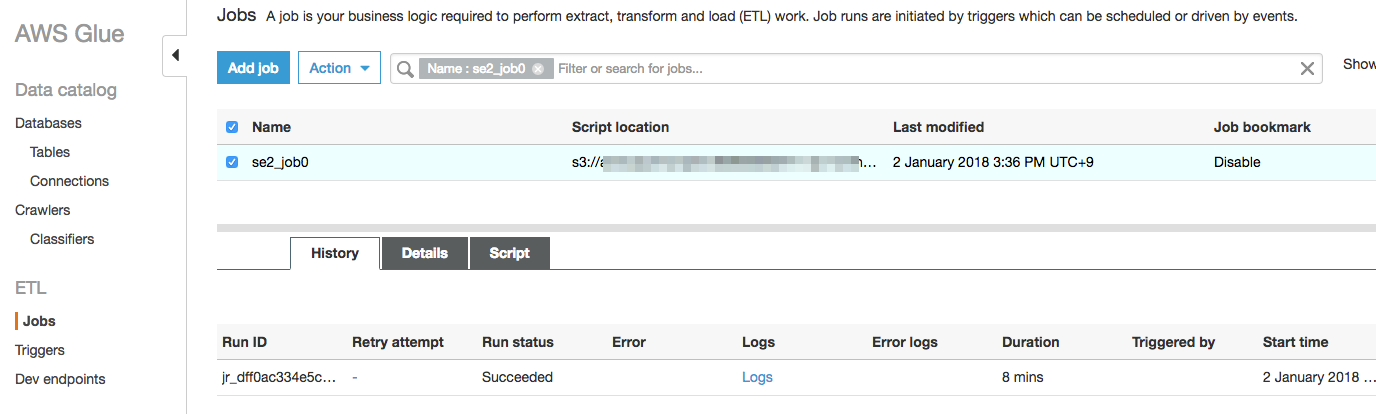
数分待って以下のように"Run status"が"Succeeded"となれば問題なく完了しています。
※問題があれば、"Error"の箇所にエラーの概要、"Logs"、"Error logs"の箇所の出力がリンクになっていてクリックするとCloudWatch logsに移動します。GlueのログはデフォルトでCloudWatch logsに出力されます
出力したParquetフォーマットのファイルを、ソースデータと同様にクローラーを使ってスキーマを作り、スキーマオンリードでAthenaクエリを実行してみます。クローラー作成手順は前回と同様なので割愛します。
クローラーにより自動作成されたスキーマ
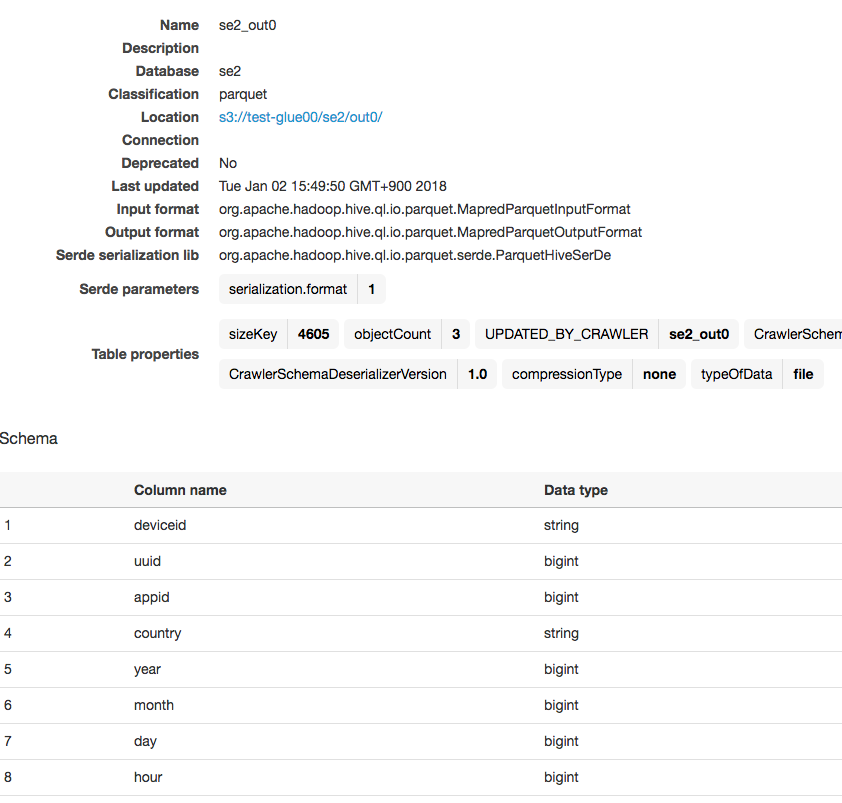
クエリ結果です。データ量が少なくselectしてるだけなのでアレですが、parquetになったので列単位での集計処理などが高速化されるデータフォーマットに変換ができました。
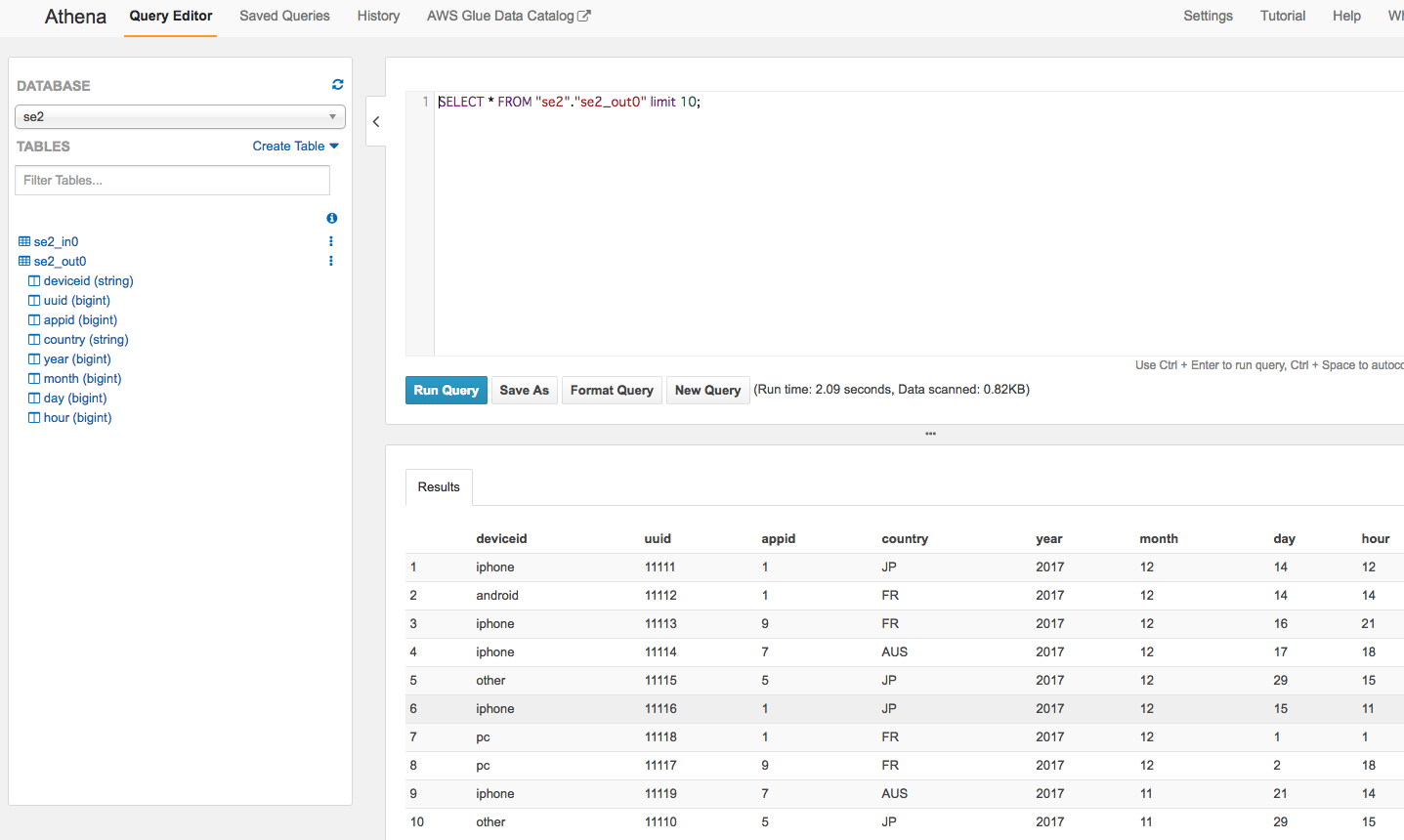
"S3の指定した場所に配置したcsvデータを指定した場所にparquetとして出力する"くらいであればGlueはGUIだけでサーバーレスでできます。
出来上がったPySparkスクリプト確認
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
ビルトイン変換のいくつか補足
-
ApplyMapping:ソースの列とデータ型をターゲットの列とデータ型にマップします
-
ResolveChoice:複数の型の値が含まれている場合の列の処理方法を指定します。列を単一のデータ型にキャストするか、1つ以上の型を破棄するか、またはすべての型を別々の列または構造体に保持するかを選択できます。choiceはspecが空の場合のデフォルトのresolution actionです
- キャストする型を指定できます(例、cast:int)。曖昧な列(たとえばstringとintがまざってる)をcastで指定した型にする。
- make_structは構造体を使用してデータを表現することにより、潜在的なあいまいさを解消します。曖昧な列(たとえばstringとintがまざってる)を、DynamicFrameにintとstringの両方を含む構造体の列が生成されます。
- make_colsはデータを平坦化することによって潜在的なあいまいさを解消します。曖昧な列(たとえばstringとintがまざってる)を、DynamicFrameにcolumnA_intおよびcolumnA_stringという名前の2つの列が生成されます。
- projectは可能性のあるデータ型の1つにすべてのデータを投影して、潜在的なあいまいさを解決します。曖昧な列(たとえばstringとintがまざってる)を、DynamicFrameに列が生成され、すべてのint値が文字列に変換されます。
-
DropNullFields:nullフィールドを削除します
To Be Continue
よくありそうな変換処理ケースを今後書いていければと思います。
ジョブを作る際に似たようなジョブを作りたい、テスト段階でジョブのパラメータを一部だけ変えたジョブを作りたいことあると思います。現在はジョブのコピーがGUIからはできないのでそのあたりの運用を考慮する場合はCLIの利用がおすすめです。またあとで書きます。
こちらも是非
似た内容ですがより丁寧にかかれています。安定のクラメソブログ
https://dev.classmethod.jp/cloud/aws/aws-glue-released/
https://dev.classmethod.jp/cloud/aws/aws-glue-tutorial/
Built-In Transforms
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/built-in-transforms.html
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-transforms-ApplyMapping.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f