Glueの話・・・というわけではないですが、TIPS的に
Zeppelinでテスト。
Glueでは開発エンドポイントを使い、Zeppelinを使うことも出来ます。
"Glueの使い方的な㉓(開発エンドポイントとノートブックの始め方_2018夏"で作成してみてください。
あとはコードで
-
test1:input_file_name()メソッド
-
test2:sparksql
-
test3:hadoop
(注)collect()は全出力なので大量ファイルなら注意してください
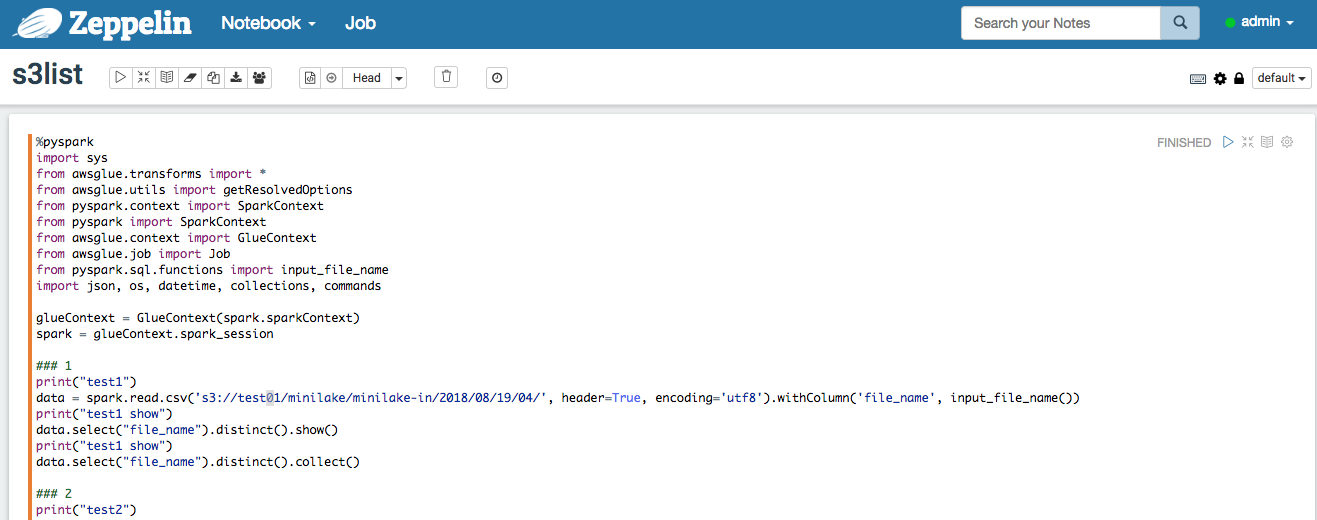
test1:input_file_name()メソッド
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import input_file_name
import json, os, datetime, collections, commands
glueContext = GlueContext(spark.sparkContext)
spark = glueContext.spark_session
### 1
print("test1")
data = spark.read.csv('s3://test01/minilake/minilake-in/2018/08/19/04/', header=True, encoding='utf8').withColumn('file_name', input_file_name())
print("test1 show")
data.select("file_name").distinct().show()
print("test1 collect")
data.select("file_name").distinct().collect()
test1出力
test1 input_file_name
test1 show
+--------------------+
| file_name|
+--------------------+
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
+--------------------+
test1 collect
[Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-32-02-8042876e-6e20-4f7d-89ec-a523211abbfc'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-36-02-478d5d9d-fd00-4a9a-bab6-f87c6b41c274'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-38-02-4ff21e9e-714e-4434-bafa-cbea9ef4ed16'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-42-02-eb40b487-4558-4497-ac9b-8f7ee7d90786'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-52-02-0c8f3918-e5c7-4749-8b49-4839a3cc8bf9'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-56-02-c052a0cd-2f40-48e3-abaa-45d659bb6d5d'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-40-02-a4c3a71e-8711-4030-b16f-a2e8fc227d0a'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-48-03-1aa10c56-a1a9-4f93-8053-e5b6890651a1'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-34-02-f38a0489-e0bf-45f8-b403-53de69898dfd'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-44-03-803f3f54-befb-4c0c-b8cb-50268e1091c6'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-46-03-9a254d76-4a8b-4fbc-abe8-d07316b37804'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-58-03-2d814ecc-abe9-41e9-97ed-52cc15114311'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-50-02-d3b3f511-fe75-4032-8bc1-a8af74c9d8da')]
test2:sparksql
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import input_file_name
import json, os, datetime, collections, commands
glueContext = GlueContext(spark.sparkContext)
spark = glueContext.spark_session
### 2
print("test2")
data = spark.read.csv('s3://test01/minilake/minilake-in/2018/08/19/04/', header=True, encoding='utf8').withColumn('file_name', input_file_name())
data.createOrReplaceTempView('sample_data')
df = spark.sql("select file_name from sample_data")
print("test2 show")
df.show()
print("test2 collect")
df.collect()
test2出力
test2 sparksql
test2 show
+--------------------+
| file_name|
+--------------------+
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
|s3://test0...|
+--------------------+
test2 collect
[Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-32-02-8042876e-6e20-4f7d-89ec-a523211abbfc'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-36-02-478d5d9d-fd00-4a9a-bab6-f87c6b41c274'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-38-02-4ff21e9e-714e-4434-bafa-cbea9ef4ed16'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-42-02-eb40b487-4558-4497-ac9b-8f7ee7d90786'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-52-02-0c8f3918-e5c7-4749-8b49-4839a3cc8bf9'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-56-02-c052a0cd-2f40-48e3-abaa-45d659bb6d5d'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-40-02-a4c3a71e-8711-4030-b16f-a2e8fc227d0a'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-48-03-1aa10c56-a1a9-4f93-8053-e5b6890651a1'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-34-02-f38a0489-e0bf-45f8-b403-53de69898dfd'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-44-03-803f3f54-befb-4c0c-b8cb-50268e1091c6'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-46-03-9a254d76-4a8b-4fbc-abe8-d07316b37804'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-58-03-2d814ecc-abe9-41e9-97ed-52cc15114311'), Row(file_name=u's3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-50-02-d3b3f511-fe75-4032-8bc1-a8af74c9d8da')]
test3:hadoop
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import input_file_name
import json, os, datetime, collections, commands
glueContext = GlueContext(spark.sparkContext)
spark = glueContext.spark_session
### 3
print("test3")
print("test3 hadoop fs ls")
commands.getoutput("hadoop fs -ls s3://test01/minilake/minilake-in/2018/08/19/04/")
test3出力
test3 hadoop fs ls
'Found 14 items\n-rw-rw-rw- 1 zeppelin zeppelin 572 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-32-02-8042876e-6e20-4f7d-89ec-a523211abbfc\n-rw-rw-rw- 1 zeppelin zeppelin 1137 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-34-02-f38a0489-e0bf-45f8-b403-53de69898dfd\n-rw-rw-rw- 1 zeppelin zeppelin 568 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-36-02-478d5d9d-fd00-4a9a-bab6-f87c6b41c274\n-rw-rw-rw- 1 zeppelin zeppelin 562 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-38-02-4ff21e9e-714e-4434-bafa-cbea9ef4ed16\n-rw-rw-rw- 1 zeppelin zeppelin 44556 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-40-02-a4c3a71e-8711-4030-b16f-a2e8fc227d0a\n-rw-rw-rw- 1 zeppelin zeppelin 1707 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-42-02-eb40b487-4558-4497-ac9b-8f7ee7d90786\n-rw-rw-rw- 1 zeppelin zeppelin 1563 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-44-03-803f3f54-befb-4c0c-b8cb-50268e1091c6\n-rw-rw-rw- 1 zeppelin zeppelin 2401 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-46-03-9a254d76-4a8b-4fbc-abe8-d07316b37804\n-rw-rw-rw- 1 zeppelin zeppelin 988 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-48-03-1aa10c56-a1a9-4f93-8053-e5b6890651a1\n-rw-rw-rw- 1 zeppelin zeppelin 43699 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-50-02-d3b3f511-fe75-4032-8bc1-a8af74c9d8da\n-rw-rw-rw- 1 zeppelin zeppelin 1401 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-52-02-0c8f3918-e5c7-4749-8b49-4839a3cc8bf9\n-rw-rw-rw- 1 zeppelin zeppelin 141 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-54-02-94214b4f-d006-4f67-b954-5390375fd700\n-rw-rw-rw- 1 zeppelin zeppelin 1419 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-56-02-c052a0cd-2f40-48e3-abaa-45d659bb6d5d\n-rw-rw-rw- 1 zeppelin zeppelin 2125 2018-08-19 23:26 s3://test01/minilake/minilake-in/2018/08/19/04/minilake1-1-2018-08-19-04-58-03-2d814ecc-abe9-41e9-97ed-52cc15114311'
こちらも是非
ノートブックサーバー構築手順(公式)
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/dev-endpoint-notebook-server-considerations.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f