開発エンドポイントとノートブック
"開発エンドポイント"はGlueの開発中のコードの実行環境です。
"ノートブック"はコードの記述と実行結果を表示するものです。
どちらもGlueのコード開発のために使います。
今回は入力出力データの配置にS3のみを使うことを想定した手順です。まずはノートブックを動かすところまで実現したいと思います。
※今回はRDSやRedshiftを使ったGlueジョブの開発のノートブック利用は対象外とします。
構築を行うと、ノートブックとしてZeppelinがインストールされたEC2が1台作成され、
Sparkのクラスタとその接続口としてGlueの開発エンドポイントが1つ作成されます。
全体の流れ
- 前準備
- 開発エンドポイント作成
- ノートブックサーバー作成
- Zeppelinの動作確認
前準備
EC2キーペア
EC2のキーペアを作成する。既にあればそれでOK
VPC関連の確認
今回はDefault VPCを利用します。インターネットから接続出来る状態であればどのVPCでも問題ありません。(Default VPCとDefault VPCのパブリックサブネットがなければ作成しておきます)
ノートブックサーバーに付けるSecurity Group作成
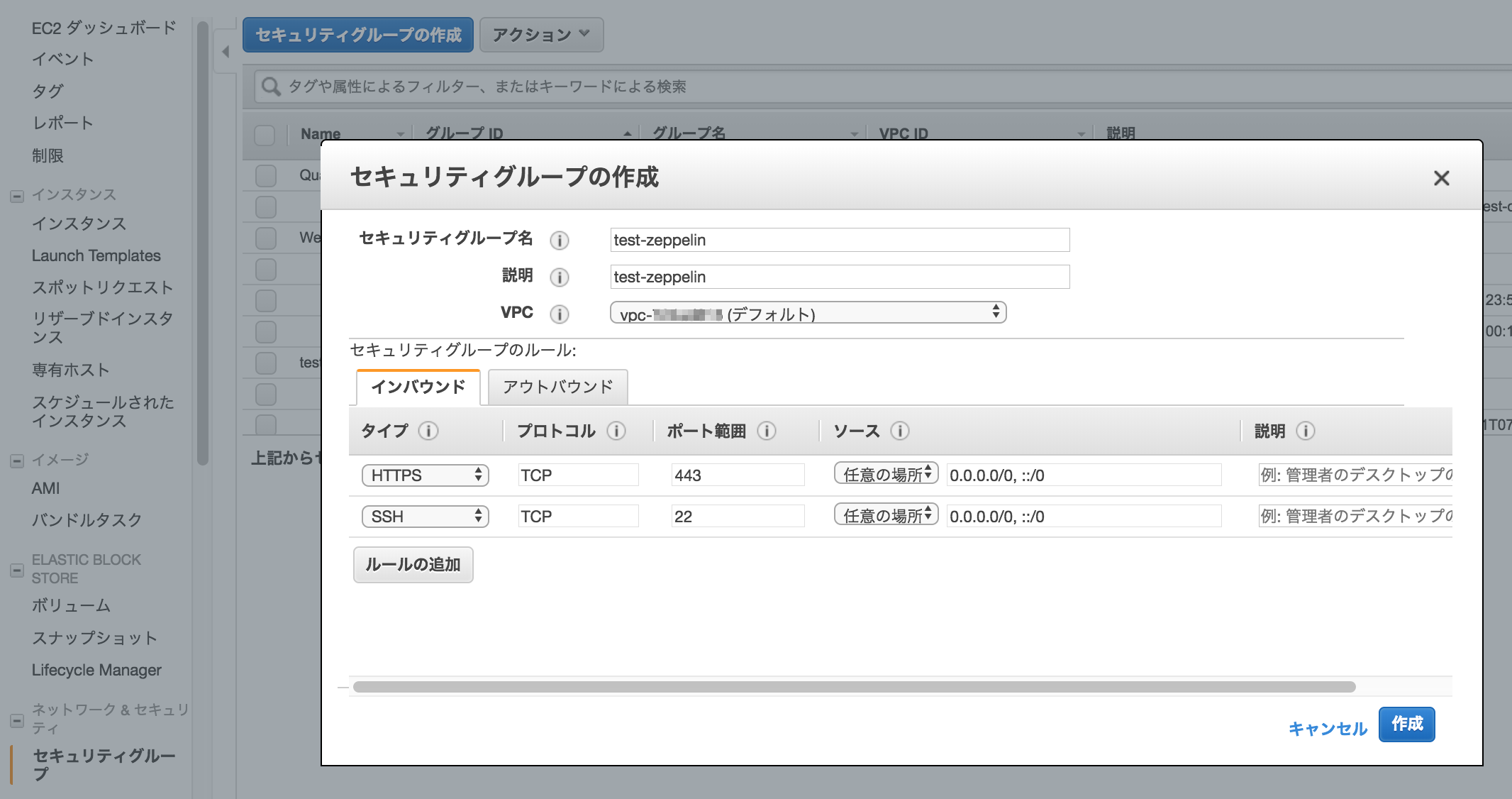
EC2の画面の左側メニューから[セキュリティグループ]をクリック、[セキュリティグループの作成]をクリックし、以下の情報を入力し[作成]をクリックする
- セキュリティグループ名:test-zeppelin(任意)
- 説明:test-zeppelin(任意)
- VPC:xxxx(デフォルトVPC)
- インバウンドルール:SSHとHTTPSを任意の場所から許可
※SSHはEC2接続用、HTTPSはZeppelin接続用
IAMロールを2つ準備
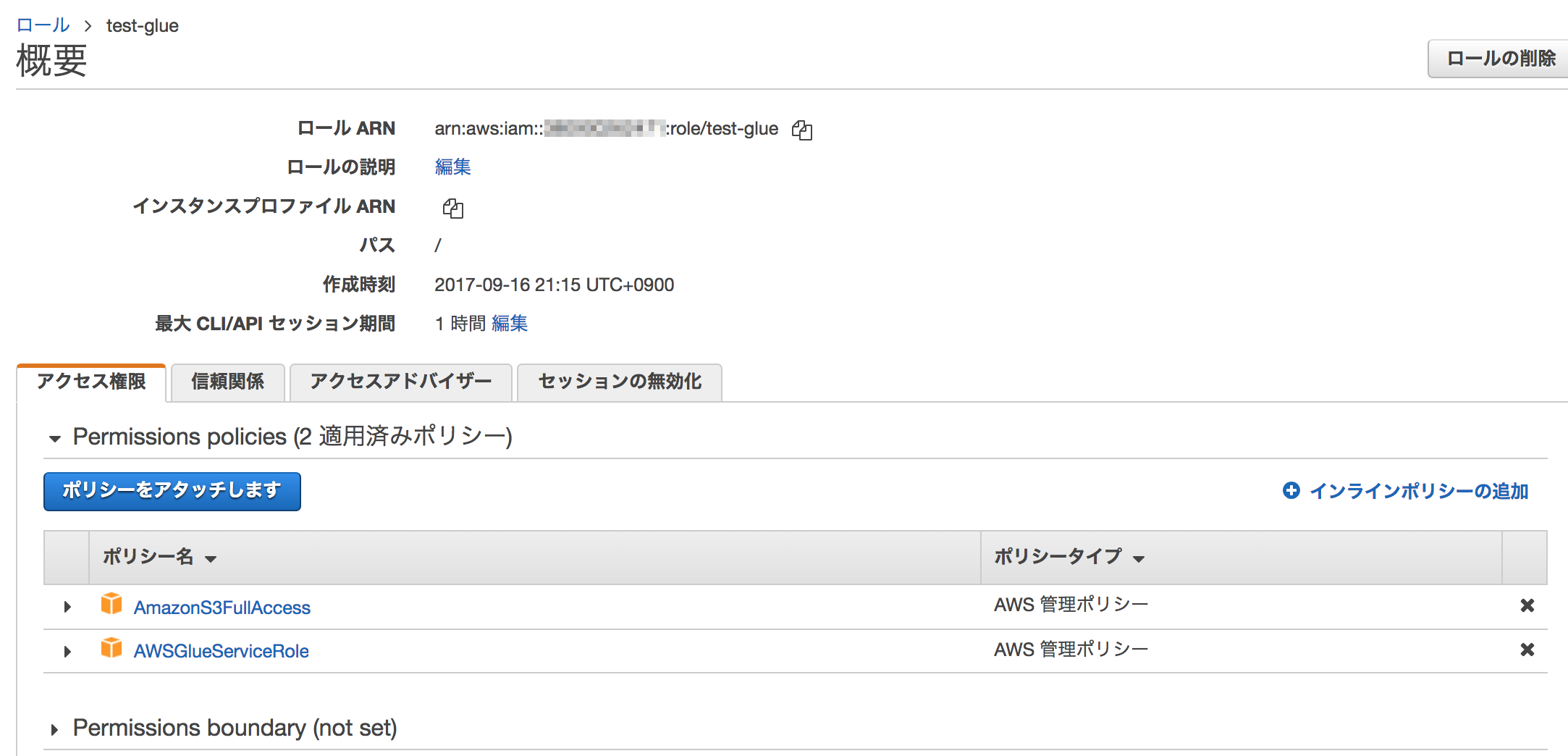
(1)開発エンドポイントにアタッチするIAMロール
Glueの実行やGlueが使うリソースにアクセスするための権限を指定します。すでにクローラやジョブの実行に作成したロールがあればそれでOKです。
- IAMロール名:test-glue(任意)
- アタッチするIAMポリシー:AmazonS3FullAccess、AWSGlueServiceRole
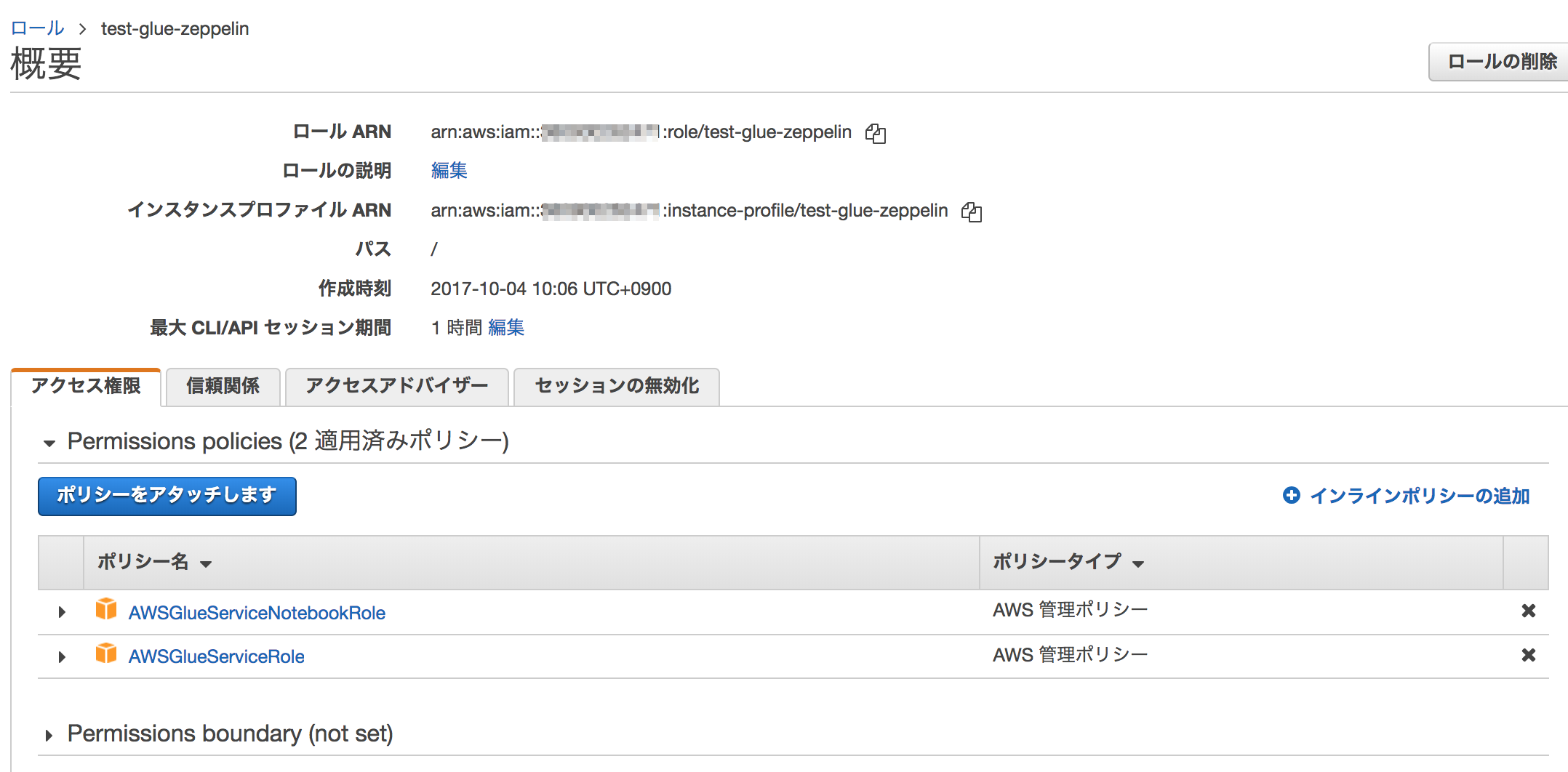
(2)ノートブックが起動するEC2にアタッチするIAMロール作成
- IAMロール名:test-glue-zeppelin(任意)
- アタッチするIAMポリシー:AWSGlueServiceNotebookRole、AWSGlueServiceRole
開発エンドポイント作成
Glueの画面の左側メニューの[開発エンドポイント]をクリック、[エンドポイントの追加]をクリックする
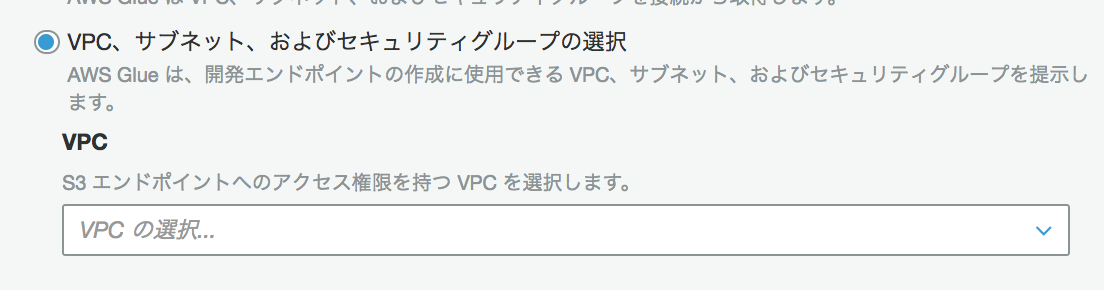
各値を入力し、[次へ]をクリックする
- 開発エンドポイント名:test1(任意)
- IAMロール:test-glue(さっき作ったやつ)
- データ処理単位(DPU):5(デフォ値なので必要に応じて変えます。値が大きいと性能も料金も大きい、課金に関わる)
- 必要なライブラリやJarがあればS3に置いてパスを入力
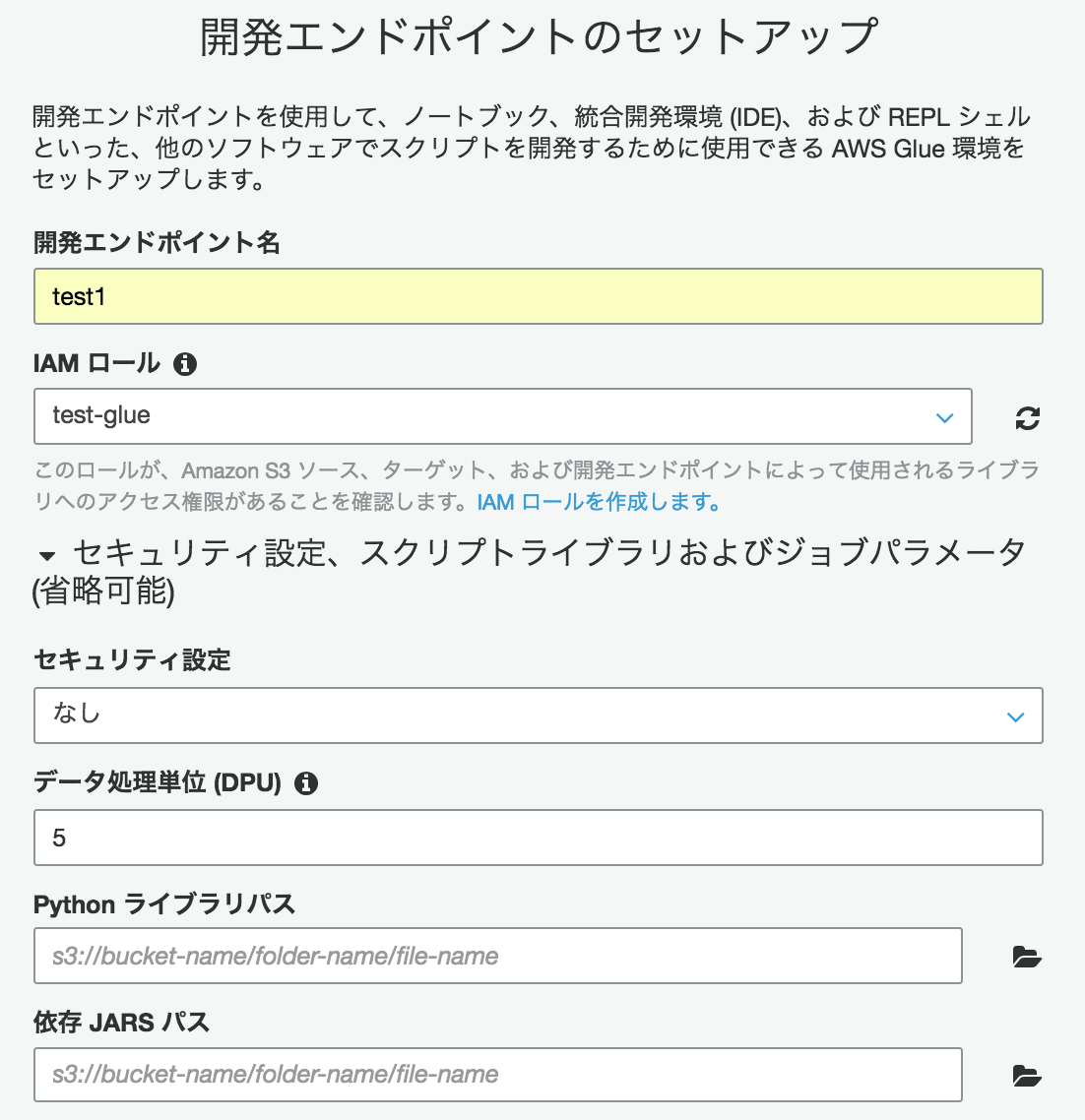
今回はS3のみ利用なので"ネットワーキング情報をスキップ"にチェックを入れ[次へ]をクリック
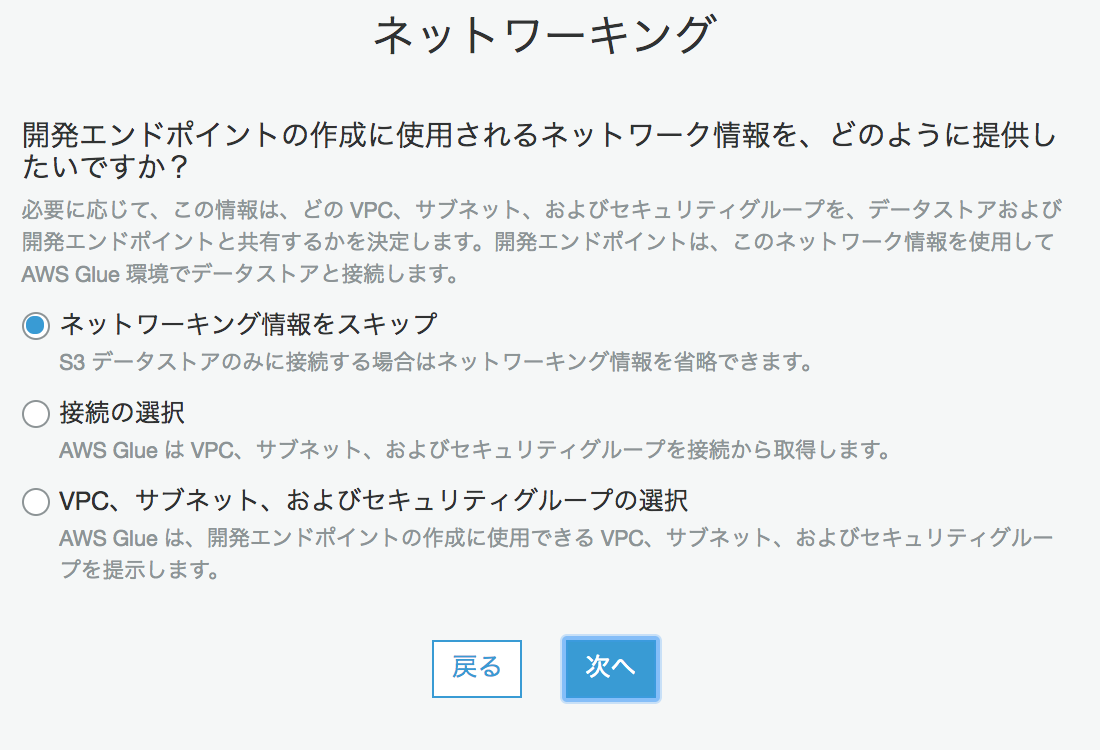
(補足)ちなみにRDSやRedshiftやオンプレRDB使う場合はここにチェック入れてGlueの"接続"を定義し選択する
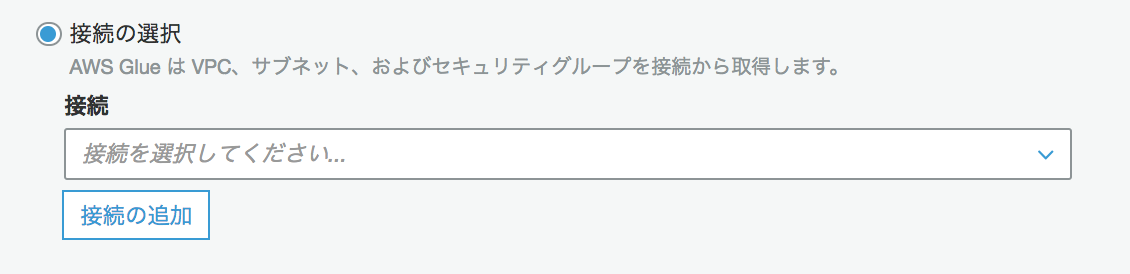
(補足)S3にS3エンドポイントからアクセスする場合はここにチェックを入れS3エンドポイントが設定されたVPCを選択する
今回はEC2のノートブックサーバーから接続するので、SSHパブリックキーはなにもせず[次へ]をクリック
※ローカルのノートブックやIDEから接続することも出来、その場合にキーを追加します。
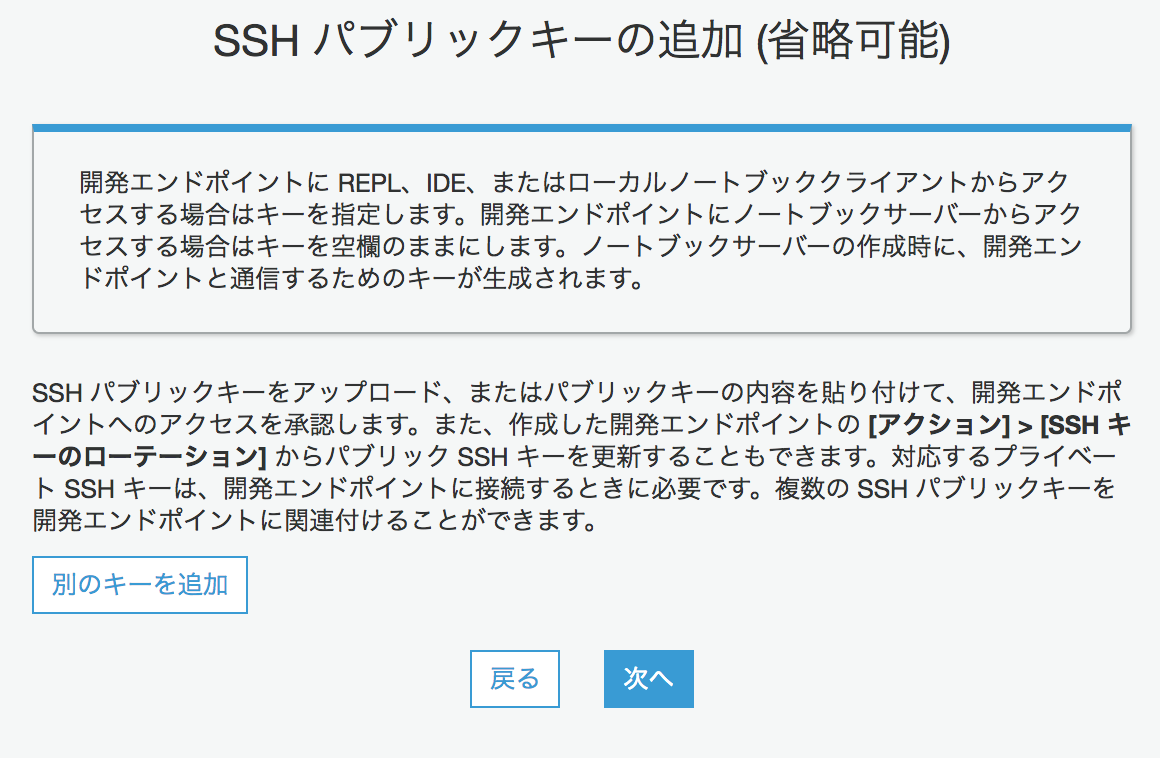
簡素な画面ですが、今回だと入力箇所も少ないためこのような内容です。
[完了]をクリックします。
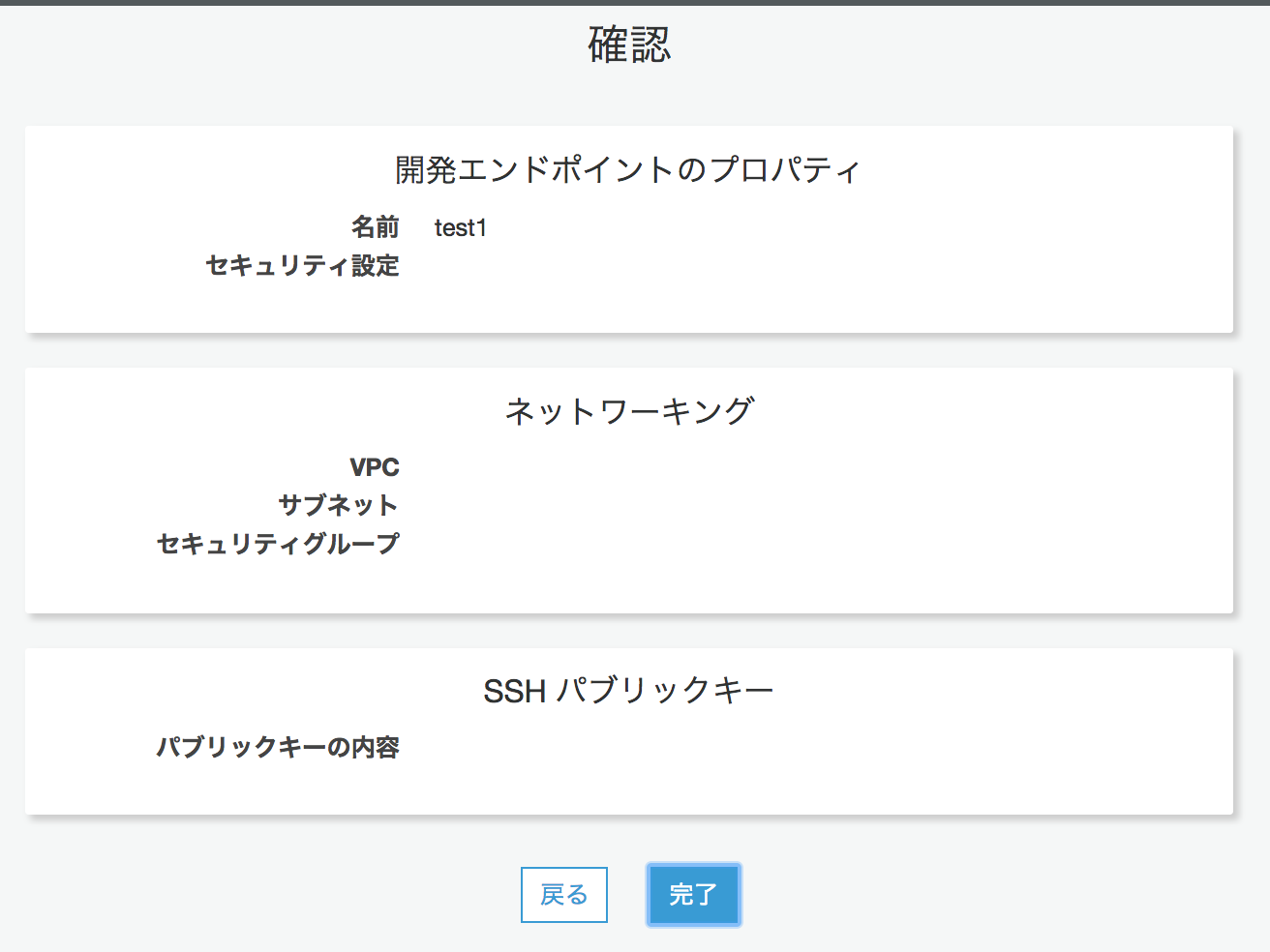
ステータスがProvisioningになります。10分ほど待つとReadyに変わります。
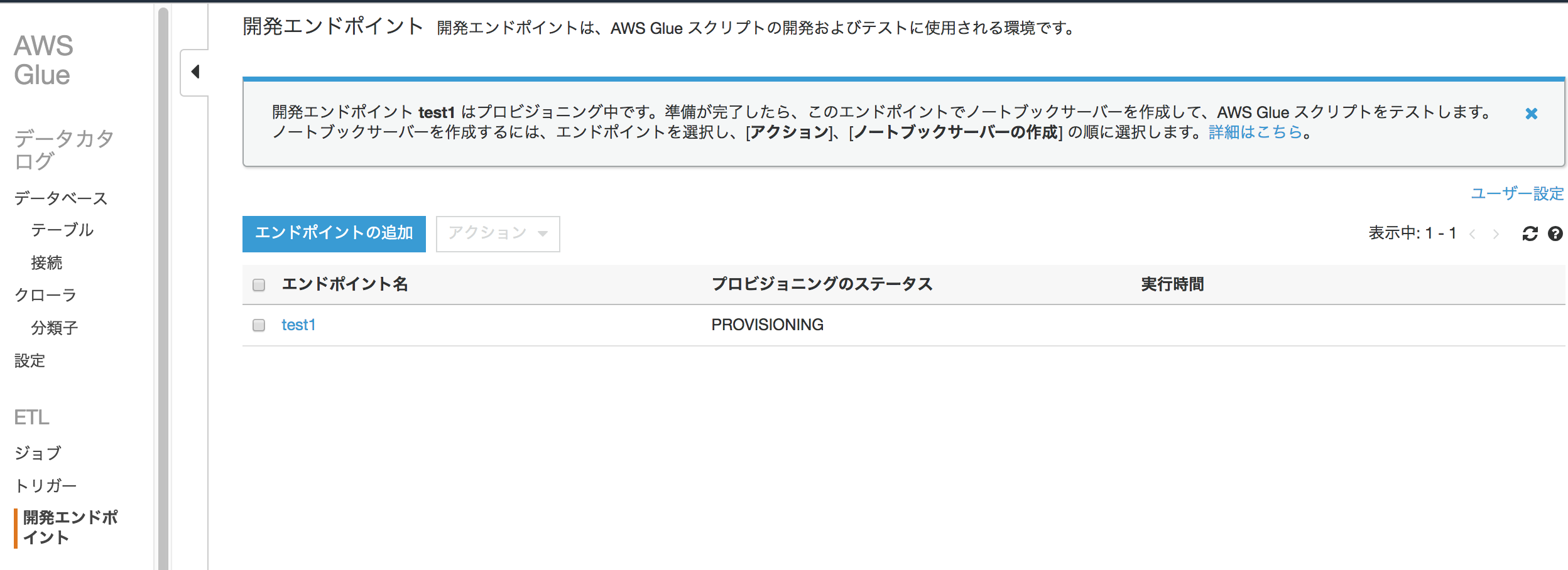
Zeppelinノートブックの動作確認
開発エンドポイントのステータスがREADYとなり作成が完了したら、対象のエンドポイントにチェックを入れ[アクション]をクリックし[Create Zeppelin notebook]をクリックする
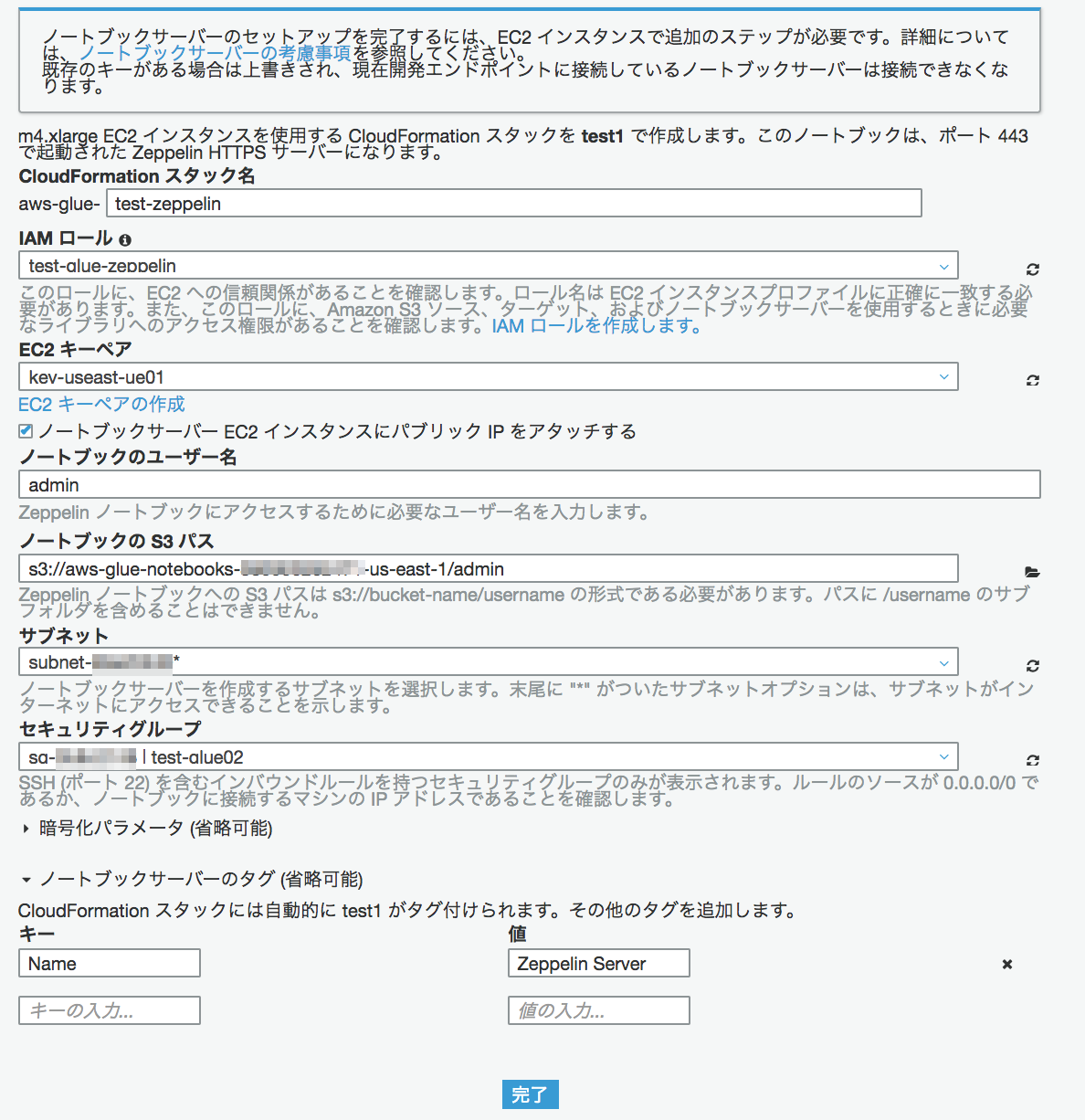
各値を入力し、[完了]をクリックする
- スタック名:test-zeppelin(任意)
- IAMロール:test-glue-zeppelin(さっき作ったやつ)
- EC2キーペア:今回作成したもの(既に作成済ものもでもOK)
- サブネット:今回はDefault VPCなのでDefault VPCのパブリックサブネットを選択
- セキュリティグループ:test-zeppelin(今回作成したもの)
- ノートブックサーバーのタグ:キーに"Name"、値に"Zeppelin Server"など入れるとわかりやすい
※ノートブックのS3パス:ここにノートブックで作成したコードの情報が保存される
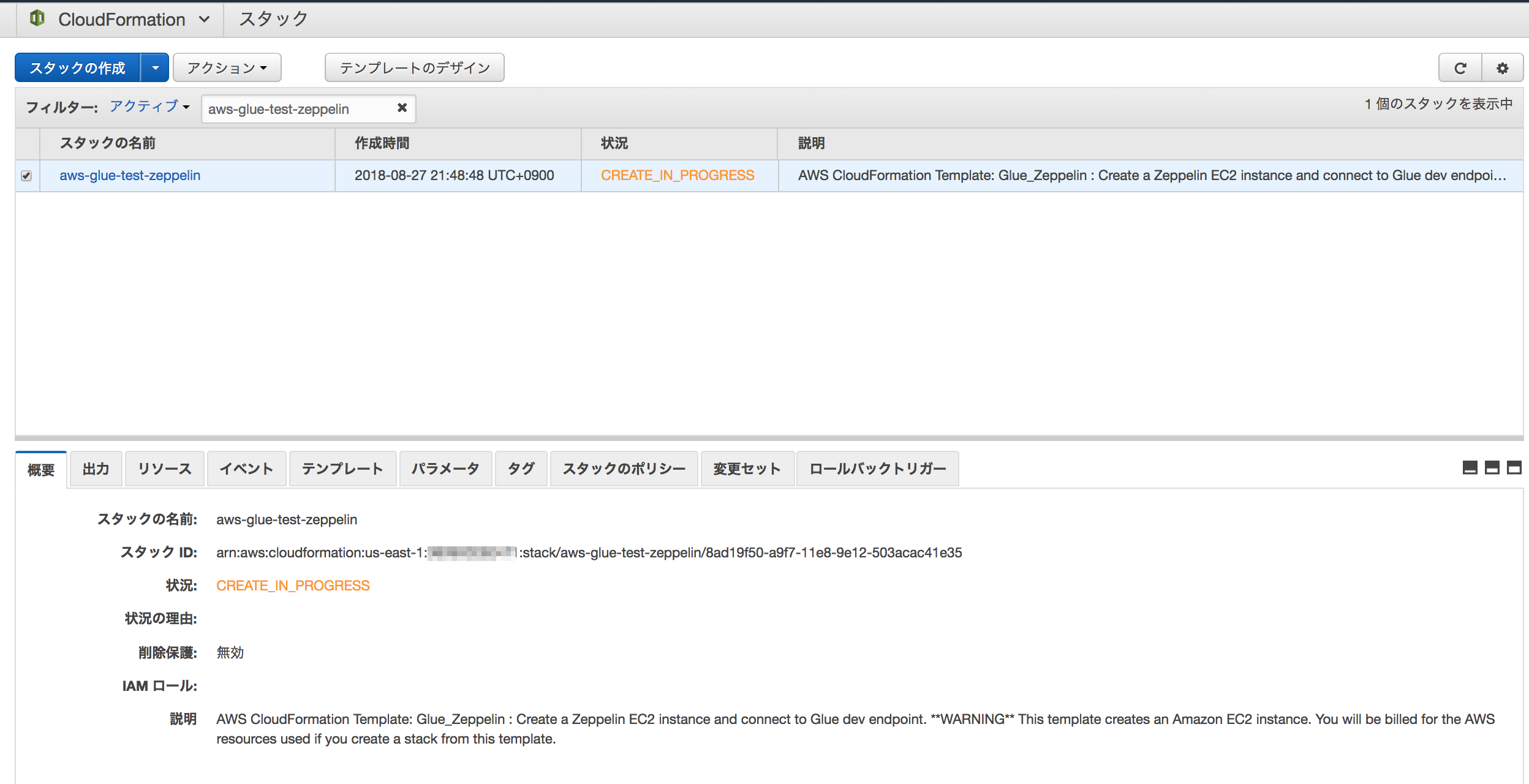
CloudFormationによるノートブックサーバーの構築が始まる。3分くらいで出来上がる。
(注)もしCloudFormationで以下のようなエラーが出る場合、私が遭遇したパターンだと、起動してくるEC2のuserdataで実行されるコマンドがうまくいかない場合、失敗のシグナルを受信しCloudFormatinがエラーで終わります。私の場合、NATGWなしのプライベートサブネットを選択したことにより起動してきたEC2が外部にでれなくuserdata内のyumがタイムアウトしており以下のエラーとなりました。
Failed to receive 1 resource signal(s) within the specified duration
EC2の画面でEC2が1台起動していることを確認
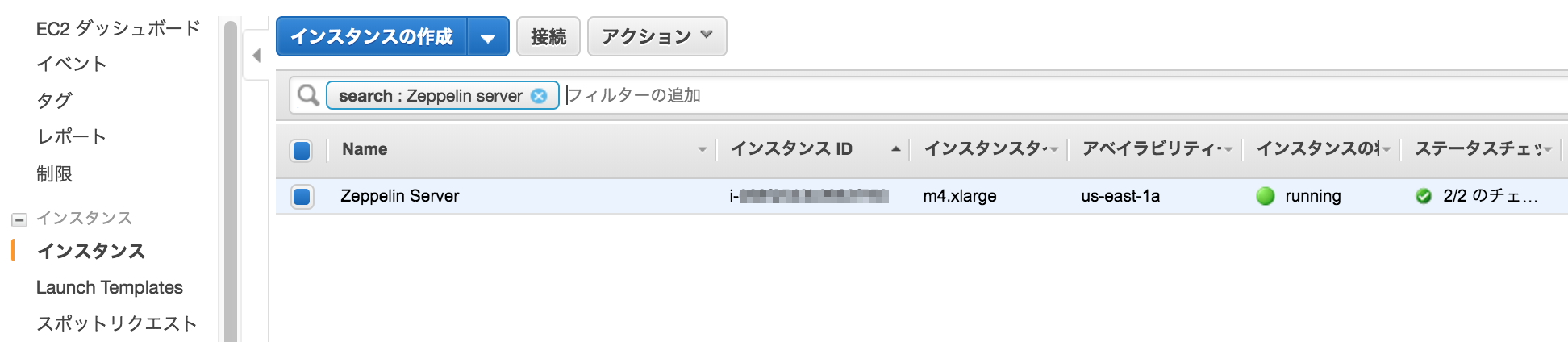
起動したEC2インスタンスに、指定した鍵を使いSSHログインする。
ssh -i ./key-useast-ue01.pem ec2-user@ec2-xx-xx-xx-xx.compute-1.amazonaws.com
セットアップスクリプトを実行する(この辺が今年の春ころから変更された手順です)
- Zeppelinのパスワード入力(任意)(デフォのユーザー名はadmin)
- SSHキーを作成:yes
- JKS keystore:no
[ec2-user@ip-172-31-yy-yy ~]$ ./setup_notebook_server.py
Starting notebook server setup. See AWS Glue documentation for more details.
Press Enter to continue...
Creating password for Zeppelin user admin
Type the password required to access your Zeppelin notebook:
Confirm password:
Updating user credentials for Zeppelin user admin
Zeppelin username and password saved.
Setting up SSH tunnel to devEndpoint for notebook connection.
Do you want a SSH key pair to be generated on the instance? WARNING this will replace any existing public key on the DevEndpoint [y/n] y
Generating SSH key pair /home/ec2-user/dev.pem
Generating public/private rsa key pair.
Your identification has been saved in /home/ec2-user/dev.pem.
Your public key has been saved in /home/ec2-user/dev.pem.pub.
The key fingerprint is:
56:a1:ce:34:34:8a:a6:73:xx:xx:xx:xx:xx:xx:xx:xx ec2-user@ip-172-31-xx-xx
The key's randomart image is:
+--[ RSA 2048]----+
| o . |
| . o o . |
| o . + . |
| + + o |
| = . S |
| =. . |
| +o . |
| +.+o |
|=.Eo |
+-----------------+
Attempting to reach AWS Glue to update DevEndpoint's public key. This might take a while.
Waiting for DevEndpoint update to complete...
Waiting for DevEndpoint update to complete...
Waiting for DevEndpoint update to complete...
DevEndpoint updated to use the public key generated.
Configuring Zeppelin server...
********************
We will configure Zeppelin to be a HTTPS server. You can upload a CA signed certificate for the server to consume (recommended). Or you can choose to have a self-signed certificate created.
See AWS Glue documentation for additional information on using SSL/TLS certificates.
********************
Do you have a JKS keystore to encrypt HTTPS requests? If not, a self-signed certificate will be generated. [y/n] n
Generating self-signed SSL/TLS certificate at /home/ec2-user/ec2-34-229-154-121.compute-1.amazonaws.com.jks
Self-signed certificates successfully generated.
Exporting the public key certificate to /home/ec2-user/ec2-34-229-154-121.compute-1.amazonaws.com.der
Certificate stored in file </home/ec2-user/ec2-34-229-154-121.compute-1.amazonaws.com.der>
Configuring Zeppelin to use the keystore for SSL connection...
Zeppelin server is now configured to use SSL.
SHA256 Fingerprint=B6:55:5B:96:38:03:9A:58:33:35:F6:9D:C4:75:9F:F2:1C:C4:3A:BF:2E:77:4D:xx:xx:xx:xx:xx:xx:xx:xx:xx
**********
The public key certificate is exported to /home/ec2-user/ec2-34-229-154-121.compute-1.amazonaws.com.der
Run on your local host the following command to copy the certificate.
scp -i <ec2-key.pem> ec2-user@ec2-xx-xx-xx-xx.compute-1.amazonaws.com:/home/ec2-user/ec2-xx-xx-xx-xx.compute-1.amazonaws.com.der <local-path>
The SHA-256 fingerprint for the certificate is
B6:55:5B:96:38:03:9A:58:33:35:F6:9D:C4:75:9F:F2:1C:C4:3A:BF:2E:77:4D:xx:xx:xx:xx:xx:xx:xx:xx:xx
You may need it when importing the certificate to the client. See AWS Glue documentation for more details.
**********
Press Enter to acknowledge and continue...
All settings done!
Starting SSH tunnel and Zeppelin...
autossh start/running, process 27359
Done. Notebook server setup is complete. Notebook server is ready.
See /home/ec2-user/zeppelin/logs/ for Zeppelin log files.
Zeppelinの起動確認
$ sudo ./zeppelin/bin/zeppelin-daemon.sh status
Zeppelin is running [ OK ]
Glueの画面で[開発エンドポイント]をクリックし、今回作成したエンドポイント名(ここではtest1)をクリック
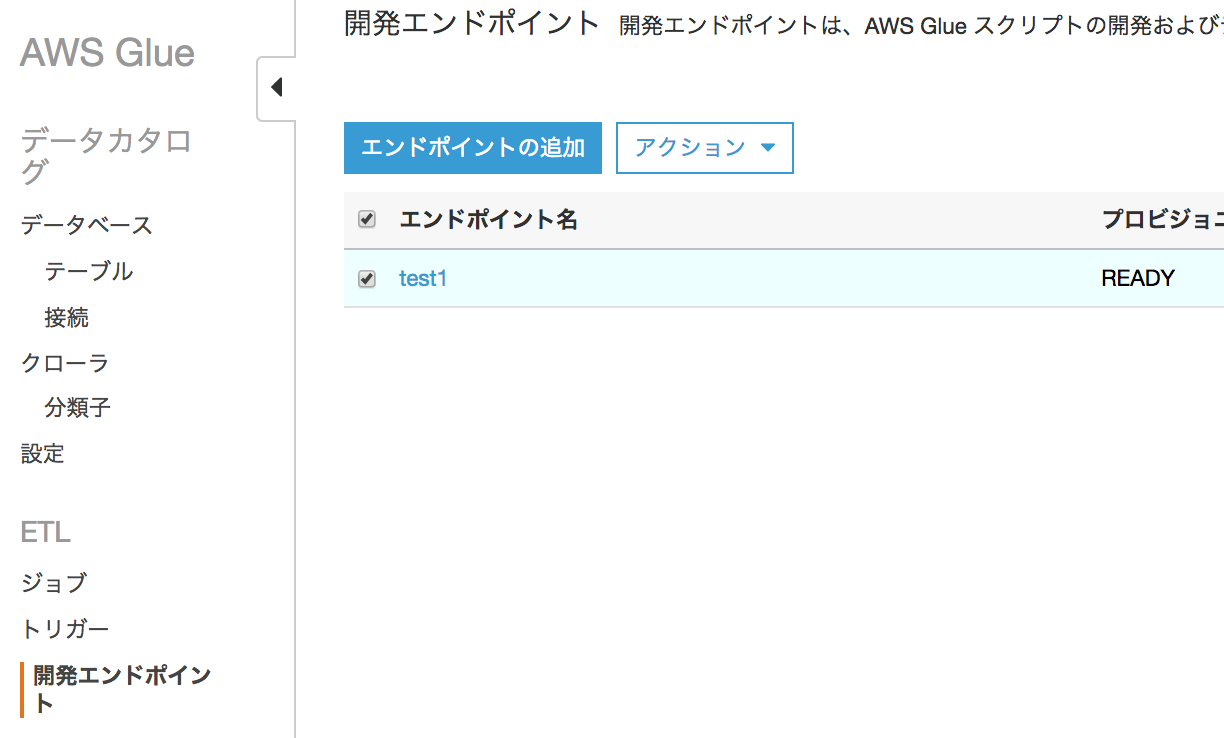
HTTPS URLをクリックします。ブラウザで保護されてない通信の警告が出るので無視して進むと、Zeppelinの画面が表示されます。

Zeppelinの動作確認
Zeppelinの画面が表示されたら、右上の[Login]をクリックします。
構築時に入力したID/Passwordでログインします。
今回は、admin/*******
画面左上の[Notebook]をクリックし、[+Create new note]をクリックする
Note Nameに"test note 1"を入力し[Create note]をクリックする
ノートを自由に作ってコードを実行していきます。コメントも書けるので動く手順書です。トライアンドエラーがやりやすいので分析する方によく使われています。他のノートブックではJyupiter notebookなどもよく使われています。
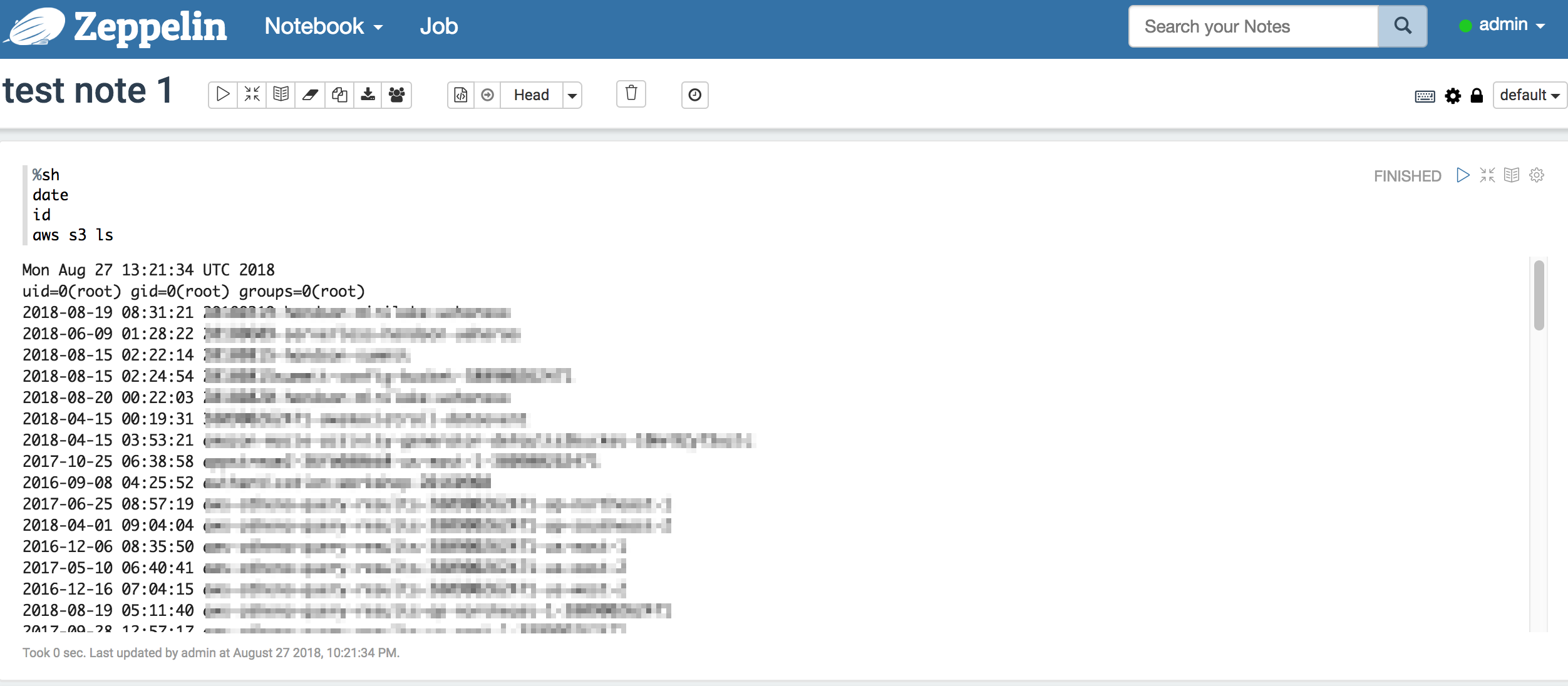
まずはシェルを実行してみる
ノートの画面右上に実行ボタンがあります。またはShift+Enterが実行のショートカットです。
%sh
date
id
aws s3 ls
DataFrame作ってみる
%pyspark
from pyspark.sql.types import *
# DataFrameを作ってみる
df = spark.createDataFrame ([
(1,144.5,5.9,33,'M'),
(2,167.2,5.4,45,'M'),
(3,124.1,5.2,23,'F'),
(4,144.5,5.9,33,'M'),
(5,133.2,5.7,54,'F'),
(3,124.1,5.2,23,'F'),
(5,129.2,5.3,42,'M')
],['id','weight','height','age','gender'])
df.show()

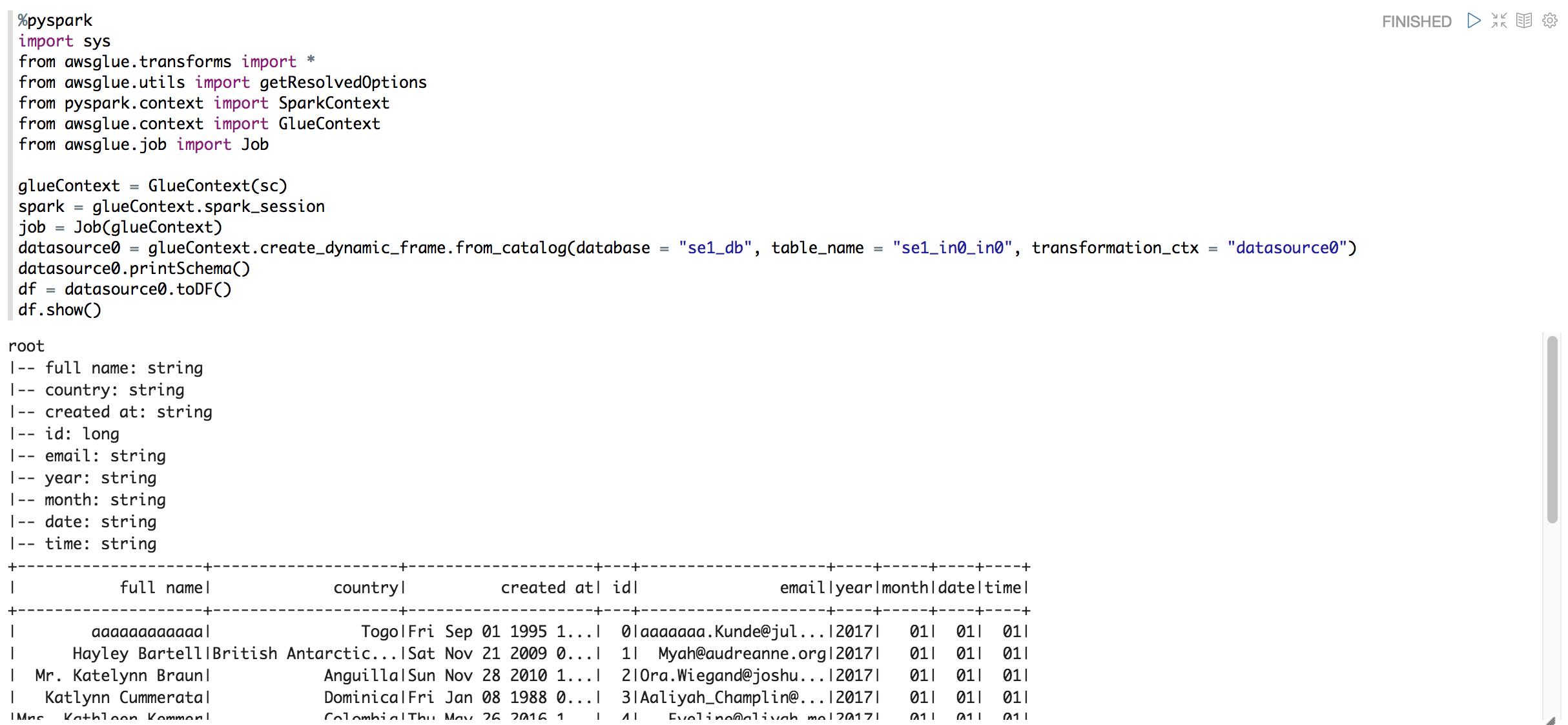
サンプルのelb_logのスキーマやデータを見る
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se1_db", table_name = "se1_in0_in0", transformation_ctx = "datasource0")
datasource0.printSchema()
df = datasource0.toDF()
df.show()
①と同じコードをZeppelinで実行する
"Glueの使い方的な①(GUIでジョブ実行)"のコードを使います。処理内容はcsv->parquetにしているだけでGUIの操作のみで作成できるコードです。
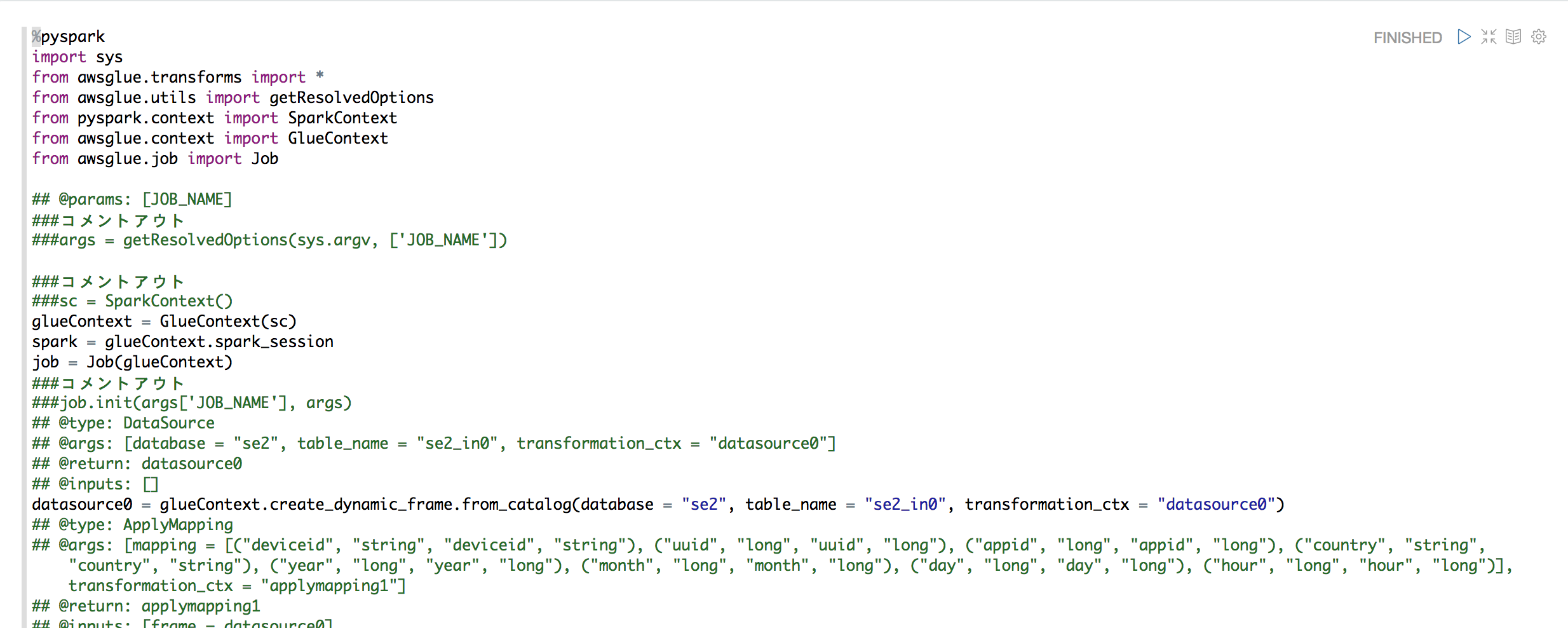
ただ、コードの一部修正が必要です。Zeppelin側からするとJobという概念はないのでその辺をコメントアウトします。以下がコメントアウトした箇所です。
###コメントアウト
###args = getResolvedOptions(sys.argv, ['JOB_NAME'])
###コメントアウト
###sc = SparkContext()
###コメントアウト
###job.init(args['JOB_NAME'], args)
###コメントアウト
###job.commit()
こちらが実際のコードです。
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
### コメントアウト
### args = getResolvedOptions(sys.argv, ['JOB_NAME'])
### コメントアウト
### sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
### コメントアウト
### job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "long", "year", "long"), ("month", "long", "month", "long"), ("day", "long", "day", "long"), ("hour", "long", "hour", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
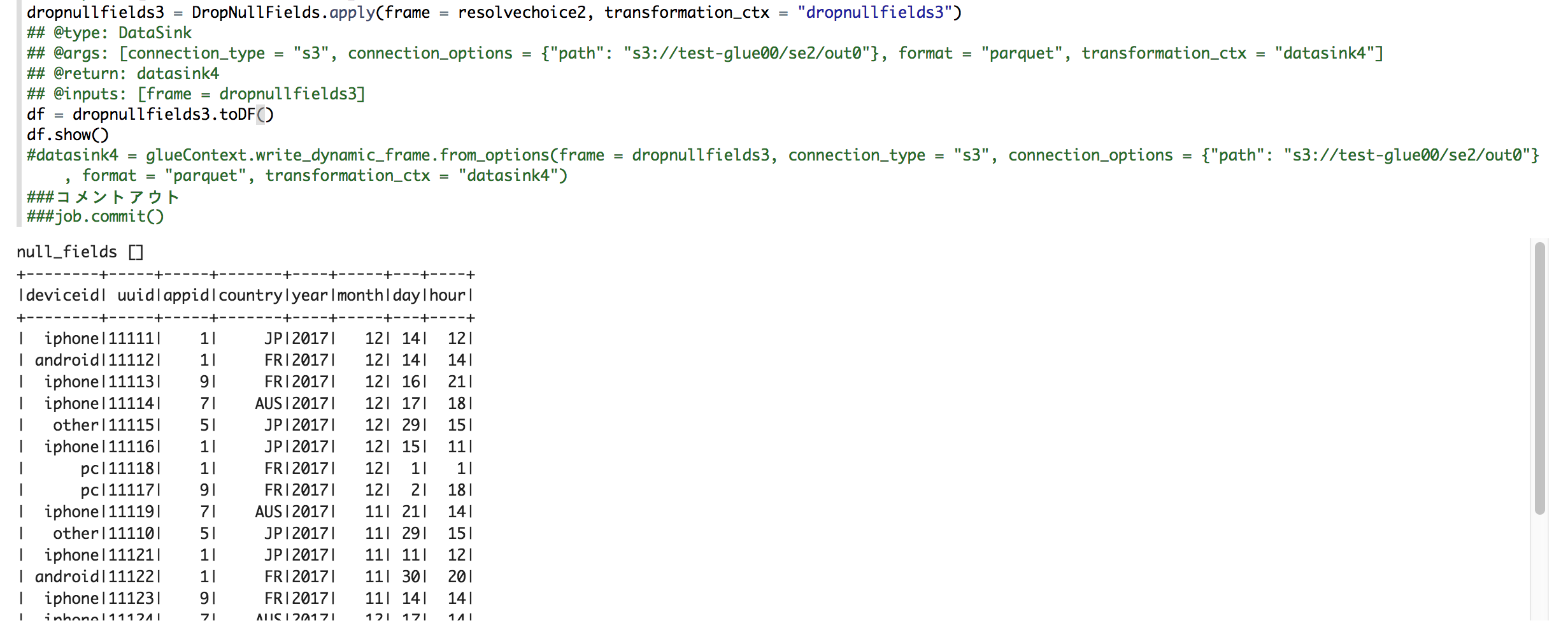
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4")
### コメントアウト
### job.commit()
開発途中は、S3への出力をコメントアウトし、df.show()などして確認行うなどができます。
df = dropnullfields3.toDF()
df.show()
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out0"}, format = "parquet", transformation_ctx = "datasink4")
その他
Interpreter
画面の右上の歯車マークをクリックするとZeppelinにbindingされているinterpreterを確認できます。結構たくさんあります。
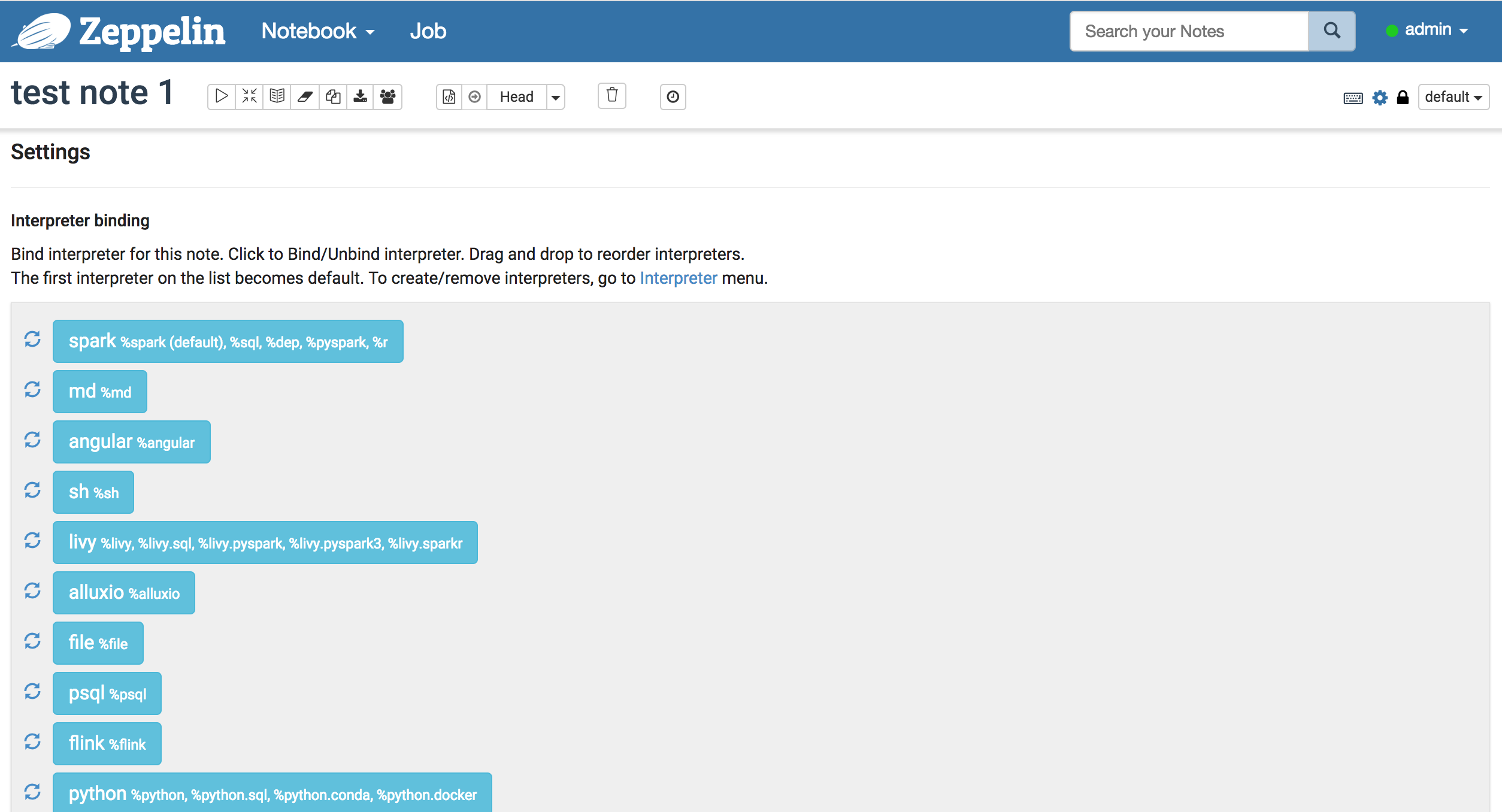
各Interpreterの右にある回転矢印マークは各Interpreterの再起動を行います。たまに接続できないなど動きがおかしいときはやってみてください。
ノートブックのコードの場所
ノートの中身はS3に保存されてます。これを取っておけば別のZeppelinでも同じノートを使えます。
$ aws s3 cp s3://aws-glue-notebooks-xxxxxxxxxxxx-us-east-1/admin/notebook/2DRKWGDJ9/note.json -
{
"paragraphs": [
{
"text": "%sh\ndate\nid\naws s3 ls",
"user": "admin",
"dateUpdated": "Aug 27, 2018 1:31:01 PM",
"config": {
"colWidth": 12.0,
"enabled": true,
"results": {
"0": {
"graph": {
"mode": "table",
"height": 134.0,
"optionOpen": false
}
}
},
"editorSetting": {
"language": "sh",
起動しっぱなしは注意
開発エンドポイントは起動時間で課金されます。起動してほっておいても課金されますので必要ない時は削除しましょう。
ちなみに
Zeppelin:ツェッペリン(独: Zeppelin)とは、20世紀初頭、フェルディナント・フォン・ツェッペリン伯爵(通称Z伯)が開発した硬式飛行船の一種を指す。


こちらも是非
ノートブックサーバー構築手順(公式)
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/dev-endpoint-notebook-server-considerations.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f