#今回の内容
Azure ML Python SDK を使う:データセットをインプットとして使う - その1 および
[Azure ML Python SDK を使う:データセットをインプットとして使う - その2]
(https://qiita.com/notanaha/items/30d57590c92b03bc953c)
ではインプットデータの取り扱いについて記載しました。
アウトプットは既定で用意される outputs フォルダを使いましたが、今回は任意の blob storage に書きだすことにします。
#登場アイテム
今回登場するアイテムは、
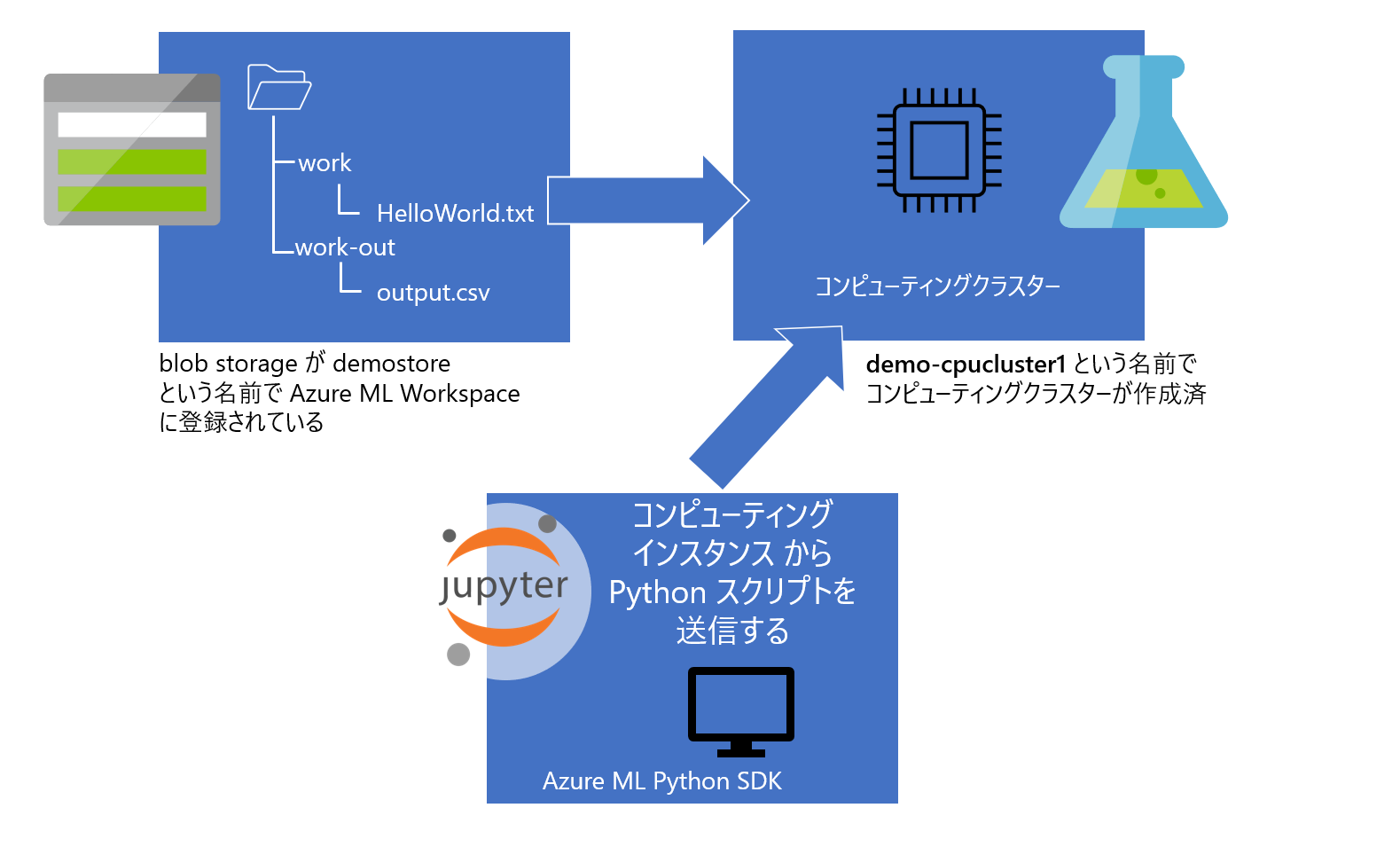
- CSVファイル(運用を意識して Azure Blob Storage に配置されていると仮定)
- 下の図で、始めに準備されているのは work フォルダの HelloWorld.txt だけで、work-out の output.csv は今回のスクリプトの実行の結果コピーされるファイルです
- リモート仮想マシン(以降 Azure ML の用語を用いて "コンピューティングクラスター")
- Jupyter Notebook
- Azure Machine Learning Studio のコンピューティングインスタンスから起動したもの
カーネルは Python 3.8 - AzureML を、Azure ML Python SDK バージョン 1.33.0 で検証しています
- Azure Machine Learning Studio のコンピューティングインスタンスから起動したもの
Python SDK のバージョンを確認するには、
import azureml.core
print("SDK version:", azureml.core.VERSION)
Notebook のフォルダー構造は次のようになっている前提で記述します。
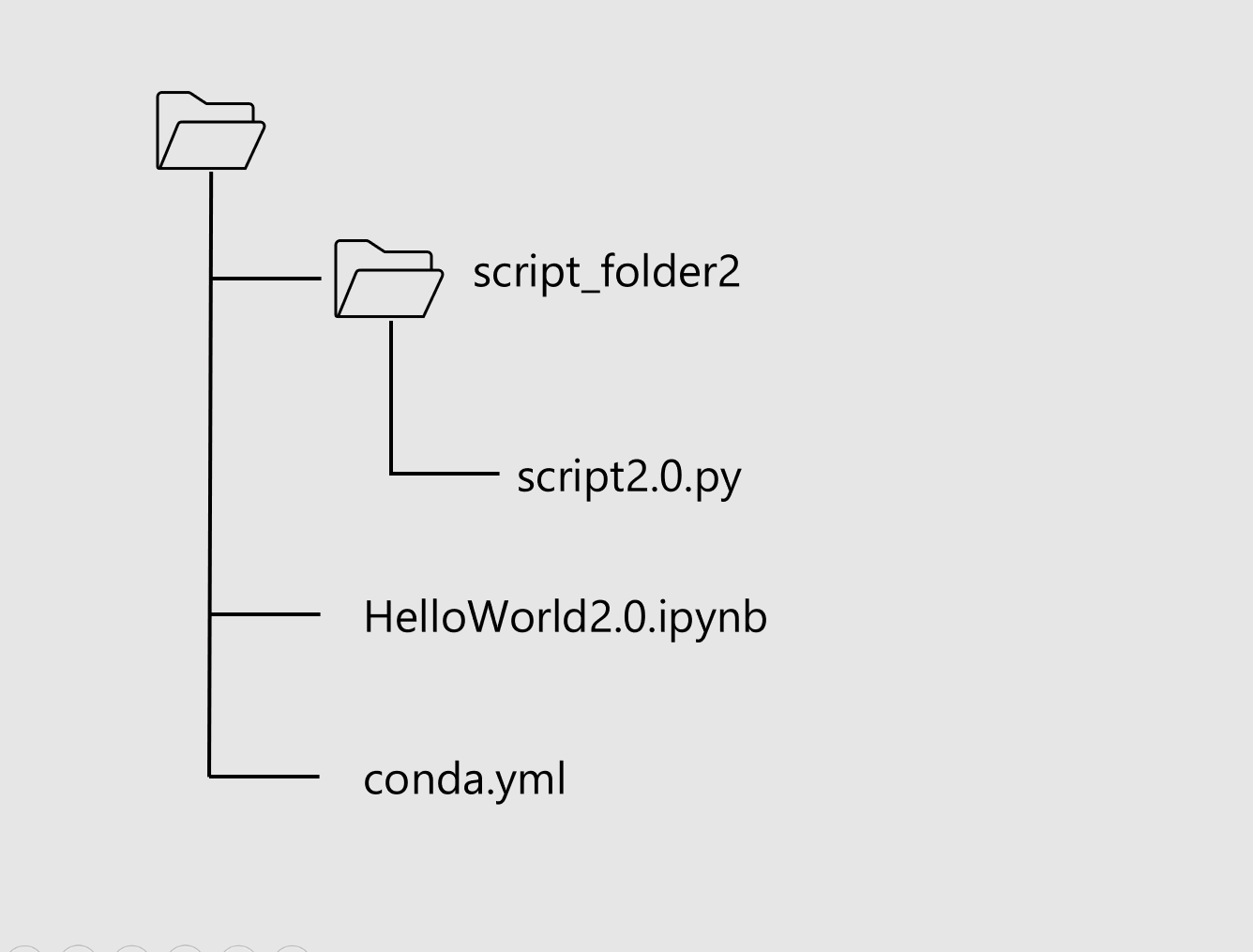
前回までと同じく script2.py は blob Storage 上の CSV ファイルを Read して work-out フォルダに書きだすだけの簡単な内容です。
同様に script2.py をコンピューティングクラスターに送りこんで実行させるのが HelloWorld2.0.ipynb の役目です。
HelloWorld2.0.ipynb の手順は以下のとおり。③ でアウトプットフォルダを指定しています。
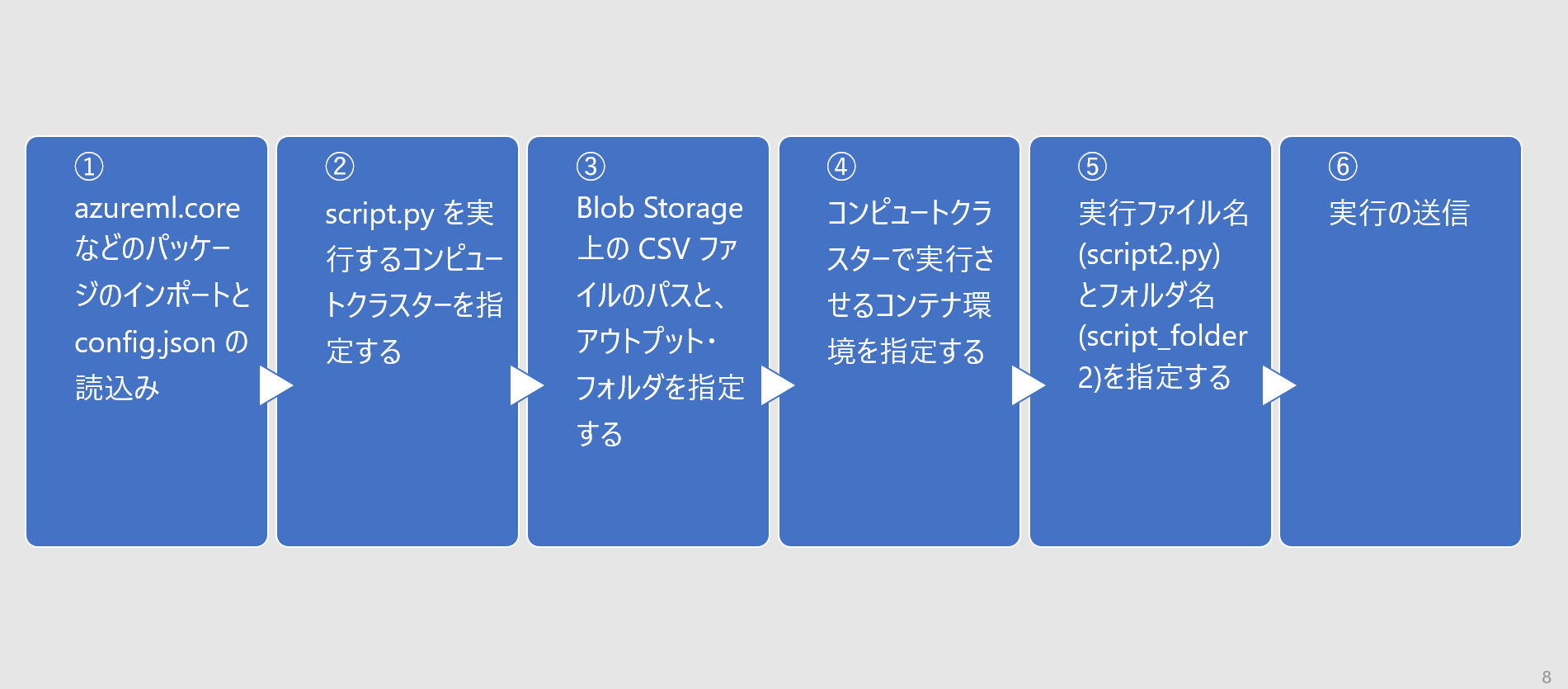
手順
順番に手順をみていきます。
-
パッケージの読込み
まずパッケージを読込みます。from azureml.core import Workspace, Experiment, Dataset, Datastore, ScriptRunConfig, Environment from azureml.core.compute import ComputeTarget from azureml.core.compute_target import ComputeTargetException from azureml.core.conda_dependencies import CondaDependencies from azureml.core.runconfig import DockerConfiguration from azureml.data import OutputFileDatasetConfig workspace = Workspace.from_config() -
コンピューティングクラスターの指定
Python SDK でリモートコンピュートリソースを作成することもできますが、ここでは全体の見通しがよくなるように事前にAzure ML Studio でコンピューティングクラスターを作成しておきました。aml_compute_target = "demo-cpucluster" # <== The name of the cluster being used try: aml_compute = ComputeTarget(workspace, aml_compute_target) print("found existing compute target.") except ComputeTargetException: print("no compute target with the specified name found") -
CSV ファイルのパスとアウトプットフォルダの指定
demostore は Azure ML Workspace に登録したデータストア名です。データストアの BLOB コンテナ内のファイルパスを dataset クラスに渡しています。
前回と違いファイル名 File.from_files() で渡しています。Tabular.from_delimited_files() は csv ファイルなどの表形式データを渡すのに使いますが、File.from_files() を使うことでそれ以外のファイルやフォルダを渡すことができます。ds = Datastore(workspace, 'demostore') input_data = Dataset.File.from_files(ds.path('work/HelloWorld.txt')).as_named_input('input_ds').as_mount() output = OutputFileDatasetConfig(destination=(ds, 'work_out')) -
環境の指定
上述のとおり今回は RunConfiguration() ではなく Environment() を使います。前者ではコンピューティングクラスターの変数をここで指定しましたが、後者では指定せず、コンピューティングクラスターの変数は次の ScriptRunConfig() で指定することになります。myenv = Environment.from_conda_specification(name="my-env", file_path="conda.yml") docker_config = DockerConfiguration(use_docker=True)conda.yml はノートブックと同じフォルダに配置されているものとします。
name: my-env dependencies: - python=3.8.5 - pip: - azureml-defaults - pandas==1.1.4 channels: - anaconda - conda-forge -
実行ファイル名の指定
source_directory で リモート実行するスクリプト一式がはいったフォルダ名を指定します。また script でリモート実行のエントリーとなるスクリプトファイル名を指定します。
リモート実行では source_directory 内のファイル、サブディレクトリ全てが コンテナに渡されるので、不要なファイルは配置しないように注意します。
前回まではデータセットの受け渡しにおいて Azure ML Python SDK 特有の方法を紹介しましたが、今回は arguments で指定した引数を argparse で受け取る方法に沿って記述します。
引数名 datadir で input_data を、引数名 output で output を渡します。
また compute_target でコンピューティングクラスター名を指定し、environment で Environment をインスタンス化した myenv を渡しています。src = ScriptRunConfig(source_directory='script_folder2', script='script2.py', arguments =['--datadir', input_data, '--output', output], compute_target=aml_compute, environment=myenv, docker_runtime_config=docker_config) -
実験の実行
スクリプトを実行します。exp = Experiment(workspace, 'InOutSample') run = exp.submit(config=src)このセルは非同期に終了するので、実行の終了を待つ場合は 次のステートメントを実行します。
%%time run.wait_for_completion(show_output=True) -
script2.py
リモート実行されるスクリプトの中身です。
parser を用いて datadir と output の引数を取り出すことができます。args.datadir にはインプットファイルへのフルパスが渡されます。いっぽう args.output にはフォルダ名までしか渡ってきていないので、os.path.join を使ってファイル名 output.csv をここで指定しています。import argparse import os print("*********************************************************") print("************* Hello World! *************") print("*********************************************************") parser = argparse.ArgumentParser() parser.add_argument('--datadir', type=str, help="data directory") parser.add_argument('--output', type=str, help="output") args = parser.parse_args() print("Argument 1: %s" % args.datadir) print("Argument 2: %s" % args.output) with open(args.datadir, 'r') as f: content = f.read() with open(os.path.join(args.output, 'output.csv'), 'w') as fw: fw.write(content)
おわりに
いかがでしょうか。今回はアウトプットを任意の blob storage に書きだす方法を紹介しました。
またインプットファイルの指定に File.from_files() を使い、コンテナ環境の指定には Environment() を使った点が前回までと異なっていました。
次回は File.from_files() でフォルダを指定するバリエーションを紹介します。
参考資料
Azure Machine Learning SDK for Python とは
Azure/MachineLearningNotebooks: scriptrun-with-data-input-output
azureml.data.OutputFileDatasetConfig class - Microsoft Docs
azureml.core.Environment class - Microsoft Docs
Azure ML Python SDK を使う1:データセットをインプットとして使う - その1
Azure ML Python SDK を使う2:データセットをインプットとして使う - その2
Azure ML Python SDK を使う4:アウトプットを Blob ストレージに書きだす - その2
Azure ML Python SDK を使う5:パイプラインの基本