#今回の内容
Azure ML Python SDK を使う:データセットをインプットとして使う - その1 ではインプットデータセットはスクリプト script.py を呼出す側で指定しました。
Azure Machine Learning Workspace ではデータセットを登録(Register)することができるので、script.py の中で勝手に取出して使わせたいと考えるのは自然だと思います。
今回はその方法について紹介します。
#登場アイテム
今回登場するアイテムは次のとおり。
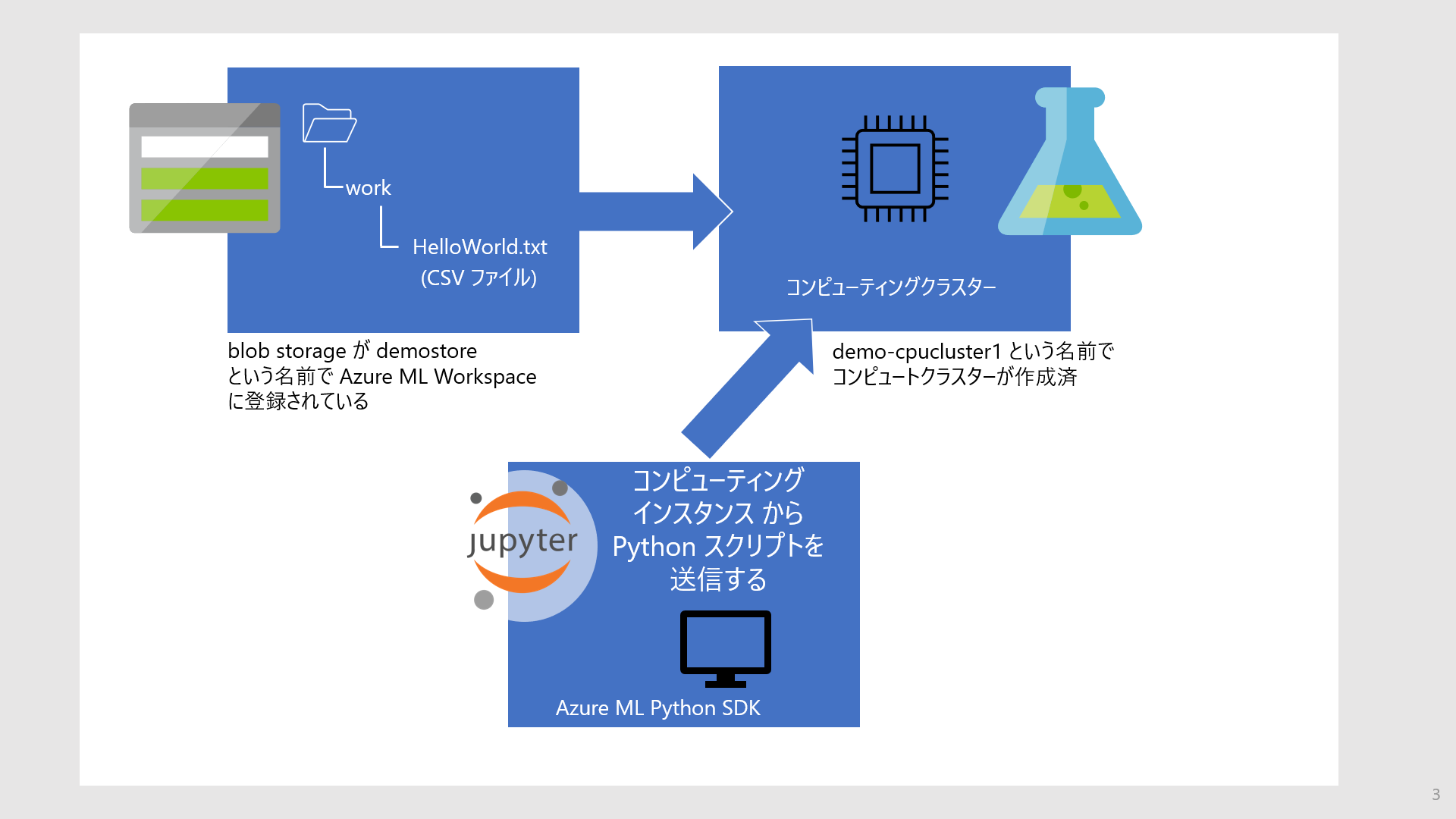
- CSVファイル(運用を意識して Azure Blob Storage に配置されていると仮定)
- ここで CSV ファイルは Azure Machine Learning Studio UI で登録済とする
- リモート仮想マシン(以降 Azure ML の用語を用いて "コンピューティングクラスター")
- Jupyter Notebook
- Azure Machine Learning Studio のコンピューティングインスタンスから起動したもの
前回は Jupyter Notebook ではなくローカル PC( Visual Studio Code, Azure ML Python SDKがインストール済)としていましたが、リモートのコンピューティングクラスターをスクリプト実行に使うという観点でどちらも同じになります。Azure Machine Learning Studio のコンピューティングインスタンスから起動する Jupyter Notebook は、コンピューティングインスタンスを再作成することで最新の Azure ML Python SDK version を利用することができるので便利です。ここでは カーネルとして Python 3.8 - AzureML を、Azure ML Python SDK として 1.33.0 を使っています。
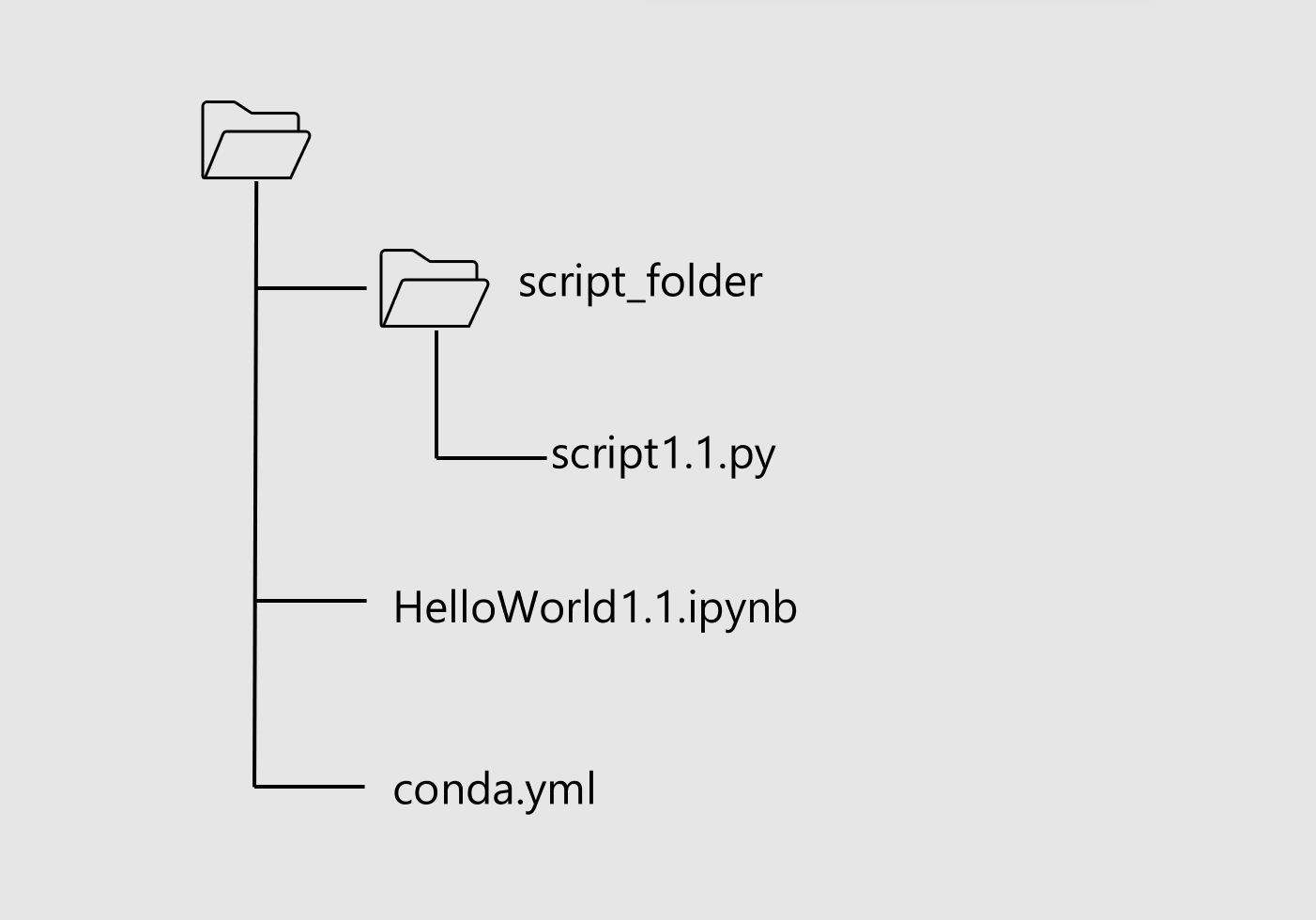
Notebook のフォルダー構造は次のようになっている前提で記述します。Azure ML Workspace 環境内なので config.json は考慮する必要はありません。
今回の例でも script1.1.py は blob Storage 上の CSV ファイルを Read して outputs ディレクトリに書きだすだけの簡単な内容です。
同様に script1.1.py をコンピューティングクラスターに送りこんで実行させるのが HelloWorld1.1.ipynb の役目になります。
HelloWorld1.1.ipynb の手順は以下のとおり。前回と違って Blob Storage 上の CSV ファイルパスを指定するステップがありません。
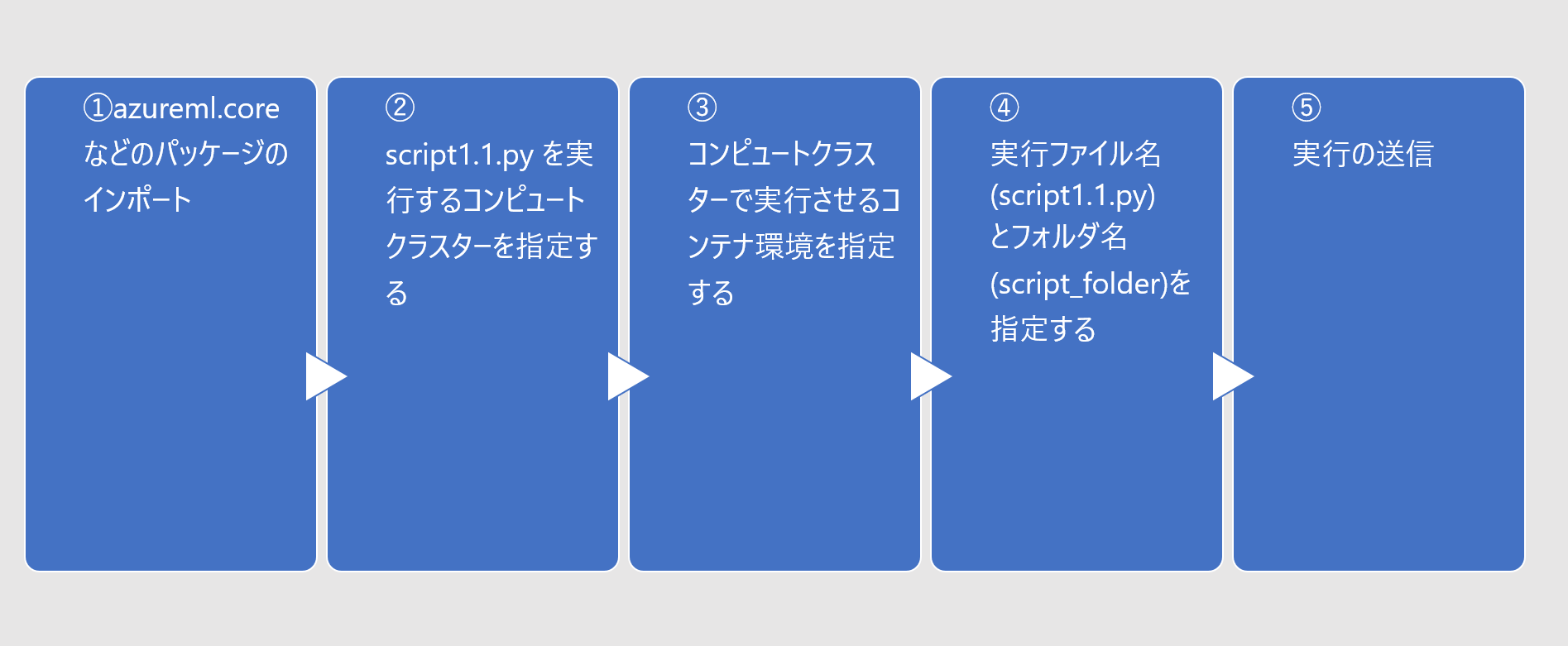
手順
順番に手順をみていきます。
-
パッケージの読込み
まずパッケージを読込みます。from azureml.core import Workspace, Experiment, Dataset, Datastore, ScriptRunConfig, Environment from azureml.core.compute import ComputeTarget from azureml.core.compute_target import ComputeTargetException from azureml.core.conda_dependencies import CondaDependencies from azureml.core.runconfig import DockerConfiguration workspace = Workspace.from_config() -
コンピューティングクラスターの指定
Python SDK でリモートコンピュートリソースを作成することもできますが、ここでは全体の見通しがよくなるように事前にAzure ML Studo ワークスペースでコンピューティングクラスターを作成しておきました。aml_compute_target = "demo-cpucluster" # <== The name of the cluster being used try: aml_compute = ComputeTarget(workspace, aml_compute_target) print("found existing compute target.") except ComputeTargetException: print("no compute target with the specified name found") -
環境の指定
ここでは実行環境を指定します。環境名に myenv を指定し、その環境(コンテナイメージ)で使用するパッケージを指定します。myenv = Environment.from_conda_specification(name="my-env", file_path="conda.yml") docker_config = DockerConfiguration(use_docker=True)conda.yml はノートブックと同じフォルダに配置されているものとします。
name: my-env dependencies: - python=3.8.5 - pip: - azureml-defaults - pandas==1.1.4 channels: - anaconda - conda-forge -
実行ファイル名の指定
script_folder1 で リモート実行するスクリプト一式がはいったフォルダ名を指定します。また script でリモート実行のエントリーとなるスクリプトファイル名を指定します。
リモート実行では script_folder1 内のファイル、サブディレクトリ全てが コンテナに渡されるので、不要なファイルは配置しないように注意します。
インプットファイルは script1.1.py で取出されるのでここでは指定がありません。src = ScriptRunConfig(source_directory='script_folder1', script='script1.1.py', compute_target=aml_compute, environment=myenv, docker_runtime_config=docker_config) -
実験の実行
experiment_name は実験の表示名として使われます。experiment_name = 'ScriptRunConfig2' experiment = Experiment(workspace = workspace, name = experiment_name) run = experiment.submit(config=src) runこのセルは非同期に終了するので、実行の終了を待つ場合は 次のステートメントを実行しておきましょう。
%%time run.wait_for_completion(show_output=True) -
script1.1.py
リモート実行されるスクリプトの中身です。
get_context() によって呼び出し側スクリプトの実行情報が渡されます。この run の中の属性情報である experiment 情報を取出し、さらに experiment の属性情報である workspace 情報を取出します。workspace 情報が分れば当該 workspace に登録されているデータセットを get_by_name で入手することができます。この get_by_name の書き方は Azure Machine Learning Studio の登録済データセットから "使用する" タブで現れる書式と同じです。
このスクリプトは最後に outputs フォルダにファイルを書きだします。この outputs フォルダは既定で何もしなくても作成され、実行後に実験の 「出力とログ」 から参照することができます。from azureml.core import Run, Dataset, Workspace run = Run.get_context() exp = run.experiment workspace = exp.workspace dataset = Dataset.get_by_name(workspace, name='hello_ds') df = dataset.to_pandas_dataframe() HelloWorld = df.iloc[0,1] print('*******************************') print('********* ' + HelloWorld + ' *********') print('*******************************') df.to_csv('./outputs/HelloWorld.csv', mode='w', index=False) -
[参考] HelloWorld.txt の中身
ここで使った CSV ファイルは簡単な内容です。0,Hello World 1,Hello World 2,Hello World
おわりに
いかがでしょうか。Azure ML Python SDK の input/output にはいくつかのバリエーションがあります。次回はアウトプットについてご紹介したいと思います。
参考資料
Azure Machine Learning SDK for Python とは
azureml.core.experiment.Experiment class - Microsoft Docs
Azure ML Python SDK を使う1:データセットをインプットとして使う - その1
Azure ML Python SDK を使う3:アウトプットを Blob ストレージに書きだす - その1
Azure ML Python SDK を使う4:アウトプットを Blob ストレージに書きだす - その2
Azure ML Python SDK を使う5:パイプラインの基本