
Microsoft Ignite 2025 において発表された Microsoft Foundry は、モデル、ツール、そしてナレッジを 1 つのオープン システムに統合し、組織がビジネス全体で高性能なエージェント フリートとインテリジェントなワークフローを実行できるようにします。
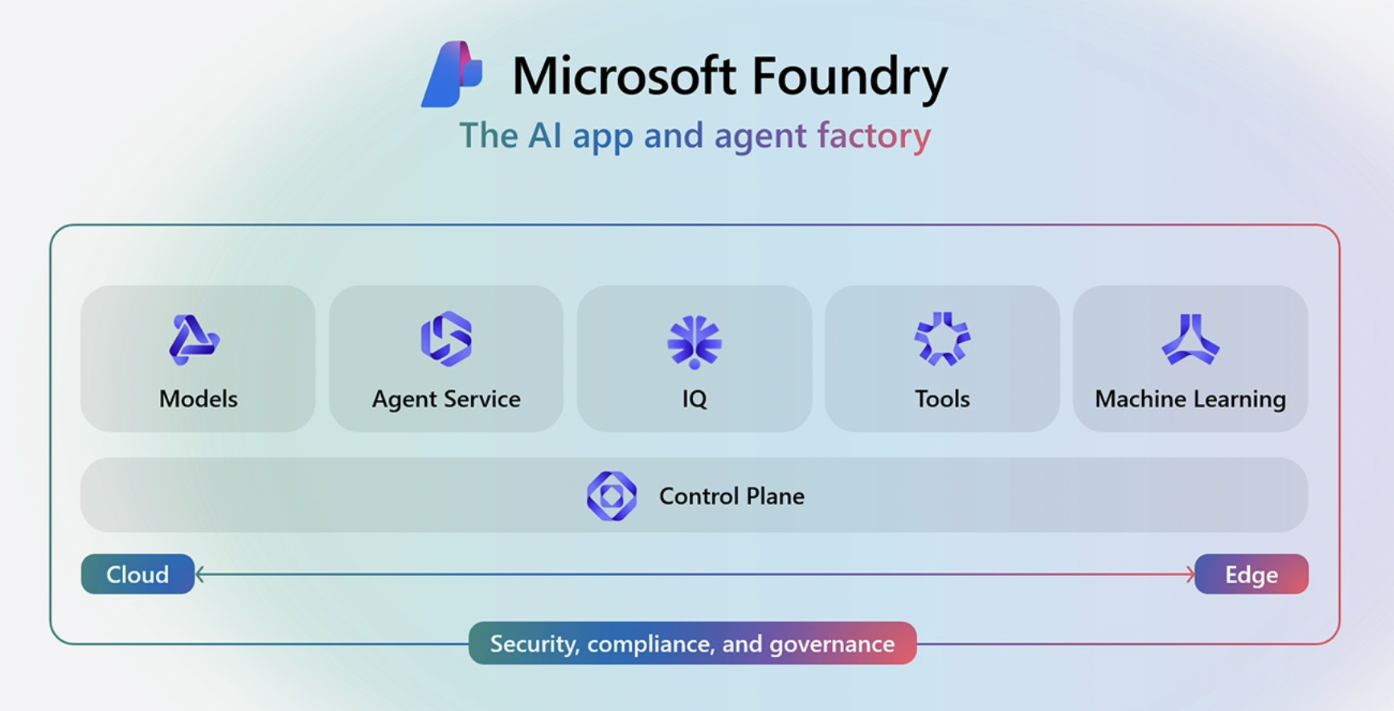
その Microsoft Foundry の 統合ナレッジレイヤーを担当するのが Foundry IQ であり、Azure AI Search を基盤としてすべてのエージェントにエンタープライズ コンテキストを提供する役割を持っています。いいニュースですね!新しい Microsoft Foundry のコンテキストエンジニアリング基盤の要素の一つとして位置づけられたということです!

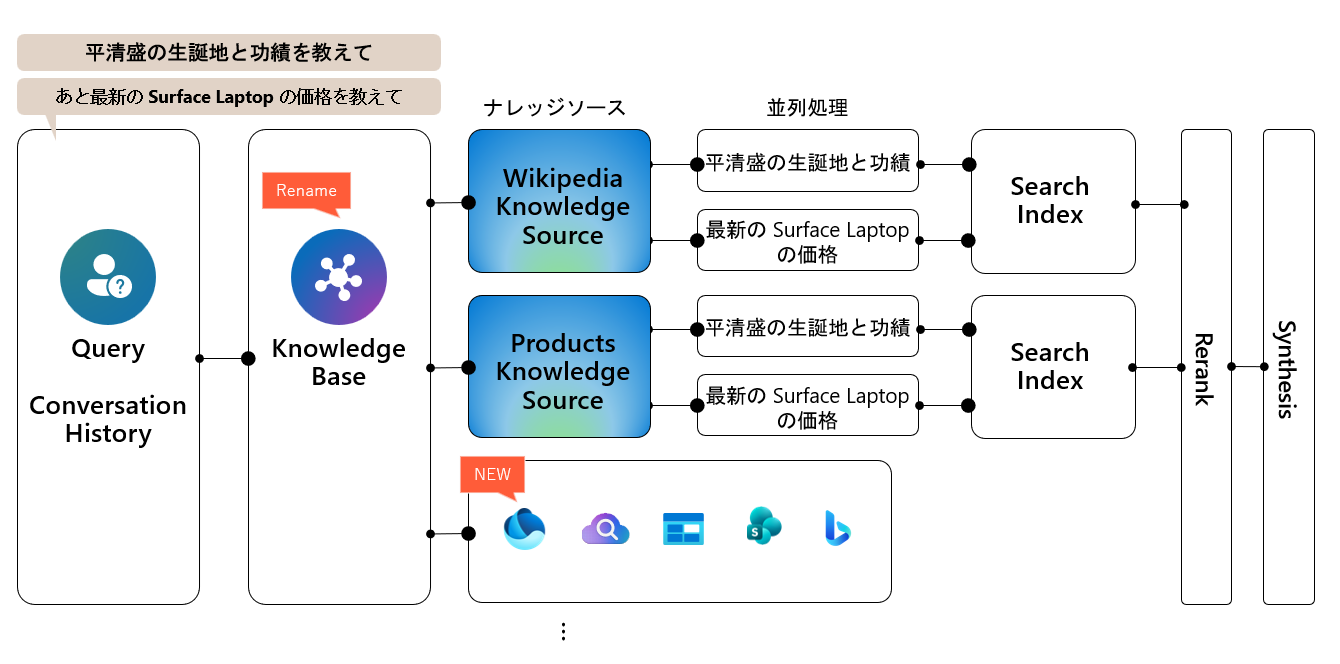
新しい Azure AI Search では、Agentic retrieval 機能がさらにアップデートされました。単一のエントリポイントですべてのコンテンツを検索、Web グラウンディングなどのフェデレーションソースへのアクセスによるプライベートデータの補完、セルフリフレクション検索、レイテンシと品質のトレードオフ制御、高品質な回答出力といった機能を提供します。開発者は単一のナレッジベースを「スーパーツール」として構成・登録することで、エージェントが様々なナレッジソースにアクセスできるようになります。これにより、エージェント開発の複雑さが大幅に軽減され、ナレッジの取得(ナレッジベース)とナレッジの利用(エージェント)という2つの課題を分離することが可能になります。

セルフリフレクション検索では、取得された結果の品質がクエリへの回答として不十分な場合は、修正されたクエリプランを使用して、追加の反復処理が実行されます。この新しいエージェント検索で応答関連性を 36% 向上したという Microsoft の調査結果も発表されています。
Azure AI Search 新機能
- Foundry IQ ナレッジベース(旧ナレッジエージェント):新しい Foundry ポータルから直接利用できるナレッジベースは、トピック中心の再利用可能なコレクションで、複数のエージェントとアプリケーションを単一の API で統合できます。エージェントの構築が簡素化され、プロジェクトごとに複雑なデータツールを組み込む必要がなくなります。
- インデックス化および統合されたナレッジソースへの自動アクセス:インデックス化されたナレッジソースとリモートナレッジソースの両方に接続することで、エージェントがアクセスできるデータの範囲を拡大します。インデックス化されたソースの場合、Foundry IQ はテキスト、画像、Web、複雑なドキュメントの自動インデックス作成、ベクトル化、エンリッチメントを実現します。
- ナレッジ ベースのエージェント検索エンジン: 構成可能な「検索推論努力」を使用して、AI を使用してソース全体の回答を計画、検索、および統合するセルフリフレクション型クエリ エンジン。
- エンタープライズ グレードのセキュリティとガバナンス ドキュメント レベルのアクセス制御、既存の権限モデルとの整合、インデックス データとリモート データの両方のオプションをサポートします。
その他の Updates
- Azure Content Understanding Skill (プレビュー)
- SharePoint インデクサー ACL サポート (プレビュー)
- ACL の昇格された読み取り権限 (プレビュー)
- ドキュメントレベルの機密ラベルのインデックス作成(プレビュー)
- SharePoint インデックスの更新 (プレビュー)
- スコアリング関数の集計(プレビュー)
- ファセット集計(プレビュー)
Foundry IQ ナレッジベース
Microsoft Foundry ポータル側で作成したナレッジベースは自動的に Azure AI Search 側にも反映されます。
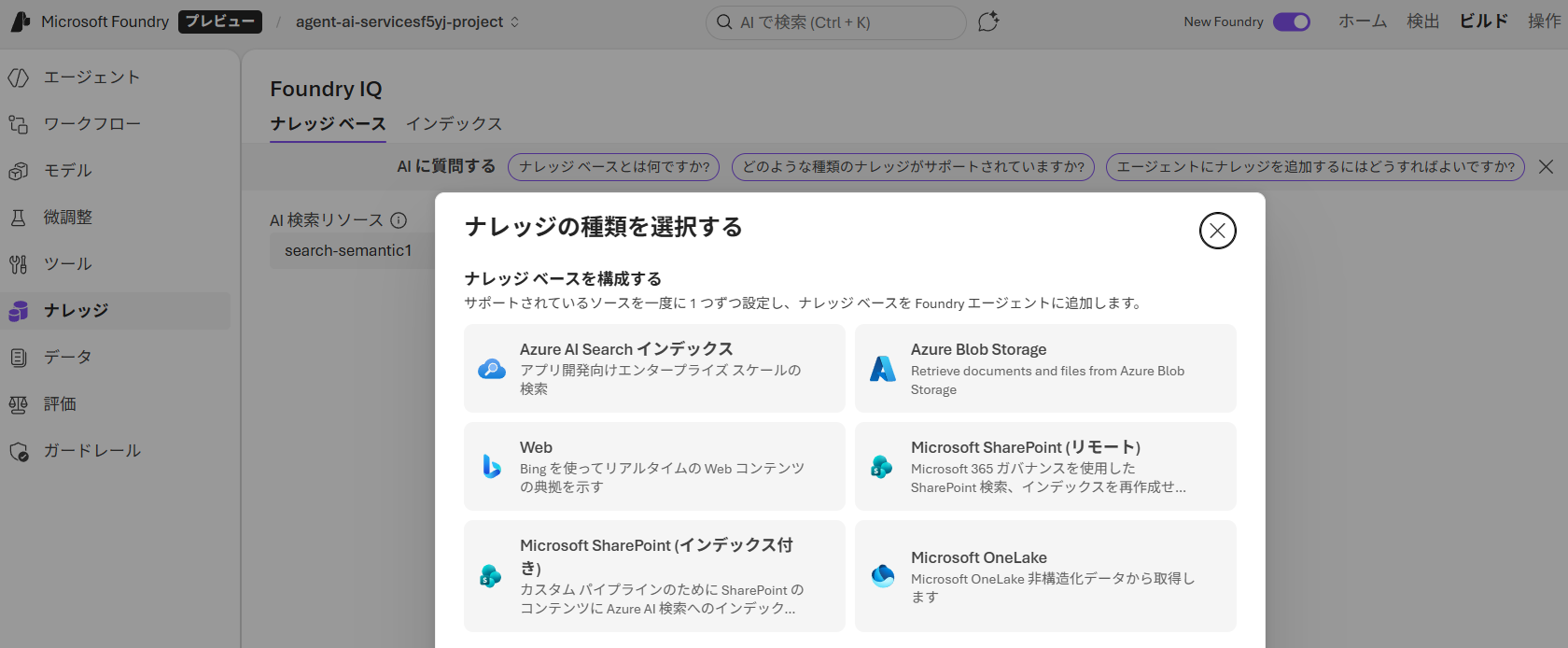
ナレッジベースはエージェントによる検索をオーケストレーションする最上位オブジェクトで、これまではナレッジエージェントと呼ばれていました。ナレッジベースは、クエリ対象となるナレッジソースと、検索操作のデフォルトの動作を定義します。クエリ実行時には、retrieve メソッドがナレッジベースをターゲットとして、構成された検索パイプラインを実行します。
ナレッジソースに追加可能なサービス

- Azure AI Search インデックス
- Azure Blob Storage
- Web(Grounding with Bing Search) ⭐
- Microsoft Sharepoint(リモート) ⭐
- Microsoft Sharepoint(インデックス付き) ⭐
- Microsoft OneLake ⭐
え、Web グラウンディングも Azure AI Search 側で行うの?!ちょっと驚きですね。これまでユーザーが独自で行っていたエージェント処理の領域を取り込んだと言えます。この時点で、もはや単なる検索エンジン+ベクトルデータベースの枠を超えて次世代 RAG 基盤、コンテキストエンジニアリング基盤に進化してしまったと言えるかもしれません…
= Foundry IQ
Foundry IQ 発表動画には MCP や Fabric IQ の表示もあり、さらなる拡張が期待されます。

ナレッジソースとしてモデルコンテキストプロトコル(MCP)を追加するプライベートプレビューはこちらから申し込むことができます。

Foundry IQ ナレッジベース設定画面
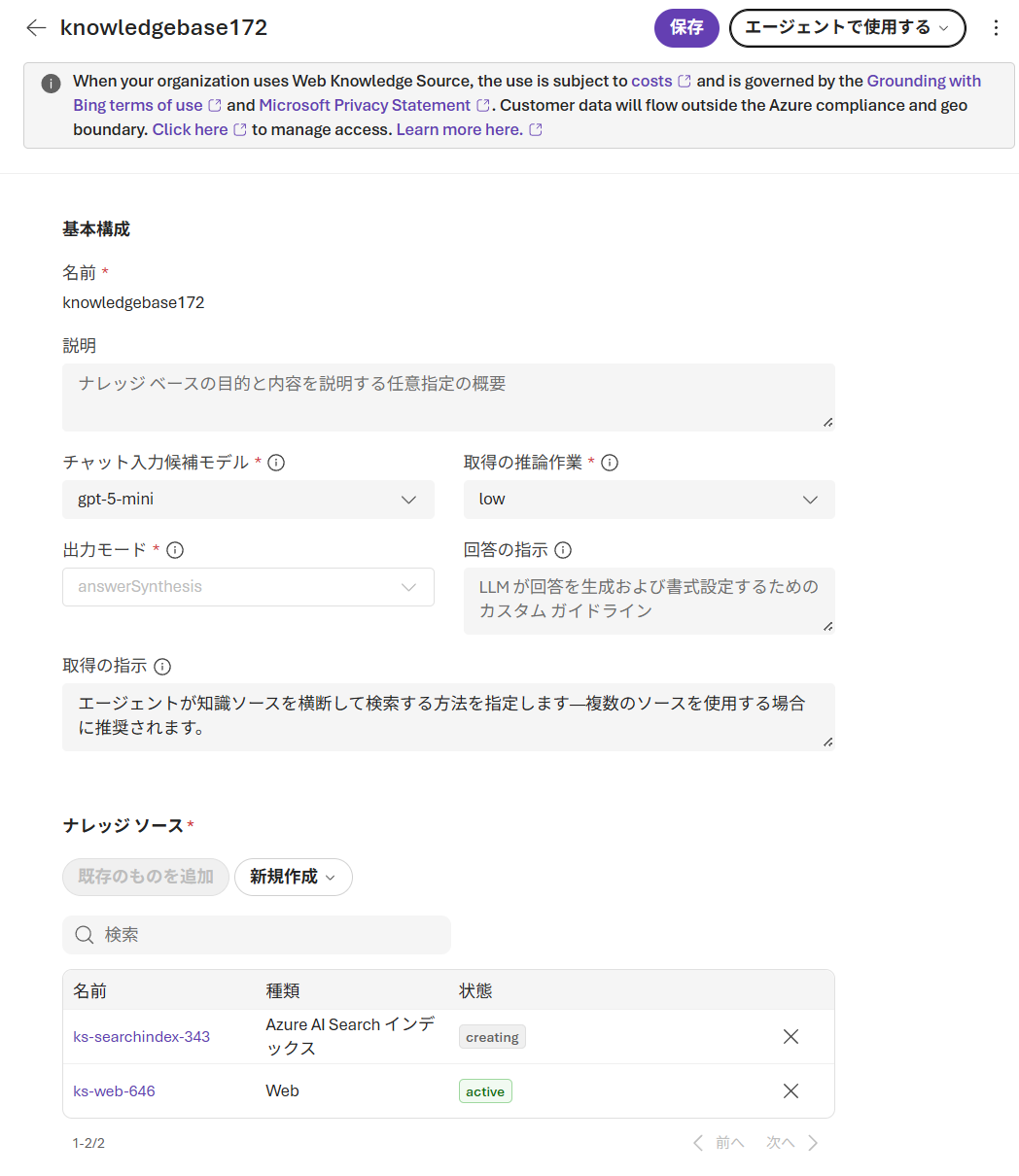
- 検索可能なコンテンツを指す 1 つ以上のナレッジ ソース
- クエリ計画と回答作成のための推論機能を提供するオプションの LLM
- LLM が呼び出されるかどうかを決定し、コスト、待ち時間、および品質を管理する検索推論努力を設定
- ルーティング、ソース選択、出力形式、オブジェクトの暗号化を制御するカスタム プロパティ
Azure AI Search ポータル画面
Azure Portal の Azure AI Search リソースメニューから「ナレッジソース」および「ナレッジベース」の設定ができるようになりました。ナレッジベースの Agentic retrieval をすぐに試せるプレイグラウンド機能も搭載されています。
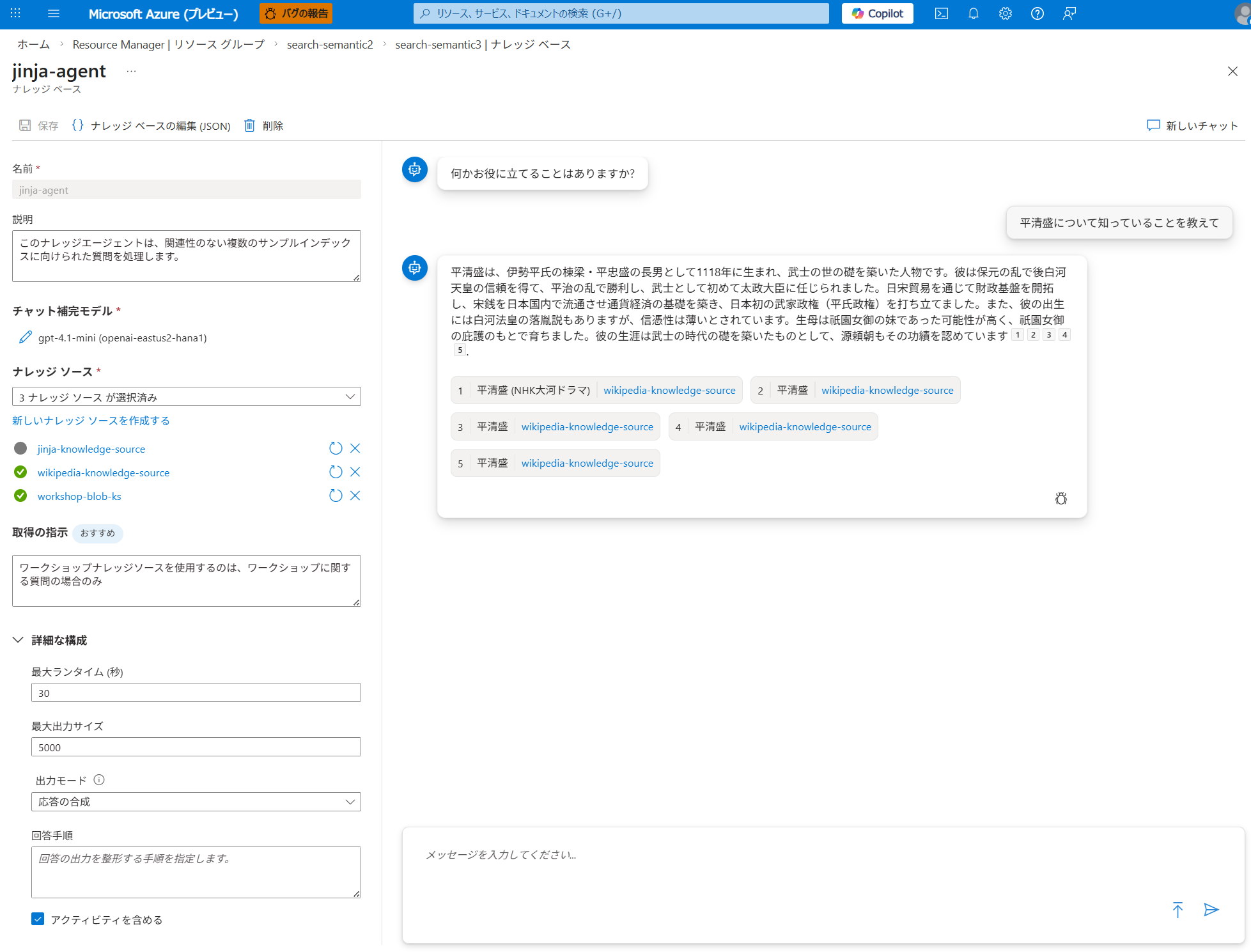
検索推論努力
Agentic Retrieval では、クエリプランニングと回答作成のための大規模言語モデル(LLM)処理のレベルを指定できます。この retrievalReasoningEffort プロパティを使用して、LLM 処理レベルを決定します。このプロパティは、ナレッジベースまたは検索リクエストで設定できます。
- minimal: LLM 処理なし
- low: LLM ベースのクエリプランニングとナレッジソース選択を 1 パス実行(既定)
- medium: Agentic Retrieval にさらに詳細な検索と強化された検索スタックを追加して、完全性を最大限に高めます。取得された結果の品質がクエリへの回答として不十分な場合は、修正されたクエリプランを使用して、追加の反復処理が実行されます。この修正されたクエリプランでは、クエリの調整、用語の拡張、Web などのソースの追加などにより、既に実行されたクエリと取得されたドキュメントが考慮されます。
検索推論努力レベルごとの検索パイプライン実行 ON/OFF 表

クエリプランニングとリフレクティブ検索を備えたナレッジベースは、すべてのナレッジソースを直接検索するよりも 36% の効率向上
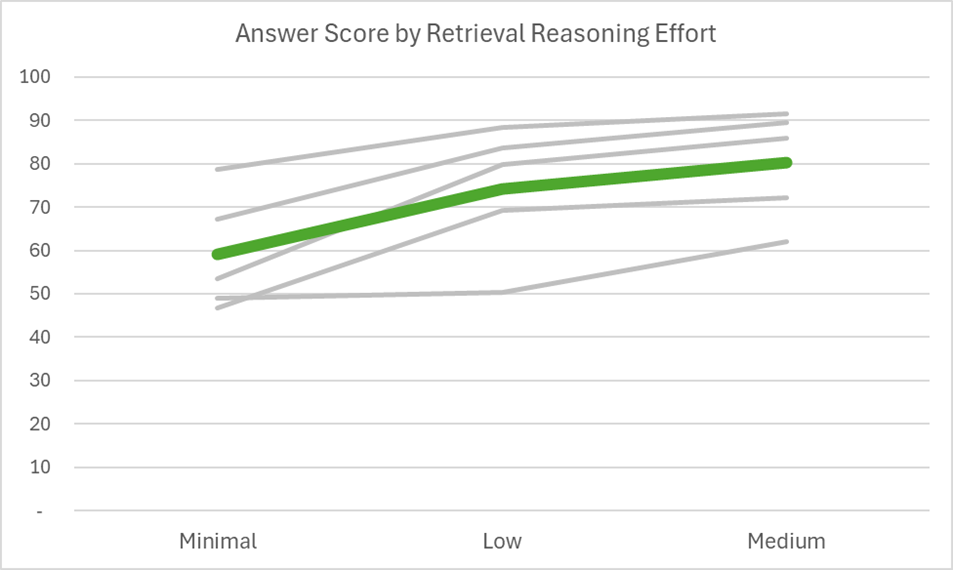
図1:5つの異なるデータセットにおける、検索推論努力レベルごとの回答スコア。太い緑の線は平均パフォーマンスです。
複数(最大 10 個)のナレッジソースを含むナレッジベースを設定し、推論の試行ごとに難しいクエリを実行すると、レベルごとにパフォーマンスが向上することがわかりました。
-
minimal : 全てのナレッジ ソースに対して、呼び出し元クエリを並列に実行します。コンテンツ出力は 5,000 トークンのバジェットで実行し、オーバーリトリーバル推論の取り組みと同じ回答生成ステップを追加しました。Minimal は現在回答生成をサポートしていないことに注意。
low: 入力クエリをクエリプランニングとソース選択にかけ、複数のナレッジソースにフェデレーションします。Low では、5000 トークンの回答生成バジェットを使用します。 - medium: 入力クエリをクエリプランニングとソース選択にかけ、複数のナレッジソースに統合し、最大1回のリフレクティブフォローアップ検索を可能にします。Medium では、10,000 件の回答生成バジェットを使用します。
クエリプランニングを minimal から low まで追加することで大幅に効果が得られ、リフレクション検索により、low から minimal までパフォーマンスがさらに向上します。これらの改善はすべてのデータセットで明らかであり、平均で 36% の向上が見られます。
新機能 Reflection:反復検索による日本語 RAG の精度向上
新しいナレッジソース
インデックス化された SharePoint
インデックス化された SharePoint ナレッジソースを使用して、エージェントによる検索パイプラインでSharePoint コンテンツのインデックス作成とクエリを実行します。ナレッジソースは独立して作成され、ナレッジベースで参照され、エージェントまたはチャットボットがクエリ実行時に検索アクションを呼び出す際のグラウンディングデータとして使用されます。
リモート SharePoint
リモート SharePoint ナレッジソースは、Copilot Retrieval API を使用して Microsoft 365 の SharePoint から直接テキストコンテンツをクエリし、結果をエージェント検索エンジンに返してマージ、ランク付け、および応答の作成を行います。このナレッジソースでは検索インデックスは使用されず、テキストコンテンツのみがクエリされます。
クエリ実行時に、リモート SharePoint ナレッジ ソースはユーザー ID に代わって Copilot Retrieval API を呼び出すため、ナレッジ ソース定義に接続文字列は必要ありません。ユーザーがアクセスできるすべてのコンテンツがナレッジ取得の対象となります。サイトを制限したり、検索を制約したりするには、フィルター式を設定します。Azure テナントと Microsoft 365 テナントは同じ Microsoft Entra ID テナントを使用する必要があり、呼び出し元の ID は両方のテナントで認識される必要があります。
Web(Grounding with Bing Search)
Web Knowledge Sourceは、エージェントによる検索パイプラインで Microsoft Bing からリアルタイムの Web データを取得できるようにします。ナレッジソースは独立して作成され、ナレッジベース内で参照され、エージェントまたはチャットボットがクエリ時に取得アクションを呼び出す際のグラウンディングデータとして使用されます。
Web Knowledge Source の検索プロバイダーは常に Bing Custom Search です。別の検索プロバイダーやエンジンを指定することはできませんが、https://learn.microsoft.com などの特定のドメインを追加または除外することは可能です。ドメインを指定しない場合、Web Knowledge Source はパブリックインターネット全体に無制限にアクセスできます。
Microsoft OneLake
OneLakeナレッジソースを使用して、エージェントによる検索パイプラインでMicrosoft OneLakeファイルのインデックス作成とクエリを実行します。ナレッジソースは独立して作成され、ナレッジベースで参照され、エージェントまたはチャットボットがクエリ実行時に検索アクションを呼び出す際のグラウンディングデータとして使用されます。
OneLake ナレッジ ソースを作成するときは、外部データ ソース、モデル、プロパティを指定して、次の Azure AI Search オブジェクトを自動的に生成します。
その他の Updates
Azure Content Understanding Skill (プレビュー)
Azure Content Understanding スキルは、Foundry Tools の Azure Content Understanding のドキュメント アナライザーを使用して、非構造化ドキュメントやその他のコンテンツ タイプを分析し、自動化ワークロードに統合可能な、整理された検索可能な出力を生成します。
SharePoint インデクサー ACL サポート (プレビュー)
Azure AI Search インデクサーを使用して、Microsoft 365 の SharePoint からアクセス制御リスト (ACL) を他のコンテンツと共に取り込むことができます。SharePoint からの権限は、インデックス付けされた各ドキュメントの権限メタデータとして保持されます。ユーザーが SharePoint のコンテンツを含むインデックスに対してクエリを実行すると、検索結果には、ユーザーがアクセス権限を持つドキュメントのみが表示されます。
完全な SharePoint 権限モデル、機密ラベル、そしてすぐに使えるセキュリティトリミングを必要とするシナリオでは、リモート SharePoint ナレッジソースを使用してください。このアプローチでは、Copilot retrieval API を介して SharePoint を直接呼び出すため、ガバナンスは完全に SharePoint 内に維持され、クエリ結果は適用可能なすべての権限とラベルを自動的に反映します。
ACL の昇格された読み取り権限 (プレビュー)
ドキュメント アクセス制御で使用される ACL 構成の問題を調査するために、管理者に昇格された読み取り権限を割り当てる新しい機能が追加されました。
ドキュメントレベルの機密ラベルのインデックス作成(プレビュー)
Azure AI Search は、インデックス作成時にドキュメントレベルで Microsoft Purview の機密ラベルを自動抽出し、クエリ実行時にラベルベースのアクセス制御を適用する機能をサポートするようになりました。パブリックプレビューで利用可能なこの機能により、組織は検索エクスペリエンスを Microsoft Purview で定義されている既存の情報保護ポリシーに適合させることができます。
Azure AI Search は、機密ラベルインデックスを使用して、各ドキュメントの機密レベルを表すメタデータを抽出し、保存します。また、ラベルベースのアクセス制御を適用することで、承認されたユーザーのみが検索結果でラベル付きコンテンツを表示または取得できるようにします。
SharePoint インデックスの更新 (プレビュー)
SharePoint インデクサーに改善された認証オプション、増分更新、ドキュメント権限の基本的な処理などが追加されました。
スコアリング関数の集計(プレビュー)
複数のスコアリング関数を組み合わせて集約する新しい機能により、より洗練された関連性のカスタマイズと重み付けされたシグナルの組み合わせが可能になります。
ファセット集計(プレビュー)
最小値、最大値、平均値、カーディナリティなどの新しいファセット集計操作により、ファセット検索エクスペリエンスにおける分析が強化されます。
おまけ
● ● ● ● ●
● ● ● ● ● ● ●
● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ● ●
● ● ● ● ● ● ● ● ● ●
参考