Azure AI Search の新機能 Agentic retrieval では、新しくナレッジソースを追加できるようになり、LLM が検索対象のインデックスを自律的に選べるようになりました。さらに、LLM を活用した回答合成機能も利用できるようになっています。これにより、エージェントは複数のインデックスにまたがって情報をグラウンディングし、引用付きの回答を生成できるようになりました。
Agentic retrieval Updates
-
Knowledge agents(ナレッジ エージェント、プレビュー)
ナレッジエージェント定義のアーキテクチャ変更により、ターゲットインデックスの代わりに1つ以上のナレッジソースが必要となり、defaultMaxDocsForRerankerは非推奨となりました。新しいretrieval_instructionsおよびoutput_configurationプロパティにより、クエリ計画と実行の制御性が向上しました。 -
Knowledge sources(ナレッジ ソース、プレビュー)
ナレッジエージェントがクエリの作成と回答に使用するコンテンツを表します。このプレビューでは、検索インデックスと Azure Blob のナレッジ ソースを作成できます。 -
Answer synthesis(回答合成、プレビュー)
検索結果をもとに、LLM が自然言語の回答を生成します。 -
Fast path(ナレッジ エージェントの高速パス、プレビュー)
クエリが簡潔で、最初の応答が十分に関連している場合は処理時間を短縮できます。 -
Retrieval instructions(取得手順、プレビュー)
エージェント検索ワークフローでのクエリ計画をガイドします。 たとえば、特定のナレッジ ソースを含めたり除外したりするための条件を指定できます。
Other Updates
-
インデクサーランタイム追跡情報の改善 (プレビュー)
Standard 3 High Density (S3 HD) サービスにのみ適用されます。 Get Service Statistics 応答で、サービス全体の累積インデクサー処理情報が提供されるようになりました。 -
ベクトルクエリの厳密なポストフィルター処理 (プレビュー)
vectorFilterModeプロパティに新しいstrictPostFilterモードが追加。指定するとグローバルトップk ベクター結果が識別された後にフィルターが適用され、返されるドキュメントがフィルター処理されていない結果のサブセットであることを確認します。 -
ベクトルフィールドの最大次元の増加
ベクトルフィールドあたりの最大次元が4096に。
新 Agentic retrieval 処理フロー
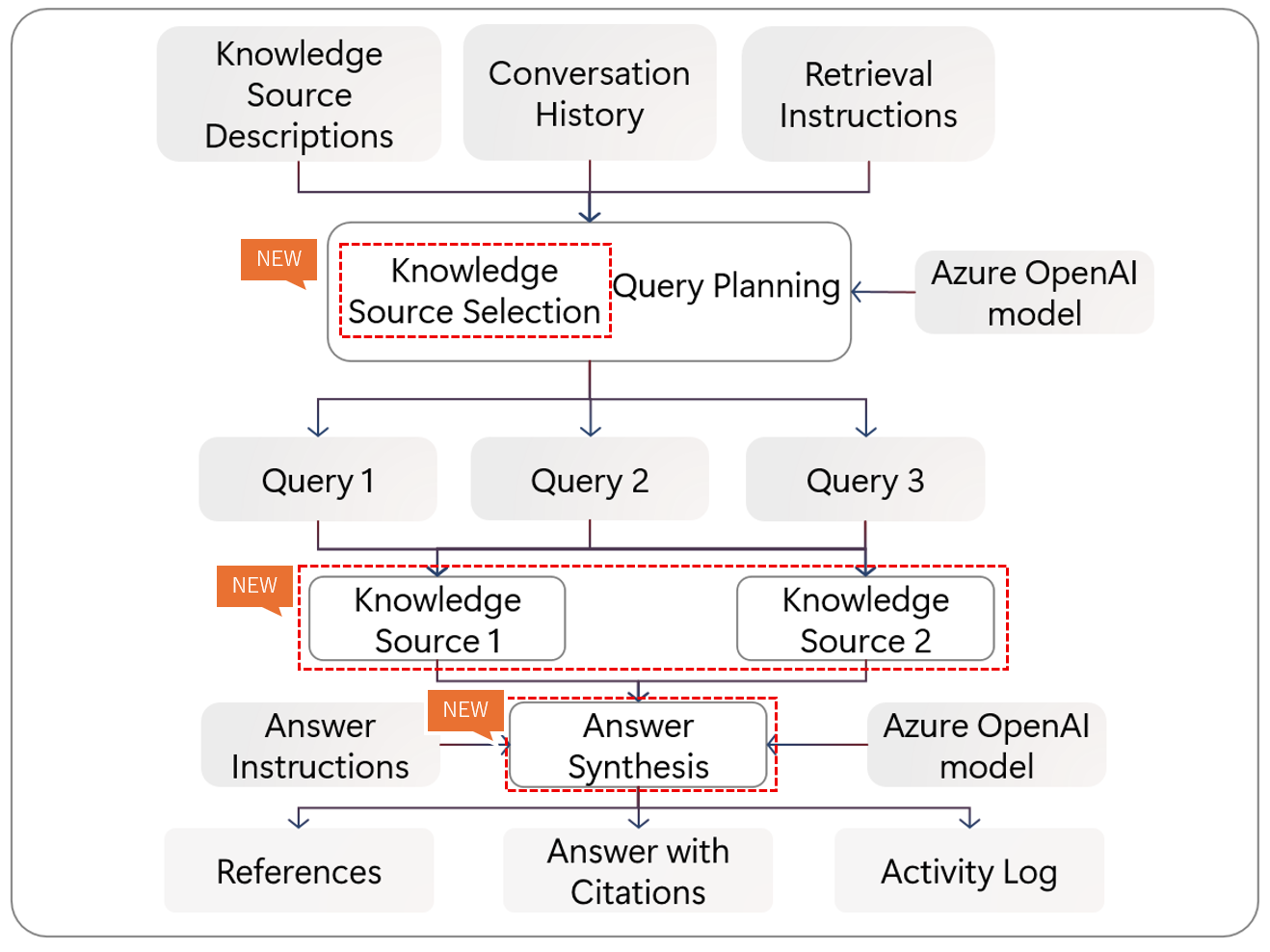
LLM はナレッジソース選定・クエリ計画および回答生成のために2回呼ばれるようになりました。ナレッジソースのレイヤーがインデックスの上位に追加され、ナレッジソースごとにサブクエリを並列実行するようになりました。
新機能ウォークスルー
新機能は REST API か azure-search-documents==11.7.0b1 で利用することができます。
pip install azure-search-documents==11.7.0b1
Agentic retrieval の前提条件
1. ナレッジソースの作成
この手順では、以前に作成したインデックスを対象とするナレッジソースを作成します。次の手順では、ナレッジソースを使用してエージェント型検索を調整するナレッジエージェントを作成します。
ナレッジソースは、エージェント検索用の追加のプロパティで検索インデックスをラップします。 ナレッジエージェントの作成に必要な定義です。通常、次の手順で作成します。
-
検索サービスで最上位レベルのリソースとして複数のナレッジソースを作成します
-
ナレッジエージェント内の 1 つ以上のナレッジソースを参照します。エージェント検索パイプラインでは、1 つの要求で複数のナレッジソースに対してクエリを実行できます。サブクエリは、ナレッジソースごとに生成されます。上位の結果が取得応答で返されます。
from azure.search.documents.indexes.models import SearchIndexKnowledgeSource, SearchIndexKnowledgeSourceParameters
index_name="wikipedia-index" # 既存のインデックス名を指定
knowledge_source_name = "wikipedia-knowledge-source"
# Search Indexをナレッジソースとして使用
search_index_params = SearchIndexKnowledgeSourceParameters(
search_index_name=index_name # 既存のインデックス名を指定。必須
)
knowledge_source = SearchIndexKnowledgeSource(
name=knowledge_source_name,
search_index_parameters=search_index_params, #ナレッジソースのパラメータ。必須。
description="Wikipedia のナレッジソース"
)
try:
# Knowledge Source の作成・アップデート
search_client.create_or_update_knowledge_source(knowledge_source=knowledge_source, api_version=search_api_version)
print(f"Knowledge Source '{knowledge_source.name}' を作成しました")
# Knowledge Source の作成のみ
# created_source = search_client.create_knowledge_source(knowledge_source)
# print(f"Knowledge Source '{created_source.name}' を作成しました")
except Exception as e:
print(f"Knowledge Source の作成中にエラーが発生しました: {e}")
print(f"エラーの種類: {type(e).__name__}")
検索したいインデックスごとにナレッジソースを作成します。
ナレッジソースの種類
既存の検索インデックスまたは Azure Blob Storage コンテナを使用してナレッジソースを作成できます。Blob ナレッジソースは統合ベクトル化を利用し、マルチモーダルコンテンツを自動的にチャンク化およびベクトル化した後、新しい検索インデックス内に保存する完全なインデックス作成パイプラインを自動生成します。ナレッジソースは一度定義すれば、複数の異なるエージェントが基盤として利用できます。

Blob ナレッジソースの作成(オプション)
2. ナレッジエージェントの作成
このステップでは、ナレッジソースと LLM デプロイメントをラッパーとして扱うナレッジエージェントを作成します。
Azure AI Search では、 ナレッジエージェントは、Agentic retrieval ワークロードで使用するチャット完了モデルへの接続を表す最上位レベルのリソースです。 ナレッジエージェントは、LLM を利用した情報取得パイプラインの retrieve メソッド によって使用されます。
ナレッジ エージェントによって次のものが指定されます。
- 検索可能なコンテンツを指すナレッジ ソース (1 つ以上)
- クエリの計画と回答の定式化のための推論機能を提供するチャット完了モデル
- パフォーマンス最適化のプロパティ (クエリ処理時間の制約)
ナレッジ エージェントを作成した後は、いつでもそのプロパティを更新できます。 ナレッジ エージェントが使用中の場合、更新は次のジョブで有効になります。
knowledge_agent_name = "wikipedia-agent"
# 正しいAzure OpenAIモデルの設定
openai_params = AzureOpenAIVectorizerParameters(
resource_url=AZURE_OPENAI_ENDPOINT,
deployment_name="gpt-4.1-mini", # サポートされているモデル名に変更
api_key=AZURE_OPENAI_API_KEY,
model_name="gpt-4.1-mini"
)
# Knowledge Agent モデルの設定
agent_model = KnowledgeAgentAzureOpenAIModel(
azure_open_ai_parameters=openai_params
)
# Knowledge Source の参照
knowledge_source_ref = KnowledgeSourceReference(
name=knowledge_source_name,
)
# 2つ目の Knowledge Source の参照
knowledge_source_ref2 = KnowledgeSourceReference(
name="products-knowledge-source", # 既存のKnowledge Source名を指定
# reranker_threshold=2.5, # このソースの再ランク付けのしきい値を設定します。 これをセットすると modelQueryPlanning が走ります
# always_query_source=True, #このナレッジソースはソース選択をバイパスし、検索時に常に照会されるべきであることを示します。特定のナレッジ ソースで attempt_fast_path を使用している場合は、 always_query_source を true に設定する必要があります。
# include_references=False, #このソースから取得したデータに対して参照を含めるべきかを示す
# include_reference_source_data=False, #参照が、取得中に得られた構造化データをペイロードに含めるべきかを示す。
# max_sub_queries=5 # must be 2>= #このソースからデータを取得する際、同時に発行できるクエリの最大数。
)
# 出力設定
# Answer synthesis (preview)
output_config = KnowledgeAgentOutputConfiguration(
modality=KnowledgeAgentOutputConfigurationModality.ANSWER_SYNTHESIS,
# modality=KnowledgeAgentOutputConfigurationModality.EXTRACTIVE_DATA,
include_activity=True, # 検索結果にアクティビティ情報を含めるべきかを示します
attempt_fast_path=False, # 高速パスを試みる。エージェントがモデル呼び出しをバイパスし、最新のチャットメッセージをナレッジソースへの直接クエリとして発行を試みるべきかを示します。
# answer_instructions="" #ナレッジエージェントが回答生成時に考慮する指示。
)
# リクエスト制限設定
request_limits = KnowledgeAgentRequestLimits(
max_runtime_in_seconds=30,
max_output_size=5000
)
# Knowledge Agentの作成
agent = KnowledgeAgent(
name=knowledge_agent_name,
models=[agent_model],
knowledge_sources=[knowledge_source_ref, knowledge_source_ref2], #複数指定可
output_configuration=output_config,
request_limits=request_limits,
retrieval_instructions="質問に関する情報を検索し、適切な回答を提供してください。",
description="このナレッジエージェントは、関連性のない複数のサンプルインデックスに向けられた質問を処理します。"
)
# Knowledge Agentの作成・アップデート
try:
created_agent = search_client.create_or_update_agent(agent)
print(f"Knowledge Agent '{created_agent.name}' を作成しました")
except Exception as e:
print(f"エラー: {e}")
3. 新プロパティ解説
今回複数の新プロパティが追加されました。各プロパティはセットするクラスが異なるため注意してください。
3.1. Knowledge agents
ナレッジエージェント定義のアーキテクチャ変更により、targetIndexes の代わりに1つ以上の knowledge_sources が必要となり、defaultMaxDocsForReranker は非推奨となりました。新しい retrieval_instructions および output_configuration プロパティにより、クエリ計画と実行の制御性が向上しました。
3.2. Answer synthesis(回答合成)
既定では、Azure AI Search の ナレッジエージェントがデータ抽出を実行し、ナレッジソースから生のグラウンド チャンクを返します。データ抽出は特定の情報を取得するのに役立ちますが、複雑なクエリに必要なコンテキストと推論がありませんでした。
エージェントを構成して 回答合成を実行できます。この合成では、デプロイされたチャット完了モデルを使用して自然言語でクエリに回答します。各回答には、取得したソースへの引用が含まれており、箇条書きの使用など、指定した指示に従います。
-
ANSWER_SYNTHESIS: LLM が応答用の回答を生成する -
EXTRACTIVE_DATA: ナレッジソースから生成的な変更を加えずに直接データを返す。既存の機能。
3.3. Retrieval Instructions(取得手順)
複数のナレッジ ソースがある場合は、次のプロパティを設定して、クエリ計画を特定のナレッジソースに制限します。
-
always_query_source: クエリの計画に常に当該ナレッジソースが含まれます。既定値はFalse -
retrieval_instructions: 回答にナレッジソースを含めたり除外したりする指示を自然言語で記述します。例:「質問に関する情報を検索し、適切な回答を提供してください。製品ついての問い合わせには、製品ナレッジソースのみを使用してください。それ以外の場合は、Wikipedia ナレッジソースをご利用ください。」
always_query_source プロパティは、retrieval_instructions を上書きします。 取得手順を指定するときは、必ず always_query_source を False に設定する必要があります。

Agentic retrieval は、LLM を用いてチャットスレッド全体を分析し、会話の根底にある情報ニーズに最も関連性の高いナレッジソースを、その名称と説明から特定します。自然言語による検索指示を提供することで、エージェント型検索がナレッジソースを選択する際の考慮方法に影響を与えることが可能です。LLM クエリプランナーはこれらのナレッジソースを統合し、エージェント向けに最も関連性の高いコンテンツを取得するための集中的なクエリ計画を構築します。
3.4. Include Activity, References, ReferenceSourceData
検索結果の分析、チューニングに使えるデバッグ情報は以下を設定可能です。
-
クエリの実行と経過時間に関する分析情報を得るために、
include_activityをTrue(既定) に設定したままにします。(KnowledgeAgentOutputConfigurationクラス) -
個別にスコア付けされた各結果の詳細については、
include_references設定をTrue(既定) に保持します。(KnowledgeSourceReferenceクラス) -
インデックスの逐語的な内容が不要な場合は、
include_reference_source_dataをFalseに設定します。 この情報を省略すると、応答が簡略化され、読みやすくなります。(KnowledgeSourceReferenceクラス)
4. 結果の取得
このステップでは、エージェント型検索パイプラインを実行し、根拠に基づき引用付きで裏付けられた回答を生成します。会話履歴と検索パラメータに基づき、ナレッジエージェントは以下の処理を行います:
- 会話全体を分析し、ユーザーの情報ニーズを推測
- 複合クエリを焦点化されたサブクエリに分解
- サブクエリをナレッジソースに対して並列実行
- セマンティックランカーを用いて結果を再ランク付け・フィルタリング
- 上位結果を統合し、自然言語の回答を生成
from azure.search.documents.agent import KnowledgeAgentRetrievalClient
from azure.search.documents.agent.models import (
KnowledgeAgentRetrievalRequest,
KnowledgeAgentMessage,
KnowledgeAgentMessageTextContent,
SearchIndexKnowledgeSourceParams,
)
print(f"Knowledge Agent: {knowledge_agent_name} から取得")
agent_client = KnowledgeAgentRetrievalClient(endpoint=SEARCH_ENDPOINT, agent_name=knowledge_agent_name, credential=AzureKeyCredential(SEARCH_KEY))
query_1 = """
平清盛の生誕地と功績を教えて
"""
messages.append({
"role": "user",
"content": query_1
})
# 単一クエリである必要はない。チャット履歴を入力できる
req = KnowledgeAgentRetrievalRequest(
messages=[
KnowledgeAgentMessage(
role=m["role"],
content=[KnowledgeAgentMessageTextContent(text=m["content"])]
) for m in messages if m["role"] != "system"
]
)
result = agent_client.retrieve(retrieval_request=req, api_version=search_api_version)
print(f"Retrieved content from '{knowledge_source_name}' successfully.")
response
平清盛の生誕地は、京都府京都市であるという説が有力であり、また山城国の京都または伊勢国の産品(うぶしな)の生まれともされている[ref_id:0][ref_id:4]。平清盛は伊勢平氏の棟梁・平忠盛の長男として生まれ、保元の乱で後白河天皇の信頼を得て、平治の乱で最終的な勝利者となり、武士として初めて太政大臣に任じられた。日宋貿易によって財政基盤を開拓し、宋銭を日本国内で流通させ通貨経済の基礎を築き、日本初の武家政権を打ち立てた(平氏政権)[ref_id:10]。
結果の分析
ナレッジエージェントは回答合成用に設定されているため、検索応答には以下の値が含まれます。
-
response_content: 検索クエリに対する LLM 生成の回答(検索された文書を引用したもの) -
activity_content: 詳細な計画と実行情報(サブクエリ、再順位付けの決定、中間ステップを含む) -
references_content: 回答に貢献したソース文書とチャンク
ヒント:リランキングのしきい値やナレッジソースのプロパティといった検索パラメータは、エージェントがどの程度積極的に再ランク付けを行い、どの情報源を照会するかに影響します。アクティビティと参照情報を確認し、根拠の妥当性を検証するとともに、追跡可能な引用を構築してください。
include_activity = True の結果
{
"activity": [
{
"id": 0,
"type": "modelQueryPlanning",
"elapsed_ms": 1972,
"input_tokens": 2132,
"output_tokens": 131
},
{
"id": 1,
"type": "searchIndex",
"elapsed_ms": 126,
"knowledge_source_name": "wikipedia-knowledge-source",
"query_time": "2025-09-08T02:47:47.583Z",
"count": 9,
"search_index_arguments": {
"search": "平清盛 生誕地"
}
},
{
"id": 2,
"type": "searchIndex",
"elapsed_ms": 73,
"knowledge_source_name": "wikipedia-knowledge-source",
"query_time": "2025-09-08T02:47:47.657Z",
"count": 12,
"search_index_arguments": {
"search": "平清盛 功績"
}
},
{
"id": 3,
"type": "semanticReranker",
"input_tokens": 50270
},
{
"id": 4,
"type": "modelAnswerSynthesis",
"elapsed_ms": 5713,
"input_tokens": 6742,
"output_tokens": 334
}
]
}
クエリプランニング→サブクエリ分解→並列検索→セマンティックリランキング→回答合成の順で実行されていることがわかります。
include_references = True の結果
{
"references": [
{
"type": "searchIndex",
"id": "0",
"activity_source": 1,
"source_data": {
"text": "永久6年1月18日(1118年2月10日)、伊勢平氏の頭領である平忠盛の長男として生まれる(実父は白河法皇という説もある。詳細後述)。出身地は京都府京都市という説が有力である。生母は不明だが、もと白河法皇に仕えた女房で、忠盛の妻となった女性(『中右記』によると保安元年(1120年)没)である可能性が高い。『平家物語』の語り本系の諸本は清盛の生母を祇園女御としているが、読み本系の延慶本は清盛は祇園女御に仕えた中﨟女房の腹であったというように書いている。また、近江国胡宮神社文書(『仏舎利相承系図』)は清盛生母を祇園女御の妹とし、祇園女御が清盛を猶子としたと記している。清盛が忠盛の正室の子でない(あるいは生母が始め正室であったかもしれないがその死後である)にもかかわらず嫡男となった背景には、後見役である祇園女御の権勢があったとも考えられる。",
"title": "平清盛",
"AzureSearch_DocumentKey": "aHR0cHM6Ly9..."
},
"reranker_score": 3.5816414,
"doc_key": "aHR0cHM6Ly9..."
}
]
}
さらに include_reference_source_data = False にすると source_data が消えてスリムになります。
5. Fast path processing(高速パス処理)
Fast path は、特定の条件下で適用され、通常の検索と同等に近い高速(ミリ秒単位)の応答性能を提供するクエリ処理方式です。有効にすると、検索エンジンは次の条件を満たす場合に Fast path を適用しようとします。
-
attempt_fast_pathがKnowledgeAgentOutputConfiguration内でTrueに設定されている。 - クエリ入力が 512 文字未満の単一メッセージである。
- クエリ対象は、エージェント内で
always_query_sourceがTrueに設定されているナレッジソースです。
ナレッジエージェントに登録されている、対応可能なすべてのナレッジソースに対して並列に実行される小規模クエリは、スコアが 1.9 以上の場合に結果を返します。その中で最も高いスコアの結果が応答として返されます。もしこの条件を満たす結果がなければ Fast path は中止され、クエリ実行はクエリプランニングと通常のエージェント型検索パイプラインに戻ります。
Fast path では、応答にクエリプランニング情報(type: modelQueryPlanning)は含まれず、各参照の引用において activitySource が 0 に設定されます。
また Fast path では、retrieval_instructions は無視されます。一般的に、always_query_source が retrieval_instructions に優先します。
knowledge_agent_name = "wikipedia-agent"
# 正しいAzure OpenAIモデルの設定
openai_params = AzureOpenAIVectorizerParameters(
resource_url=AZURE_OPENAI_ENDPOINT,
deployment_name="gpt-4.1-mini", # サポートされているモデル名に変更
api_key=AZURE_OPENAI_API_KEY,
model_name="gpt-4.1-mini"
)
# Knowledge Agent モデルの設定
agent_model = KnowledgeAgentAzureOpenAIModel(
azure_open_ai_parameters=openai_params
)
# Knowledge Source の参照
knowledge_source_ref = KnowledgeSourceReference(
name=knowledge_source_name,
always_query_source=True
)
# 2つ目の Knowledge Source の参照
knowledge_source_ref2 = KnowledgeSourceReference(
name="products-knowledge-source", # 既存のKnowledge Source名を指定
always_query_source=True #このナレッジソースはソース選択をバイパスし、検索時に常に照会されるべきであることを示します。特定のナレッジ ソースで attempt_fast_path を使用している場合は、 always_query_source を true に設定する必要があります。
)
# 出力設定
# Answer synthesis (preview)
output_config = KnowledgeAgentOutputConfiguration(
# modality=KnowledgeAgentOutputConfigurationModality.ANSWER_SYNTHESIS,
modality=KnowledgeAgentOutputConfigurationModality.EXTRACTIVE_DATA,
include_activity=True, # 検索結果にアクティビティ情報を含めるべきかを示します
attempt_fast_path=True, # 高速パスを試みる。エージェントがモデル呼び出しをバイパスし、最新のチャットメッセージをナレッジソースへの直接クエリとして発行を試みるべきかを示します。
)
# リクエスト制限設定
request_limits = KnowledgeAgentRequestLimits(
max_runtime_in_seconds=30,
max_output_size=5000
)
# Knowledge Agentの作成
agent = KnowledgeAgent(
name=knowledge_agent_name,
models=[agent_model],
knowledge_sources=[knowledge_source_ref, knowledge_source_ref2], #複数指定可
output_configuration=output_config,
request_limits=request_limits,
retrieval_instructions="質問に関する情報を検索し、適切な回答を提供してください。",
description="このナレッジエージェントは、関連性のない複数のサンプルインデックスに向けられた質問を処理します。"
)
# Knowledge Agentの作成・アップデート
try:
created_agent = search_client.create_or_update_agent(agent)
print(f"Knowledge Agent '{created_agent.name}' を作成しました")
except Exception as e:
print(f"エラー: {e}")
attempt_fast_path と always_query_source を True に設定します。
Activity の結果
modelQueryPlanning が実行されなくなり、knowledge_sources で指定したすべてのナレッジソースにクエリをそのまま投げていることがわかります。
[
{
"id": 0,
"type": "searchIndex",
"elapsed_ms": 611,
"knowledge_source_name": "wikipedia-knowledge-source",
"query_time": "2025-09-08T06:55:23.299Z",
"count": 0,
"search_index_arguments": {
"search": "\n平清盛の生誕地と功績を教えて\n "
}
},
{
"id": 1,
"type": "searchIndex",
"elapsed_ms": 83,
"knowledge_source_name": "products-knowledge-source",
"query_time": "2025-09-08T06:55:23.383Z",
"count": 7,
"search_index_arguments": {
"search": "\n平清盛の生誕地と功績を教えて\n "
}
},
{
"id": 2,
"type": "semanticReranker",
"input_tokens": 14926
}
]
異種クエリを投入した場合の動き
ナレッジエージェントには異種混合のナレッジソースを含めることができますが、現状だと以下のように完全に関係のないナレッジソースは除外されますが、一つでもマッチするナレッジソースがあった場合、そこにすべてのサブクエリを並列で投げており、ちょっと動作が気になるところではあります。

retrieval_instruction を「質問に関する情報を検索し、適切な回答を提供してください。」に設定。
GitHub
参考