はじめに
この記事では、Qiitaの記事データを題材としたpandasによるデータ分析の実践例を紹介する。
Qiita APIを利用したデータの取得については以下の記事を参照。
対象とするのは2018年8月15日未明に取得した、それまでの全記事データ(32万件程度)。
以降のサンプルコードでは特定の列のみを読み込んで使う。
import collections
import itertools
import os
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
result_dir_path = 'results'
df = pd.read_csv(
os.path.join(result_dir_path, 'summary.csv'),
usecols=['title', 'created_at', 'likes_count', 'comments_count', 'tags_str', 'url', 'id']
)
print(len(df))
# 322129
最終的に以下のようなグラフを作成する。
記事数上位10タグのシェアの推移。
曜日別・時間帯別の記事数の分布(ヒートマップ)。
※普段は自分のサイトに書いているのですが、Qiitaのデータを使わせてもらった内容はQiitaに書くのが筋だろうと思いこちらに書くことにしました。
pandas.DataFrameの基本的な扱い
行名・列名、行番号・列番号によるデータの選択
df[列名]で列を選択できる。列名をリストで指定して複数列を選択することも可能。スペースの都合上、head()メソッドで先頭5行のみ出力する。
print(df['title'].head())
# 0 HTTP::Request -> AnyEvent::HTTP -> HTTP::Response
# 1 http://qiita.com/items/239/chunk の string= 使う ...
# 2 さておき、#.とかload-time-valueは(割とあやしい)使いでがありそうで良いです...
# 3 文字列をエスケープするときに"&"をエスケープしないと、セキュリティ的にまずい状況なることっ...
# 4 CLあやしいTips
# Name: title, dtype: object
print(df[['created_at', 'likes_count']].head())
# created_at likes_count
# 0 2011-09-28T16:18:38+09:00 1
# 1 2011-09-28T14:41:56+09:00 1
# 2 2011-09-28T08:51:27+09:00 1
# 3 2011-09-27T23:57:21+09:00 1
# 4 2011-09-27T22:29:04+09:00 2
df[スライス]で行を選択できる。スペースの都合上、[列名]で一列分のみ出力する。
print(df[5:10]['title'])
# 5 Rubyで文字列strのn番目(nは0オリジン)から後ろの部分文字列を取り出したいときに、次...
# 6 Evernoteに書くときに緯度経度が欲しくなったのでちょっと調べた.これでlat/long取れる
# 7 GoogleAppEngine/Python開発についての解説本のおすすめはありませんか?
# 8 slime便利コマンド
# 9 WebGLを勉強したいのですが、日本語のドキュメントやチュートリアルとかありませんか?
# Name: title, dtype: object
at, iat, loc, ilocで行名・列名、行番号・列番号によってデータを選択できる。使い分けは以下の通り。
- 位置の指定方法
-
at,loc: 行名、列名 -
iat,iloc: 行番号、列番号
-
- 選択できるデータ
-
at,iat: 単独の要素の値 -
loc,iloc: 単独および複数の要素の値- ※単独の要素を選択するのであれば
at,iatのほうが高速
- ※単独の要素を選択するのであれば
-
set_index()でid列をインデックスに設定したDataFrameを例とする。
df_id = df.set_index('id')
print(df_id['title'].head())
# id
# c96f56f31667fd464d40 HTTP::Request -> AnyEvent::HTTP -> HTTP::Response
# 94e9fdf602d14fbbb58b http://qiita.com/items/239/chunk の string= 使う ...
# 427a15cad55a2ff6c0b9 さておき、#.とかload-time-valueは(割とあやしい)使いでがありそうで良いです...
# 1e647cf795b42f9da4cc 文字列をエスケープするときに"&"をエスケープしないと、セキュリティ的にまずい状況なることっ...
# afcdd03b456c59bd9320 CLあやしいTips
# Name: title, dtype: object
print(df_id.columns)
# Index(['title', 'created_at', 'likes_count', 'comments_count', 'tags_str',
# 'url'],
# dtype='object')
at, iat, loc, ilocでの選択結果。loc, ilocではリストやスライスで範囲を指定できる。
print(df_id.at['c96f56f31667fd464d40', 'title'])
# HTTP::Request -> AnyEvent::HTTP -> HTTP::Response
print(df_id.iat[0, 0])
# HTTP::Request -> AnyEvent::HTTP -> HTTP::Response
print(df_id.loc[['c96f56f31667fd464d40', 'afcdd03b456c59bd9320'], ['likes_count', 'comments_count']])
# likes_count comments_count
# id
# c96f56f31667fd464d40 1 0
# afcdd03b456c59bd9320 2 3
print(df_id.iloc[:3, [1, 3]])
# created_at comments_count
# id
# c96f56f31667fd464d40 2011-09-28T16:18:38+09:00 0
# 94e9fdf602d14fbbb58b 2011-09-28T14:41:56+09:00 1
# 427a15cad55a2ff6c0b9 2011-09-28T08:51:27+09:00 0
より詳しくは以下の記事を参照。
条件によるデータの抽出
query()
条件に応じてデータを抽出するにはquery()メソッドを使う。
対象の列の列名に対して比較演算子で条件を指定した文字列をquery()の引数に渡す。andやorを使った複数条件も可能。
print(df.query('likes_count > 5000')['title'])
# 316 Markdown記法 チートシート
# 35420 ペアプログラミングして気がついた新人プログラマの成長を阻害する悪習
# 49770 非デザイナーエンジニアが一人でWebサービスを作るときに便利なツール32選
# 78460 うまくメソッド名を付けるための参考情報
# 146751 ロシアの天才ハッカーによる【新人エンジニアサバイバルガイド】
# Name: title, dtype: object
print(df.query('likes_count > 500 and comments_count > 100')['title'])
# 316 Markdown記法 チートシート
# 83947 IT業界で横行する恥ずかしい英語発音
# 131276 ズンドコキヨシまとめ
# 239255 ビットコイン自動裁定取引システムを開発・トレードした結果
# Name: title, dtype: object
print(df.query('tags_str == "Ruby"')['title'].head())
# 5 Rubyで文字列strのn番目(nは0オリジン)から後ろの部分文字列を取り出したいときに、次...
# 23 Rubyでは Object#send で指定された名前のメソッドを呼び出せるけれど、これはR...
# 36 extendがよく分かってない。
# 67 感謝しました。
# 68 句読点を切り替えるのを書きました.
# Name: title, dtype: object
ブール値のリストで抽出
列名にスペースやピリオドなどが含まれているとquery()は使えない。
より汎用的には、元のDataFrameの行数と等しい要素数のブール値のリストやSeriesを指定することで、Trueの行を抽出できる。
print((df['tags_str'] == 'Ruby').head(10))
# 0 False
# 1 False
# 2 False
# 3 False
# 4 False
# 5 True
# 6 False
# 7 False
# 8 False
# 9 False
# Name: tags_str, dtype: bool
print(df[df['tags_str'] == 'Ruby']['title'].head())
# 5 Rubyで文字列strのn番目(nは0オリジン)から後ろの部分文字列を取り出したいときに、次...
# 23 Rubyでは Object#send で指定された名前のメソッドを呼び出せるけれど、これはR...
# 36 extendがよく分かってない。
# 67 感謝しました。
# 68 句読点を切り替えるのを書きました.
# Name: title, dtype: object
strアクセサによる文字列メソッド(.str.xxx())を使うと文字列の列に対する様々な処理が可能。例えばstr.contains()は文字列が特定の文字列を含んでいる場合にTrueとするメソッド。
これを利用すると、==による完全一致ではなく部分一致の条件で行を抽出できる。
print(df['tags_str'].str.contains('Ruby').head(10))
# 0 False
# 1 False
# 2 False
# 3 False
# 4 False
# 5 True
# 6 False
# 7 False
# 8 False
# 9 False
# Name: tags_str, dtype: bool
print(df[df['tags_str'].str.contains('Ruby')]['title'].head())
# 5 Rubyで文字列strのn番目(nは0オリジン)から後ろの部分文字列を取り出したいときに、次...
# 15 NArrayを拡張したほうがいいのかな。あれはタイプを指定してnewするわけだし。
# 16 Arrayクラスを拡張したコードを幾つか書いているけれど、Arrayインスタンスに格納されて...
# 17 スリープソートをRubyで汎用的に書いてみる。
# 23 Rubyでは Object#send で指定された名前のメソッドを呼び出せるけれど、これはR...
# Name: title, dtype: object
tags_strに対する'Ruby'の完全一致および部分一致によって抽出される行数は以下の通り。
print(len(df.query('tags_str == "Ruby"')))
# 3736
print(len(df[df['tags_str'].str.contains('Ruby')]))
# 18878
これはQiitaサイトで「Ruby」タグを検索した結果の件数(17000件強)と一致しない。
tags_strはカンマ区切りの文字列であるため、完全一致では複数タグが設定された記事が漏れてしまい、部分一致では「RubyOnRails」タグなどがカウントされてしまうのが原因。
タグの扱いについては後述する。
ソート
sort_values()に列名を指定することで、その列の値を基準に並び替えることができる。
- pandas.DataFrame.sort_values — pandas 0.23.4 documentation
- pandas.DataFrame, Seriesをソートするsort_values, sort_index
print(df[['title', 'likes_count']].sort_values('likes_count', ascending=False)[:10].reset_index(drop=True))
# title likes_count
# 0 ロシアの天才ハッカーによる【新人エンジニアサバイバルガイド】 7339
# 1 Markdown記法 チートシート 6753
# 2 ペアプログラミングして気がついた新人プログラマの成長を阻害する悪習 6064
# 3 非デザイナーエンジニアが一人でWebサービスを作るときに便利なツール32選 5851
# 4 うまくメソッド名を付けるための参考情報 5090
# 5 Gitでやらかした時に使える19個の奥義 4930
# 6 数学を避けてきた社会人プログラマが機械学習の勉強を始める際の最短経路 4741
# 7 【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超 4642
# 8 もう保守されない画面遷移図は嫌なので、UI Flow図を簡単にマークダウンぽく書くエディタ作った 4344
# 9 新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡 4214
「いいね」数ランキングなどが簡単に出力できる。ここではiterrows()でforループを回して行ごとに処理を行う。
for i, row in df.sort_values('likes_count', ascending=False)[:10].reset_index().iterrows():
print('- No.{0}: [{1[title]}]({1[url]}) ({1[likes_count]} likes)'.format(i + 1, row))
歴代いいね数ランキングの結果。
- No.1: ロシアの天才ハッカーによる【新人エンジニアサバイバルガイド】 (7339 likes)
- No.2: Markdown記法 チートシート (6753 likes)
- No.3: ペアプログラミングして気がついた新人プログラマの成長を阻害する悪習 (6064 likes)
- No.4: 非デザイナーエンジニアが一人でWebサービスを作るときに便利なツール32選 (5851 likes)
- No.5: うまくメソッド名を付けるための参考情報 (5090 likes)
- No.6: Gitでやらかした時に使える19個の奥義 (4930 likes)
- No.7: 数学を避けてきた社会人プログラマが機械学習の勉強を始める際の最短経路 (4741 likes)
- No.8: 【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超 (4642 likes)
- No.9: もう保守されない画面遷移図は嫌なので、UI Flow図を簡単にマークダウンぽく書くエディタ作った (4344 likes)
- No.10: 新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡 (4214 likes)
時系列データの扱い
日時情報を含む時系列データの扱いもpandasの得意分野。
時系列データとして設定
'created_at'列に記事の作成日時が文字列として格納されている。
この列をインデックスに指定してpd.to_datetime()で変換することでDatetimeIndexとなり、時系列データとして扱われる。
タイムゾーンをpd.to_datetime()の引数utc=True, tz_convert(), tz_localize()で処理している。utc=Trueでタイムゾーンを「UTC」と指定して変換した後にtz_convert()で「Asia/Tokyo」にタイムゾーンを変更、さらに、以降ではタイムゾーンを使わないので tz_localize(None)としてタイムゾーン情報を削除している。
print(df['created_at'][0])
# 2011-09-28T16:18:38+09:00
print(type(df['created_at'][0]))
# <class 'str'>
df_ts = df.set_index('created_at')
df_ts.index = pd.to_datetime(df_ts.index, utc=True).tz_convert('Asia/Tokyo').tz_localize(None)
print(df_ts.index)
# DatetimeIndex(['2011-09-28 16:18:38', '2011-09-28 14:41:56',
# '2011-09-28 08:51:27', '2011-09-27 23:57:21',
# '2011-09-27 22:29:04', '2011-09-27 10:20:28',
# '2011-09-26 13:10:17', '2011-09-25 16:24:46',
# '2011-09-25 15:01:57', '2011-09-24 00:49:49',
# ...
# '2018-07-31 09:56:12', '2018-07-31 09:51:58',
# '2018-07-31 09:45:02', '2018-07-31 09:44:14',
# '2018-07-31 09:43:06', '2018-07-31 09:23:30',
# '2018-07-31 09:18:31', '2018-07-31 09:10:51',
# '2018-07-31 09:02:54', '2018-07-31 09:00:52'],
# dtype='datetime64[ns]', name='created_at', length=322129, freq=None)
df_ts.sort_index(inplace=True)
print(df_ts['title'].head())
# created_at
# 2011-09-16 03:01:10 RubyでFizzBuzz
# 2011-09-16 13:38:20 Emacsをずっと開いてるとだんだん重くなることがあり,気になっています
# 2011-09-16 13:39:42 句読点を切り替えるのを書きました.
# 2011-09-16 13:43:07 感謝しました。
# 2011-09-16 13:44:24 UINavigationController から自分自身を外して別のViewControl...
# Name: title, dtype: object
時系列データとして扱うと、日時指定や日時のスライスで行を選択できる。便利。
print(df_ts['2011-10-01']['title'])
# created_at
# 2011-10-01 11:07:58 Eloquent JavaScript を翻訳中。果たして需要はあるのだろうか。
# 2011-10-01 14:34:54 (1)「最近投稿されたアイテム」がタグによっては上部の緑の線より下が何も表示されません。
# 2011-10-01 17:10:41 リストの中身が昇順かどうか
# 2011-10-01 17:29:45 Google+で見かけたコメントに,「Pythonでリストの何番目の要素が最大/最小か求める...
# 2011-10-01 22:08:06 MacのMySQL GUiクライアントでSequel Proというのが便利.DBちょっと覗き...
# Name: title, dtype: object
print(df_ts['2015-01-01 00:00':'2015-01-01 01:00']['title'])
# created_at
# 2015-01-01 00:14:32 Free Pascal であけましておめでとうございます!
# 2015-01-01 00:42:22 Dockerライフサイクルをハンズオンで学ぶ
# 2015-01-01 00:46:17 VimfilerでQuick Lookを使ってファイルをプレビューする
# 2015-01-01 00:51:22 S3 事始め
# Name: title, dtype: object
リサンプリング
年ごと、四半期ごと、月ごとなど、期間ごとにデータを集約したい場合はresample()を使う。
resample()には年、四半期、月などに対応する頻度コードを指定し、さらにsum()(合計)やmean()(平均)などのメソッドを呼ぶことでデータを処理する。記事数をカウントするために'post_count'列を新たに追加し1を代入している。
df_ts['post_count'] = 1
print(df_ts.resample('YS').sum())
# likes_count comments_count post_count
# created_at
# 2011-01-01 11527 578 563
# 2012-01-01 125271 3150 6797
# 2013-01-01 412339 7833 15825
# 2014-01-01 1278658 18913 39936
# 2015-01-01 1358820 24384 56889
# 2016-01-01 1216427 27054 70561
# 2017-01-01 724694 28125 74528
# 2018-01-01 405493 16128 57030
print(df_ts.resample('YS').mean())
# likes_count comments_count post_count
# created_at
# 2011-01-01 20.474245 1.026643 1.0
# 2012-01-01 18.430337 0.463440 1.0
# 2013-01-01 26.056177 0.494976 1.0
# 2014-01-01 32.017678 0.473583 1.0
# 2015-01-01 23.885461 0.428624 1.0
# 2016-01-01 17.239367 0.383413 1.0
# 2017-01-01 9.723782 0.377375 1.0
# 2018-01-01 7.110170 0.282799 1.0
print(df_ts.resample('QS').sum())
# likes_count comments_count post_count
# created_at
# 2011-07-01 138 48 75
# 2011-10-01 11389 530 488
# 2012-01-01 16071 727 1054
# 2012-04-01 31233 665 1874
# 2012-07-01 36416 795 1670
# 2012-10-01 41551 963 2199
# 2013-01-01 64548 1378 2983
# 2013-04-01 88184 1678 3320
# 2013-07-01 98427 2246 3656
# 2013-10-01 161180 2531 5866
# 2014-01-01 217767 3489 7144
# 2014-04-01 321725 4803 9686
# 2014-07-01 350838 4927 10336
# 2014-10-01 388328 5694 12770
# 2015-01-01 312881 5717 12181
# 2015-04-01 316221 5658 12631
# 2015-07-01 296997 5650 13401
# 2015-10-01 432721 7359 18676
# 2016-01-01 349902 7031 16766
# 2016-04-01 297488 6097 15648
# 2016-07-01 249191 5947 15657
# 2016-10-01 319846 7979 22490
# 2017-01-01 180904 6753 16764
# 2017-04-01 147739 6818 16517
# 2017-07-01 139676 6221 15787
# 2017-10-01 256375 8333 25460
# 2018-01-01 173046 6933 21312
# 2018-04-01 169695 6430 24079
# 2018-07-01 62752 2765 11639
上の結果から分かるように、mean()は対象期間のデータ一件あたりの平均値となる。
一日あたりの平均値を求めるには日数を別途カウントして割る(ほかにいい方法があるのかもしれないが知らない)。
df_days = pd.DataFrame({'days_count': 1},
index=pd.date_range(df_ts.index[0], df_ts.index[-1], freq='D'))
print(df_days.resample('YS').sum())
# days_count
# 2011-01-01 107
# 2012-01-01 366
# 2013-01-01 365
# 2014-01-01 365
# 2015-01-01 365
# 2016-01-01 366
# 2017-01-01 365
# 2018-01-01 227
print((df_ts.resample('YS').sum().T / df_days.resample('YS').sum()['days_count']).T)
# likes_count comments_count post_count
# created_at
# 2011-01-01 107.728972 5.401869 5.261682
# 2012-01-01 342.270492 8.606557 18.571038
# 2013-01-01 1129.695890 21.460274 43.356164
# 2014-01-01 3503.172603 51.816438 109.413699
# 2015-01-01 3722.794521 66.805479 155.860274
# 2016-01-01 3323.571038 73.918033 192.789617
# 2017-01-01 1985.463014 77.054795 204.186301
# 2018-01-01 1786.312775 71.048458 251.233480
被除数をDataFrame、除数をSeriesとする場合、DataFrameのcolumns(列名)とSeriesのindexが一致していると一括で処理されるため、.Tで転置を行っている。
これらの結果を見ると、一日あたりの記事数は増加しているが、一記事あたりの「いいね」数やコメント数が減少傾向にあることが分かる。ユーザー間のコミュニケーションが減っているのは運営サイドとしてはなんとかしたいポイントかもしれない。
resample()のあとに適用できるメソッドには、sum()やmean()のほかにOHLC(Open: 始値、High: 高値、Low: 安値、Close: 終値)を出力するohlc()もある。株価のデータを処理する場合は非常に便利。
移動平均を算出したい場合はrolling()を使う。
マルチインデックス、GroupBy
リサンプリングは連続した期間を区切ってデータを集約するが、曜日別や時間別にデータを集約したい場合もある。そのような場合はマルチインデックス(階層型インデックス)を指定すると便利。
DatetimeIndexは属性yearやweekday, hourなどで、年や曜日、時間の値を取得できる。それらをset_index()でリストで指定することでマルチインデックスのDataFrameとなる。weekdayは0が月曜で6が日曜。
df_multi = df_ts.set_index([df_ts.index.year, df_ts.index.month, df_ts.index.weekday,
df_ts.index.hour, df_ts.index])
df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date']
print(df_multi['title'].str[:30].head(20))
# year month weekday hour date
# 2011 9 4 3 2011-09-16 03:01:10 RubyでFizzBuzz
# 13 2011-09-16 13:38:20 Emacsをずっと開いてるとだんだん重くなることがあり,気に
# 2011-09-16 13:39:42 句読点を切り替えるのを書きました.
# 2011-09-16 13:43:07 感謝しました。
# 2011-09-16 13:44:24 UINavigationController から自分自身を
# 2011-09-16 13:45:52 文字列化についてです
# 2011-09-16 13:46:02 PerlのFizzBuzz教えて!
# 2011-09-16 13:56:03 awkは奥(awk)深すぎ
# 14 2011-09-16 14:10:42 CoreTextを使ってNSAttributedString
# 2011-09-16 14:14:41 最近使ってるObjective-Cの便利ライブラリ。クロージ
# 2011-09-16 14:16:48 @yaotti コードにpermalink があって wge
# 2011-09-16 14:18:17 XCodeのプロジェクトに他のプロジェクトを静的ライブラリと
# 2011-09-16 14:23:24 NSNotificationCenter。所謂Observe
# 2011-09-16 14:39:22 キータで聞いたった
# 2011-09-16 14:56:09 JavaScript で new Regexp("[\s\S
# 15 2011-09-16 15:03:02 Node.js上でのおすすめWebアプリケーションフレームワ
# 2011-09-16 15:40:38 Qiitaが緑色ではなく紫色を使っていたら、emacsの話題
# 2011-09-16 15:45:53 CRubyでFizzBuzzを書いてみた。JRubyでは動か
# 16 2011-09-16 16:03:31 もっとソーシャルなgistみたいに使うのかな?
# 2011-09-16 16:06:04 FacebookのGraph APIで特定のURLを渡して、
# Name: title, dtype: object
マルチインデックスの場合、sum()やmean()などのメソッドの引数levelに対象の階層の列名を指定することで、その階層の値ごとにデータが集約される。
levelにはリストで指定することも可能で、例えば年ごとの曜日別の集計などが簡単に処理できる。
print(df_multi.sum(level='month').sort_index())
# likes_count comments_count post_count
# month
# 1 429876 10339 24840
# 2 439354 10348 25629
# 3 445889 11341 27735
# 4 460904 10672 27496
# 5 467723 10927 28059
# 6 443658 10550 28200
# 7 461725 10892 28457
# 8 372658 8840 23274
# 9 400052 8867 20490
# 10 388668 8535 21635
# 11 379596 9101 22975
# 12 843126 15753 43339
print(df_multi.sum(level='weekday').sort_index())
# likes_count comments_count post_count
# weekday
# 0 865072 18376 46818
# 1 831175 18933 48118
# 2 834613 19202 49858
# 3 846123 19383 49098
# 4 794135 18602 46568
# 5 634303 15795 38730
# 6 727808 15874 42939
print(df_multi.sum(level=['year', 'weekday']).sort_index())
# likes_count comments_count post_count
# year weekday
# 2011 0 637 40 62
# 1 507 42 89
# 2 841 59 100
# 3 726 45 72
# 4 7756 299 114
# 5 654 47 72
# 6 406 46 54
# 2012 0 16490 397 894
# 1 20758 489 1004
# 2 25332 569 1181
# 3 16102 441 1116
# 4 17205 498 1087
# 5 14792 412 763
# 6 14592 344 752
# 2013 0 59357 1126 2176
# 1 59528 1069 2381
# 2 66403 1258 2613
# 3 66047 1315 2583
# 4 56691 1349 2442
# 5 53512 937 1744
# 6 50801 779 1886
# 2014 0 196297 2705 5839
# 1 191499 2927 6011
# 2 203721 3113 6562
# 3 192436 2805 6279
# 4 192853 2915 5899
# 5 136089 2175 4485
# 6 165763 2273 4861
# 2015 0 209829 3416 8162
# 1 205036 3803 8564
# 2 206591 3607 8963
# 3 226439 3713 9113
# 4 191561 3699 8246
# 5 150534 3288 6695
# 6 168830 2858 7146
# 2016 0 190717 4018 10243
# 1 186006 4037 10456
# 2 171077 3869 10528
# 3 180857 4288 10730
# 4 170601 3828 10244
# 5 142972 3310 8857
# 6 174197 3704 9503
# 2017 0 123818 4225 11092
# 1 105243 4120 11090
# 2 103436 4158 11209
# 3 99905 4390 11087
# 4 104829 3922 10586
# 5 88308 3531 9016
# 6 99155 3779 10448
# 2018 0 67927 2449 8350
# 1 62598 2446 8523
# 2 57212 2569 8702
# 3 63611 2386 8118
# 4 52639 2092 7950
# 5 47442 2095 7098
# 6 54064 2091 8289
マルチインデックスによる集約は内部でGroupByの仕組みを使っている。マルチインデックスを設定せずにgroupby()を直接使ってもいい。おこのみで。
- pandas.DataFrame.groupby — pandas 0.23.4 documentation
- pandas.DataFrameをGroupByでグルーピングし統計量を算出 | note.nkmk.me
print(df_ts.groupby(df_ts.index.month).sum().sort_index())
# likes_count comments_count post_count
# created_at
# 1 429876 10339 24840
# 2 439354 10348 25629
# 3 445889 11341 27735
# 4 460904 10672 27496
# 5 467723 10927 28059
# 6 443658 10550 28200
# 7 461725 10892 28457
# 8 372658 8840 23274
# 9 400052 8867 20490
# 10 388668 8535 21635
# 11 379596 9101 22975
# 12 843126 15753 43339
これらの結果の可視化は後述。
タグの扱い
文字列をリストに分割
今回の例のタグtags_strのようなカンマ区切りの文字列はリストとして扱うと便利なことが多い。
str.split(',')で文字列をリストに分割する。スペースが入っている場合は', 'などとする必要がある。
print(df_ts['tags_str'].head())
# created_at
# 2011-09-16 03:01:10 Ruby,FizzBuzz
# 2011-09-16 13:38:20 Emacs
# 2011-09-16 13:39:42 Ruby
# 2011-09-16 13:43:07 Ruby
# 2011-09-16 13:44:24 Objective-C
# Name: tags_str, dtype: object
df_ts['tags_list'] = df_ts['tags_str'].str.split(',')
print(df_ts['tags_list'].head())
# created_at
# 2011-09-16 03:01:10 [Ruby, FizzBuzz]
# 2011-09-16 13:38:20 [Emacs]
# 2011-09-16 13:39:42 [Ruby]
# 2011-09-16 13:43:07 [Ruby]
# 2011-09-16 13:44:24 [Objective-C]
# Name: tags_list, dtype: object
なお、文字列もリストも列のデータ型dtypeはobject。考慮しなければいけない場面は少ないが、objectは常に文字列というわけではないので注意。
print(df_ts['tags_str'].dtypes)
# object
print(df_ts['tags_list'].dtypes)
# object
print(type(df_ts['tags_str'][0]))
# <class 'str'>
print(type(df_ts['tags_list'][0]))
# <class 'list'>
各タグの個数を算出
標準ライブラリitertoolsモジュールのitertools.chain.from_iterable()を使うとリストが格納されたSeriesを平坦化したイテレータを取得できる。確認のためlist()でリスト化すると以下のような結果となる。
all_tag_list = list(itertools.chain.from_iterable(df_ts['tags_list']))
print(all_tag_list[:10])
# ['Ruby', 'FizzBuzz', 'Emacs', 'Ruby', 'Ruby', 'Objective-C', 'Perl', 'Perl', 'awk', 'Objective-C']
print(len(all_tag_list))
# 793849
平坦化したイテレータを標準ライブラリcollectionsモジュールのcollections.Counter()に渡すと、各タグの出現個数をカウントできる。辞書ライクなオブジェクトを返すのでlen()でユニークなタグの数を取得したり、タグ名を指定して個数を取得したりできる。most_common()メソッドで出現回数順にタグとその個数を取得することも可能。
c = collections.Counter(itertools.chain.from_iterable(df_ts['tags_list']))
print(len(c))
# 37547
print(c['Ruby'])
# 17648
print(c['Python'])
# 19143
print(c.most_common()[:5])
# [('JavaScript', 20302), ('Python', 19143), ('Ruby', 17648), ('PHP', 12775), ('iOS', 11845)]
Seriesに変換することもできる。
tags = pd.Series(c)
print(tags.sort_values(ascending=False)[:50])
# JavaScript 20302
# Python 19143
# Ruby 17648
# PHP 12775
# iOS 11845
# Rails 11833
# Android 10340
# Swift 9654
# Java 9634
# AWS 9407
# Linux 8196
# docker 7305
# Git 6635
# Node.js 6450
# Mac 6151
# C# 5475
# Unity 5462
# MySQL 4901
# C++ 4617
# Xcode 4582
# Windows 4448
# CSS 4407
# Go 4387
# CentOS 4056
# #migrated 3912
# python3 3883
# Ubuntu 3854
# Objective-C 3841
# 機械学習 3794
# HTML 3655
# vagrant 3514
# RaspberryPi 3416
# GitHub 3364
# jQuery 3173
# Bash 3109
# Vim 3068
# laravel 2634
# 初心者 2619
# Scala 2473
# DeepLearning 2392
# golang 2387
# WordPress 2322
# MacOSX 2261
# R 2236
# HTML5 2121
# nginx 2088
# ShellScript 2058
# C 1988
# RubyOnRails 1980
# Slack 1866
# dtype: int64
print(tags.sum())
# 793849
リストに対する条件で抽出
上述のように、例えば「Ruby」を抽出したい場合、カンマ区切りの文字列に対して処理をすると「Ruby」単独の記事しか抽出できなかったり「RubyOnRails」まで抽出してしまったりする問題があった。
正規表現を駆使してもいいが、リスト化して処理することも可能。
列の各要素に関数を適用するapply()に無名関数を指定する。Qiitaサイトで「Ruby」タグを検索した結果件数と同じ数の行が抽出できている(データ取得日時とのズレがあるので完全に一致はしない)。
- pandas.DataFrame.apply — pandas 0.23.4 documentation
- pandasで要素、行、列に関数を適用するmap, applymap, apply
- Pythonの無名関数(ラムダ式、lambda)の使い方
df_ruby = df_ts[df_ts['tags_list'].apply(lambda x: 'Ruby' in x)]
print(df_ruby['title'].head())
# created_at
# 2011-09-16 03:01:10 RubyでFizzBuzz
# 2011-09-16 13:39:42 句読点を切り替えるのを書きました.
# 2011-09-16 13:43:07 感謝しました。
# 2011-09-16 15:45:53 CRubyでFizzBuzzを書いてみた。JRubyでは動かない
# 2011-09-16 21:30:38 XML/SOAPのAPIでWSDLファイルが無い場合ってどうすればいいんでしょう? Ruby...
# Name: title, dtype: object
print(len(df_ruby))
# 17648
なお、Qiitaのタグに関しては「Python」と「python3」が混在していたりするので厳密には名寄せを行う必要があるが、今回は省略。
タグごとに集約
リストに対する条件でタグごとのデータを抽出できれば、上述のresample()などで集約できる。
print(df_ruby.resample('QS').sum())
# likes_count comments_count post_count
# created_at
# 2011-07-01 27 11 12
# 2011-10-01 546 38 55
# 2012-01-01 6073 211 127
# 2012-04-01 4567 134 275
# 2012-07-01 9199 173 239
# 2012-10-01 7054 167 283
# 2013-01-01 14270 267 458
# 2013-04-01 9263 162 380
# 2013-07-01 10866 193 372
# 2013-10-01 18379 207 519
# 2014-01-01 16437 347 591
# 2014-04-01 43087 519 749
# 2014-07-01 32853 554 837
# 2014-10-01 37885 594 866
# 2015-01-01 23768 659 819
# 2015-04-01 17408 543 631
# 2015-07-01 16508 601 726
# 2015-10-01 24183 611 939
# 2016-01-01 22043 728 797
# 2016-04-01 10219 427 769
# 2016-07-01 11665 506 776
# 2016-10-01 15099 501 985
# 2017-01-01 8949 520 834
# 2017-04-01 5278 474 731
# 2017-07-01 5460 553 755
# 2017-10-01 11092 571 872
# 2018-01-01 4756 333 838
# 2018-04-01 10917 441 902
# 2018-07-01 2340 212 511
タグ別のストック数上位記事を出力するのも簡単。
for t in tags.sort_values(ascending=False).index[:5]:
print('- __{}__'.format(t))
df_tag = df_ts[df_ts['tags_list'].apply(lambda x: t in x)].sort_values('likes_count', ascending=False)
for i, row in df_tag[:3].reset_index().iterrows():
print(' - No.{0}: [{1[title]}]({1[url]}) ({1[likes_count]} likes)'.format(i + 1, row))
タグ別のストック数ランキング。
-
JavaScript
- No.1: ペアプログラミングして気がついた新人プログラマの成長を阻害する悪習 (6064 likes)
- No.2: 【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超 (4642 likes)
- No.3: もう保守されない画面遷移図は嫌なので、UI Flow図を簡単にマークダウンぽく書くエディタ作った (4344 likes)
-
Python
- No.1: 【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超 (4642 likes)
- No.2: Pythonを書き始める前に見るべきTips (3245 likes)
- No.3: 特にプログラマーでもデータサイエンティストでないけど、Tensorflowを1ヶ月触ったので超分かりやすく解説 (3154 likes)
-
Ruby
- No.1: ペアプログラミングして気がついた新人プログラマの成長を阻害する悪習 (6064 likes)
- No.2: 非デザイナーエンジニアが一人でWebサービスを作るときに便利なツール32選 (5851 likes)
- No.3: 【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超 (4642 likes)
-
PHP
- No.1: 【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超 (4642 likes)
- No.2: PHPでデータベースに接続するときのまとめ (2211 likes)
- No.3: 動的言語だけやってた僕が、38日間Go言語を書いて学んだこと (1755 likes)
-
iOS
- No.1: iOSでこんなアプリ,こんな機能を作りたかったらこれを見ろ!作りたいアプリに対応するクラス、フレームワーク、ライブラリのまとめ! (2116 likes)
- No.2: Swiftで作られたイケてるUIライブラリたち (2009 likes)
- No.3: エンジニアのための「Sketch入門!」 1時間コース (1772 likes)
タグごとの記事数の推移をまとめたいというような場合は、それぞれの結果のDataFrameをリストに格納しpd.concat()で連結するという方法がある。
df_tag_list = []
top_tag_list = tags.sort_values(ascending=False).index[:10].tolist()
for t in top_tag_list:
df_tag = df_ts[df_ts['tags_list'].apply(lambda x: t in x)]
df_tag_list.append(df_tag[['post_count']].resample('QS').sum())
df_tags = pd.concat(df_tag_list, axis=1)
df_tags.columns = top_tag_list
print(df_tags)
# JavaScript Python Ruby PHP iOS Rails Android Swift Java \
# created_at
# 2011-07-01 8 2 12 4 NaN NaN NaN NaN 1
# 2011-10-01 42 27 55 42 NaN 39.0 34.0 NaN 7
# 2012-01-01 109 37 127 123 12.0 67.0 37.0 NaN 47
# 2012-04-01 159 53 275 120 55.0 171.0 81.0 NaN 46
# 2012-07-01 148 69 239 125 91.0 134.0 42.0 NaN 35
# 2012-10-01 201 64 283 122 85.0 123.0 41.0 1.0 52
# 2013-01-01 186 104 458 129 178.0 208.0 80.0 3.0 62
# 2013-04-01 277 107 380 192 141.0 180.0 121.0 2.0 112
# 2013-07-01 287 150 372 260 151.0 186.0 111.0 0.0 125
# 2013-10-01 386 237 519 281 325.0 270.0 202.0 3.0 188
# 2014-01-01 480 309 591 284 518.0 331.0 253.0 5.0 260
# 2014-04-01 556 345 749 469 461.0 474.0 344.0 277.0 360
# 2014-07-01 606 333 837 407 523.0 500.0 453.0 372.0 340
# 2014-10-01 691 425 866 489 668.0 513.0 571.0 559.0 346
# 2015-01-01 777 509 819 526 528.0 533.0 492.0 409.0 323
# 2015-04-01 848 431 631 549 532.0 534.0 438.0 478.0 321
# 2015-07-01 866 440 726 522 621.0 560.0 516.0 500.0 390
# 2015-10-01 1125 910 939 671 876.0 732.0 648.0 860.0 587
# 2016-01-01 1104 782 797 643 632.0 606.0 580.0 702.0 650
# 2016-04-01 972 849 769 621 528.0 589.0 576.0 584.0 475
# 2016-07-01 865 893 776 658 699.0 521.0 500.0 629.0 464
# 2016-10-01 1233 1311 985 811 850.0 561.0 735.0 842.0 648
# 2017-01-01 1070 1200 834 607 538.0 588.0 474.0 521.0 484
# 2017-04-01 1021 1186 731 599 473.0 625.0 474.0 500.0 486
# 2017-07-01 1063 1312 755 609 406.0 537.0 438.0 436.0 490
# 2017-10-01 1564 2016 872 856 718.0 651.0 696.0 666.0 720
# 2018-01-01 1413 1959 838 802 466.0 601.0 561.0 528.0 602
# 2018-04-01 1515 1991 902 809 528.0 653.0 562.0 502.0 722
# 2018-07-01 728 1092 511 445 239.0 346.0 280.0 275.0 291
#
# AWS
# created_at
# 2011-07-01 NaN
# 2011-10-01 1.0
# 2012-01-01 6.0
# 2012-04-01 15.0
# 2012-07-01 13.0
# 2012-10-01 12.0
# 2013-01-01 41.0
# 2013-04-01 54.0
# 2013-07-01 49.0
# 2013-10-01 69.0
# 2014-01-01 116.0
# 2014-04-01 126.0
# 2014-07-01 247.0
# 2014-10-01 345.0
# 2015-01-01 343.0
# 2015-04-01 356.0
# 2015-07-01 426.0
# 2015-10-01 549.0
# 2016-01-01 502.0
# 2016-04-01 507.0
# 2016-07-01 488.0
# 2016-10-01 821.0
# 2017-01-01 594.0
# 2017-04-01 570.0
# 2017-07-01 503.0
# 2017-10-01 826.0
# 2018-01-01 740.0
# 2018-04-01 696.0
# 2018-07-01 391.0
この結果の可視化は後述。
plotメソッドによる可視化
Series, DataFrameのメソッドとしてplot()がある。Pythonのグラフ描画ライブラリMatplotlibのラッパーで、簡単にグラフを作成できる。
上述のリサンプリングやマルチインデックスを使った集約結果もDataFrameなので、さらにplot()メソッドを呼ぶだけでグラフを生成可能。
Jupyter Notebookの場合、先に%matplotlib inlineを実行しておくとグラフがインラインで表示される。画像ファイルとして保存する場合はplt.savefig()を使う。
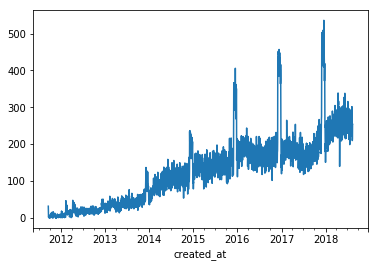
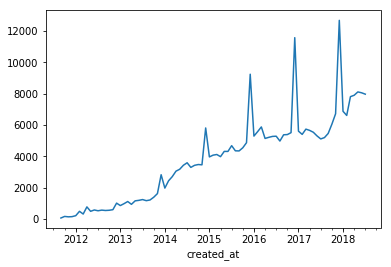
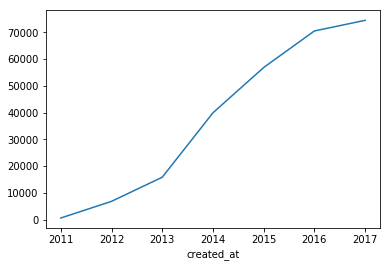
記事数の推移(折れ線グラフ)
plot()はデフォルトで折れ線グラフを出力する。
末尾のデータは期間の途中で終わっているので[:-1]で省いている。
df_ts['post_count'].resample('D').sum()[:-1].plot()
df_ts['post_count'].resample('M').sum()[:-1].plot()
df_ts['post_count'].resample('Y').sum()[:-1].plot()
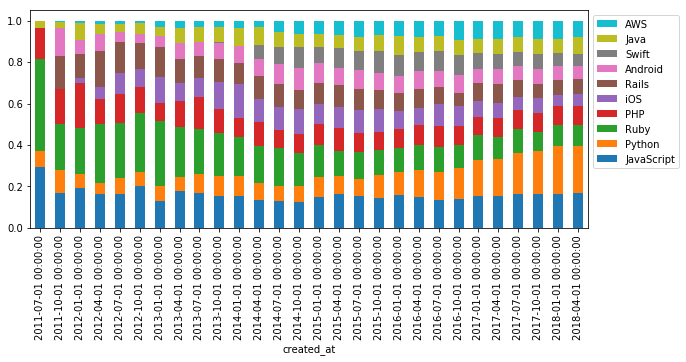
タグ別の記事数とそのシェアの推移(積み上げ棒グラフ)
上で作成した記事数上位10タグの記事数の推移のデータ(df_tags)を可視化する。
plot()デフォルトは折れ線グラフ。特に指定しなくても列名が凡例として表示される。
df_tags[:-1].plot(figsize=(10, 4))
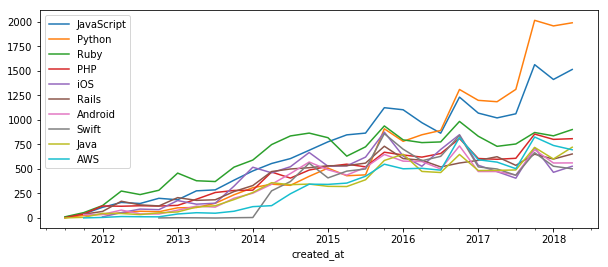
- 2014年末: Ruby → JavaScript
- 2016年半ば: JavaScript → Python
という記事数トップのタグの変遷が分かる。
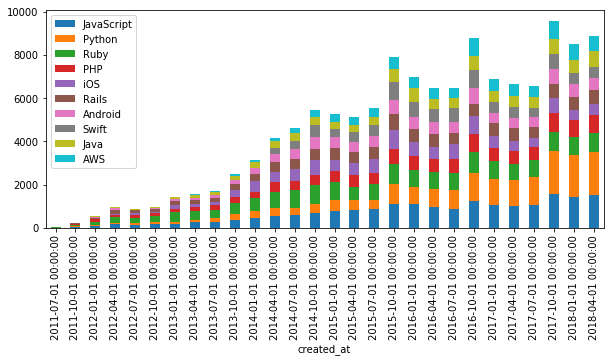
折れ線グラフ以外のグラフの種類はplot.bar()またはplot(kind='bar')のように指定する。各種のグラフに対する設定は引数で指定する。例えば棒グラフの場合、stacked=Trueとすると積み上げ棒グラフになる。
df_tags[:-1].plot.bar(stacked=True, figsize=(10, 4))
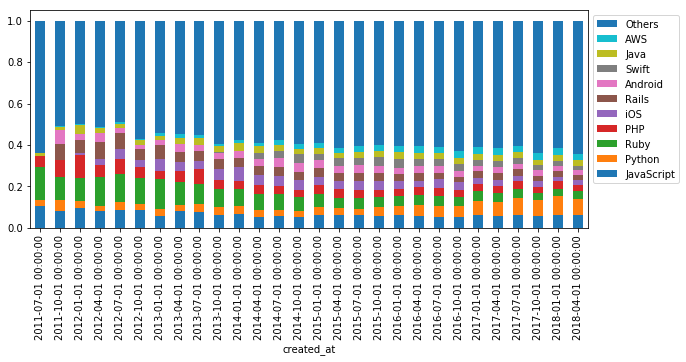
シェアの推移を見るために総数を1として規格化する。
df_normalized = (df_tags.T / df_tags.sum(axis=1)).T
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
df_normalized[:-1].plot.bar(stacked=True, ax=ax, figsize=(10, 4))
handles, labels = ax.get_legend_handles_labels()
plt.legend(reversed(handles), reversed(labels), loc='upper left', bbox_to_anchor=(1, 1))
RubyからPythonへのシェアの移り変わりや、PHPやJavaの根強さが分かる。
ちなみに上位10タグが含まれていない記事も追加すると以下の結果となる。
df_others = df_ts[df_ts['tags_list'].apply(lambda x: not (set(top_tag_list) & set(x)))]
df_tag_list_others = df_tag_list + [df_others[['post_count']].resample('QS').sum().rename(columns={'post_count': 'Others'})]
df_tags_others = pd.concat(df_tag_list_others, axis=1)
df_tags_others.columns = top_tag_list + ['Others']
df_normalized_others = (df_tags_others.T / df_tags_others.sum(axis=1)).T
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
df_normalized_others[:-1].plot.bar(stacked=True, ax=ax, figsize=(10, 4))
handles, labels = ax.get_legend_handles_labels()
plt.legend(reversed(handles), reversed(labels), loc='upper left', bbox_to_anchor=(1, 1))
厳密には上位10タグは重複してカウントされていることを考慮する必要があるが、上位10タグの占める割合は全体のおよそ4割程度で推移している。
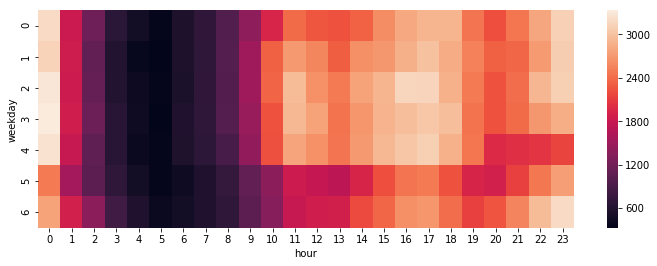
曜日別・時間別の記事数の分布(ヒートマップ)
pandasのplot()だけでなく、ビジュアライゼーションライブラリseabornを使うとさらに様々なグラフを簡単に作成できる。
上で作成した曜日などでマルチインデックス化したデータ(df_multi)を例とする。
マルチインデックスをsum()などで処理した結果もDataFrameなので、plot()でそのままプロットできる。曜日別と時間別。weekdayは0が月曜で6が日曜。
df_multi['post_count'].sum(level='weekday').sort_index().plot.bar(color='navy')
df_multi['post_count'].sum(level='hour').sort_index().plot.bar(color='navy')
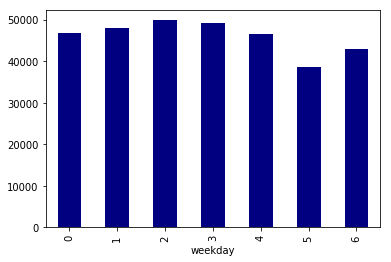
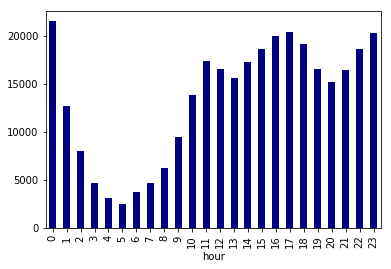
- 土日の記事数が少ない
- 13時、20時に谷がある(食事や帰宅の時間?)
ということが分かる。
さらに曜日別・時間別を合わせて可視化する。2つのインデックスで集約したあとでunstack()で二次元の形にする。
df_w_h = df_multi['post_count'].sum(level=['weekday', 'hour']).sort_index()
print(df_w_h)
# weekday hour
# 0 0 3204
# 1 1828
# 2 1179
# 3 656
# 4 475
# 5 348
# 6 556
# 7 701
# 8 970
# 9 1394
# 10 1942
# 11 2401
# 12 2272
# 13 2242
# 14 2343
# 15 2626
# 16 2811
# 17 2903
# 18 2899
# 19 2455
# 20 2221
# 21 2468
# 22 2804
# 23 3120
# 1 0 3139
# 1 1848
# 2 1082
# 3 595
# 4 382
# 5 324
# ...
# 5 18 2244
# 19 1932
# 20 1895
# 21 2136
# 22 2485
# 23 2745
# 6 0 2779
# 1 1898
# 2 1379
# 3 839
# 4 572
# 5 414
# 6 476
# 7 575
# 8 690
# 9 1052
# 10 1339
# 11 1794
# 12 1870
# 13 1878
# 14 2196
# 15 2359
# 16 2631
# 17 2682
# 18 2414
# 19 2139
# 20 2258
# 21 2563
# 22 2949
# 23 3193
# Name: post_count, Length: 168, dtype: int64
print(df_w_h.unstack(level='hour'))
# hour 0 1 2 3 4 5 6 7 8 9 ... 14 \
# weekday ...
# 0 3204 1828 1179 656 475 348 556 701 970 1394 ... 2343
# 1 3139 1848 1082 595 382 324 550 692 991 1512 ... 2631
# 2 3298 1830 1121 600 419 348 546 710 973 1518 ... 2776
# 3 3334 1876 1152 646 432 324 571 690 991 1472 ... 2684
# 4 3262 1802 1075 646 396 352 568 685 895 1426 ... 2705
# 5 2496 1558 1045 694 474 357 435 582 737 1078 ... 1924
# 6 2779 1898 1379 839 572 414 476 575 690 1052 ... 2196
#
# hour 15 16 17 18 19 20 21 22 23
# weekday
# 0 2626 2811 2903 2899 2455 2221 2468 2804 3120
# 1 2693 2866 2995 2845 2545 2334 2364 2715 3092
# 2 2909 3165 3151 2881 2488 2241 2416 2921 3102
# 3 2892 2971 3047 2975 2441 2248 2403 2689 2861
# 4 2925 3034 3101 2883 2474 1973 2019 2056 2166
# 5 2228 2462 2491 2244 1932 1895 2136 2485 2745
# 6 2359 2631 2682 2414 2139 2258 2563 2949 3193
#
# [7 rows x 24 columns]
これをSeabornのheatmap()に渡す。
plt.figure(figsize=(12, 4))
sns.heatmap(df_w_h.unstack(level='hour'))
- 金曜日の夜からおやすみモード
- 土曜日は夜更かししがち
- 月曜日(特に午前中)はまだエンジンがかかっていない
というようなQiitaユーザーのみなさんの生態が分かる。日曜日の夜も意外と活発。大きなお世話だと思うが、早めに寝たほうがいいんじゃないだろうか。
折れ線グラフはこちら。曜日間の差分はヒートマップよりこちらのほうが分かりやすい。それぞれに良し悪しがある。
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
df_w_h.unstack(level='weekday').plot(figsize=(10, 4), ax=ax)
plt.legend(loc='upper left', bbox_to_anchor=(1, 1))
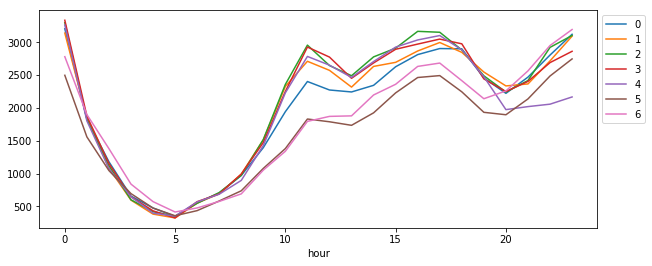
データを絞り込んで同様の処理を行うのも簡単。
なんとなく時間帯によって差がありそうな「ポエム」タグの時間別の記事数を例にする。
df_poem = df_multi[df_multi['tags_str'].str.split(',').apply(lambda x: 'ポエム' in x)]
print(len(df_poem))
# 910
df_poem['post_count'].sum(level='hour').sort_index().plot.bar(color='navy')
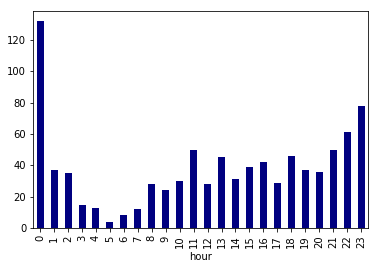
「ポエム」タグはこのデータ取得時点で900件強とまだ少ないので参考程度ではあるが、イメージ通り深夜0時頃に投稿された記事数が多い。
「ポエム」タグの記事をいくつか読んでみた感じでは別にそんなにポエティックな内容でもないように思えたが、人は夜中になると「ポエム」タグを付けたくなるのかもしれない。タグはあとからでも追加できるので、夜中に投稿した記事を昼間に読み返して「ポエム」タグを付ける場合もあるかもしれない。
曜日別・時間別のヒートマップがこちら。fillna()で欠損値を埋めている。
plt.figure(figsize=(12, 4))
sns.heatmap(df_poem['post_count'].sum(level=['weekday', 'hour']).sort_index().unstack(level='hour').fillna(0))
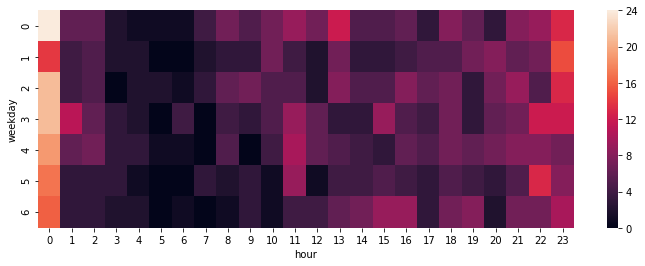
最多投稿数はまさかの日曜深夜(月曜0〜1時)。大きなお世話だと思うが、日曜日の夜はポエムを書くよりも早めに寝たほうがいいんじゃないだろうか。
ちなみに、Seabornのヒートマップは関係性がよくわからないデータに対してとりあえず相関行列を可視化してみて様子を伺うときに便利。
ヒートマップのほかにはペアプロット図(散布図行列)などもある。
まとめ
今回扱った32万件(75MB)程度のデータであればpandasのメソッドをそのまま使うだけでサクサクと処理できる。全件をforループでまわすようなことをしなければストレスを感じるほど時間がかかることもないはず。
今回はただ適当にグラフを作っただけだが、実際の業務においては何らかの答えを出すためにデータをいじくって試行錯誤を繰り返すことになる。pandasを活用して、データを集約したりちょっとグラフ化してみたりというような処理を素早く行うことによって、本来時間をかけるべきところ・悩むべきところに集中できる。
ということで、みなさん、非常に便利なpandasをどんどん使いましょう。
おまけ
NumPy, pandas, Matplotlibをしっかり学びたいなら『Pythonデータサイエンスハンドブック』が最高にオススメ。英語版は全文がオンラインで無料で公開されている。
- O'Reilly Japan - Pythonデータサイエンスハンドブック
- Python Data Science Handbook | Python Data Science Handbook
- 『Pythonデータサイエンスハンドブック』は良書(NumPy, pandasほか)
pandasをより詳しく学びたいなら第二版の日本語版が出た『Pythonによるデータ分析入門』。
なお、『Pythonによるデータ分析入門』の初版(2013年)は最新のバージョンのpandasでサンプルコードを動かすとエラーだらけなので、もし安くなっていても買ってはいけない。