はじめに
WiDS Datathon2021は2021年のWiDS Worldwide conferenceの開催前の時期に合わせてKaggleを使って行われるCompetitionです。
Women in Data Science (WiDS Worldwide)は、性別に関係なく、世界中のデータサイエンティストにインスピレーションを与え、教育を行い、現場の女性を支援することを目的としした活動です。
参加資格
WiDS Datathon2021の参加資格は、4人以内のチームで(1人でもOK)、チームの半数が女性であることのみです。女性の皆さん、間に合えばどんどん参加しましょう! 男性の皆さんもチームに半分以上の女性を誘って参加しましょう!
スケジュール
全て2021年、日時はUTCです。
- 1月6日 KaggleでDatathon開始
- 2月26日 チームのMerge期限。この日は、競技者がチームに参加したり、Mergeしたりできる最終日です。
- 3月1日 Leaderboard Prizeの対象となる最終的なKaggleの提出期限
- 3月8日 WiDSワールドワイドカンファレンスにて、Datathon Leaderboardの受賞者を発表
今回の課題
今回の課題は、ICUに入院した患者が特定のタイプの糖尿病(Diabetes Mellitus)と診断されたかどうかを判断するという課題です。
参加方法
WiDS Datathon2021の参加方法は、こちらに記載されています。Prizeもここに記載されています、
簡単に言うと、WiDSのサイトでregisterしてから、 WiDS Datathon page on Kaggleで参加してねってことです。
AutoAIを使って予測してみる
AutoAIはIBM Cloud上のWatson Studio(あるいはCloud Pak for Data)で使える、学習データを渡すと自動で機械学習モデルを作成できるツールです。
実は昨年のWiDS DatathonもAutoAIを使って参加してみました。さすがに入賞するほどの結果は出なかったのですが、半分以上くらいの順位は出たと記憶しています。今年もAutoAIチャレンジってことで、AutoAIで参加してみます。
尚、残念なお知らせですが、学習データ量の関係で、無料枠内では最後まではできませんでした。
無料でやってみたかった方は、AutoAIの使い方だと思って別データで試してみていただければと思います。
以下はIBM Cloud上のWatson Studio(あるいはCloud Pak for Data)を使う前提で書いています。
1. データ準備
WiDS Datathon page on KaggleにJoin Competitionして(kaggleへのユーザー登録が必要です)、データタブから必要なファイルをダウンロードしてください。
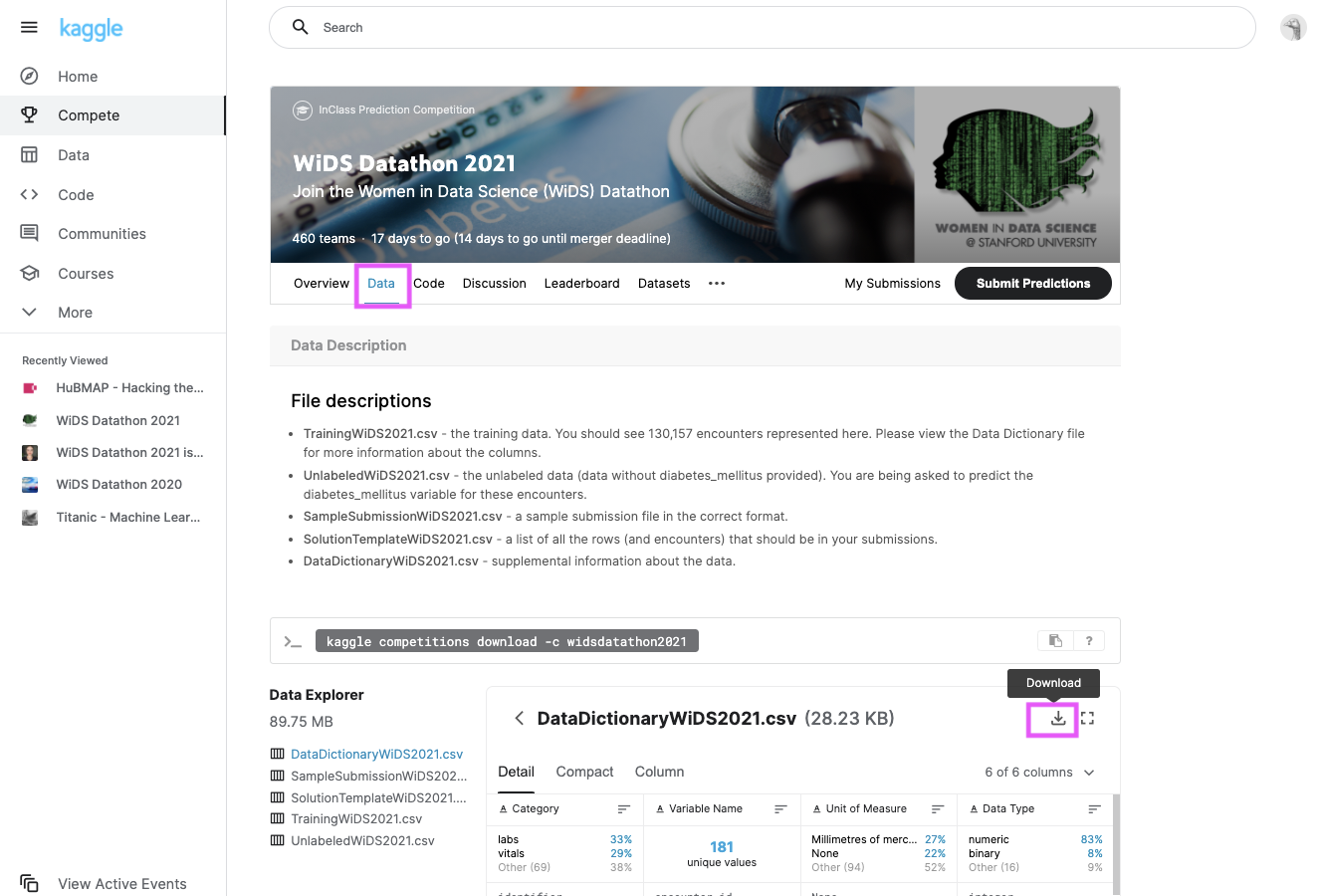
ダウンロードアイコンからダウンロードすると、提供されているすべてのファイルがZipされたファイルがダウンロードできます。適当な場所にunzipしておきましょう。
以下が各ファイルの概要です:
- TrainingWiDS2021.csv - トレーニングデータです。130,157件あります。列の詳細については、Data Dictionaryファイルにあります。
- UnlabeledWiDS2021.csv - 非ラベルデータ(糖尿病かどうか(diabetes_mellitus)が提供されていないデータ)です。これらの情報のdiabetes_mellitus変数を予測するように求められています。
- SampleSubmissionWiDS2021.csv - 正しいフォーマットのサンプル提出ファイルです。
- SolutionTemplateWiDS2021.csv - 提出物に含まれるべきすべての行のリストです。
- DataDictionaryWiDS2021.csv - データに関する情報です。
2. AutoAIを使うための前準備
2-1. Watson Studio サービスとプロジェクトの作成
まずはWatson Studio サービスとプロジェクトの作成をします。手順は以下になります。
Watson Studio サービスとプロジェクトの作成
2-2. Machine Learningサービスの作成
これはIBM CloudのWebコンソールのカタログから作成しても、Watson Studioから作成してもOKです。同じリージョンで既に作成済みであればそれを使用することが可能です(同じリージョンである必要があります。)
作成するのは以下です。
- 作成するサービス:
Machine Learning - リージョンの選択: Watson Studioと同じリージョン
方法1: Watson Studioから作成
方法2: IBM CloudのWebコンソールから作成
2-3. デプロイメント・スペースの作成
作成したモデルを利用するにはデプロイメント・スペースへのデプロイが必要なので、先に作成しておきます。
以下の手順で実施してください(前提は実施済みなので、1から実施)。
2-4. Machine Learningサービスとプロジェクトの関連付け
以下の手順で実施してください(前提は実施済みなので、1から実施)。
3. AutoAIでモデル作成
いよいよ AutoAIでモデル作成します。Watson Studio(またはCloud Pak for Data)でプロジェクトを開いた状態(2-4が終了している状態)から説明します。
3-1. 上部にあるプロジェクトに追加をクリック

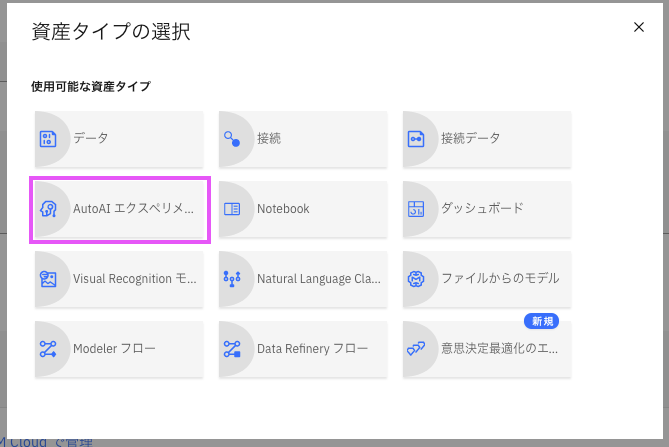
3-2. 「資産タイプの選択」画面からAIエクスペリメントをクリック
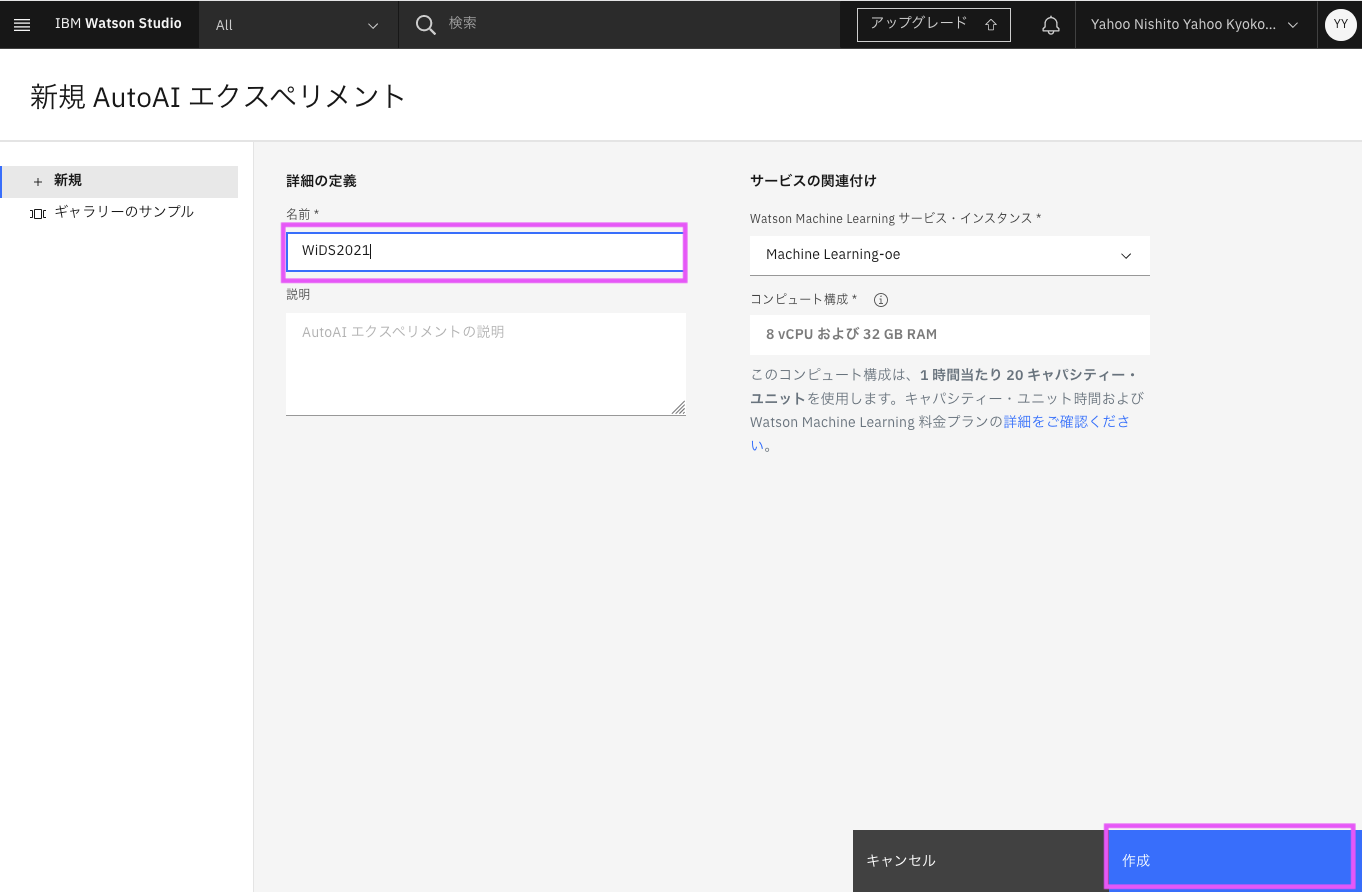
3-3. 「新規 AutoAI エクスペリメント」の画面で名前を入力し、作成をクリック
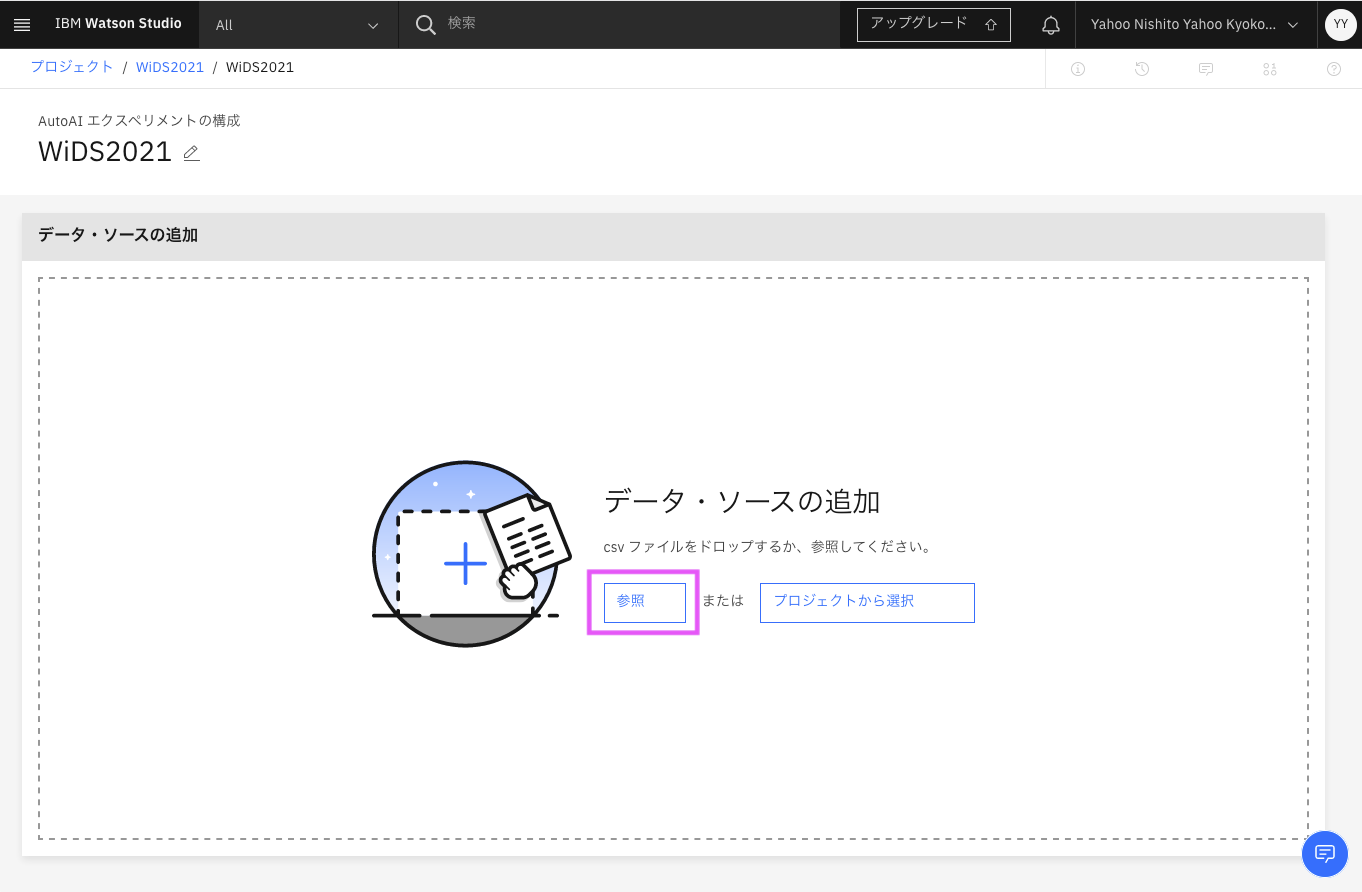
3-4. 「データ・ソースの追加」画面が表示されるので、「1. データ準備」でダウンロードしたTrainingWiDS2021.csvファイルをドロップするか、参照から選択してください。
3-5. 予測列をセットして実行
しばらく待つと、「AutoAI エクスペリメントの構成」画面が表示されるので、「詳細の構成」にある「予測する内容」の「予測列」のドロップダウンから, 予測すべき値「糖尿病かどうか」の列diabetes_mellitusを選択します。
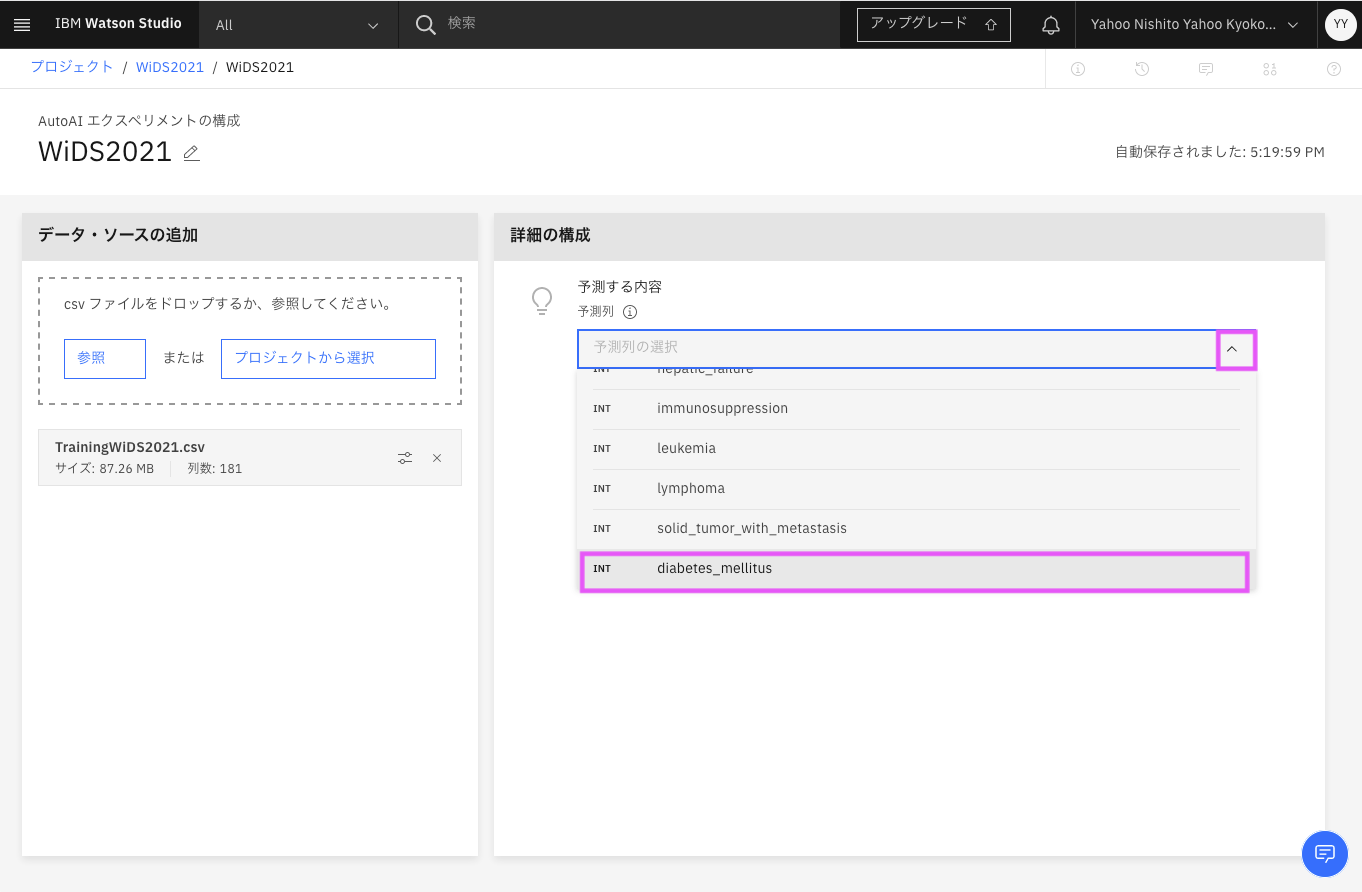
AutoAIはデーターから2項分類であると予測タイプを判断しました。問題なければエクスペリメントの実行をクリックします。
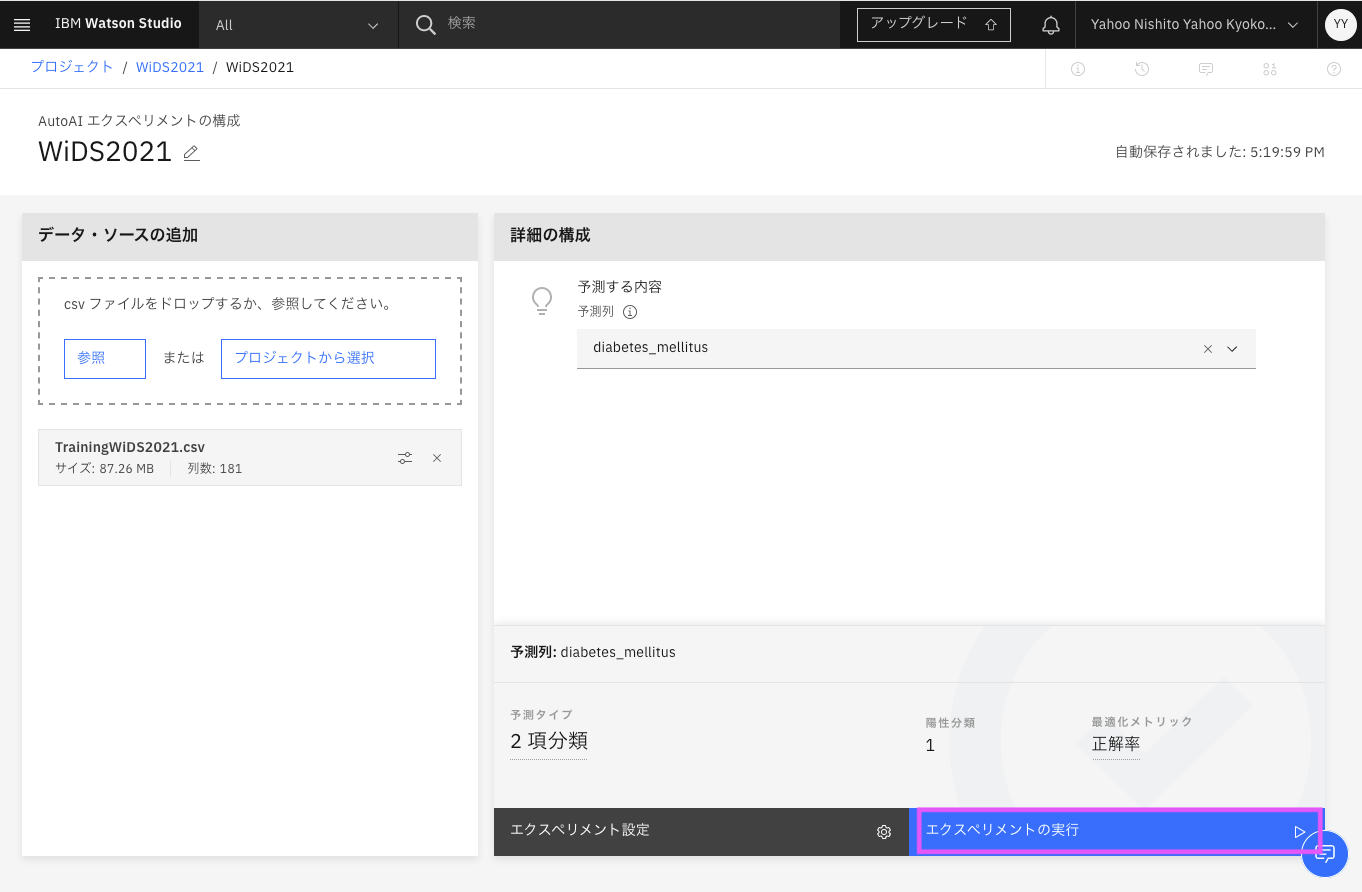
しばらくすると以下の画面になり、実行の状況が表示されます。
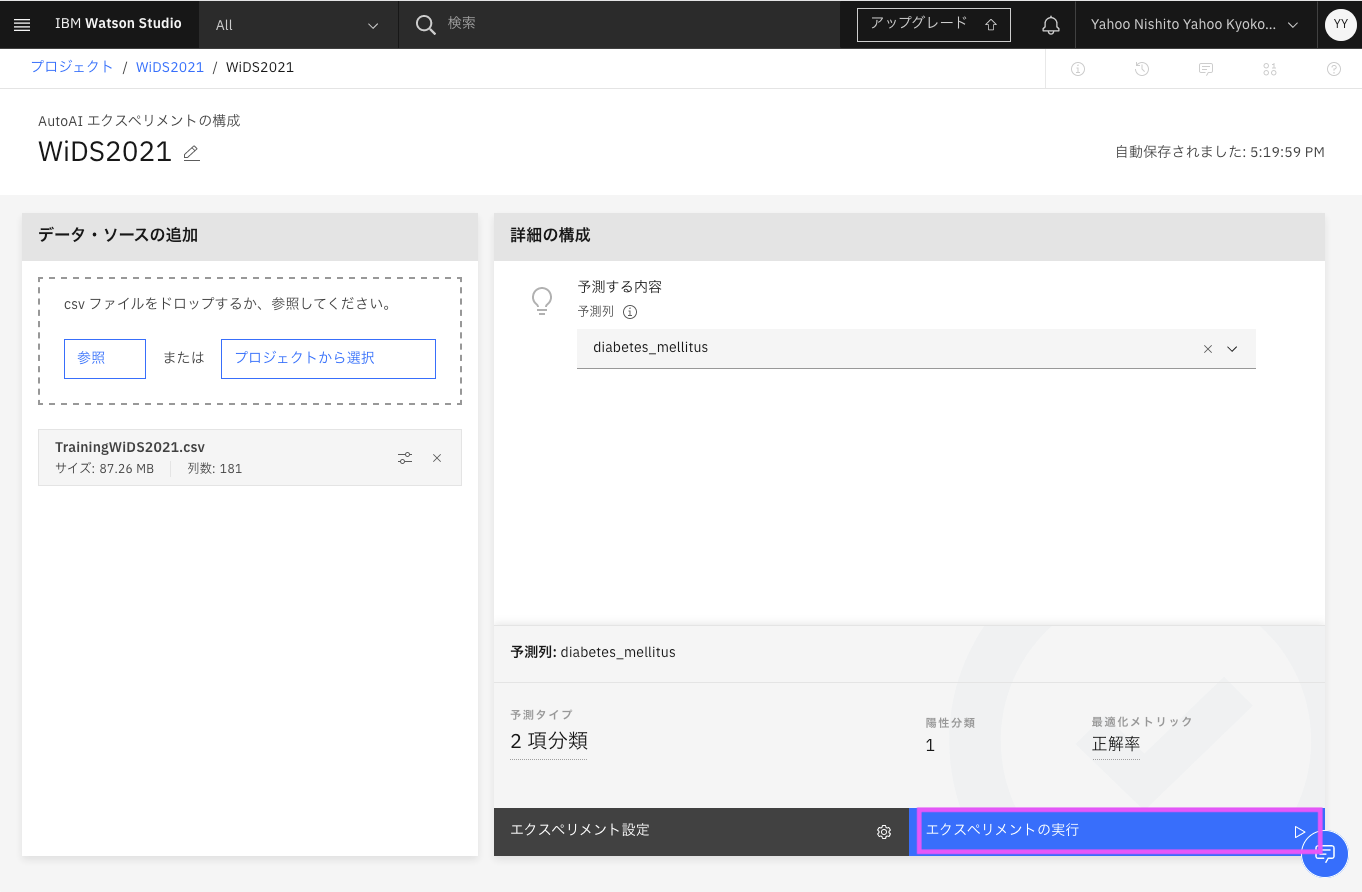
しかし残念ながら無料プランでは力及ばず、、、1つパイプラインを作成完了でキャパオーバーになりました。1時間くらいで力尽きてたようです、、、、。
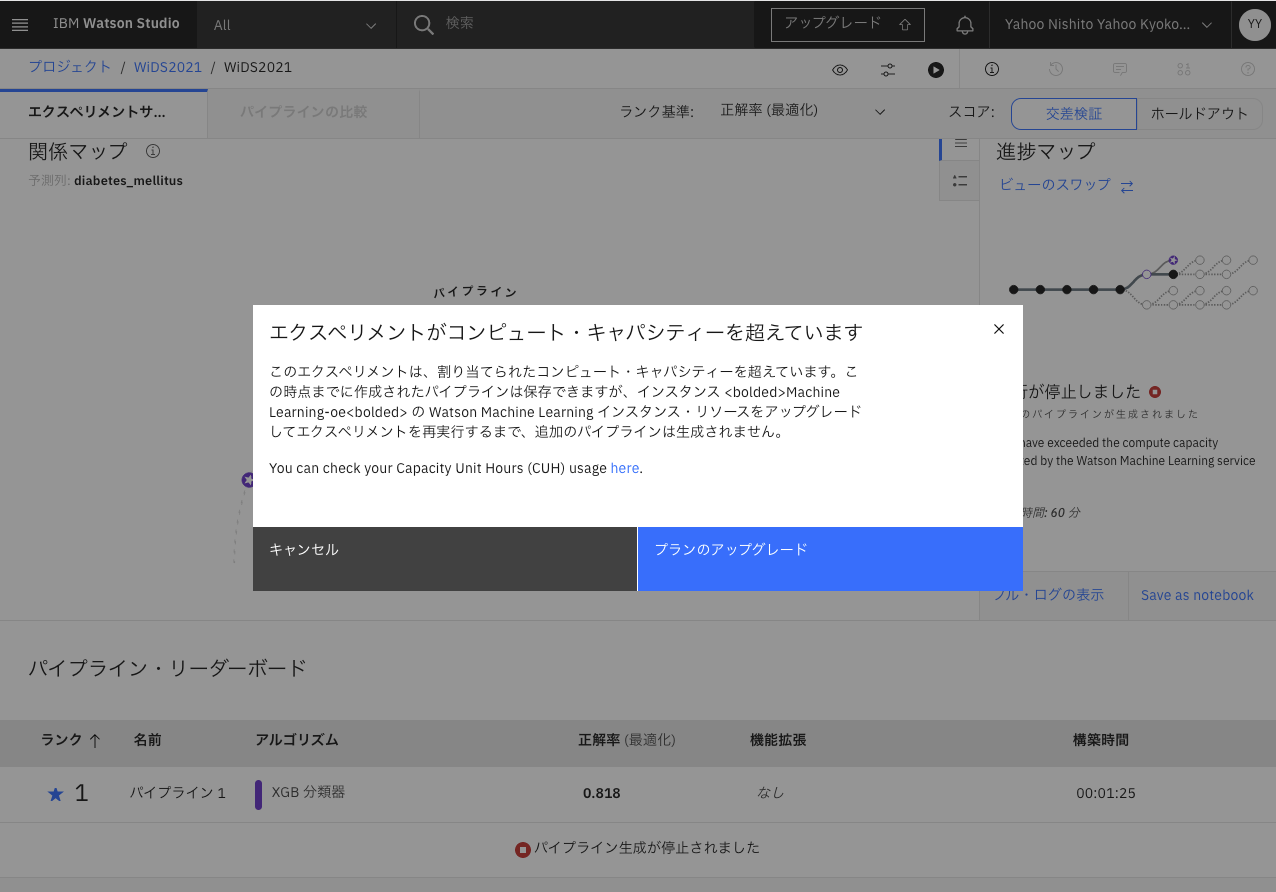
キャパが足りてた場合は、デフォルトの設定で8つパイプラインができるのですが、、、。
もちろん作成完了したこの1つのパイプラインは保存し、モデルとしてDeployできます。
とりあえず作成できたこのパイプラインのモデルを使うことにしたいのですが、もうキャパがなく後続作業ができないため、ここから先は実際には別有料環境を混ぜてやっています。
「キャンセル」をクリックして、作成できたパイプラインをモデルに保存します。
3-6. モデルの保存
「パイプライン・リーダーボード」にある保存したいパイプラインの行にマウスを重ねると、右側に「名前をつけて保存」というボタンが表示されるので、クリックします。
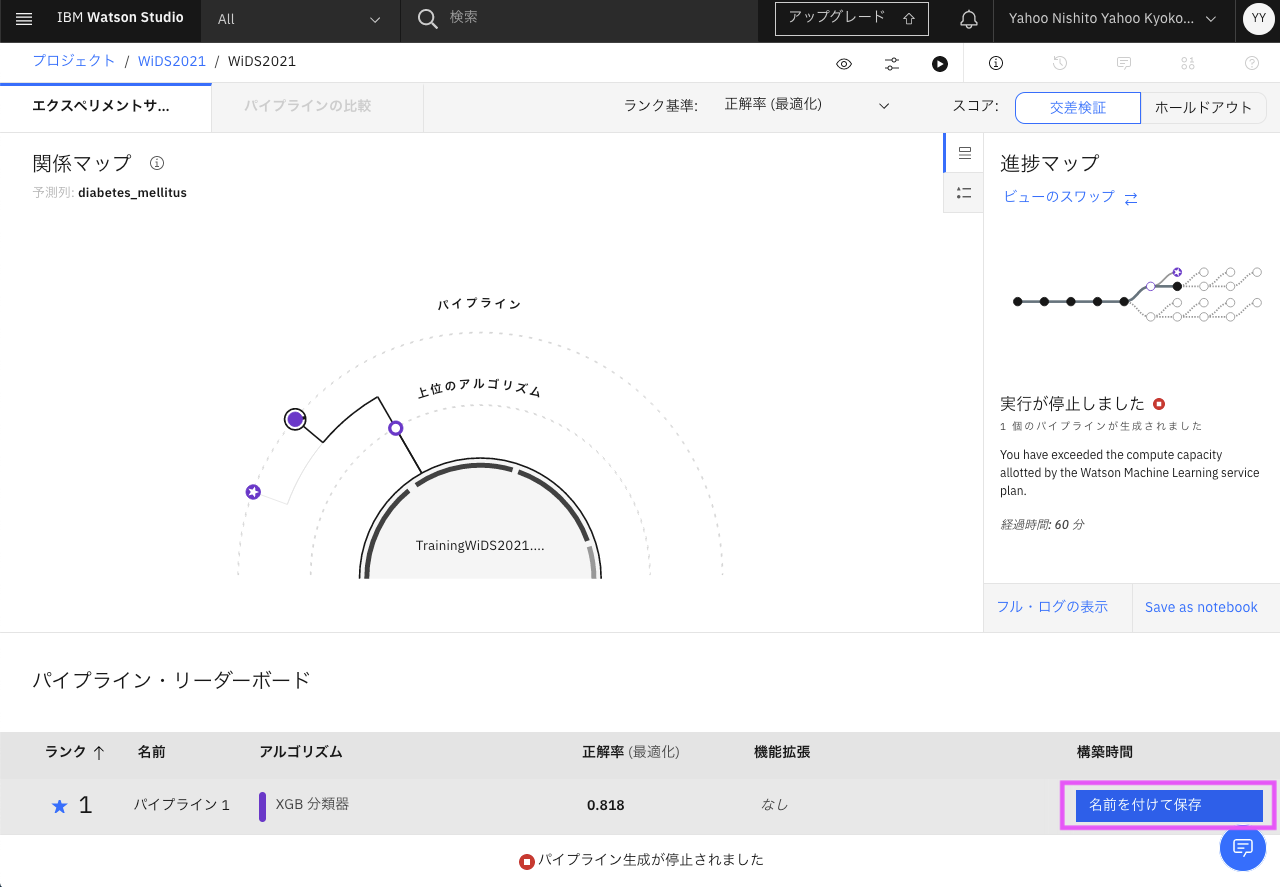
「モデル」が選択されていることを確認し、名前を変更したい場合は変更して、「作成」をクリックします。
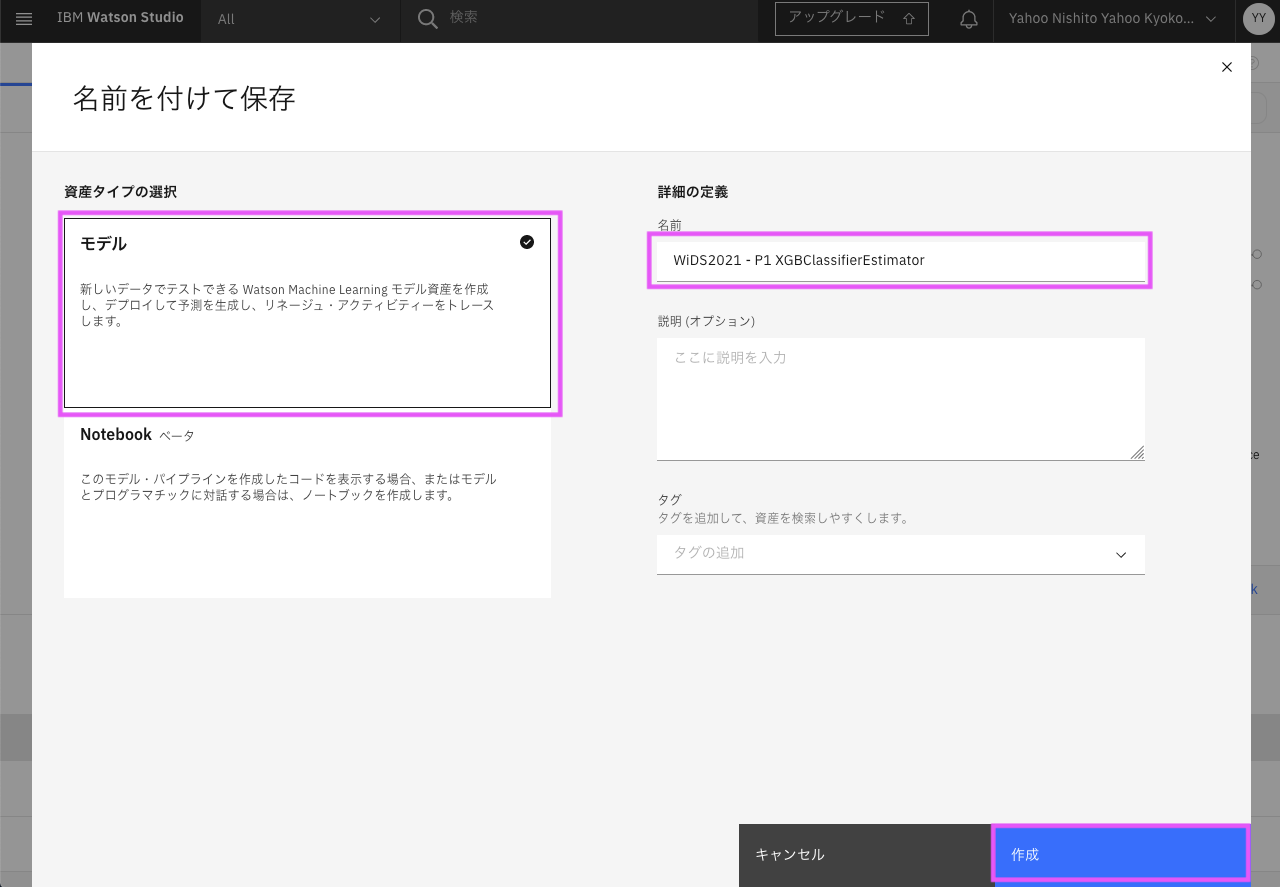
「モデルが正常に保存されました」のメッセージが右上に表示されるので、「プロジェクトに表示」をクリックします。
モデルの概要が表示されます。
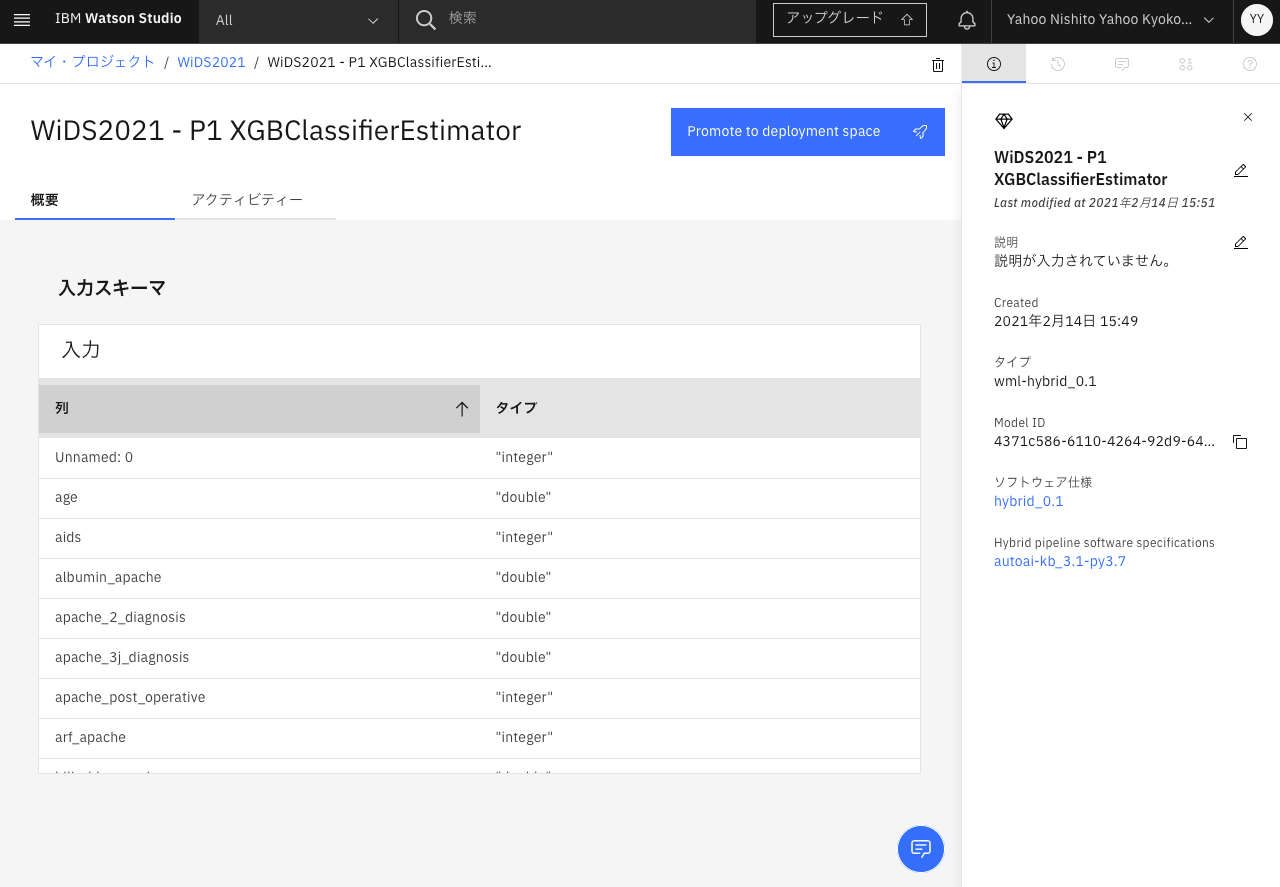
3-7. モデルのプロモート
このモデルがWebサービスで使用できるようにモデルをデプロイメント・スペースにプロモートします。
右上の「Promote to deployment space」をクリックします。
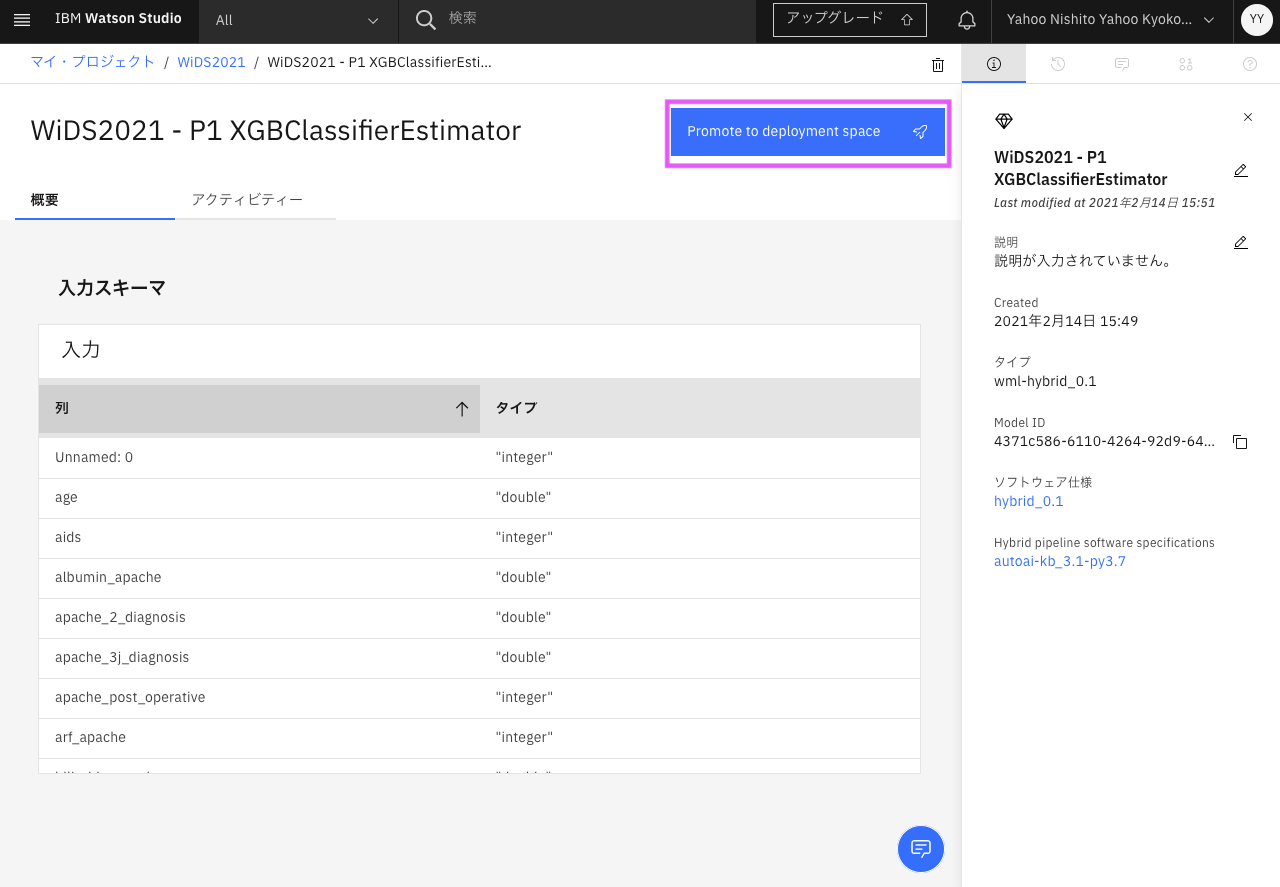
「スペースへのプロモート」が表示されます。ターゲット・スペースが「2.AutoAIを使うための前準備」で作成したデプロイメントスペースになっていることを確認し、「プロモート」をクリックします。
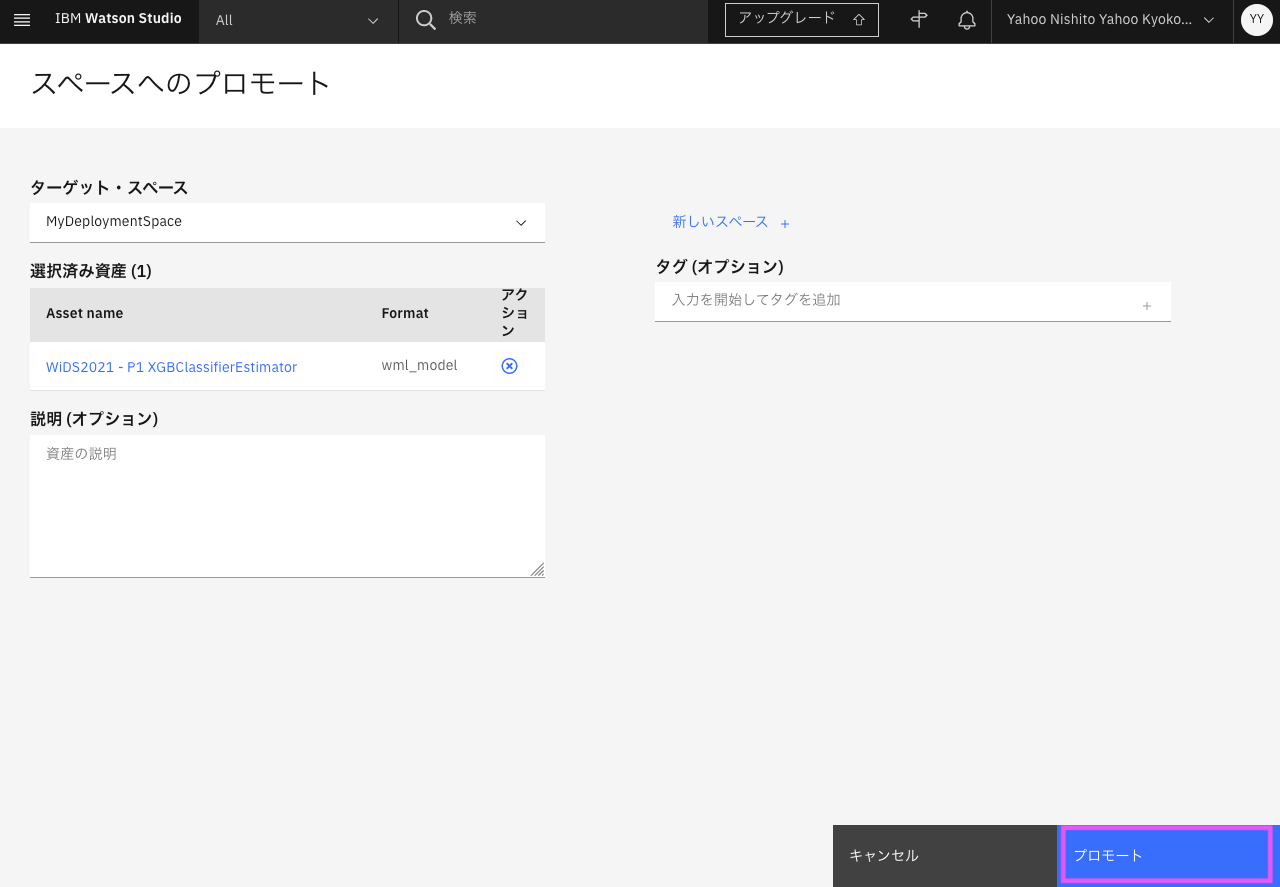
「デプロイメント・スペースに正常にプロモートされました」のメッセージが表示されれば、プロモート完了です。
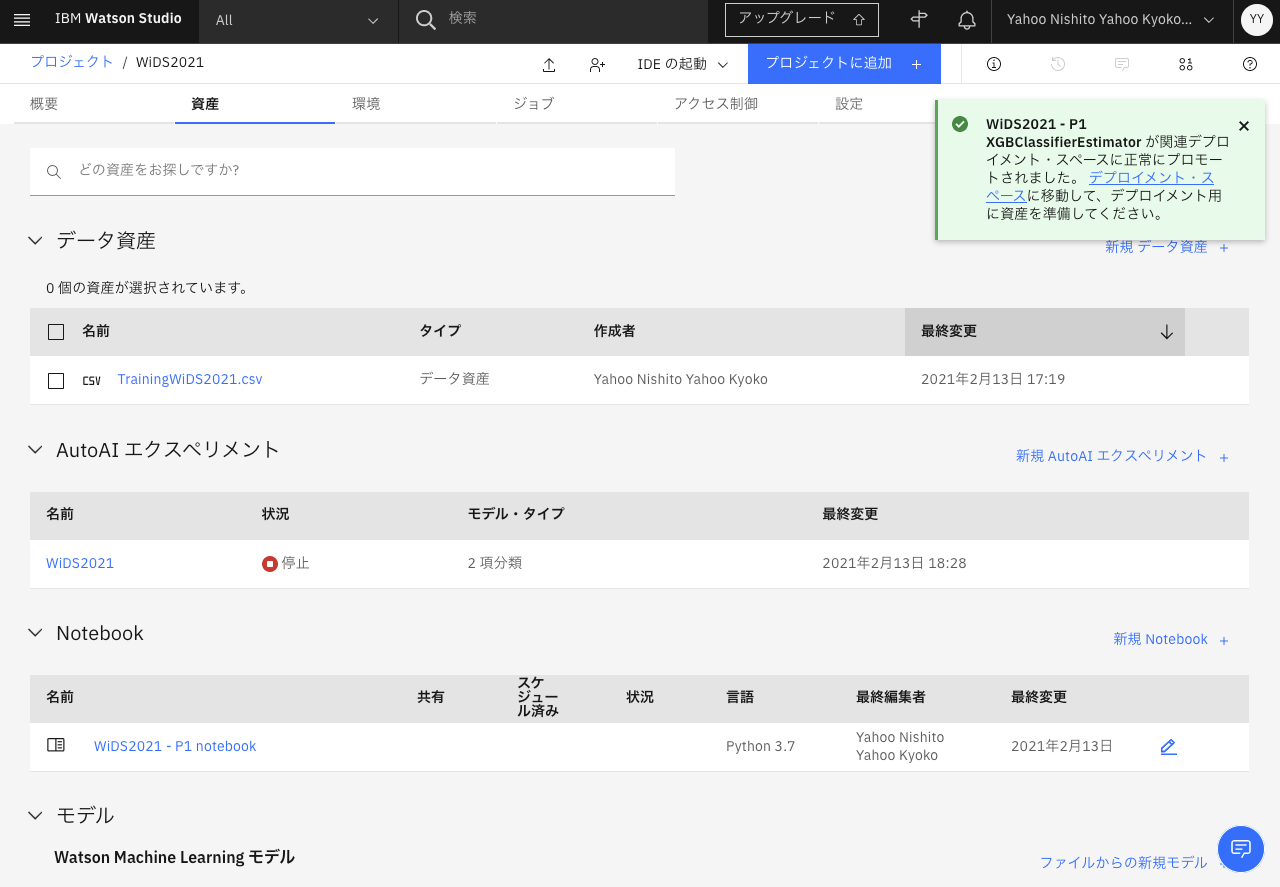
実際無料枠でできたのはここまです。
この先も無料枠で行いたい場合は、デプロイメント・スペースをエクスポートし、別の無料枠があるアカウントのWatson Studio(またはCloud Pak for Data)でデプロイメント・スペースをエクスポートしたファイルから作成して続けてください。
4. モデルのデプロイ
デプロイメント・スペースでプロモートしたモデルをデプロイします。
右上のナビゲーションメニューをクリックし、「デプロイメント・スペース」→「すべてのスペースの表示」をクリックします。
- 「すべてのスペースの表示」の下にデプロイメント・スペース名が表示されていれば、そこをクリックして直接デプロイメント・スペースを開くこともできます、
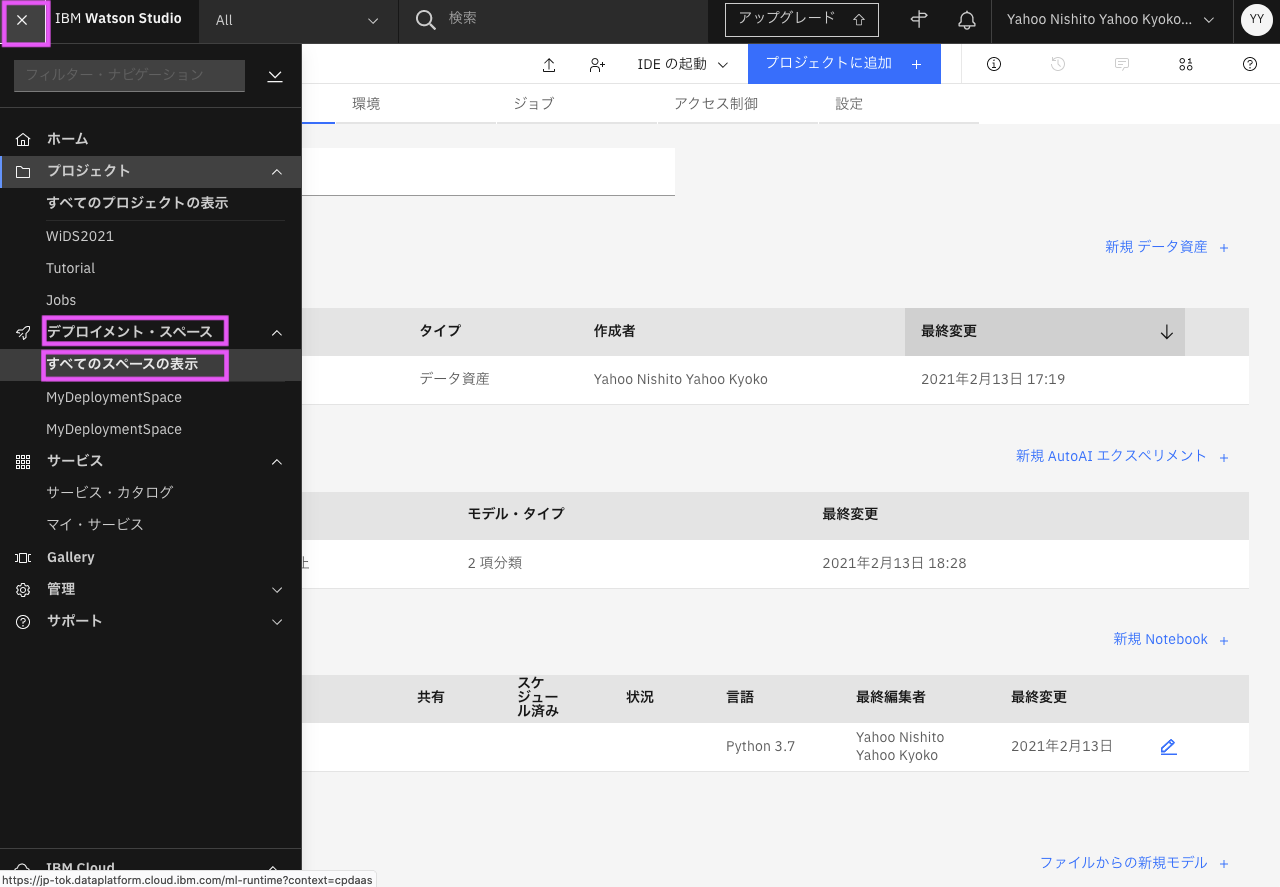
デプロイメント・スペース一覧が表示されるので、モデルをプロモートしたデプロイメント・スペース名をクリックします。
ここで後ほど使用するkaggleからダウンロードした予測すべき値が入ったファイルUnlabeledWiDS2021.csvをデプロイメント・スペースにアップロードしておきます。
ここにファイルをドロップするか、アップロードするファイルを参照します。の四角いエリアにUnlabeledWiDS2021.csvをドラッグ・アンド・ドロップします。またはここにファイルをドロップするか、アップロードするファイルを参照します。をクリックしてファイルダイアログを表示してUnlabeledWiDS2021.csvを指定します。
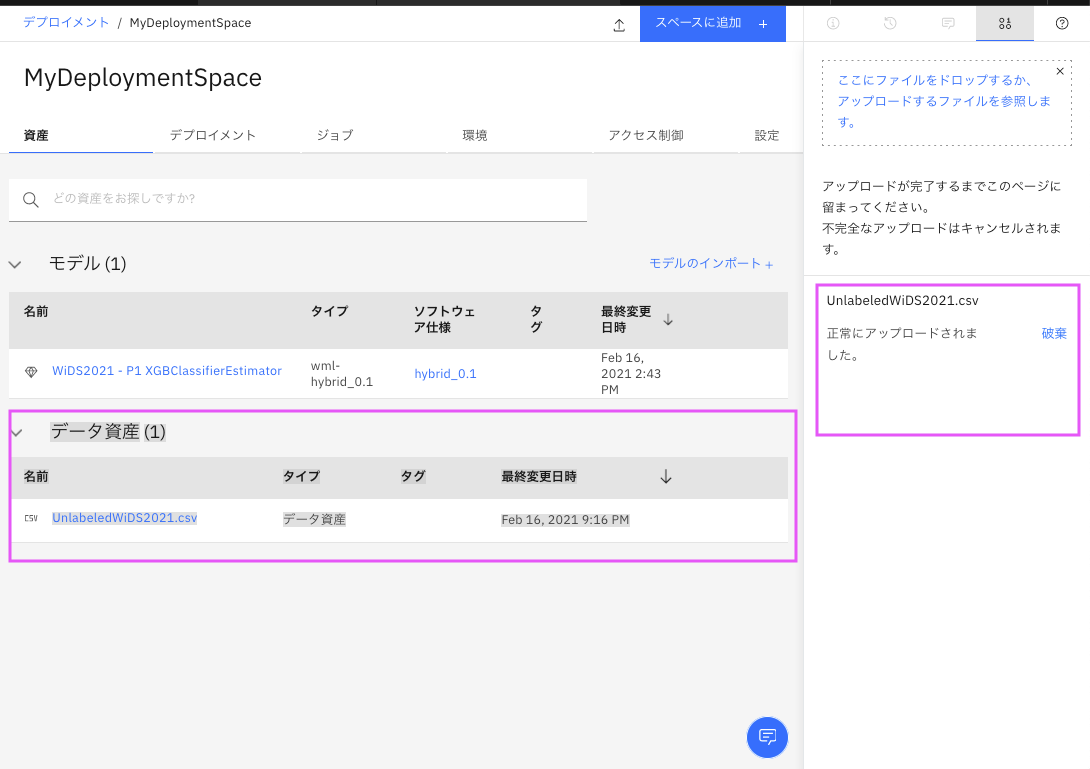
アップロードされ、「データ資産」として表示されました。
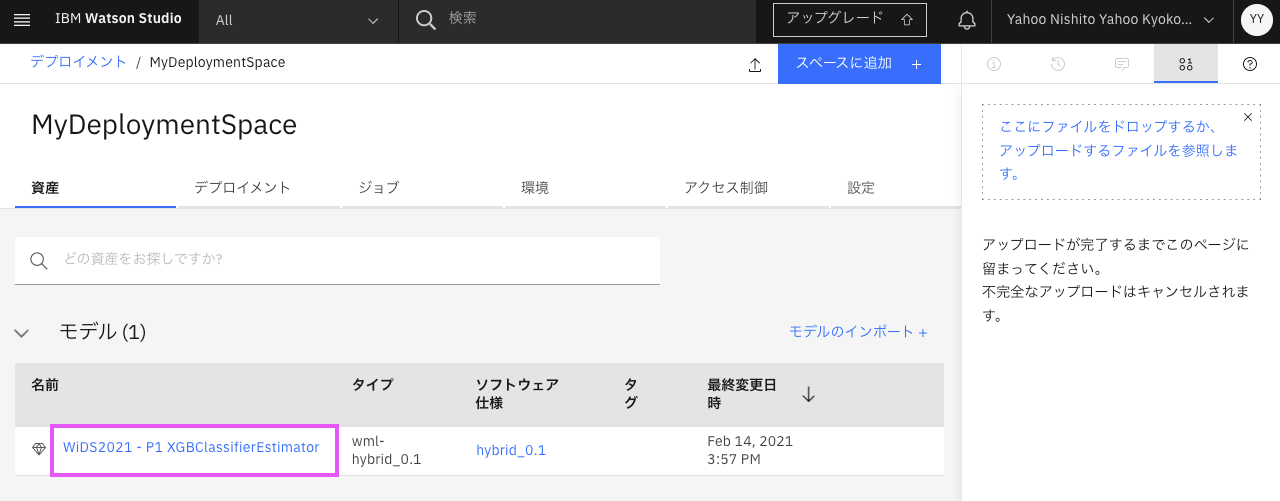
「資産」タブに表示されているプロモートしたモデル名をクリックします。
右上の「デプロイメントの作成」をクリックします。
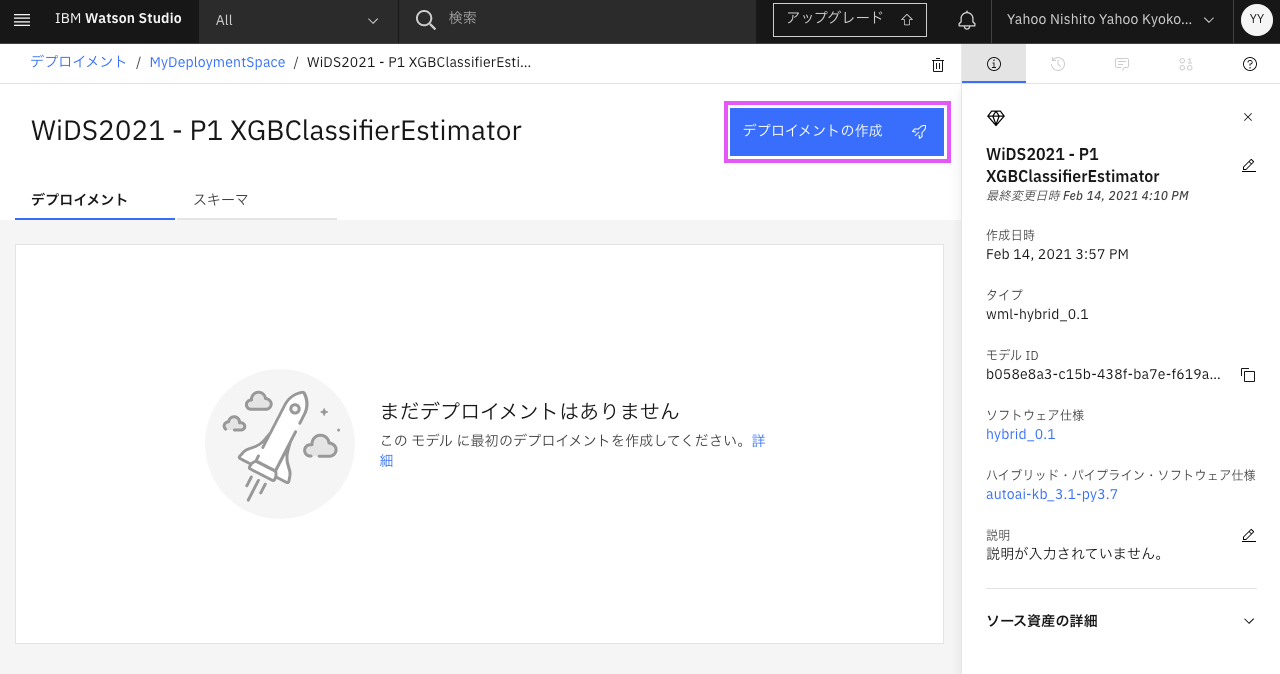
kaggleからダウンロードしたUnlabeledWiDS2021.csvをサクッと渡して結果を出したいので「デプロイメント・タイプ」は「バッチ」を選択し、名前を入力、ハードウェア定義を選択して、作成をクリックします。
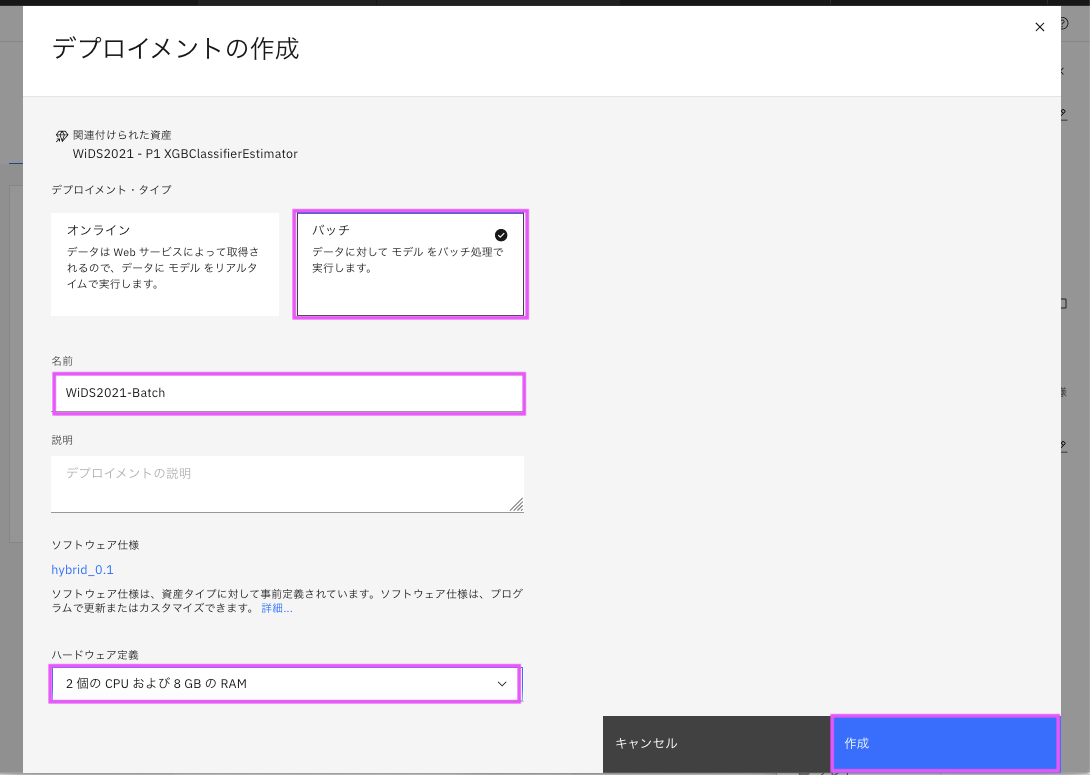
「デプロイ済み」と表示されればデプロイ完了です。
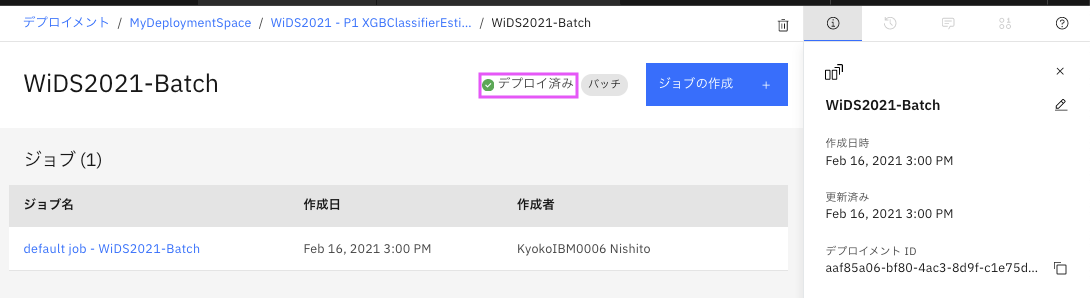
5. ジョブの実行
ジョブの作成+をクリックします。
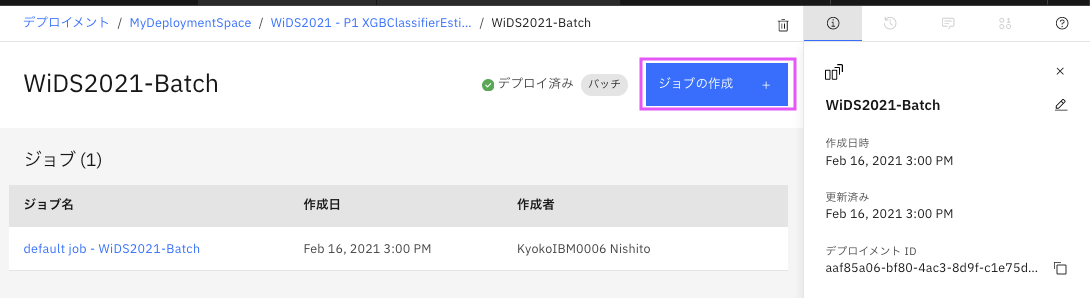
「詳細の定義」のページで「名前」を入力し、`次へをクリックします。
「構成」のページで「ハードウェア仕様」を確認し(必要に応じて変更)、`次へをクリックします。
「スケジュール」のページはそのまま、`次へをクリックします。
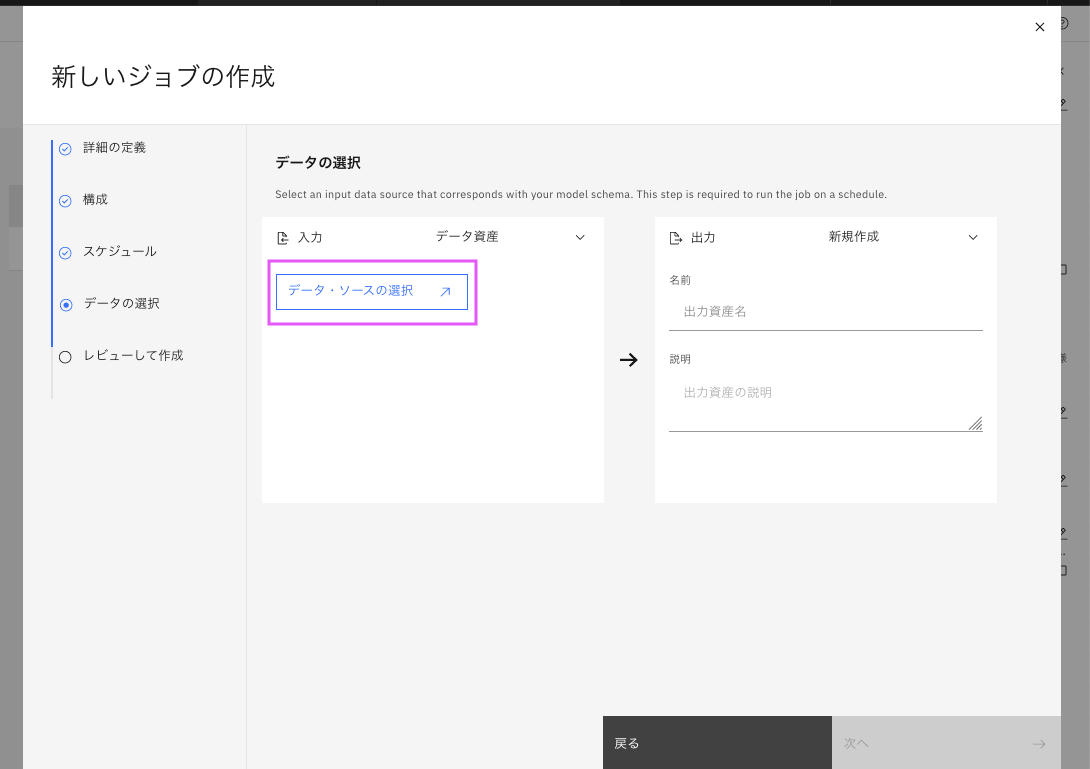
「データの選択」のページで、データ・ソースの選択をクリックします。
UnlabeledWiDS2021.csvにチェックを入れ、確認をクリックします。
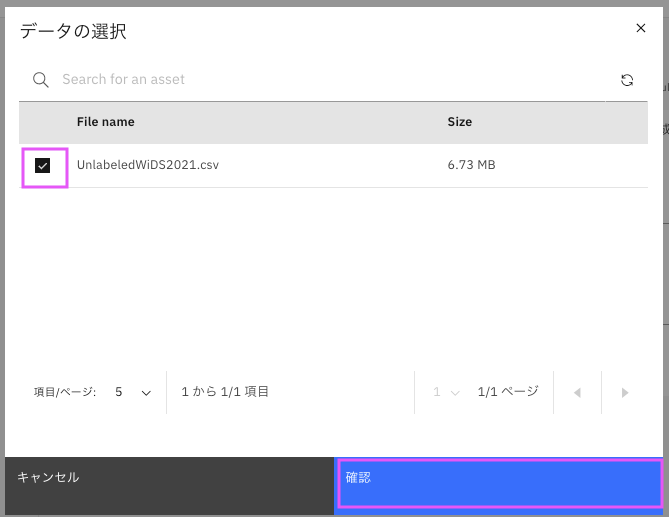
Warningが出ますが、そのままにして、出力の下にある「名前」を入力します。結果を出力するファイルの名前になります。名前を入力したら次へをクリッックします。
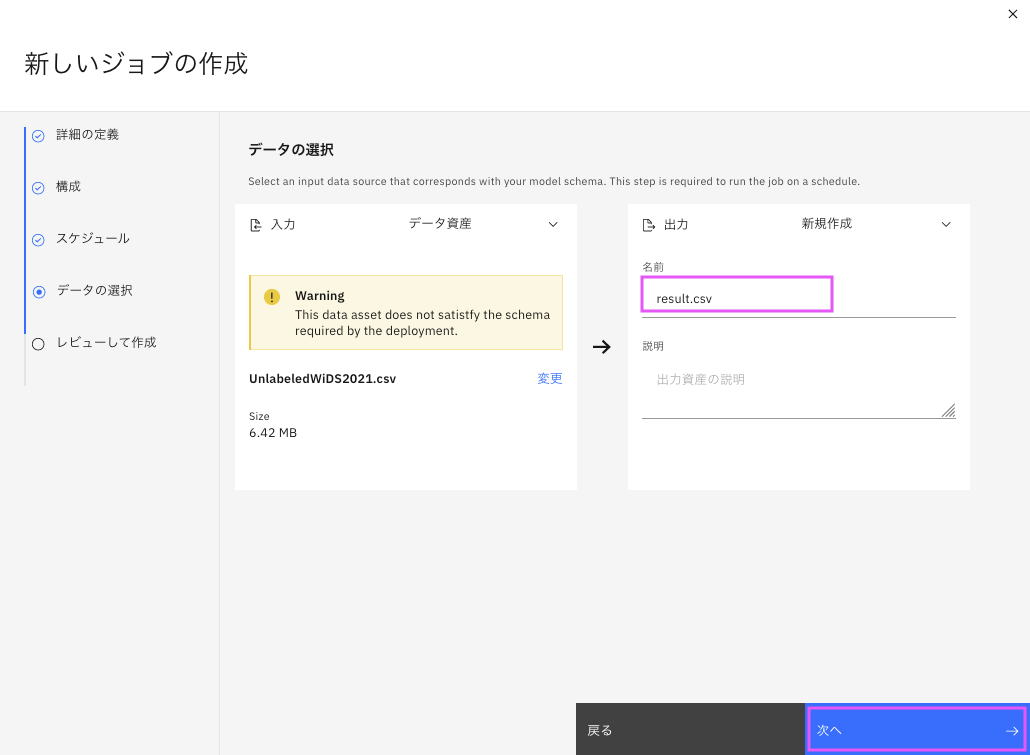
「レビューして作成」のページで確認後、作成をクリッックします。
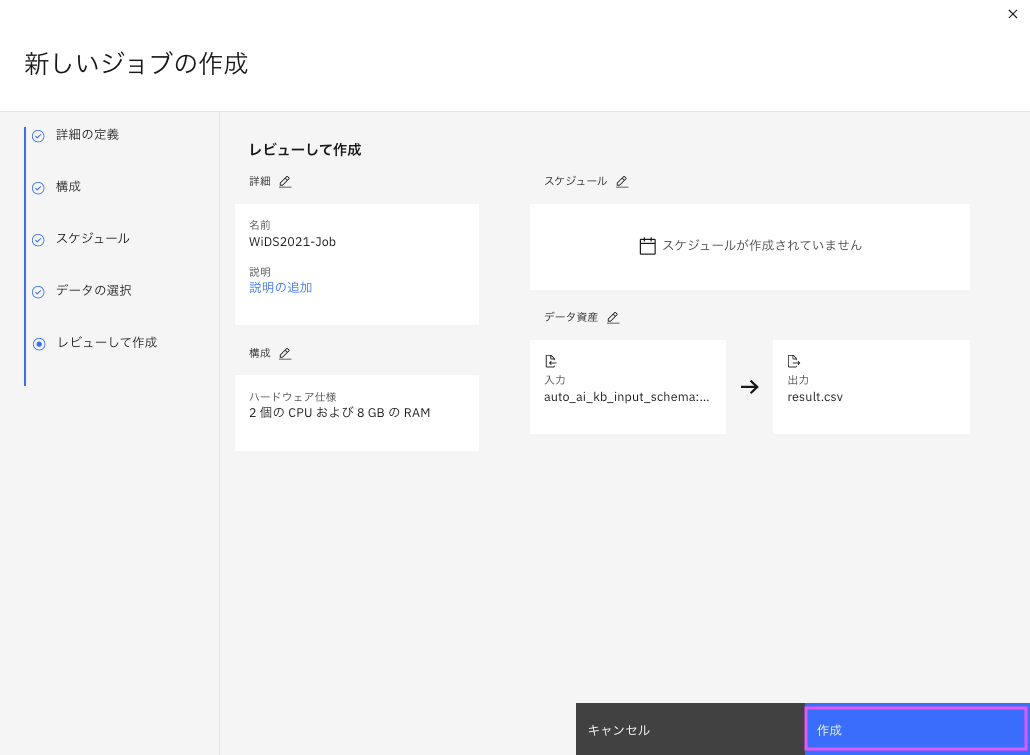
作成したジョブが一覧に表示されます。作成したジョブ名をクリックします。
ジョブの実行状況が見えます。
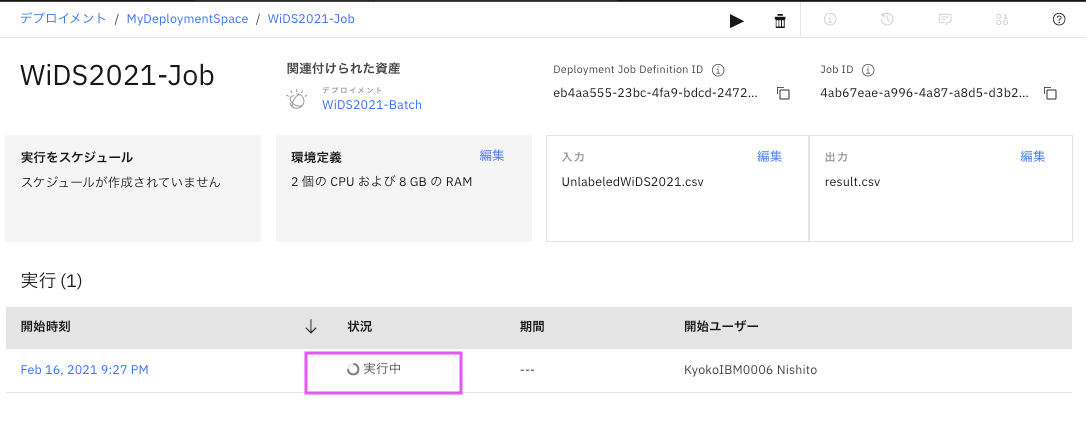
状況が「完了」になったら、上部にあるデプロイメント・スペース名をクリックします。
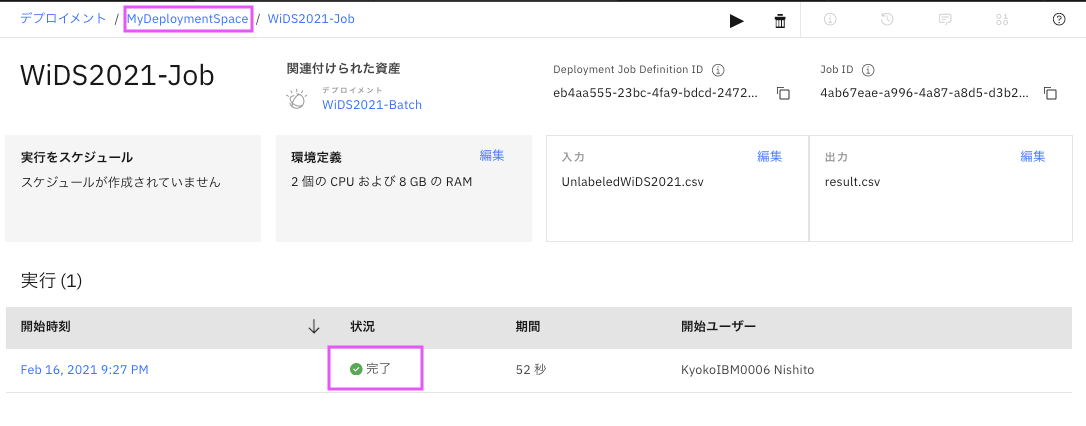
「資産」タブをクリックすると。「データ資産」にジョブで指定した出力ファイルができています。
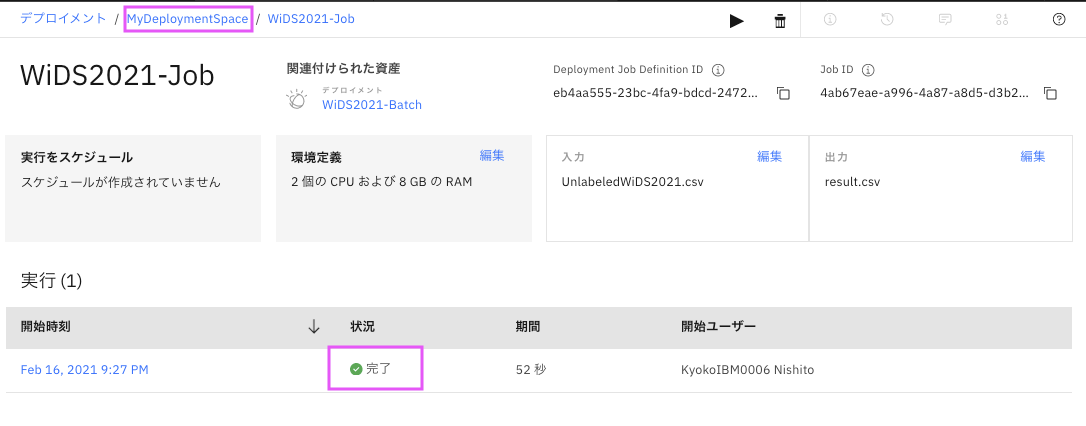
ダウンロードアイコンをクリックして、出力ファイルをダウンロードします。

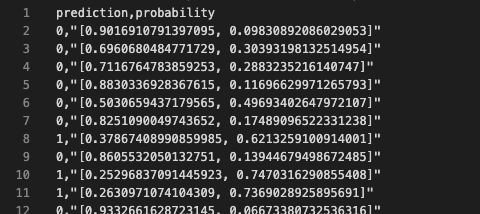
中身を確認します。predictionが予測結果で、probabilityは配列で、ラベル0、1の確信度になります。
6. 提出ファイルとしてフォーマットして、Submit
SampleSubmissionWiDS2021.csvをみるとencounter_id,diabetes_mellitus(の確率)を入れることになっていますので、この形にフォーマットします。idは出力ファイルにありませんが、入力ファイルUnlabeledWiDS2021.csvの行の順で予測されているので、この中のとencounter_idと結合して作成します。
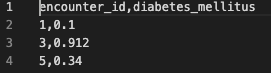
フォーマットはExcelなんかでやってもよいですが、まあここはpythonでやっておきます。
以下のコードでフォーマットしました。
mport pandas as pd
# バッチの出力ファイル
RESULT_FILE = '/Users/xxxx/WiDS_Datathon/result.csv'
# バッチの入力ファイル
INPUT_FILE = '/Users/xxxx/WiDS_Datathon/widsdatathon2021/UnlabeledWiDS2021.csv'
# Submission用に作成するファイル名
OUTPUT_FILE = '/Users/xxxx/WiDS_Datathon/submission.csv'
def create_submission_file():
df_result = pd.read_csv(RESULT_FILE)
df_input = pd.read_csv(INPUT_FILE)
df_output = pd.DataFrame()
df_output['encounter_id'] = df_input['encounter_id'].copy()
df_output['diabetes_mellitus'] = df_result['probability'].apply(lambda x: eval(x)[1]).copy()
#print(df_output[0:5])
df_output.sort_values('encounter_id', inplace=True)
df_output.reset_index(inplace=True, drop=True)
#print(df_output[0:5])
df_output.to_csv(OUTPUT_FILE, index=False)
return
if __name__ == '__main__':
create_submission_file()
作成されたsubmission.csvをWiDS Datathon2021でSubmitします。
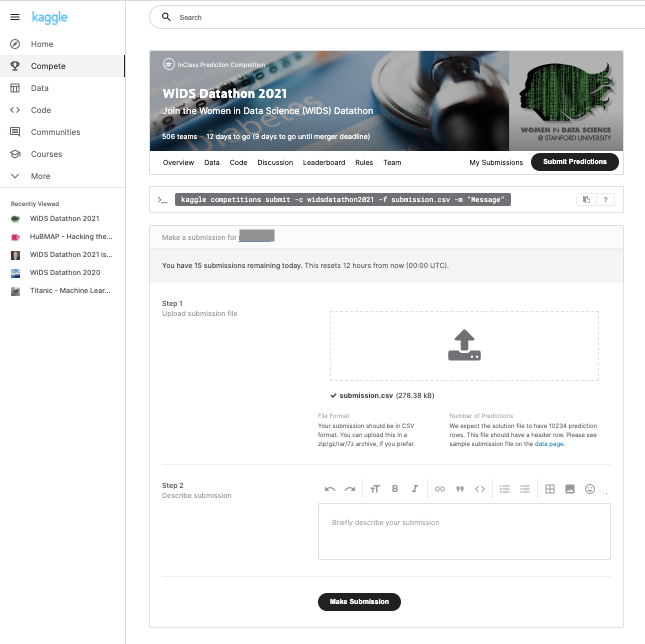
Submitの結果はScoreは0.85009、2021年2月17日現在の順位は507チーム中288位でした。
AutoAIのモデルで昨年は上位30%だったのに今年は半分以下だったので、やはり最後までモデル作成ができたものがあればという感じですね、、、。
まとめ
最後にフォーマットでCodeを書きましたが、AutoAIでkaggleに出せるそこそこ?のモデルがコーディングなしで簡単に作成できるのがわかったと思います。みなさんもkaggleにAutoAIで挑戦してみてください。入賞は難しいかもしれませんが、「そこそこ」いけます!
機械学習の腕に自身のあるかたはぜひ入賞目指して自分の力でWiDS Datathon2021にSubmitしてみてください!!
以上です。