この記事は、
『Pytorchユーザーが実験速度で悩んでるときに、Tensorflowを部分的に使ってみるの割とアリでは説』
をちょっと検証してみたという内容になります
とどのつまり(編集 2020/07/20)
ちゃんぽんの方が純粋pytorchより速かったりもしますが、いやでもやっぱ普通はフレームワーク統一した方がいいですたぶん。(可読性、コードの再利用性的に)
背景(ちょっとポエムを…本題は『やったこと』からです)
Pytorch v.s. Tensorflow
先日こんなツイートを見かけました(引用失礼します![]() )
)
TensorFlowが書きにくいというのはどういうことだろう.インターフェイスとして書きにくいというのであれば,それはないと思う,というかどのツールも正直大して変わらない.エラーの出処が深すぎて(あとデコレータでスタック改造していたりするので)デバッグできないというのは分かる.
— Yusuke Oda (@odashi_t) December 5, 2019
TF(v1)だと一度走れば完璧に動くことが期待できるのでデプロイに強いのと,いくらでもグラフの最適化の余地があるあたりが長所で,一方でこういうのは研究向けには割とどうでも良いので,実際にTFが製品・PyTorchが研究方面でよく使われているのを見ると棲み分けは出来ている気がしますね.
— Yusuke Oda (@odashi_t) December 5, 2019
ただ、企業での利用において、PyTorchでは困難なほどのグラフの最適化が要求される割合が、今後(金銭的コスト当たりの計算力や、計算力あたりの精度の向上なども考慮したうえで)どの程度変化するかで、ニーズが大きく変わる可能性もあると思っています。
— じんべえざめ (@jinbeizame007) December 5, 2019
個人的にまとめると↓こんな感じだと思ってます
- Tensorflowは速度・デプロイ重視でPytorchはデバッグしやすさ重視??(辿ればおそらくDefine-and|by-Runの話)
- ただ重たい実験はPytorchだと渋いかも…
- そんなことより、国産派はPytorch一択。(?)(ChainerがPytorchに合流することになったそうですし…)
- そんなそんなことより、深層生成モデルをPixyzで、深層強化学習をMachinaで書きたいので、問答無用でPytorch
まぁぶっちゃけ一番最後ですね!!!
Pytorch高速化の日々
- 完全に余談
- 著者はあるメタ学習手法の再現をPytorchで書いたもののクソ遅かったので、怒涛の並列化で10倍速くらいにした経験があります。これはたぶんうまくいきました(元が遅かった
 )。
)。 - 著者は別のメタ学習手法の再現をPytorchで書いたもののクソ遅くて実装もバグっていたときに、高速化ばっかして速くはなったものの結局バグったまま精度が出ず締め切りに間に合わなかった経験があります。(順番を考えましょう…)
- 著者はあるメタ学習手法の再現をPytorchで書いたもののクソ遅かったので、怒涛の並列化で10倍速くらいにした経験があります。これはたぶんうまくいきました(元が遅かった
- はいつらい。はい苦い。
Pytorchがなぜ(比較的?)遅いのか
- Define-and-Run思想の設計ゆえだと思うんですが、Tensorflowはepoch回す前の最適化が強そう
- というかPytorchは特にデータの読み込みとか前処理が遅そう
- データの
.pt/.npy化、CPUメモリ/GPUメモリに乗せておく、とかで若干は速くできるものの…
- データの
悪魔のささやき『ちゃんぽん』
- そんなときにたまたま
Tensorflow/datasetsのDataLoaderに出会い、しかもそれがtf系の形式じゃなくてnumpy形式でもイテレートしてくれるそうということを知って魔が差してしまいました…。
やったこと
-
Pytorch製のモデルと学習器 + Tensorflow製のデータローダー で、簡単なディープの実験を回してみて、純正Pytorchコードと比較しました。
- 注意!)条件はだいたい揃えていますが、必ずしも厳密に比較できているわけではない点をご了承ください。
- Tensorflow版のデータローダーには
tf.data.Dataset系を採用してます。- 興味のある方は↓を参考にしてみてください
- ドキュメント, GitHub, デフォルトで用意されてるデータセット一覧(120種類くらいあります、すごい)
環境
手元のzbox(4CPU)で実験しました。
- CUDA: 9.2
- torch: 1.3.0+cu92
- torchvision: 0.4.2+cu92
- tensorflow: 2.0.0
- tensorflow-datasets 1.3.2
インストール
pip install tensorflow-datasets
あとは普通に
実験
MNIST分類のコードを2種類書いて比較しました。
(参考: Pytorch本家のサンプルコード(をだいぶシンプルにして使いました))
- まずは共通部分のPytorchモデルのコード
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.fc1 = nn.Linear(12*12*64, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
- 続いて純正Pytorch用のメイン
def train(model, device, train_loader, optimizer, epoch):
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
print('Epoch {} Train loss: {:.6f}; '.format(epoch, loss.item()), end="")
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test loss: {:.4f}, acc: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
### ----------------
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
### ----------------
import time
def main():
device = torch.device("cuda")
### ----------------
transform=transforms.Compose([transforms.ToTensor()])
kwargs = {'num_workers': 4, 'pin_memory': True}
train_loader = DataLoader(
datasets.MNIST('../data', train=True, download=True, transform=transform),
batch_size=64, shuffle=True, **kwargs)
test_loader = DataLoader(
datasets.MNIST('../data', train=False, download=True, transform=transform),
batch_size=1000, shuffle=True, **kwargs)
### ----------------
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
start = time.time()
for epoch in range(1, 11):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
elapsed_time = time.time() - start
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()
-
### ----------------で囲まれたところが大きく変わるところです -
最後に主役のPytorch+Tensorflowのメイン
def train(model, device, train_loader, optimizer, epoch):
model.train()
n = 0 ###
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
n += len(data) ###
if n > 60000: ###
break ###
print('Epoch {} Train loss: {:.6f}; '.format(epoch, loss.item()), end="")
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
n = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
n += len(data) ###
if n > 10000: ###
break ###
test_loss /= n
print('Test loss: {:.4f}, acc: {}/{} ({:.0f}%)'.format(
test_loss, correct, n,
100. * correct / n))
### ----------------
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
tf.compat.v1.enable_eager_execution()
class MnistDataLoader():
def __init__(self, split, batch_size, epochs):
self.ds, self.info = tfds.load(name="mnist", split=split, in_memory=True, with_info=True)
self.num_examples = self.info.splits[split].num_examples
self.ds = self.ds.repeat(epochs).shuffle(self.num_examples).batch(batch_size)
self.ds = self.ds.map(
lambda x:{'image': tf.dtypes.cast(tf.transpose(x['image'], [0,3,1,2]), tf.float32) / 255.,
'label': x['label']},
num_parallel_calls=4)
self.ds = self.ds.prefetch(5)
self.ds = tfds.as_numpy(self.ds)
def __iter__(self):
return self
def __next__(self):
batch = next(self.ds)
data, target = batch['image'], batch['label']
return torch.from_numpy(data), torch.from_numpy(target)
def __len__(self):
return self.num_examples
### ----------------
import time
def main():
device = torch.device("cuda")
### ----------------
train_loader = MnistDataLoader(split="train", batch_size=64, epochs=10)
test_loader = MnistDataLoader(split="test", batch_size=1024, epochs=10)
### ----------------
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
start = time.time()
for epoch in range(1, 11):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
elapsed_time = time.time() - start
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
if __name__ == '__main__':
main()
- tfds形式のDatasetを軸に、Pytorch風のDataLoaderクラスを定義しています。
- 今回はデフォルトで用意されているMNISTクラスをロードしています。
- あとに書くように、自分でtfds形式のデータセットを用意することもできます
-
tfds.as_numpyで、tensorflow形式ではなくnp形式でイテレートできるようになります、神。
実行!
(なんと、ちゃんぽんコードは無事に動いてくれました!!!笑)
-
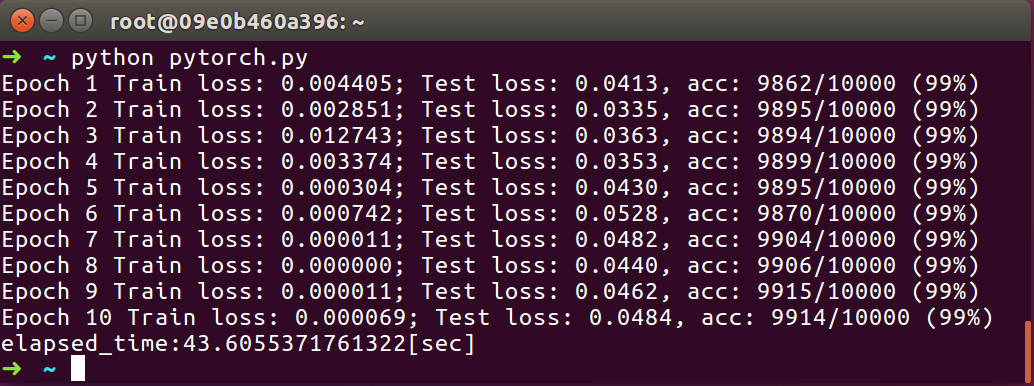
純正Pytorch
- 70.92678928375244[sec](num_workers=1)
- 43.6055371761322[sec](num_workers=4)
- 48.38671255111694[sec](num_workers=8)
- 54.59042549133301[sec](num_workers=16)
-
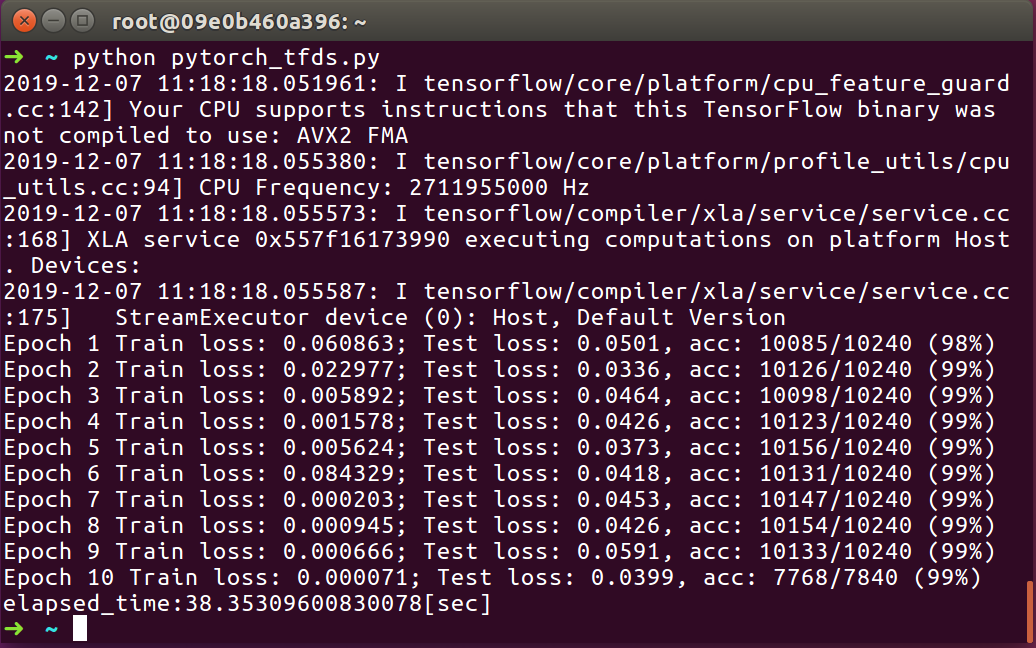
Pytorch + Tensorflow (Ours)
- 38.35309600830078[sec]
はい、やはりOutperformeしてくれました![]()
他のサーバーで回してもちゃんぽんが圧勝でした
-
Pytorch + Tensorflow
-
純正Pytorch
どこで差がついたのか…?
- 実はtfds版のほうが、epochが始まる前(タイマー圏外)にかかる時間は5秒くらい長かったです。
- がそれはepochを重ねれば誤差の範囲
- tfdsの
.prefetch()が強そう(しかも簡単!)- pytorchにもあるかもしれないけどggってもぱっとしない
- tfdsの
.map()が強そう(しかも簡単)-
__init__で.map()って言いながら実際に計算するのはprefetchの時っぽくて賢そう。
-
tfds版はもっと速くできるかも…?
-
ds.cache()でデータセットのキャッシュ化 -
tf.data.experimental.AUTOTUNEを使うと、ds.prefetch()や.map()時の並列化数を自動で決めてくれるらしい。強ひ。 - 若干チートではあるけど、
ds.shuffle()するときのバッファーサイズ(何個ずつの範囲でシャッフルするか?)を小さくすると、シャッフルが雑になるけど結構速くなる。- 少々雑にしても精度は変わらないと思う
tensorflow-datasetって自作データでも使えるの?
- Yes!
- つい先日、tensorflow-datasetの使い方について素晴らしい記事が出ていたので紹介
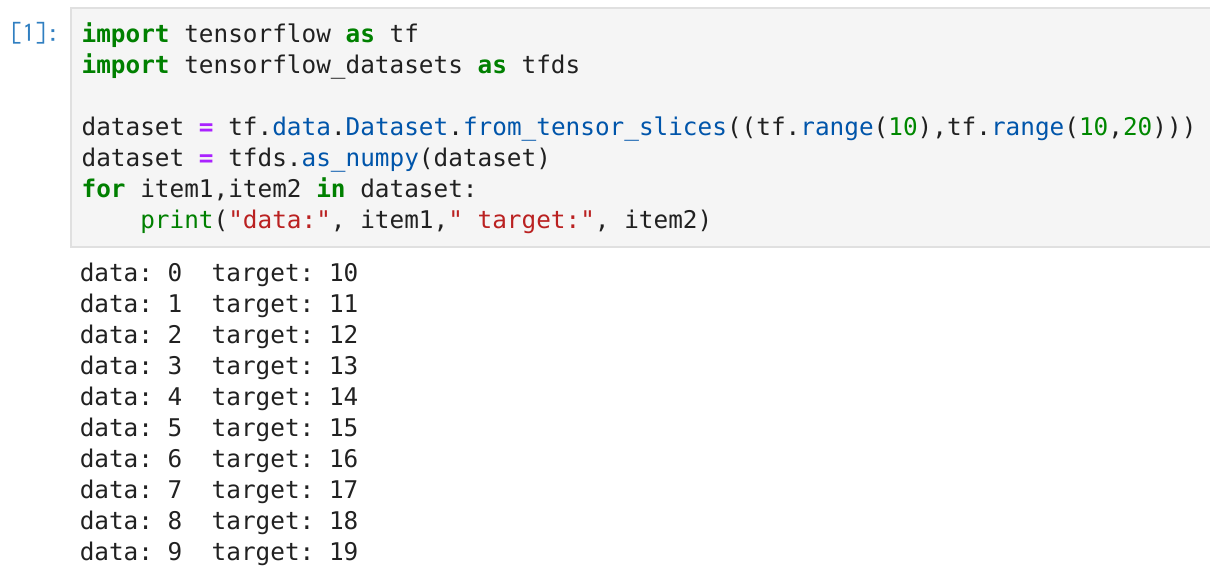
- ちょっとだけかじらせていただくと、tfds形式のデータローダーは↓な感じで簡単に用意できます
import tensorflow as tf
import tensorflow_datasets as tfds
dataset = tf.data.Dataset.from_tensor_slices((tf.range(10),tf.range(10,20)))
dataset = tfds.as_numpy(dataset)
for item1,item2 in dataset:
print("data:", item1," target:", item2)
- メモリに載り切らないデータを使う場合は、ここらへんを参考に↓を埋めたらtfdsで扱えそうです。
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version('0.1.0')
def _info(self):
# Specifies the tfds.core.DatasetInfo object
pass # TODO
def _split_generators(self, dl_manager):
# Downloads the data and defines the splits
# dl_manager is a tfds.download.DownloadManager that can be used to
# download and extract URLs
pass # TODO
def _generate_examples(self):
# Yields examples from the dataset
yield 'key', {}
まとめ
- Pytorchユーザーも、データローダーにはTensorflowを使うというのはアリかもしれないです。たぶん速いです。
- tensorflow-datasetsはデフォルトで(mnistとか以外にも)120種類くらいのデータセットが用意されていて、しかも
np形式でイテレートしてくれるので使い得な気がします。
以上!!
(twitterもよろしく)
\def\textlarge#1{%
{\rm\Large #1}
}
\def\textsmall#1{%
{\rm\scriptsize #1}
}
$\textsmall{い\ い\ ね\ ほ\ し\ い\ !}$