はじめに
2026 年 4 月の Qwen 3.6-27B Dense リリースをきっかけに 前回の記事で量子化バリアントを並べて測ったのですが、書きながら「同じ 27〜31B 帯の Dense モデルを横並びで比べないと、Qwen 3.6-27B の立ち位置が分かりにくいな」と感じていました。
DenseモデルとMoEモデルの違い(前提整理)
本記事では Dense モデルと MoE(Mixture of Experts)モデルを比較しています。
両者は内部構造が異なり、性能特性も大きく異なります。
-
Denseモデル:
全てのトークン処理で全パラメータを使用する構造。
品質が安定しやすく、挙動が予測しやすい一方で、計算コストが高くなりがち。 -
MoEモデル:
トークンごとに一部の「専門家(Experts)」のみを選択して計算する構造。
計算効率が高く、高速に動作するが、タスクによっては出力品質のばらつきが出ることがある。
一般に「速度重視ならMoE」「品質の安定性重視ならDense」と言われることが多いですが、実際にどこまで差が出るかはハードウェアや量子化設定に強く依存します。本記事では、DGX Spark 実機上で、Dense(Qwen / Gemma)と MoE の両方を同一条件で測定し、実用上どちらを選ぶべきかを検証します。特に「Denseは遅くて使えないのでは?」という前提が、量子化(Q4_K_M)によってどこまで変わるかを重点的に確認します。
過去には MoE 同士の比較を 2 本書いています。
これらの記事ではいずれも Dense モデルを意図的に避けて MoE を比較対象にしています。理由は DGX Spark の帯域律速環境で、Gemma 4-31B Dense は理論値 4.4 t/s、実測でも 3.7 t/s という NVIDIA フォーラムの計測 があり、「実用速度が出にくい」と切り捨てたためです。
ところが、Q4_K_M 量子化前提なら 27〜31B Dense でも実用速度に乗るのでは? という仮説が前回記事を書いていて出てきました。Qwen 3.6-27B Q4_K_M で tg 11.75 t/s が出ていて、これは MoE の 60 t/s 台と比べれば遅いものの、対話用途として明らかに使える速度です。それなら同サイズ帯の他の Dense でもそうなのか、品質はどう違うのか、を取り直したくなりました。
本記事はその実測ログです。Qwen 3.5-27B / Qwen 3.6-27B / Gemma 4-31B の 3 系統 × BF16 / Q4_K_M = 6 構成を、同じ DGX Spark + 最新の llama.cpp ビルド(b8922)で揃えて、速度(短文・ロング)・JCommonsenseQA・VLM の 3 軸で並べました。3 モデルとも Apache 2.0 ライセンスで、商用含めて使いやすい部類です。
この記事の結論(TL;DR)
- Q4_K_M Dense は DGX Spark で実用速度に到達しました。tg 10〜12 t/s 台で、対話用途として体感的に十分動きます。BF16 では 3.8〜4.5 t/s 帯で、確かに「日常使いには厳しい」過去記事の評価通りです。Q4_K_M / BF16 比は 2.6〜2.8 倍ありました。
- JCommonsenseQA(Thinking OFF)では Gemma 4-31B が頭ひとつ抜け、 BF16 で 98.12%、Q4_K_M でも 97.77% でした。ただし 11 構成比較で最高〜最低差は 2.14 ポイント(24 問)、 JCQ では各モデルがある程度の精度に張り付きやすく、量子化や MoE / Dense の差はこの範囲ではほぼ誤差レンジです。
- 量子化(BF16 → Q4_K_M)による JCQ 劣化は 0.2〜0.6 ポイントで、誤差レンジに近い結果でした。Qwen 3.6-27B では BF16 の方が Q4_K_M より僅かに低い(96.69% vs 96.87%)という逆転も見られましたが、差は 2 問なのでノイズの範囲と見るのが無難です。
- ロングプロンプト(pp512 → pp16384)の劣化率は、Qwen 系で -3〜-6%、Gemma 4 で -12〜-13%。Qwen 系は long でも素直に伸び、Gemma 4 はやや落ち幅が大きいという結果でした。
- VLM(Q4_K_M のみ)では JSON 抽出は 3 モデルとも parse 100%、PPE 検出は Qwen 3.5 / Gemma 4 が 1/3、Qwen 3.6 が 0/3。サンプル 3 件と少ないため目安にとどめますが、Qwen 3.6-27B の Q4_K_M は今回のセットでは PPE スキーマで形が崩れる傾向が見えました。
1. なぜ「Dense 27-31B」を取り直したか
過去記事 1 本目(Gemma 4 vs Qwen 3.5 MoE 対決)では、Gemma 4 シリーズに含まれる 31B Dense モデルを意図的に対象から外しました。理由は同記事で書いた以下の表の通りで、帯域律速の物理から見て tg 4 t/s 前後しか出ないと判断したためです。
| モデル | アーキテクチャ | Active パラメータ | 毎トークン読み出し | 理論 tok/s |
|---|---|---|---|---|
| Qwen 3.5-35B-A3B MXFP4 | MoE | 3B | ~3 GB | ~91 |
| Gemma 4 26B-A4B F16 | MoE | 3.8B | ~8 GB | ~34 |
| Gemma 4 31B BF16 | Dense | 30.7B | ~62 GB | ~4.4 |
しかし、前回記事(Qwen 3.6-27B 量子化別比較)で Qwen 3.6-27B Q4_K_M の tg が 11.75 t/s 出ていたのを見て、状況が変わったと感じました。Q4_K_M に量子化するとメモリから読む量が約 1/4 弱になるため、Dense でも tg 10 t/s 台に乗ってきます。同じ理屈は Gemma 4-31B にも当てはまるはずで、Q4_K_M なら 10 t/s 前後出る計算です。
これは推測ではなく、過去記事の MoE 比較で出した「理論値 = メモリ帯域 ÷ Active パラメータのメモリサイズ」の延長で、**Q4_K_M Dense は DGX Spark にとって新しいスイートスポットになるのでは?**という仮説が出てきます。今回はそれを 3 モデルで実測してみた、という位置づけです。
帯域律速のおさらい:
理論値 = メモリ帯域 ÷ Active パラメータのメモリサイズ
DGX Spark のメモリ帯域: 約 273 GB/s
Gemma 4-31B BF16: 273 ÷ ~62 GB ≈ 4.4 t/s → 実測 3.82 t/s(87% 効率)
Gemma 4-31B Q4_K_M: 273 ÷ ~17 GB ≈ 16 t/s → 実測 10.65 t/s(67% 効率)
Qwen 3.6-27B BF16: 273 ÷ ~54 GB ≈ 5.0 t/s → 実測 4.54 t/s(91% 効率)
Qwen 3.6-27B Q4_K_M: 273 ÷ ~17 GB ≈ 16 t/s → 実測 11.85 t/s(74% 効率)
BF16 は帯域効率がほぼ理論値に近づく一方、Q4_K_M は 67〜74% で頭打ちになる傾向が見えます。Q4_K_M の方が CUDA カーネル側の演算オーバーヘッドが乗りやすいため、と考えられます。それでも実測で Q4_K_M Dense なら 10〜12 t/s 帯に達しており、対話用途としては十分実用的です。
2. llama.cpp の最近の動き(b8892 → b8922)
本検証では llama.cpp を 前回記事 時点の b8892 から b8922 に更新しました。約 1 週間のあいだに 30 タグが切られており、目についた範囲での主なトピックを簡単に整理しておきます。
-
server: heap-buffer-overflow 修正(CVE-2026-21869、#22267) —
n_discardが負値で渡された場合の領域外アクセス。llama-server を外部公開している環境では確実に当てたい修正です - server: anthropic API のプレフィックスキャッシュ修正(#21793) — Anthropic 互換 API でキャッシュが効かない不具合の修正
- server: SWA-full ロジック修正(#22288) — Sliding Window Attention のフル展開時の挙動修正、Gemma 系列に関係
- CUDA: fuse relu + sqr(#22249) — relu + sqr の融合カーネル追加。本記事の 6 構成に対する影響は誤差範囲だったため、リグレッションテストでも差は出ませんでした
- HIP: graphs default ON(#22254) — AMD ROCm 環境のデフォルト挙動変更。AMD 環境を併用している方は影響あり
- SYCL: oneAPI 2025.3.3 更新 / MoE mul_mat_vec_q 融合(#21920) — Intel GPU 環境向けの大きめ更新
DGX Spark / CUDA 環境にとっての直接の性能影響は今回小さく、b8892 と b8922 で Qwen 3.6-27B Q4_K_M の pp512 / tg128 をリグレッションテストで再計測した結果も誤差レンジに収まっています(pp512: 825.89 → 818.80、tg128: 11.90 → 11.88)。とはいえ、llama-server の CVE 修正は確実に追従しておきたいため、今回の測定はすべて b8922(commit 13d36cf89、CUDA、SM121a) で揃えました。
3. 検証環境
| 項目 | 内容 |
|---|---|
| ハードウェア | NVIDIA DGX Spark(GB10、Grace + Blackwell、統合メモリ 128 GB) |
| OS | NVIDIA DGX OS(Ubuntu 24.04.3 LTS ベース、aarch64) |
| カーネル | 6.14.0-1015-nvidia |
| CUDA | 13.0 |
| llama.cpp |
b8922(commit 13d36cf89、ソースビルド、CUDA、SM121a) |
| 品質テスト | JCommonsenseQA v1.1(1,119 問、5 択、3-shot) |
| VLM テスト | キャプション生成 / JSON 抽出 / PPE 検出(8 画像) |
ビルドコマンド(過去記事と同じです):
cmake -B build \
-DGGML_CUDA=ON \ # CUDA バックエンド有効化
-DGGML_CUDA_FA_ALL_QUANTS=ON \ # Flash Attention を全量子化で有効
-DCMAKE_CUDA_ARCHITECTURES=121 \ # GB10(compute capability 12.1)向け
-DGGML_CUDA_F16=ON \ # FP16 CUDA カーネル有効化
-DGGML_NATIVE=ON \ # ホスト CPU(Grace Arm)向け最適化
-DCMAKE_BUILD_TYPE=Release
cmake --build build -j $(nproc) \
--target llama-server llama-bench llama-cli llama-mtmd-cli
CMAKE_CUDA_ARCHITECTURES=121 は cmake 側で 121a に置換され、GB10 のネイティブアーキになります。
4. テストしたモデル(6 構成)
| # | モデル | 量子化 | 重みサイズ | ソース |
|---|---|---|---|---|
| 1 | Qwen 3.5-27B(Dense) | Q4_K_M | 15.58 GiB | unsloth |
| 2 | Qwen 3.6-27B(Dense) | Q4_K_M | 15.65 GiB | unsloth |
| 3 | Gemma 4-31B(Dense) | Q4_K_M | 17.39 GiB | ggml-org |
| 4 | Qwen 3.5-27B(Dense) | BF16 | 50.10 GiB | unsloth |
| 5 | Qwen 3.6-27B(Dense) | BF16 | 50.10 GiB | unsloth |
| 6 | Gemma 4-31B(Dense) | BF16 | 57.18 GiB | ggml-org |
JCQ は 6 構成すべてで実測、VLM は Q4_K_M の 3 モデルのみ実測しました。VLM BF16 は 1 サンプルあたり 200 秒級の時間が見込まれ、サンプル数を確保するためのコストが高いので別記事に回します。
5. 速度: llama-bench
llama-bench は llama.cpp に付属するベンチマークツールで、推論エンジンの API オーバーヘッドを含まない素の処理速度を計測できます。プロンプト処理(pp、prompt processing)とトークン生成(tg、token generation)の 2 つの指標を別々に測れるため、用途に合わせた性能特性が見えやすいのが特徴です。
計測コマンド:
llama-bench -p 512 -n 128 -ngl 99 -fa 1 -mmp 0 -r 5 -m <model.gguf>
-
-ngl 99: 全レイヤを GPU にオフロード(DGX Spark は統合メモリなので BF16 でも余裕で載ります) -
-fa 1: Flash Attention 有効 -
-mmp 0: mmap 無効(計測ノイズ低減のため) -
-r 5: 5 回計測の平均
5-1. 短文(pp512 / tg128)
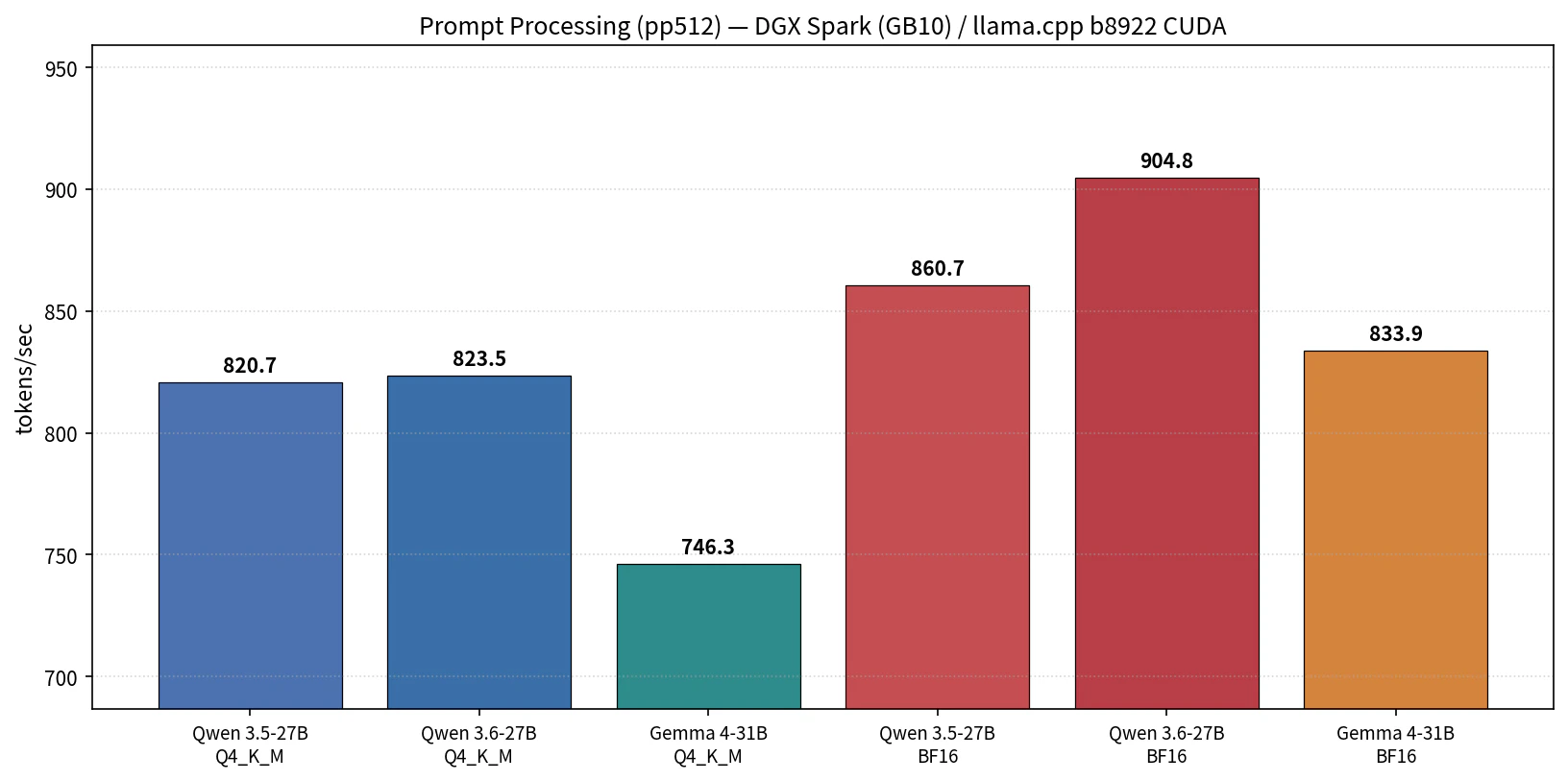
図1: pp512 比較(6 構成)
- BF16 が pp で全モデル上位(833〜905 t/s)、Q4_K_M はその 5〜12% 下(746〜823 t/s)
- Qwen 3.6-27B BF16 が 904.8 t/s で 6 構成中の最速
- Gemma 4-31B は BF16・Q4_K_M とも Qwen 27B 系より約 8% 遅く、これはパラメータ数(30.7B vs 26.9B)の差がそのまま乗っている
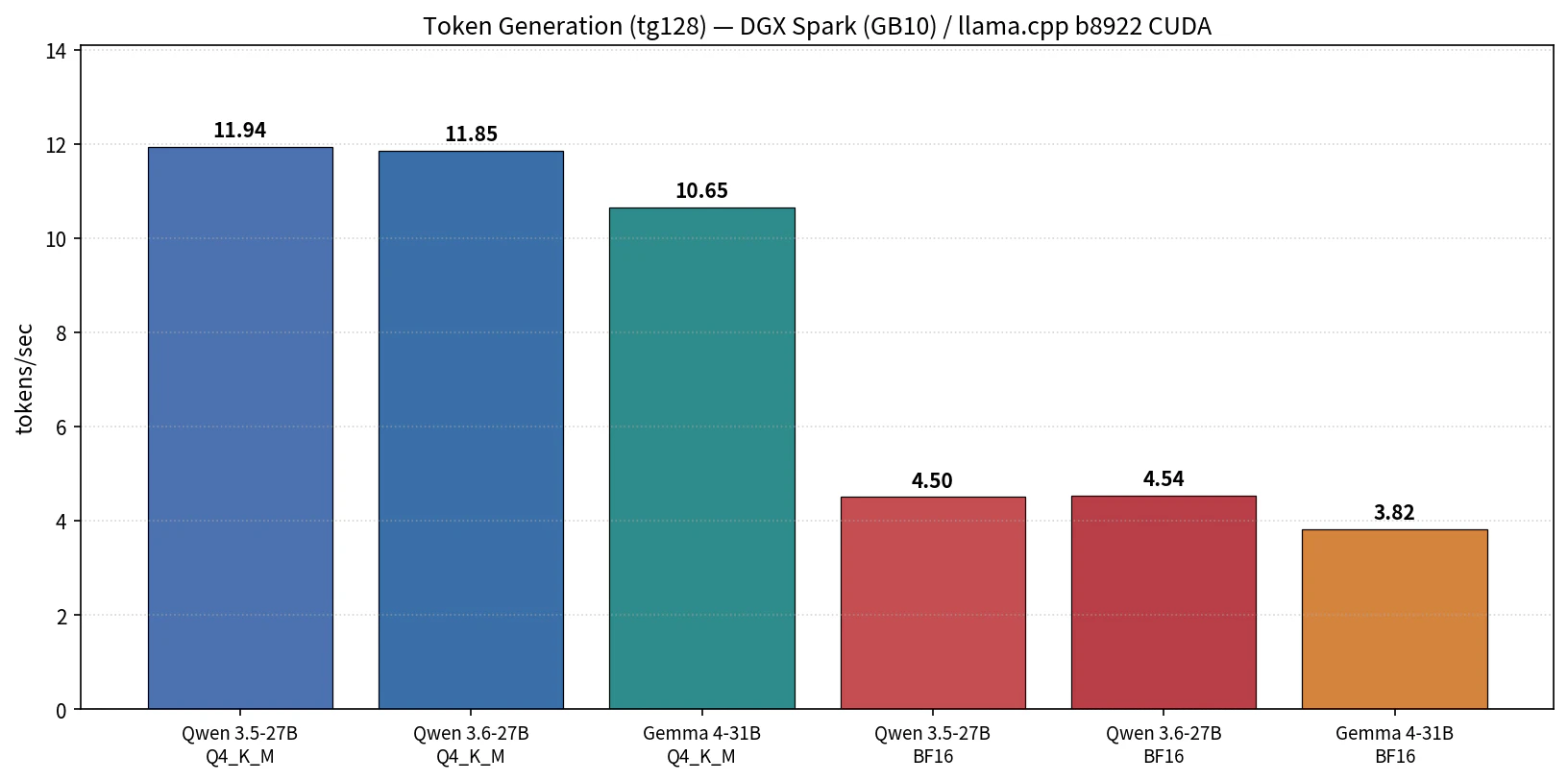
図2: tg128 比較(6 構成)
- Q4_K_M が tg で 2.6〜2.8 倍速い(11 t/s 台 vs 4 t/s 台)
- Qwen 3.5 と Qwen 3.6 はほぼ同等(11.94 vs 11.85)。同一アーキテクチャ系列なので想定通り
- Gemma 4-31B は Qwen 27B 系より tg で約 11% 遅い
| モデル | 量子化 | pp512(t/s) | tg128(t/s) |
|---|---|---|---|
| Qwen 3.5-27B | Q4_K_M | 820.68 ± 5.53 | 11.94 ± 0.01 |
| Qwen 3.6-27B | Q4_K_M | 823.49 ± 7.86 | 11.85 ± 0.01 |
| Gemma 4-31B | Q4_K_M | 746.31 ± 2.29 | 10.65 ± 0.01 |
| Qwen 3.5-27B | BF16 | 860.67 ± 7.42 | 4.50 ± 0.00 |
| Qwen 3.6-27B | BF16 | 904.80 ± 6.42 | 4.54 ± 0.00 |
| Gemma 4-31B | BF16 | 833.90 ± 5.82 | 3.82 ± 0.00 |
- tg は Q4_K_M が圧勝(2.6〜2.8 倍)で、これは想定通りです。Q4_K_M Dense なら 10〜12 t/s 帯に乗り、対話用途として体感的に問題なく動きます。
-
pp は BF16 が 5〜12% 程度速い結果でした。前回の Qwen 3.6-27B 単体比較でも同じ傾向で、Blackwell の BF16 テンソルコア(
-DGGML_CUDA_F16=ONでビルドしている前提)が pp 側で効いている可能性があります。ただし pp の差は実用上ほぼ気にならない範囲だと思います。 - Qwen 3.5 と 3.6 は速度面でほぼ同等で、これは前回の MoE 世代間比較(Qwen 3.5 vs 3.6 MoE)と同じ向きです。アーキテクチャ系列が同じだと当然の結果と言えます。
5-2. ロングコンテキスト・スケーリング(pp512 → pp16384)
長文プロンプトを処理する場合、pp スループットがどれだけ低下するかを見る指標です。RAG や長文要約のように 8K〜16K のコンテキストを扱う用途では、短文ベンチだけでなくこのロング側の挙動を確認しておく必要があります。
前回の MoE 世代間比較 では、Qwen 3.6 MoE が pp512 → pp16384 の劣化率を -6.2% → -2.4% に縮めたという改善が一番のハイライトでした。今回の Dense でも同じ傾向が出るか気になっていたところです。

図3: プロンプト長に対する pp スループットの推移(6 構成)
- Qwen 3.5 / 3.6-27B は BF16・Q4_K_M とも 16K まで素直に伸び、劣化率は -3〜-6% の範囲に収まる
- Gemma 4-31B は BF16・Q4_K_M とも -12〜-13% と他より落ち幅が大きい(SWA + Global Attention のハイブリッド構成が長文側のコストとして効いていそう)
- Qwen 3.6 は 3.5 より僅かに劣化が小さい(-6.2% → -4.1%)。MoE で見た改善方向と同じ向きだが、MoE の -6.2% → -2.4% ほどの大きな縮小ではない
| プロンプト長 | Q3.5 Q4 | Q3.6 Q4 | G4 Q4 | Q3.5 BF16 | Q3.6 BF16 | G4 BF16 |
|---|---|---|---|---|---|---|
| pp512 | 812 | 801 | 740 | 898 | 898 | 850 |
| pp2048 | 808 | 800 | 723 | 914 | 913 | 872 |
| pp4096 | 802 | 805 | 706 | 919 | 913 | 843 |
| pp8192 | 793 | 797 | 684 | 894 | 893 | 806 |
| pp16384 | 762 | 768 | 650 | 870 | 866 | 738 |
| 劣化率(512→16K) | -6.2% | -4.1% | -12.2% | -3.1% | -3.6% | -13.2% |
いずれの構成も pp16384 で 650〜870 t/s 帯のスループットを維持しており、Dense 27〜31B + Q4_K_M なら RAG や長文要約の用途でも実用域に入る感触です。
5-3. 速度まとめ
| 観点 | 結果 |
|---|---|
| tg | Q4_K_M が 2.6〜2.8 倍速い(11 t/s 台 vs 4 t/s 台) |
| pp(短文) | BF16 が 5〜12% 速いが、Q4_K_M も 700〜820 t/s 帯で十分 |
| pp(16K) | Qwen 系 -3〜-6%、Gemma 4 -12〜-13%。Qwen 系が安定 |
結論として、日常運用は Q4_K_M を主軸にして、必要な場面で BF16 を選ぶ運用がフィットしそうです。これは MoE で見た傾向(MXFP4 メイン)と同じ思想で、量子化前提が Dense でも成立する、という確認になりました。
5-4. 過去記事との比較:速度性能
過去記事で測定した MoE 3 モデル(Qwen 3.5/3.6-35B-A3B MXFP4、Gemma 4-26B-A4B F16)を、同じ DGX Spark + 同じ llama.cpp ビルド(b8922)で再測定し、今回の Dense 6 構成と並べてみました。同じハード・同じビルドで揃えることで、Active パラメータ規模の差が tg / pp にどう効くかが見えやすくなります。
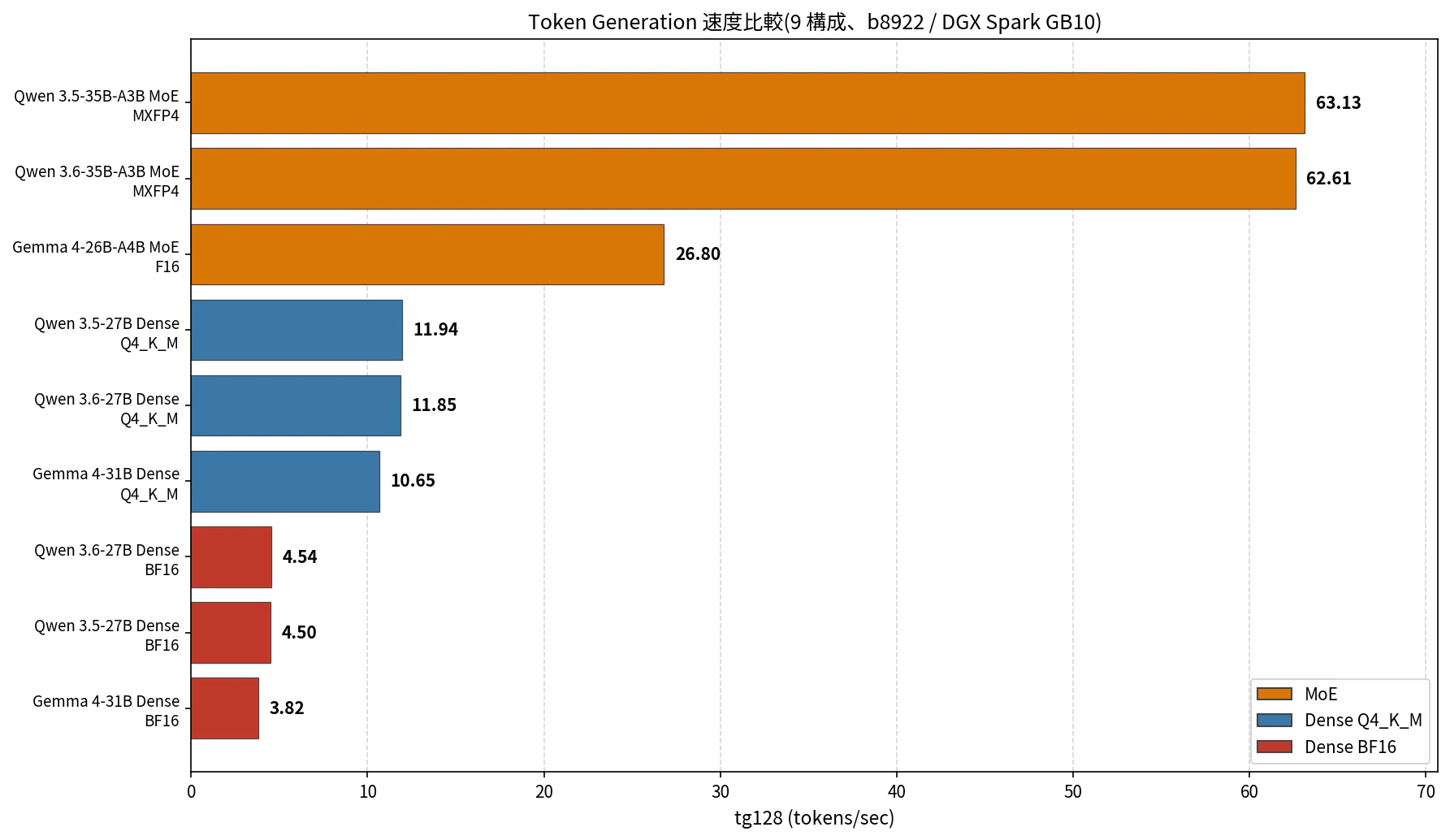
図4: tg128 速度比較(9 構成、Dense と MoE を同一環境で並列)
- MoE(Qwen 3.5/3.6-35B-A3B、Active 3B)が tg で圧倒的に速い(60+ t/s)。Active パラメータが 3B 前後なので帯域律速の影響が小さい
- Gemma 4-26B-A4B MoE F16(Active 3.8B)は MXFP4 系より遅い(26.80 t/s)が、Dense Q4_K_M(10〜12 t/s)より 2 倍以上速い。Active サイズ × 量子化精度の組み合わせで決まる
- Dense Q4_K_M(11〜12 t/s)は MoE より遅いものの、対話用途として十分実用的。BF16 Dense は 4 t/s 台で日常使いには厳しいラインに留まる
| モデル | アーキテクチャ | 量子化 | pp512(t/s) | tg128(t/s) | 出典 |
|---|---|---|---|---|---|
| Qwen 3.5-35B-A3B | MoE | MXFP4 | 2,300.99 | 63.13 | 今回(取り直し) |
| Qwen 3.6-35B-A3B | MoE | MXFP4 | 2,289.18 | 62.61 | 今回(取り直し) |
| Gemma 4-26B-A4B | MoE | F16 | 1,456.66 | 26.80 | 今回(取り直し) |
| Qwen 3.6-27B | Dense | BF16 | 904.80 | 4.54 | 今回 |
| Qwen 3.5-27B | Dense | BF16 | 860.67 | 4.50 | 今回 |
| Gemma 4-31B | Dense | BF16 | 833.90 | 3.82 | 今回 |
| Qwen 3.6-27B | Dense | Q4_K_M | 823.49 | 11.85 | 今回 |
| Qwen 3.5-27B | Dense | Q4_K_M | 820.68 | 11.94 | 今回 |
| Gemma 4-31B | Dense | Q4_K_M | 746.31 | 10.65 | 今回 |
- MoE の優位性は tg で顕著(MXFP4 で 62〜63 t/s)。これは過去記事 ② で測定した値(63.17 / 62.91)と完全に整合し、b8892 → b8922 のビルド差では誤差レンジ
- pp(短文)では MoE が Dense BF16 の約 2.5 倍。pp は MoE の 35B 全パラメータが効くため、Dense BF16(27〜31B)より速い計算上の理由がある
- Dense Q4_K_M と MoE F16(Gemma 4-26B-A4B)の tg を比べると 2.5 倍(10.65 vs 26.80)。Active 3.8B(F16)≈ Active 30.7B(Q4_K_M)というサイズ感の差が、そのまま速度差に反映している
DGX Spark のような帯域律速環境では、**「同じパラメータ規模なら MoE の方が常に速い」**という構造的な傾向が、9 構成の比較で改めて確認できました。Dense 27〜31B Q4_K_M も対話用途として十分使えますが、最高速度を狙うなら MoE 一択です。
6. 品質: JCommonsenseQA(Thinking OFF)
JCommonsenseQA(JCQ)とは何を測るベンチマークか:
JCommonsenseQA v1.1 は、日本語の常識推論能力を 5 択問題で評価するベンチマークデータセットです。1,119 問あり、3-shot プロンプト(回答例を 3 つ示してから本問を解かせる方式)で正答率を集計します。日本語 LLM の品質評価を行う標準ベンチとして過去記事でもすべての日本語性能評価で使ってきました。コーディングや数学の能力は別軸で見る必要がありますが、「日常的な日本語のやり取りで筋の通った回答ができるか」 という一次評価には十分使えると思います。
llama-server の起動コマンド例:
~/llama.cpp-b8922/build/bin/llama-server \
-m <model.gguf> \
--host 0.0.0.0 --port 8080 \
-ngl 99 -fa on -c 4096 \
--jinja \
--reasoning-format deepseek \
--chat-template-kwargs '{"enable_thinking":false}' \
--temp 0.7 --top-p 0.8 --top-k 20
-
-ngl 99: 全レイヤを GPU にオフロード -
-fa on: Flash Attention 有効 -
-c 4096: コンテキスト長(JCQ 3-shot で十分収まる) -
--jinja: モデル内蔵テンプレートを使う(Thinking 制御に必要) -
--chat-template-kwargs '{"enable_thinking":false}': Thinking OFF - サンプリングは Qwen 公式推奨値(Gemma 4 でも同条件で揃えました)
評価には前回記事と同じ jcq_bench.py を使い、llama-server の OpenAI 互換 API 経由で 1,119 問を自動評価しています。
6-1. 6 構成の正答率
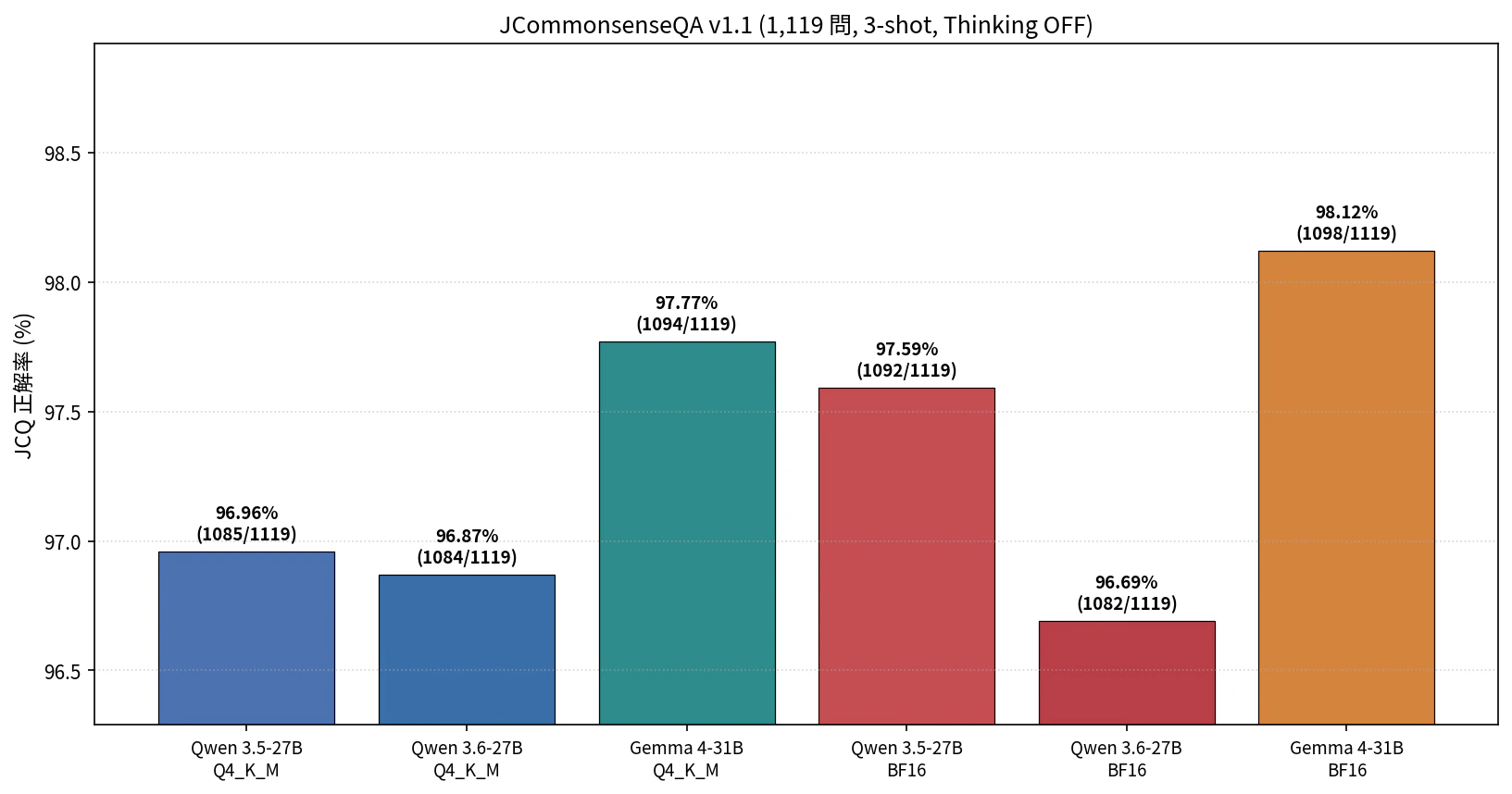
図5: JCQ 正答率比較(Y 軸 96.5〜98.5% にズーム)
- Gemma 4-31B が頭ひとつ抜けている(BF16 98.12%、Q4_K_M 97.77%)。Qwen 系の BF16(96.69〜97.59%)を上回る
- 量子化(BF16 → Q4_K_M)による劣化は 0.2〜0.6 ポイントと小さく、JCQ では誤差レンジに近い
- Qwen 3.6-27B では BF16(96.69%)が Q4_K_M(96.87%)より低い逆転。差は 2 問でノイズの可能性が高いが、「BF16 が必ず勝つ」とは限らない
| モデル | 量子化 | 正解数 / 1,119 | 正解率 |
|---|---|---|---|
| Gemma 4-31B | BF16 | 1098 | 98.12% |
| Gemma 4-31B | Q4_K_M | 1094 | 97.77% |
| Qwen 3.5-27B | BF16 | 1092 | 97.59% |
| Qwen 3.5-27B | Q4_K_M | 1085 | 96.96% |
| Qwen 3.6-27B | Q4_K_M | 1084 | 96.87% |
| Qwen 3.6-27B | BF16 | 1082 | 96.69% |
- Gemma 4-31B が頭ひとつ抜けている点について、3B ぶんの追加パラメータ(31B vs 27B)が効いているのか、JCQ が Gemma 系の得意領域に近いのか、のどちらかと思います。前者の可能性が高そうですが、断定はできない範囲です。
- 量子化による劣化が小さいのは、前回の Gemma 4 F16 vs Q4_K_M(Gemma 4 vs Qwen 3.5 MoE 比較記事)でも 0.11 ポイント差で、JCQ のような知識系 5 択では量子化の影響が小さいという傾向を再現しています。
- Qwen 3.6-27B の BF16 vs Q4_K_M 逆転は、前回の Qwen 3.6-27B 単体比較でも同じ向きの結果でしたので、再現性のある観測と言えそうです。
- Qwen 3.5 と 3.6 の差は誤差レンジ(0.1 ポイント程度)。MoE 版でも世代間差は誤差範囲だったので、Dense でも同じ傾向です。
6-2. 過去記事との比較:日本語性能
参考値として、同じ DGX Spark 環境で測った他モデルを並べておきます(すべて Thinking OFF)。

図6: 同じ DGX Spark 環境での JCQ 正答率比較(今回 6 構成 + 過去記事 4 構成)
- Gemma 4-31B BF16 が今回・過去記事を通じて 1 番(98.12%)、Nemotron 3 Super 120B(97.86%)を上回る
- Dense > MoE の傾向が出ている(Dense 27〜31B が 96.7〜98.1% 帯、MoE 35B-A3B が 95.98〜96.16%)
- 量子化精度差は小さい(Q4_K_M が BF16 を逆転する例もある)。サイズ・アーキテクチャ選びが量子化選びより優先順位が高そう
| モデル | 量子化 | JCQ OFF | 出典 |
|---|---|---|---|
| Gemma 4-31B Dense | BF16 | 98.12% | 今回 |
| Nemotron 3 Super 120B | Q4_K_M | 97.86% | 過去記事 v2 |
| Gemma 4-31B Dense | Q4_K_M | 97.77% | 今回 |
| Qwen 3.5-27B Dense | BF16 | 97.59% | 今回 |
| Qwen 3.6-27B Dense | UD-Q4_K_XL | 97.05% | 前回記事 |
| Qwen 3.5-27B Dense | Q4_K_M | 96.96% | 今回 |
| Qwen 3.6-27B Dense | Q4_K_M | 96.87% | 今回 |
| Qwen 3.6-27B Dense | BF16 | 96.69% | 今回 |
| Gemma 4-26B-A4B MoE | F16 | 96.51% | 過去記事 ① |
| Qwen 3.5-35B-A3B MoE | MXFP4 | 96.16% | 過去記事 ①② |
| Qwen 3.6-35B-A3B MoE | MXFP4 | 95.98% | 過去記事 ② |
11 構成を並べてみると、最高(Gemma 4-31B BF16: 98.12%)と最低(Qwen 3.6-35B-A3B MoE: 95.98%)の差は 2.14 ポイント、1,119 問換算で 24 問 にとどまります。日本語常識 5 択という JCQ の性質上、ある程度のサイズ(20B クラス以上)があれば横並びになる傾向で、量子化精度や MoE / Dense の選択による差はこの範囲では誤差レンジに近い と捉えるべきだと思います。
その上で、ざっくりした傾向としては:
- Gemma 4-31B が頭ひとつ抜けている (BF16 98.12%、Q4_K_M 97.77% で、いずれも 2 位以下を 0.3 ポイント以上引き離している)
- Dense > MoE の方向性 は出ている(Dense 27〜31B が 96.7〜98.1% 帯、MoE 35B-A3B が 95.98〜96.16% 帯)が、差は最大でも 2 ポイント程度
- 量子化精度の影響は 0.6 ポイント以下 で、Qwen 3.6 のように Q4_K_M が BF16 を上回る(96.87% vs 96.69%)逆転も起きる
JCQ は知識・常識タスクなので、コーディングや長文整合性のような「より差が出やすい指標」と組み合わせて評価すべきで、本記事の数値だけで「どれが優れている」とは言いにくい範囲です。
7. VLM
VLM(Vision Language Model)ベンチで何を測るか:
VLM は画像 + テキストをまとめて扱える Multi-modal LLM のことで、本記事ではその中でも 3 種類のタスクで挙動を見ます。Caption 生成は画像の内容を自由文で説明させる古典的な評価軸、JSON 抽出は構造化出力(指定スキーマで location / subjects / technologies などを抽出)できるかという業務応用寄りの軸、PPE 検出は専門領域(安全管理)での画像解析を JSON で報告できるかという更に応用寄りの軸です。Caption は出力品質の感触、JSON / PPE はパース成功率と内容の妥当性を見ます。
過去記事で使ったのと同じ展示会写真 5 枚(CEATEC 2025 等で自分が撮影)と作業現場写真 3 枚(PPE 検出用フリー素材)を使い、3 つのタスクを実施しました。
-
Caption — 日本語キャプション生成(展示会写真 5 枚、
max_tokens=1024) - JSON 抽出 — 構造化タグ抽出(展示会写真 5 枚、location / subjects / technologies 等)
- PPE 検出 — 安全保護具の着用状況判定(作業現場写真 3 枚、JSON 出力)
llama-server に --mmproj を追加して起動します:
~/llama.cpp-b8922/build/bin/llama-server \
-m <model.gguf> \
--mmproj <mmproj.gguf> \
--host 0.0.0.0 --port 8080 \
-ngl 99 -fa on -c 8192 \
--jinja
-
--mmproj: マルチモーダルプロジェクタ(画像エンコーダの重み)。これがないと画像入力を処理できません -
-c 8192: 画像 + プロンプトで 3〜5K トークン使うので、コンテキスト長を多めに取りました
7-1. VLM 性能比較(Q4_K_M Dense 3 モデル)
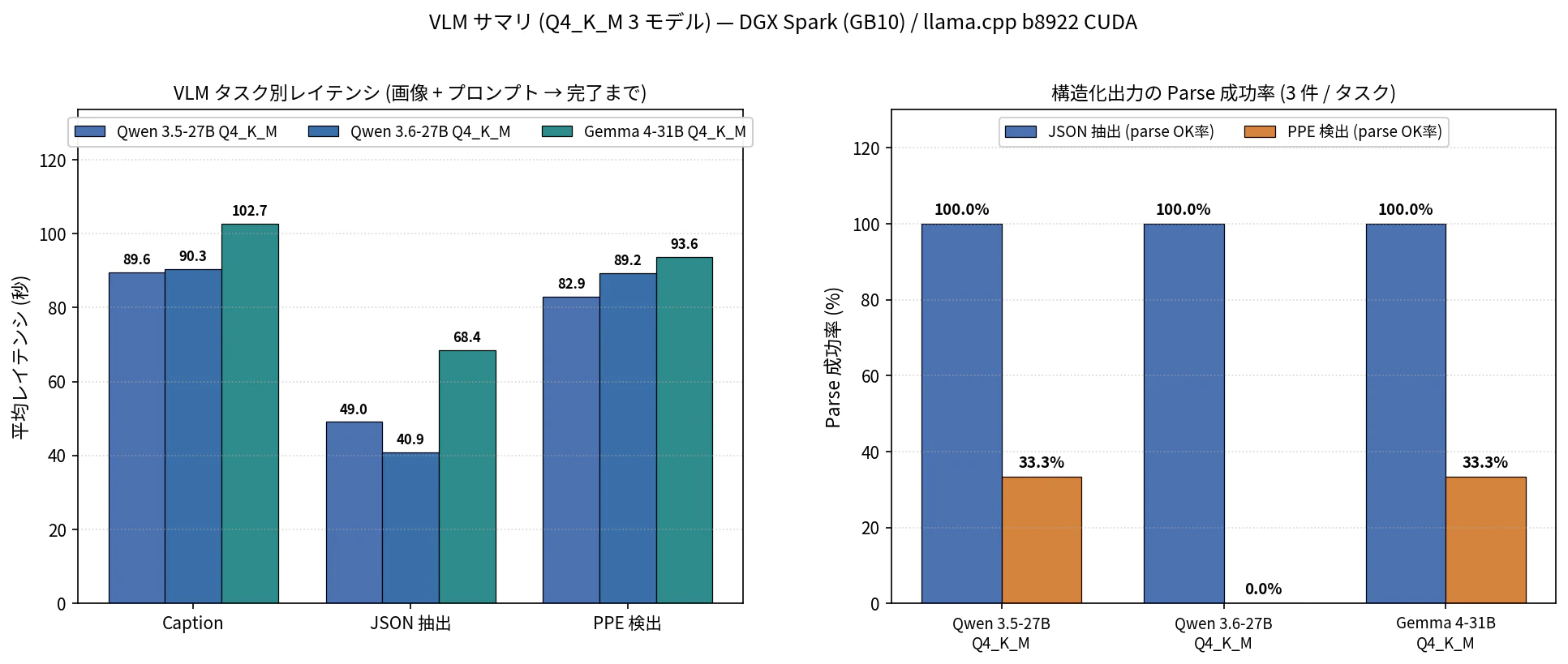
図7: VLM タスク別レイテンシと parse 成功率(Q4_K_M 3 モデル)
- JSON 抽出は 3 モデルとも parse 100%。スキーマに沿った構造化出力という点では、3 モデルとも安定している
- PPE 検出は Qwen 3.5 / Gemma 4 = 1/3、Qwen 3.6 = 0/3。Qwen 3.6 は JSON 形式自体は出るものの、PPE スキーマに沿った内容で組み上がらないケースが目立った
- レイテンシは Qwen 系 < Gemma 系(Caption 89.6〜90.4 秒 vs 102.7 秒)。Caption は max_tokens=1024 を使い切る挙動が混じっており、tg の差(11.85 vs 10.65 t/s)がそのまま反映されている
| モデル | Caption(s) | JSON(s) | PPE(s) | JSON parse | PPE parse |
|---|---|---|---|---|---|
| Qwen 3.5-27B Q4_K_M | 89.60 | 49.05 | 82.86 | 100% | 33.3% |
| Qwen 3.6-27B Q4_K_M | 90.35 | 40.86 | 89.18 | 100% | 0.0% |
| Gemma 4-31B Q4_K_M | 102.66 | 68.40 | 93.61 | 100% | 33.3% |
サンプル 3 件と少ないため断定は避けたいですが、画像 + 専門領域の構造化出力という用途では Qwen 3.5 / Gemma 4 のほうが今回のセットでは扱いやすかったように見えます。
7-2. 過去記事との比較:VLM 性能
過去記事で測定した MoE 3 モデル(Qwen 3.5/3.6-35B-A3B MXFP4、Gemma 4-26B-A4B F16)を b8922 で再測定し、今回の Dense Q4_K_M 3 モデルと並べました。VLM はビルド更新で挙動が変わりやすい(--mmproj 周りで頻繁に修正が入る)ため、同一ビルドでの再評価が比較には重要です。
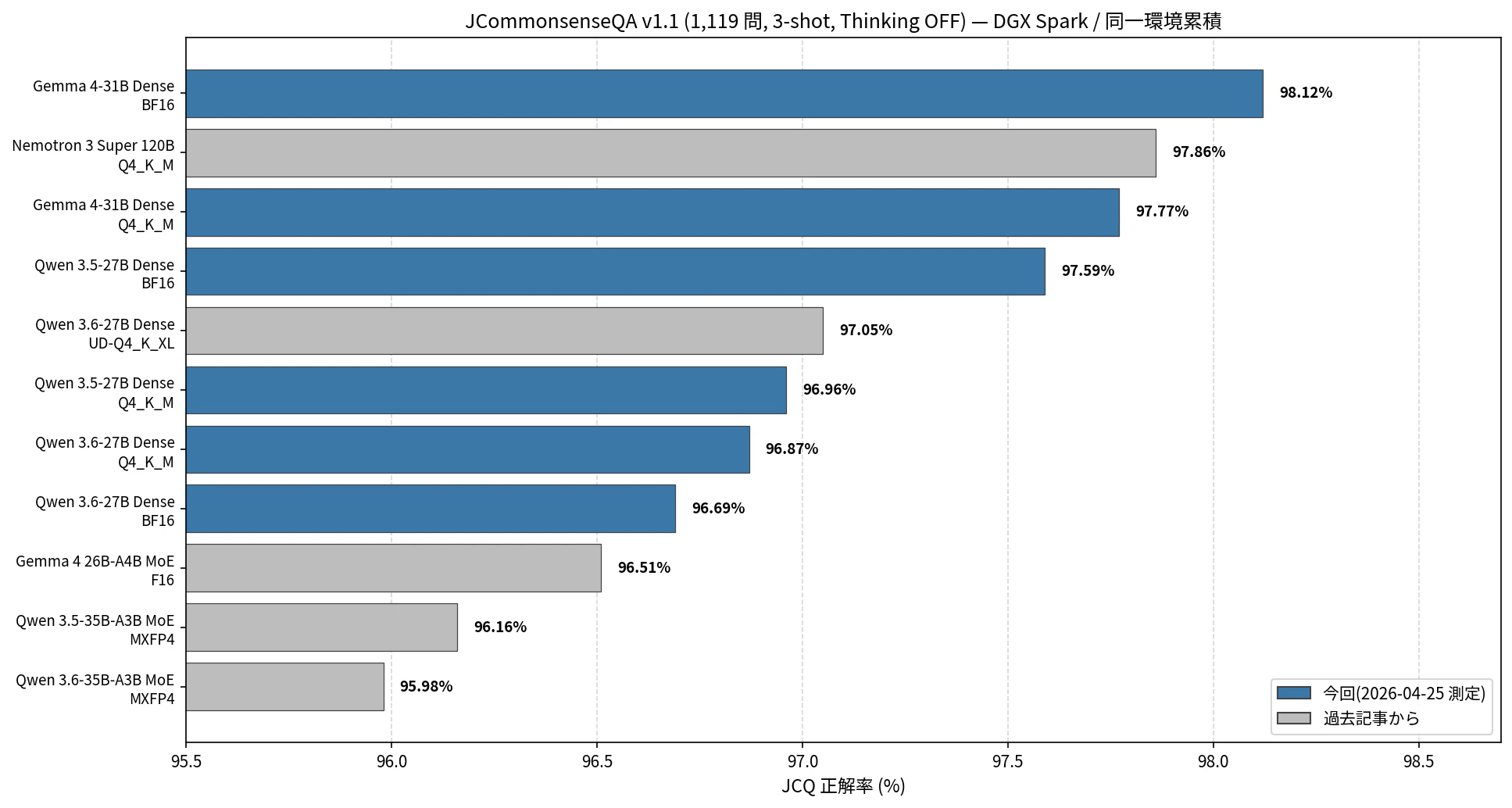
図8: VLM Caption レイテンシと JSON / PPE parse 成功率(6 構成、b8922)
-
MoE は Caption レイテンシが圧倒的に短い(17.98〜21.45 秒)。Active パラメータが 3B 前後で生成側が速いため、
max_tokens=1024上限まで生成しても短時間で完了する - JSON 抽出 parse 率は Dense Q4_K_M がトップ(全モデル 100%)。MoE は Qwen 3.5 で 80%、Qwen 3.6 で 60%、Gemma 4-26B-A4B で 40% と差が出る
- PPE 検出は全構成で 0〜33% と総じて厳しい。専門領域の構造化出力はモデル能力依存で、量子化精度や Active パラメータの差ではあまり傾向が見えない
| モデル | アーキテクチャ | 量子化 | Caption(s) | JSON parse | PPE parse | 出典 |
|---|---|---|---|---|---|---|
| Qwen 3.5-35B-A3B | MoE | MXFP4 | 17.98 | 80.0% | 33.3% | 今回(取り直し) |
| Qwen 3.6-35B-A3B | MoE | MXFP4 | 21.45 | 60.0% | 0.0% | 今回(取り直し) |
| Gemma 4-26B-A4B | MoE | F16 | 40.14 | 40.0% | 33.3% | 今回(取り直し) |
| Qwen 3.5-27B | Dense | Q4_K_M | 89.60 | 100% | 33.3% | 今回 |
| Qwen 3.6-27B | Dense | Q4_K_M | 90.35 | 100% | 0.0% | 今回 |
| Gemma 4-31B | Dense | Q4_K_M | 102.66 | 100% | 33.3% | 今回 |
- JSON 抽出の安定性は Dense Q4_K_M が一段高い(全構成で parse 100%)。MoE は parse 失敗パターンが残っており、特に Gemma 4-26B-A4B F16 は 40% と落ちる
-
Gemma 4-26B-A4B F16 の JSON parse は過去記事 ① 時点(b8665)では 0% だったため、b8922 までの間に 40% まで改善しています。
--mmproj周りの修正が効いている可能性があります -
Caption レイテンシは MoE と Dense で 4〜5 倍の差。Caption が遅い理由の多くは
max_tokens=1024を使い切る挙動なので、出力長で揃えて評価したい場合は max_tokens を増やすか、プロンプトで応答長を制御する必要があります - PPE 検出は Qwen 3.6 が両アーキテクチャ(MoE / Dense)で 0%。Qwen 3.6 は PPE スキーマに苦戦する傾向が見える(サンプル 3 件と少ないため断定はできませんが、再現性のある観察)
「画像 + 構造化出力」用途では、Dense Q4_K_M(JSON parse 100%)を主軸にして、レスポンス速度を優先するなら MoE Q4_K_M / MXFP4 を選ぶ運用が良さそうです。
8. 用途別の目安(個人の感想レベル)
日常用途(チャット / 文章生成 / コード)
- 基本は Q4_K_M を選ぶのがバランス良さそうです。tg が 10〜12 t/s 帯で対話の体感もスムーズ、JCQ で見る限り BF16 比 0.6 ポイント以下の劣化に収まります。VRAM 消費も 17 GiB 弱なので、別プロセスのモデル併走もしやすいです。
- 速度より正答率を最優先にしたい場面では BF16 を選ぶ余地はあるんですが、Qwen 3.6-27B のように BF16 が必ず勝つわけでもないので、用途ごとに事前ベンチをおすすめします。
最高品質を狙う(まとまった分量を一括処理 / 記述系評価)
- Gemma 4-31B BF16 が JCQ 98.12% で実測トップでした。容量(57 GiB)と tg 速度(3.82 t/s)を許容できるなら有力候補です。
- BF16 まで使わないなら、Gemma 4-31B Q4_K_M(JCQ 97.77%、tg 10.65 t/s)が今回のセットでは「速度と品質のバランス」で最も実用的だったように思います。
画像理解(VLM 用途)
- Q4_K_M の中では Qwen 3.5-27B が今回最も安定しました。Caption レイテンシも最短で、PPE スキーマに沿った JSON も 1/3 出ていました。
- ただしサンプル 3 件と少ないため、実運用前に対象タスクの画像で再現性確認は必須です。Qwen 3.6 は PPE で形が崩れましたが、別タスクでは挙動が変わる可能性があります。
9. まとめ
| 観点 | 結果 |
|---|---|
| Dense Q4_K_M の実用性 | tg 10〜12 t/s、対話用途として実用域に到達 |
| Q4_K_M / BF16 の tg 比 | 2.6〜2.8 倍(Q4_K_M が圧勝) |
| JCQ Thinking OFF | Gemma 4-31B が 1 段抜け(BF16 98.12%, Q4 97.77%) |
| 量子化による品質劣化 | 0.2〜0.6 ポイント、誤差レンジに近い |
| ロング pp 劣化率 | Qwen 系 -3〜-6%、Gemma 4 -12〜-13% |
| VLM JSON 抽出(Dense Q4_K_M) | 3 モデルとも parse 100% |
| VLM PPE 検出(Dense Q4_K_M) | Qwen 3.5 / Gemma 4 = 1/3、Qwen 3.6 = 0/3 |
| MoE との速度差(過去記事比較) | tg で MoE が Dense Q4_K_M の 5〜6 倍速い |
| MoE との VLM 安定性(過去記事比較) | Dense Q4_K_M が JSON parse で優位(100% vs 40〜80%) |
過去記事で「Dense は帯域律速で実用に厳しい」としていた話は、Q4_K_M に量子化すれば解消されることが今回の実測で確認できました。MoE が DGX Spark 向けに最適という結論自体は変わりませんが、Dense Q4_K_M も「使える選択肢」として並べられるようになったのは大きな違いです。
DGX Spark で 27〜31B Dense を使ってみたい方の選択指針として、本記事の数字が役立てば幸いです。
参考リンク
- DGX Spark で Gemma 4 vs Qwen 3.5 MoEモデル対決ベンチマーク(過去記事 ①)
- DGX Spark で Qwen 3.6 vs 3.5 実測比較(過去記事 ②)
- DGX Spark で Qwen 3.6-27B 量子化別比較(前回記事)
- Qwen 3.5-27B(HuggingFace)
- Qwen 3.6-27B(HuggingFace)
- Gemma 4-31B(HuggingFace)
- unsloth Qwen3.5-27B-GGUF
- unsloth Qwen3.6-27B-GGUF
- ggml-org gemma-4-31B-it-GGUF
- JCommonsenseQA v1.1
- llama.cpp GitHub
- GitHub: gemma4-vs-qwen35-dgx-spark(過去記事のベンチスクリプト)
- llama-server CVE-2026-21869 修正(#22267)
- NVIDIA Developer Forum: Gemma 4 Day-1 Benchmarks
※ 数値はすべて 2026-04-25 時点の実測値で、llama.cpp のビルドや量子化のバリアントが変われば再現値も動く可能性がある点に留意してください。