Gemma 4 vs Qwen 3.5 — DGX Spark × llama.cpp でMoEモデル対決ベンチマーク
はじめに
Google から Gemma 4 がリリースされました。Apache 2.0 ライセンスで、MoE(Mixture-of-Experts)を含む 4 つのモデルが公開されています。
クラスメソッド森茂さんの「Gemma 4 を DGX Spark で動かして日本語とマルチモーダルをベンチマークしてみた」では、Ollama を使った Gemma 4 全モデルの包括的なベンチマークが紹介されています。非常に参考になる記事で、DGX Spark 上での各モデルの特性が丁寧にまとめられています。
この記事ではその追試として、llama.cpp を使い、Qwen 3.5-35B-A3B との直接比較を行いました。同じ DGX Spark 上で、同じ llama.cpp ランタイムを使い、日本語テキスト(JCommonsenseQA)とマルチモーダル(画像理解)の 2 軸でベンチマークしています。
なぜ Qwen 3.5 との比較なのか
元記事の比較対象は Nemotron シリーズでしたが、普段 DGX Spark で Qwen 3.5-35B-A3B を常用しているのでそちらと比較することにしました。どちらも MoE アーキテクチャで Active パラメータが 3-4B という設計思想が共通しており、DGX Spark のような帯域律速環境で「軽量・高速に動く大規模モデル」という同じポジションを狙っています。日常的に使い比べられるモデル同士の比較は、実用面で価値があると考えました。
| Gemma 4 26B-A4B | Qwen 3.5-35B-A3B | |
|---|---|---|
| 総パラメータ | 26B | 35B |
| Active パラメータ | 3.8B | 3B |
| アーキテクチャ | MoE | MoE |
| ライセンス | Apache 2.0 | Apache 2.0 |
| マルチモーダル | 画像対応 | VLM 対応 |
| Thinking | <|think|> |
enable_thinking |
| LMArena ELO | 1441 | — |
なぜ 31B ではなく 26B-A4B で比較するのか
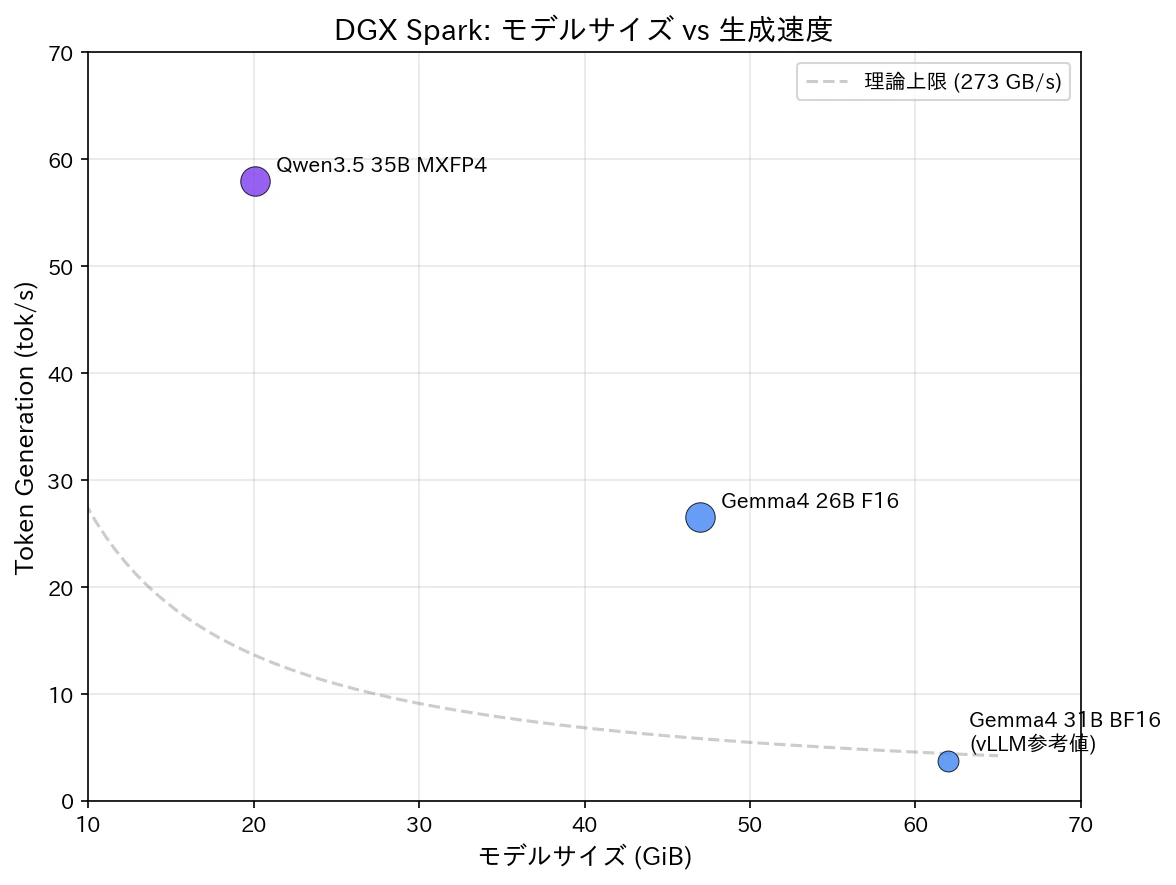
Gemma 4 には 31B Dense モデルもありますが、今回は 26B-A4B MoE を比較対象にしました。理由は DGX Spark の物理的な制約にあります。
DGX Spark のメモリ帯域は約 273 GB/s です。Token Generation では、トークンごとに Active パラメータ分のウェイトをメモリから読む必要があり、推論速度はこの帯域に律速されます。
| モデル | アーキテクチャ | Active パラメータ | 毎トークン読み出し | 理論 tok/s |
|---|---|---|---|---|
| Qwen 3.5-35B-A3B MXFP4 | MoE | 3B | ~3 GB | ~91 |
| Gemma 4 26B-A4B F16 | MoE | 3.8B | ~8 GB | ~34 |
| Gemma 4 31B BF16 | Dense | 30.7B | ~62 GB | ~4.4 |
31B Dense は全 30.7B パラメータをトークンごとに読む必要があり、理論値で 4.4 tok/s、実測でも 3.7 tok/s(NVIDIA フォーラム計測値)しか出ないとされ、Q4_K_M に量子化しても 10 tok/s 前後で、Qwen 3.5 の 58 tok/s とは 6 倍の差があることが懸念されます。これはモデルの良し悪しではなく、Dense vs MoE の構造的な宿命です。DGX Spark の帯域律速環境では MoE 同士の比較こそが意味があるんじゃないと思いました。なお、品質面では 31B Dense(LMArena ELO 1452)と 26B-A4B MoE(ELO 1441)の差はわずか 11 ポイントで、MoE でも十分に高い品質が得らると思います。
なぜ Ollama ではなく llama.cpp なのか
元記事では Ollama が使われていますが、本記事では llama.cpp を直接ビルドして使用しました。理由はいくつかあります。
ランタイム差異の排除: Ollama は内部的に llama.cpp を使用していますが、独自のテンプレート処理やメモリ管理が加わるため、ランタイム起因の差異が混入します。llama.cpp を直接使うことで、モデル間の比較がよりフェアになります。
ビルドオプションの制御: DGX Spark の GB10(compute capability 12.1)向けに -DCMAKE_CUDA_ARCHITECTURES=121 や -DGGML_CUDA_F16=ON などの最適化フラグを指定してビルドできます。Ollama のプリビルドバイナリではこの制御ができません。
量子化フォーマットの自由度: Ollama のレジストリでは Gemma 4 26B-A4B の BF16 タグが提供されていませんでした(Q4_K_M のみ)。llama.cpp なら HuggingFace 上の ggml-org の F16 GGUF を直接使えるため、フル精度での品質評価が可能です。
llama-bench の利用: llama.cpp に付属する llama-bench で prompt processing / token generation の純粋な速度を計測できます。これは推論エンジンのオーバーヘッドを含まない、より正確な性能指標になります。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark |
| GPU | NVIDIA GB10(128 GB 統合メモリ) |
| OS | Ubuntu 22.04(ARM64/SBSA) |
| CUDA | 13.0(Driver 580.126.09) |
| llama.cpp | b8665(ソースビルド、CUDA sm_121) |
ビルド
以下のコマンドで llama.cpp をビルドしました。
# CMake 構成
cmake -B build \
-DGGML_CUDA=ON \ # CUDA バックエンド有効化
-DCMAKE_CUDA_ARCHITECTURES=121 \ # GB10 (Blackwell) 向け
-DGGML_CUDA_F16=ON \ # FP16 CUDA カーネル有効化
-DGGML_NATIVE=ON \ # ホスト CPU 向け最適化
-DCMAKE_BUILD_TYPE=Release
# ビルド(必要なターゲットのみ)
cmake --build build --config Release -j$(nproc) \
--target llama-server llama-cli llama-bench llama-mtmd-cli
テストモデル
| モデル | 量子化 | GGUF サイズ | VRAM 使用量 | ソース |
|---|---|---|---|---|
| Gemma 4 26B-A4B | F16 | 47.0 GiB | 56,464 MiB | ggml-org |
| Qwen 3.5-35B-A3B | MXFP4 | 20.1 GiB | 26,432 MiB | ggml-org |
Gemma 4 はフル精度(F16)、Qwen 3.5 は MXFP4 量子化です。元記事の Gemma 4 は Ollama で Q4_K_M(16.8 GB)でしたが、DGX Spark の 128 GB 統合メモリを活かしてフル精度での品質評価を試みました。
モデルのダウンロードは hf コマンド(huggingface_hub CLI)で行いました。
# 仮想環境内で huggingface_hub をインストール
python3 -m venv ~/venv-hf-dl
source ~/venv-hf-dl/bin/activate
pip install huggingface_hub hf_transfer
# 高速転送有効化 & ダウンロード
export HF_HUB_ENABLE_HF_TRANSFER=1
hf download ggml-org/gemma-4-26B-A4B-it-GGUF \
--include "gemma-4-26B-A4B-it-f16.gguf" \
--local-dir ~/models/gemma4-26b-a4b
llama-bench 速度ベンチマーク
まず純粋な推論速度を llama-bench で計測しました。llama-bench は llama.cpp に付属するベンチマークツールで、推論エンジンの API オーバーヘッドを含まない素の処理速度を測定できます。
# -ngl 999: 全レイヤを GPU にオフロード
# -fa 1: Flash Attention 有効
# -p 2048: プロンプト長 2048 トークン
# -n 32: 生成トークン数 32
# -ub 2048: マイクロバッチサイズ
llama-bench -m <model.gguf> -ngl 999 -fa 1 -p 2048 -n 32 -ub 2048
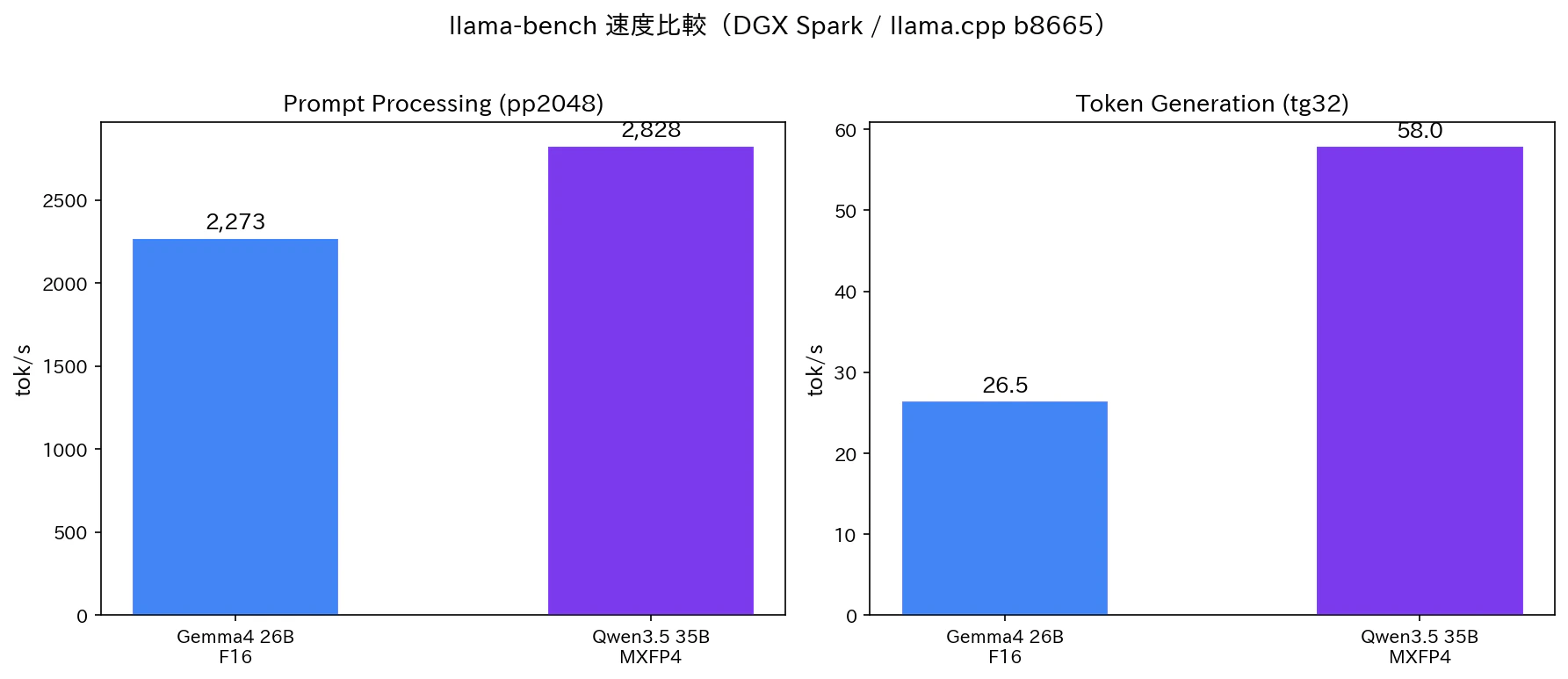
| モデル | サイズ | pp2048 (tok/s) | tg32 (tok/s) |
|---|---|---|---|
| Qwen 3.5-35B-A3B MXFP4 | 20.1 GiB | 2,828 | 58.0 |
| Gemma 4 26B-A4B F16 | 47.0 GiB | 2,273 | 26.5 |
Qwen 3.5 が Prompt Processing で 1.24 倍、Token Generation で 2.19 倍高速です。
帯域律速の物理
理論値 = メモリ帯域 ÷ Active パラメータのメモリサイズ
Qwen 3.5: 273 GB/s ÷ ~3 GB (Active 3B, MXFP4) ≈ 91 t/s → 実測 58 t/s(64%効率)
Gemma 4: 273 GB/s ÷ ~8 GB (Active 3.8B, F16) ≈ 34 t/s → 実測 26.5 t/s(78%効率)
Gemma 4 の方が帯域効率は高い(78% vs 64%)のですが、F16(1パラメータ 2 バイト)と MXFP4(1パラメータ 0.5 バイト)の差が大きく、Active パラメータの実効サイズで 2 倍以上の差がついています。Gemma 4 を Q4_K_M に量子化すれば速度差は縮まりますが、今回はフル精度での品質を優先しました。
テキストベンチマーク: JCommonsenseQA
ベンチマーク方法
元記事と同じ JCommonsenseQA v1.1 を使用しました。日本語の常識推論能力を測るデータセットで、1,119 問の 5 択問題を 3-shot プロンプトで評価しています。元記事の著者がベンチマークに使用したスクリプトは himorishige/dgx-spark-blog で公開されていますが、Ollama API 向けのため、今回は元記事のスクリプトをベースに llama-server の OpenAI 互換 API 向けに修正して使用しました(検証スクリプト参照)。
以下のコマンドで llama-server を起動し、OpenAI 互換の /v1/chat/completions エンドポイント経由で全問を自動評価しました。
# -m: モデルファイルパス
# --mmproj: マルチモーダル用プロジェクタ(テキストのみの場合も指定可)
# -ngl 999: 全レイヤを GPU にオフロード
# --jinja: Jinja テンプレートエンジン有効(モデル内蔵テンプレートを使用)
# --chat-template-kwargs: テンプレートに渡すパラメータ(Thinking の ON/OFF 制御)
# --port 8080: API サーバーのリッスンポート
# --temp / --top-p / --top-k: サンプリングパラメータ(Gemma 4 推奨値)
llama-server \
-m ~/models/gemma4-26b-a4b/gemma-4-26B-A4B-it-f16.gguf \
--mmproj ~/models/gemma4-26b-a4b/mmproj-gemma-4-26B-A4B-it-f16.gguf \
-ngl 999 --jinja \
--chat-template-kwargs '{"enable_thinking":false}' \
--port 8080 --temp 1.0 --top-p 0.95 --top-k 64
Thinking OFF 結果
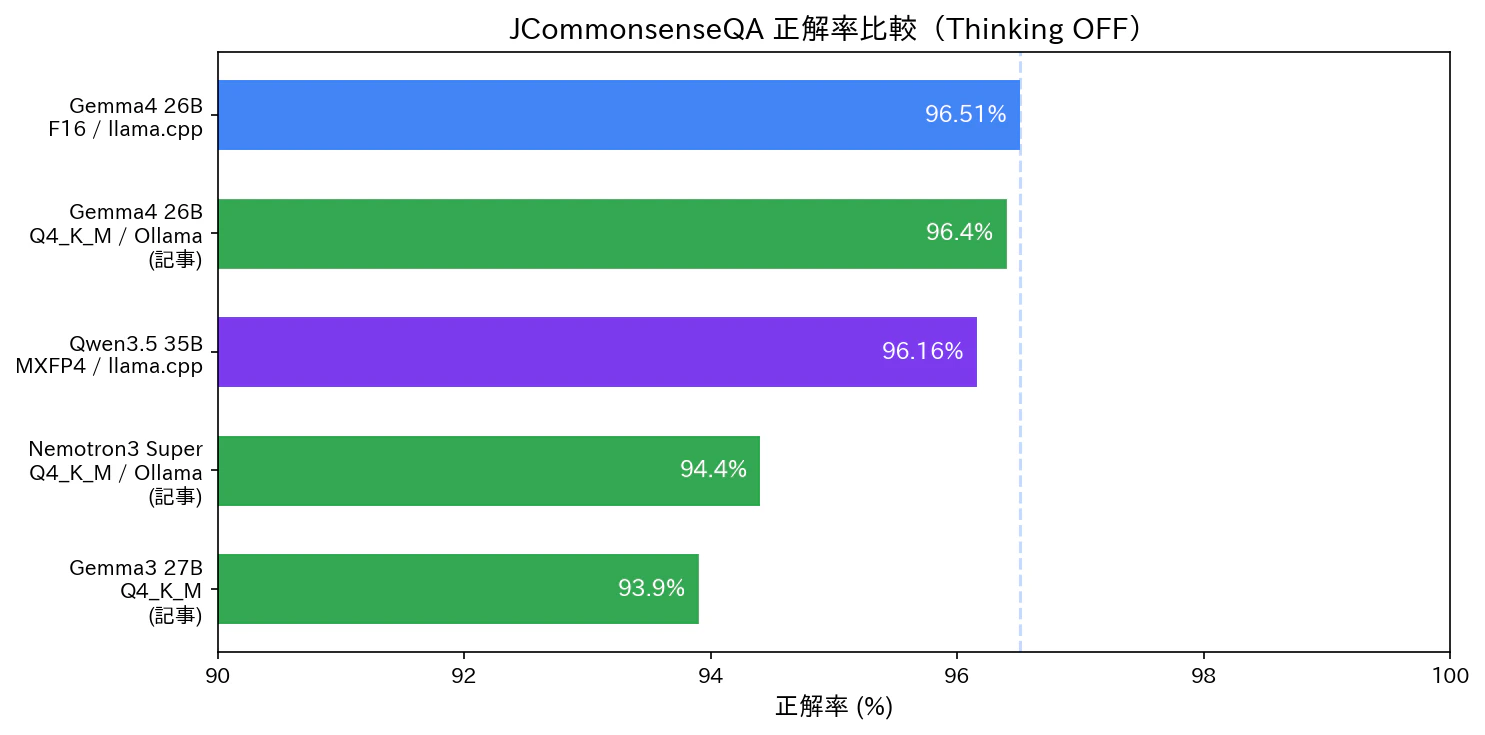
| モデル | 量子化 | ランタイム | 正解率 | レイテンシ | tok/s |
|---|---|---|---|---|---|
| Gemma 4 26B-A4B | F16 | llama.cpp | 96.51% | 0.376s | 26.7 |
| Gemma 4 26B-A4B | Q4_K_M | Ollama(元記事) | 96.4% | 0.33s | 69.5 |
| Qwen 3.5-35B-A3B | MXFP4 | llama.cpp | 96.16% | 0.236s | ~60 |
| Nemotron 3 Super | Q4_K_M | Ollama(元記事) | 94.4% | 0.92s | 35.6 |
| Gemma 3 27B | Q4_K_M | 元記事 | 93.9% | — | — |
Gemma 4 F16(96.51%)と Qwen 3.5 MXFP4(96.16%)の差はわずか 0.35 ポイント(4 問差)。ほぼ互角です。
注目すべきは Gemma 4 の F16 と Q4_K_M(元記事)の差が 0.11 ポイントしかない点です。DGX Spark の 128 GB メモリを使ってフル精度で走らせても、JCQ のような知識系 5 択問題では量子化の影響はほとんど出ないことがわかります。
なお、tok/s は元記事の Ollama Q4_K_M(69.5 tok/s)と今回の llama.cpp F16(26.7 tok/s)で大きく異なりますが、これは品質差ではなくモデルサイズの差によるものです。F16(47 GiB)は Q4_K_M(16.8 GiB)の約 2.8 倍のサイズがあり、トークンごとにメモリから読み出すデータ量が増えるため、帯域律速の DGX Spark では速度に直結します。前述の llama-bench 結果(26.5 tok/s)とも整合しており、F16 フル精度の代償として妥当な範囲です。
Thinking モードの効果
Gemma 4 と Qwen 3.5 はいずれも「Thinking(推論)モード」を搭載しています。これは最終回答の前にモデルが内部的にステップバイステップで思考を行う機能で、数学やコーディングのような段階的推論が必要なタスクで精度向上が期待できます。元記事では Gemma 4 全モデルで Thinking ON/OFF の比較が行われていたので、今回は Qwen 3.5 でも同条件で検証しました。

| モデル | nothink | think | 差分 | レイテンシ増 |
|---|---|---|---|---|
| Gemma 4 26B(元記事/Ollama) | 96.4% | 87.2% | -9.2pt | ×15 倍 |
| Gemma 4 26B(今回/llama.cpp) | 96.51% | ❌ バグ(後述) | — | — |
| Qwen 3.5 35B(今回/llama.cpp) | 96.16% | 89.28% | -6.9pt | ×58 倍 |
Qwen 3.5 でも Thinking ON で JCQ は劣化しました。元記事の Gemma 4 と同じ傾向で、知識系 5 択では Thinking が「考えすぎて迷う」現象が確認できました。
Qwen 3.5 は劣化幅が小さい(-6.9pt vs -9.2pt)ですが、レイテンシ増は大きい(×58 倍)。tok/s 自体は 60.2 で Thinking OFF と変わらないため、思考トークンの生成量が多いことが原因です。1 問あたり平均 13.7 秒かかるため、全 1,119 問の実行に約 4.3 時間を要しました。
元記事の結論と同じく、Thinking モードは数学やコーディングのような段階的推論が必要なタスク向けで、常識推論では無効にした方がよいと言えます。
Gemma 4 の Thinking バグについて
llama.cpp b8665 において、Gemma 4 の Thinking モードには深刻なバグがありました。Thinking ON で起動すると、<unused49> という未定義トークンが延々と出力され、推論内容も最終回答も一切生成されません。
# 実際の出力例(max_tokens=2048 でも回答に到達しない)
content: "<unused49><unused49><unused49><unused49>...(2048トークン全て<unused49>)"
reasoning_content: ""
finish_reason: "length"
以下の設定を試しましたが、いずれも Gemma 4 では Thinking を無効化できませんでした。
-
--chat-template-kwargs '{"enable_thinking":false}'→ サーバーログはthinking = 1のまま変わらず -
--reasoning-budget 0→ 効果なし(thinking = 1のまま) -
--reasoning-format none→ 効果なし -
--chat-template gemma(Jinja を使わない)→thinking = 0になるが、マルチモーダル API のトークナイズに失敗する
この問題は GitHub Discussion #21338 で報告されています。元記事の Ollama では Thinking モードが正常に動作しているため、llama.cpp 固有の問題です。
なお、テキスト専用で Thinking OFF(--chat-template-kwargs '{"enable_thinking":false}')の場合は、サーバーログ上は thinking = 1 と表示されるものの、実際の出力には思考トークンが含まれず正常に動作しました。JCQ ベンチの Thinking OFF 結果(96.51%)はこの設定で取得しています。VLM(マルチモーダル)テストも、この設定であれば正常に動作することを確認しました。
つまり現状の llama.cpp b8665 では、Gemma 4 は「Thinking が OFF にならないが、テキスト出力には影響しない」という不安定な状態にあります。明示的に Thinking ON にすると <unused49> で壊れるため、Thinking ON のベンチは取得できませんでした。
Qwen 3.5 では llama.cpp の Thinking 制御は安定しており、ON/OFF の切り替えが問題なく機能しています。
マルチモーダルベンチマーク
テスト概要
展示会写真 5 枚と作業現場写真 3 枚を使い、3 つのタスクを実施しました。展示会写真は自分が CEATEC 2025 等の展示会で撮影したもの、作業現場写真は PPE 検出用にフリー素材を使用しています。
- 日本語キャプション生成 — 画像のシーン説明(展示会写真 5 枚)
- JSON 構造化タグ抽出 — location, subjects, technologies 等の構造化データ(展示会写真 5 枚)
- PPE(保護具)検出 — 安全保護具の着用状況を JSON で判定(作業現場写真 3 枚)
マルチモーダル推論には --mmproj(マルチモーダルプロジェクタ)を指定して起動します。画像は OpenAI 互換 API の image_url フィールドに base64 エンコードで渡しました。
# --mmproj: マルチモーダルプロジェクタ(画像エンコーダの重み)を指定
# これを指定しないと画像入力を処理できない
llama-server \
-m ~/models/gemma4-26b-a4b/gemma-4-26B-A4B-it-f16.gguf \
--mmproj ~/models/gemma4-26b-a4b/mmproj-gemma-4-26B-A4B-it-f16.gguf \
-ngl 999 --jinja \
--chat-template-kwargs '{"enable_thinking":false}' \
--port 8080 --temp 1.0 --top-p 0.95 --top-k 64
結果
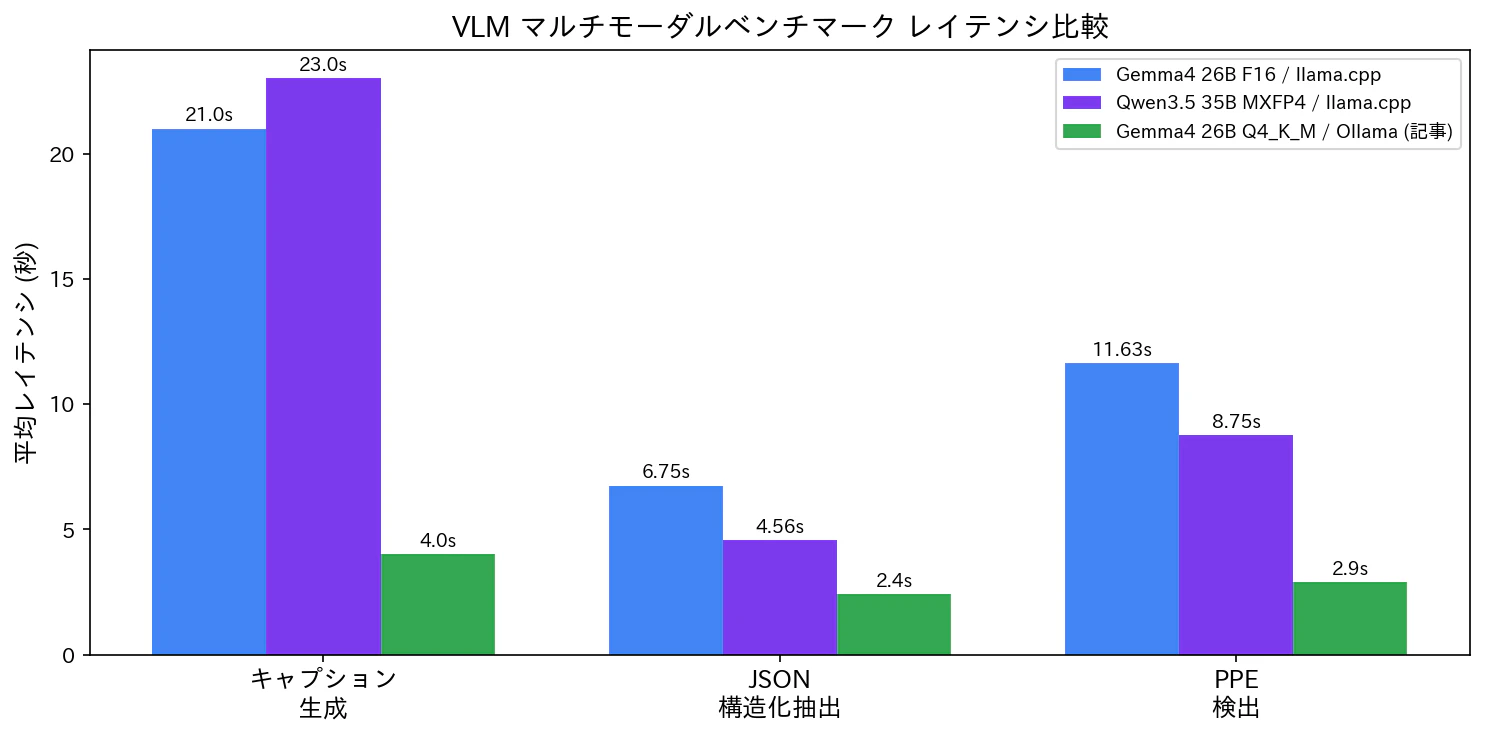
| テスト | Gemma 4 F16 | Qwen 3.5 MXFP4 | 元記事(Gemma 4 Q4_K_M / Ollama) |
|---|---|---|---|
| キャプション平均 | 21.0s | 23.0s | 4.0s |
| JSON 抽出平均 | 6.75s | 4.56s | 2.4s |
| JSON parse 率 | 100% | 100% | 100% |
| PPE 検出平均 | 11.63s | 8.75s | 2.9s |
| PPE parse 率 | 100% | 100% | 100% |
| VLM tok/s | 26.0 | 44.2 | — |
両モデルとも JSON parse 率 100% を達成。構造化データ抽出の信頼性は高いです。
キャプション生成では Gemma 4 がわずかに速い(21.0s vs 23.0s)ですが、JSON 抽出と PPE 検出では Qwen 3.5 が速い結果になりました。
llama.cpp での F16 / MXFP4 は元記事の Ollama Q4_K_M と比べてレイテンシが長くなっています。これはモデルサイズの差(47 GiB / 20 GiB vs 16.8 GiB)と、画像の prefill 処理におけるオーバーヘッドが主因と考えられます。
PPE 検出出力例(Gemma 4)
{
"workers_count": 1,
"ppe_items": [
{
"worker_id": 1,
"hard_hat": false,
"safety_vest": true,
"safety_glasses": false,
"gloves": false,
"safety_shoes": false,
"other": ["ヘルメットを手に持っている(着用していない)"]
}
],
"compliance_score": "低",
"observations": "作業員は安全ベストを着用していますが、ヘルメットを着用しておらず手に持っています。
また、保護メガネ、手袋、安全靴の着用も確認できません。建設現場の安全基準を満たしていません。"
}
「ヘルメットを手に持っている(着用していない)」という詳細な観察まで返してくれるのは、ゼロショットとしては非常に高い品質です。
VRAM 使用量
nvidia-smi で llama-server 起動時のメモリ使用量を計測しました。
| モデル | 量子化 | VRAM(llama-server 起動時) |
|---|---|---|
| Gemma 4 26B-A4B | F16 | 56,464 MiB |
| Qwen 3.5-35B-A3B | MXFP4 | 26,432 MiB |
Qwen 3.5 は MXFP4 量子化により、Gemma 4 F16 の 半分以下のメモリで動作します。DGX Spark の 128 GB 統合メモリであればどちらも余裕で載りますが、他のサービス(ComfyUI、別の LLM など)との同居を考えると、Qwen 3.5 のコンパクトさは実運用で大きなメリットになります。
全体まとめ
| 指標 | Gemma 4 26B-A4B F16 | Qwen 3.5-35B-A3B MXFP4 |
|---|---|---|
| JCQ 正解率(nothink) | 96.51% | 96.16% |
| JCQ 正解率(think) | ❌ バグ | 89.28% |
| llama-bench pp2048 | 2,273 t/s | 2,828 t/s |
| llama-bench tg32 | 26.5 t/s | 58.0 t/s |
| VLM キャプション | 21.0s | 23.0s |
| VLM JSON parse | 100% | 100% |
| VLM PPE 検出 | 11.63s | 8.75s |
| VRAM | 56,464 MiB | 26,432 MiB |
| ライセンス | Apache 2.0 | Apache 2.0 |
結論
日本語テキストの品質は両モデルでほぼ互角でした。JCQ は 0.35 ポイント差、VLM の JSON parse 率も互いに 100% で、実用上の品質差はほとんど感じられません。
速度とメモリ効率では Qwen 3.5 に軍配が上がります。Token Generation で 2 倍以上、VRAM は半分以下。MXFP4 量子化と Active 3B の組み合わせが、DGX Spark の帯域律速環境で効いています。
ライセンスは両モデルとも Apache 2.0 で、商用展開やシステムへの組み込みでもライセンス起因の制約はかかりません。選定の判断材料は、速度・品質・VRAM 効率・実装エコシステム (vLLM 等の対応状況) といった技術面に絞られると思います。
日常運用は速度・効率の Qwen 3.5、品質要件が高い場面では Gemma 4 — DGX Spark で MoE モデルを選ぶ際の、今のところの実感です。
Thinking モードは JCQ のような知識系タスクでは両モデルとも逆効果でした。Gemma 4 は llama.cpp でバグがあり Thinking ON でのベンチが取れなかったため、修正後に改めて検証したいと思います。
参考リンク
- Gemma 4 を DGX Spark で動かして日本語とマルチモーダルをベンチマークしてみた(DevelopersIO)
- Google Blog: Gemma 4
- HuggingFace: Gemma 4 コレクション
- HuggingFace: Gemma 4 26B-A4B GGUF(ggml-org)
- NVIDIA DGX Spark llama.cpp Playbook
- NVIDIA Developer Forum: Gemma 4 Day-1 Benchmarks
- JCommonsenseQA v1.1
- llama.cpp GitHub
- Gemma 4 Thinking Bug: Discussion #21338
検証スクリプト
- 本記事のベンチマークスクリプト(JCQ / VLM)は GitHub で公開しています
- 元記事の検証スクリプトは himorishige/dgx-spark-blog で公開されています