はじめに
2026/4/22 に Qwen 3.6-27B が公開されました。Qwen 3.6 シリーズとしては 4 月上旬の 35B-A3B(MoE)に続くリリースで、今回は 27B の Dense モデルです。公開翌日の時点では、英語圏の記事は「flagship-level」「beats 397B」といった強い表現が多く、実際の数字が欲しいと思ったので、手元の DGX Spark で llama.cpp を使って測ってみました。
本記事は「速度と JCommonsenseQA の結果を淡々と並べる」ものです。公式ブログで強調されているコーディング能力(SWE-Bench Verified 77.2 など)や、Thinking Preservation、マルチモーダルについては今回は触れていません。手元の環境で再現できた範囲の情報として、参考にしていただければと思います。
なお、過去記事(Qwen 3.6-35B-A3B MoE の検証)と同じ環境・同じベンチスクリプトで測っており、前世代 MoE との直接比較もできる形にしました。
この記事の結論(TL;DR)
- llama.cpp の
llama-benchで Qwen 3.6-27B の 4 量子化を測りました。pp512 は BF16(50 GiB)が最速で 887.71 t/s、tg128 は Q4_K_M(15.7 GiB)が最速で 11.75 t/s でした。 - JCommonsenseQA(Thinking OFF、1,119 問)では UD-Q4_K_XL が 97.05% で一番高く、BF16 は 96.69% でした。差は 4 問(0.36 pt)なので誤差の範囲と見ておくのが無難ですが、「4bit だから大きく劣化する」という事象は今回の 4 モデル比較では観測されませんでした。
- 同じ DGX Spark 環境で測った前世代 Qwen 3.6-35B-A3B MoE(MXFP4)と比べると、27B Dense は pp/tg ともに大幅に遅く、JCQ 正解率では約 1pt 高いという結果でした。速度で MoE、品質で Dense という構図が出ているように見えます。
- Thinking ON、ロングコンテキスト、VLM については今回測っていません。追って別記事で補足予定です。
1. Qwen 3.6-27B について
公式情報(HF model card および 公式ブログ)から、本記事に関係しそうな点を抜粋します。
- Dense 27B(総パラメータ・活性パラメータとも 27B)
- 262K native / 約 1M 拡張コンテキスト(35B-A3B と同じ)
- SWE-Bench Verified 77.2(前世代フラッグシップ 397B-A17B の 76.2 を上回るとの主張)
- Thinking Preservation:会話履歴に推論コンテキストを保持し、多ターンエージェントでの KV キャッシュ効率を高める仕組み
- VLM 対応(vision encoder 統合、mmproj を別途ロード)
- Apache 2.0 ライセンス
「Dense 27B が MoE 397B のコーディングベンチを上回る」という主張は目を引きますが、これは公式が示したコーディング系ベンチでの話です。日本語常識推論や一般対話の品質がどうかは別途確認する必要があるので、本記事では JCommonsenseQA で測ることにしました。
2. llama.cpp の最近の動き(b8672 → b8892)
本検証では llama.cpp を前回記事時点の b8672 から b8892 に更新しました。2 週間強のあいだに 220 タグが切られており、目についた範囲での主なトピックを簡単に整理します(詳細は各 PR を参照ください)。
- Generic NVFP4 MMQ CUDA kernel が追加(b88xx 台)— Blackwell 向けの NVFP4 量子化を MMQ パスで扱うための基盤整備。DGX Spark(GB10)で将来的に効いてきそうな変更と思われます
- WebGPU バックエンドの継続強化 — vectorized FlashAttention、async scheduling 改善。手元では直接関係しませんが、Mac/ブラウザ実行の足回りが整ってきている印象
- Hadamard 変換ベースの量子化品質改善 — attention activations の outlier 抑制。量子化まわりの地道な精度改善が続いています
- llama-server に JSONL HTTP tracing — リクエスト/レスポンスの観測性が上がり、長時間のベンチ運用で嬉しい変更
- speculative-simple の checkpoint 対応 — 投機的デコードの中断・再開がしやすくなった
2 週間でこれだけ動くので、ベンチ時は自分がどのビルドで測ったかを必ず記録しておかないと、後で比較できなくなります。本記事では全測定を b8892(commit 0d0764dfd、CUDA ビルド、SM121a) で統一しました。
3. 検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark(GB10、Grace + Blackwell、統合メモリ 128 GB) |
| OS | Ubuntu 24.04 |
| CUDA | 13.0.88 |
| llama.cpp | b8892(commit 0d0764dfd) |
| ビルド | CUDA、SM121a、Flash Attention 全量子化、F16 有効 |
ビルドコマンド:
cmake -B build \
-DGGML_CUDA=ON \
-DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=121 \
-DGGML_CUDA_F16=ON \
-DGGML_NATIVE=ON \
-DCMAKE_BUILD_TYPE=Release
cmake --build build -j $(nproc) \
--target llama-server llama-bench llama-cli llama-mtmd-cli
補足:
CMAKE_CUDA_ARCHITECTURES=121は cmake 側で自動的に121a(GB10 の native アーキ)に置換されます。
既存ビルド(b8672)は git worktree で別ディレクトリに分離して残しています。FFT 用のローカルパッチを保持するためと、既存の常駐 llama-server(Qwen 3.5)に影響を出さないためです。
4. テストした量子化モデル(4 つ)
すべて unsloth/Qwen3.6-27B-GGUF から取得しました。
| 量子化 | 実サイズ | 位置づけ |
|---|---|---|
| BF16 | 50.10 GiB(2 シャード) | ネイティブ精度の基準線 |
| UD-Q8_K_XL | 32.89 GiB | Unsloth Dynamic 2.0 の 8bit |
| UD-Q4_K_XL | 16.39 GiB | Unsloth Dynamic 2.0 の 4bit(daily 推奨) |
| Q4_K_M(素) | 15.65 GiB | imatrix ベースの標準的な 4bit |
執筆時点では bartowski 版 Qwen3.6-27B GGUF はまだ公開されていなかったため、今回は Unsloth 一択で揃えています。
5. 速度: llama-bench
計測コマンド:
llama-bench -p 512 -n 128 -ngl 99 -fa 1 -mmp 0 -r 3 -m <model.gguf>
5-1. 量子化別の速度
| Model | Size | pp512 (t/s) | tg128 (t/s) |
|---|---|---|---|
| Qwen3.6-27B Q4_K_M | 15.65 GiB | 811.09 ± 12.56 | 11.75 ± 0.01 |
| Qwen3.6-27B UD-Q4_K_XL | 16.39 GiB | 789.46 ± 6.12 | 11.36 ± 0.00 |
| Qwen3.6-27B UD-Q8_K_XL | 32.89 GiB | 603.79 ± 3.45 | 6.62 ± 0.01 |
| Qwen3.6-27B BF16 | 50.10 GiB | 887.71 ± 8.94 | 4.55 ± 0.01 |

図1: Qwen 3.6-27B の 4 量子化での pp512 / tg128 比較
いくつか気になった点:
-
pp では BF16 が 4 モデルの中で一番高い値(887.71 t/s)でした。Blackwell は BF16 テンソルコアを native 対応しており、
-DGGML_CUDA_F16=ONのビルドでは pp 側の処理がそのまま BF16 のまま流れるため、量子化のデクォンタイズオーバーヘッドが乗らない分有利になっているのかもしれません。ただし断定できるほど詳細に追えてはいないので、ひとまず「DGX Spark では BF16 の pp が健闘する」くらいに受け止めています。 - UD-Q8_K_XL(603.79 t/s)は pp で一番遅く、Dynamic 2.0 の mixed-precision upcast が CUDA の高速パスに乗り切らない可能性がありそうに見えます。別途調べてみるつもりです。
- tg は重みサイズにほぼ反比例し、27B Dense の場合は GB10 の統合メモリ帯域(約 273 GB/s)がボトルネックになっているようです。これは典型的なパターンですね。
5-2. 前世代 MoE との比較
同じ DGX Spark 環境で過去に測定した Qwen 3.5 / 3.6 の 35B-A3B MoE(MXFP4、b8672)と今回の 27B Dense を並べたのが次の図です。
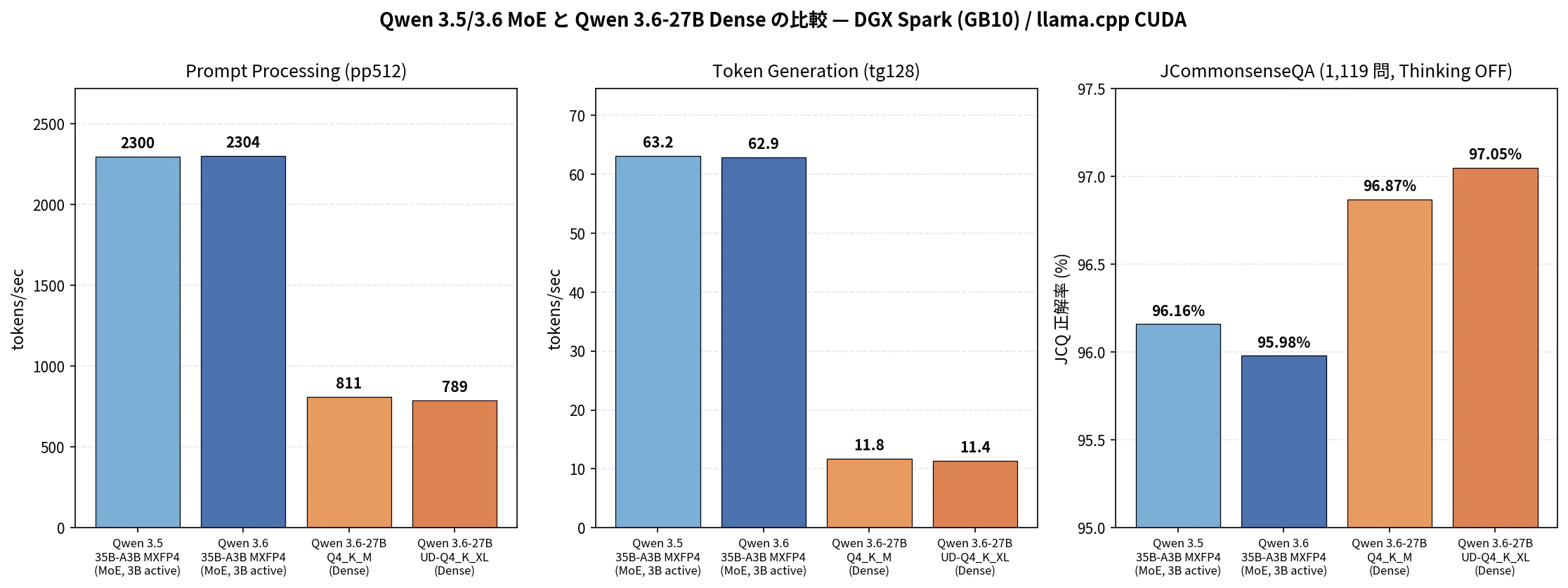
図2: 同一環境での 3 世代比較(DGX Spark / llama.cpp CUDA)
速度スケールが桁違いに見えますが、これは MoE の活性パラメータが 3B / Dense が 27B という構造的な差によるものです。
| 指標 | Qwen 3.6-35B-A3B MXFP4 | Qwen 3.6-27B Q4_K_M | 比率 |
|---|---|---|---|
| pp512 (t/s) | 2,304.22 | 811.09 | 0.35× |
| tg128 (t/s) | 62.91 | 11.75 | 0.19× |
| JCQ OFF | 95.98% | 96.87% | +0.89pt |
JCQ では 27B Dense が約 1pt 高い一方、tg 速度では約 1/5.4 になっており、「速度の MoE、品質の Dense」という構図が見えてきたように思います。用途に応じて選ぶことになりそうです。
6. 品質: JCommonsenseQA(Thinking OFF)
JCommonsenseQA v1.1(1,119 問、5 択)を 3-shot で解かせました。前回記事と完全に同じ jcq_bench.py を使っています。
6-1. 今回の 4 モデル
| Model | 正解率 | 正解数 | Avg latency | tok/s |
|---|---|---|---|---|
| UD-Q4_K_XL | 97.05% | 1086/1119 | 0.630s | 21.1 |
| Q4_K_M | 96.87% | 1084/1119 | 0.609s | 21.9 |
| BF16 | 96.69% | 1082/1119 | 0.961s | 8.8 |
| UD-Q8_K_XL | 96.60% | 1081/1119 | 0.911s | 12.6 |
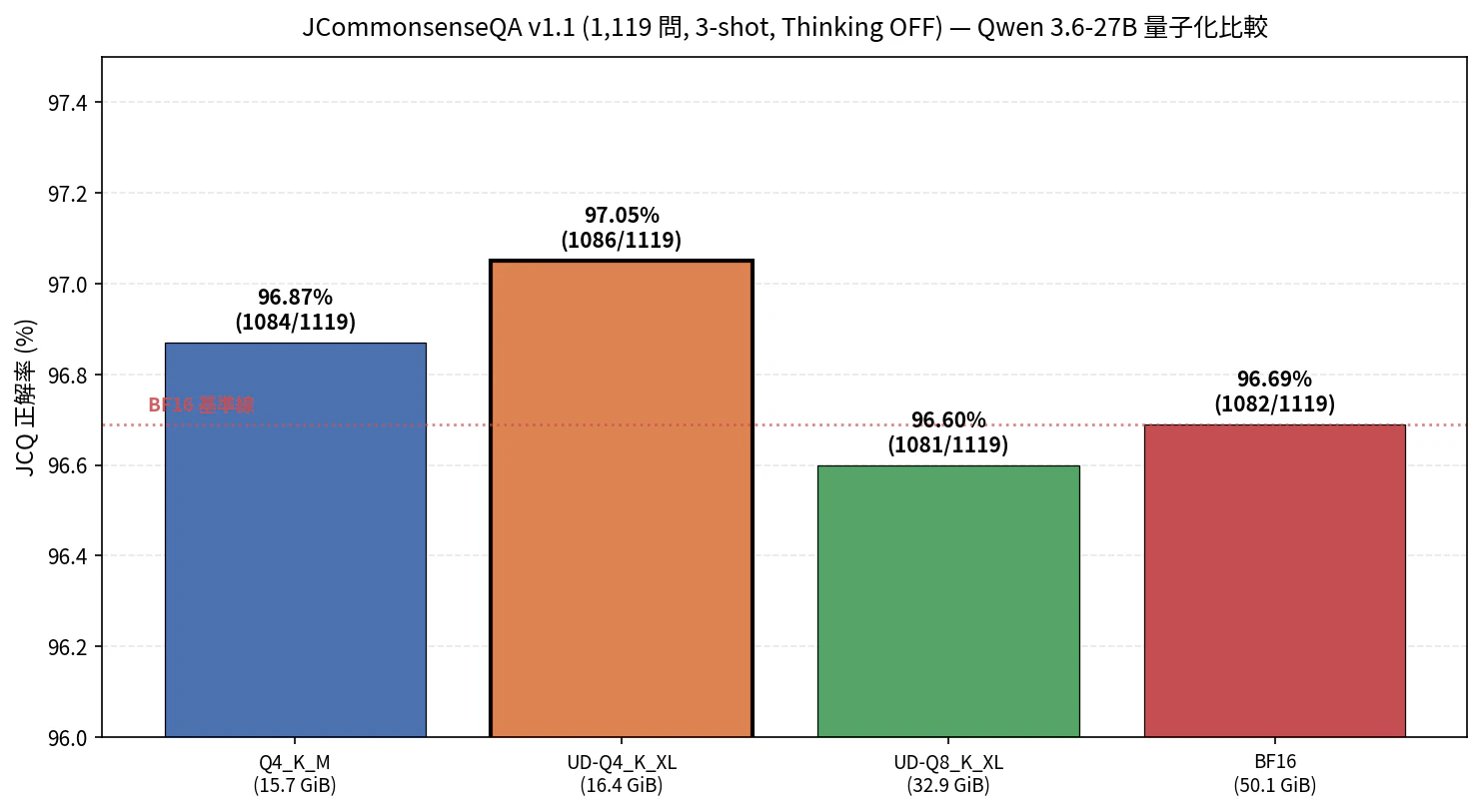
図3: Qwen 3.6-27B の 4 量子化での JCQ 正解率(Y 軸 96.0〜97.5% にズーム)
順位としては UD-Q4_K_XL > Q4_K_M > BF16 > UD-Q8_K_XL となりましたが、最大差は 5 問(UD-Q4_K_XL と UD-Q8_K_XL の差)なので、統計的には誤差の範囲と見るべきだと思います。誤答の重なりを調べると、4 モデル共通の誤答が 31 問あり、各モデルの独自誤答はほぼゼロ(Q4_K_M の 1 問のみ)でした。つまり「量子化が変わると別の問題が解ける/解けなくなる」という現象は観測されず、どの量子化も似たような問題で引っかかっているようです。
この結果から個人的に思うのは以下のような点です。
- 4bit 量子化が壊滅的に劣化するという事象は、少なくとも JCommonsenseQA の範囲では起きていないように見えます。容量が 1/3 になって正解率は 0.2pt 下がるかどうか、という程度。
- UD-Q8_K_XL が最下位になっているのはやや意外でした。Unsloth Dynamic 2.0 は 4bit 向けにチューニングされている可能性があり、8bit では旨味が出にくいのかもしれませんが、ここは推測の域を出ません。
- BF16 が中位なのも、1,119 問というサンプル数では量子化の差を有意に検出できるほどの分解能はない、という当たり前の話かもしれません。
6-2. 前世代 MoE、他モデルとの比較
参考値として、同じ環境で測った他モデルを並べておきます(すべて DGX Spark、Thinking OFF)。
| モデル | 量子化 | JCQ OFF |
|---|---|---|
| Nemotron 3 Super 120B | Q4_K_M | 97.86% |
| Qwen 3.6-27B(今回) | UD-Q4_K_XL | 97.05% |
| Qwen 3.5-35B-A3B | MXFP4 | 96.16% |
| Qwen 3.6-35B-A3B | MXFP4 | 95.98% |
27B Dense が MoE 35B-A3B(3.5 / 3.6 とも)より +0.9〜1.1pt 高い、というのが確認できた主要な差分です。Nemotron 3 Super 120B とは 0.8pt 程度の差ですが、27B と 120B ではメモリ要件・推論速度が根本的に違うので、単純比較は参考程度にとどめた方がよいと思います。
7. 用途別の目安(個人の感想レベル)
JCQ だけの評価なので、あくまで今回測った範囲での所感です。実際の運用では各自のタスクで確認してください。
| 用途 | 目安 | コメント |
|---|---|---|
| 対話・長文生成(tg 優先) | Q4_K_M または UD-Q4_K_XL | tg 11 t/s 台、JCQ 97% 近辺。17 GiB で常時ロード可 |
| pp 主体の処理(大量入力、要約など) | BF16 | pp 888 t/s、JCQ 96.69%。ただし tg 4.55 t/s なので長文出力には不向き |
| とにかく速度 | Qwen 3.6-35B-A3B MXFP4(MoE) | 27B Dense より tg で約 5.4 倍速い |
UD-Q8_K_XL については今回のベンチでは他に優位点が見いだせなかったため、選ぶ理由を見つけにくい結果でした。筆者の測り方に抜けがある可能性もあるので、他の用途で評価される方は参考までに。
8. 今回測っていないこと
時間とスコープの都合で以下は見送りました。近日中にアップデートするつもりです。
- Thinking ON:4 モデル × 1,119 問で推定合計約 97 時間。少なくとも Q4_K_M 1 モデルだけでも一晩で取れるので、近いうちに追記予定。前回 Qwen 3.6-35B-A3B MoE では Thinking ON で +0.45pt だったので、Dense 27B でどうなるかは気になるところ
- ロングコンテキスト(pp2048/4096/16384):前回 MoE では pp 劣化率が -6.2% → -2.4% に改善していた点。Dense 27B でも同じ傾向があるか
-
VLM(画像理解):mmproj ロード時の実測。Qwen 3.6-35B-A3B でも
<unused49>氾濫や segfault 報告があったので、27B で再現するかの確認は意味がありそう - SWE-Bench など公式主張のコーディング系ベンチ:環境整備のハードルが高いので、余力があれば
- bartowski 版 GGUF との比較:公開され次第
9. まとめ
DGX Spark で Qwen 3.6-27B(Dense)の 4 量子化を llama.cpp b8892 で測ってみました。個人的に覚えておきたい点は以下です。
- 4 量子化の JCQ 差は誤差範囲。Dynamic 2.0 の 4bit(UD-Q4_K_XL)が数値上は一番よかったですが、BF16 との差は 4 問(0.36pt)で統計的に意味があるかは微妙です
- pp では BF16 が健闘、tg は小さい量子化が有利。DGX Spark の統合メモリ 128GB なら BF16 が載るので、pp 主体のワークロードでは選択肢になります
- MoE 35B-A3B(速度)か Dense 27B(品質)か、という用途依存の選択。tg で約 5.4 倍、JCQ で約 1pt の差
公式主張の「397B-A17B のコーディング性能を 27B Dense が上回る」は本記事の範囲では裏取りできませんが、日本語常識問題の範疇では 手元で動かせる 27B としては悪くない選択肢と思われます。
今回測れなかった Thinking ON・ロングコンテキスト・VLM は追って追記します。
参考リンク
- Qwen/Qwen3.6-27B(Hugging Face)
- unsloth/Qwen3.6-27B-GGUF(Hugging Face)
- llama.cpp b8892 リリース
- 前回記事: DGX Spark での Qwen 3.5 → 3.6 比較(35B-A3B MoE)
- ベンチスクリプト(前回記事のリポジトリ)
- JCommonsenseQA v1.1
- 本記事のリポジトリ(結果 JSON 等): 準備中
付録: 再現コマンド
llama-bench(4 モデル一括)
llama-bench \
-m ~/models/qwen36-27b-unsloth/Qwen3.6-27B-Q4_K_M.gguf \
-m ~/models/qwen36-27b-unsloth/Qwen3.6-27B-UD-Q4_K_XL.gguf \
-m ~/models/qwen36-27b-unsloth/Qwen3.6-27B-UD-Q8_K_XL.gguf \
-m ~/models/qwen36-27b-unsloth/BF16/Qwen3.6-27B-BF16-00001-of-00002.gguf \
-ngl 99 -fa 1 -mmp 0 -p 512 -n 128 -r 3 -o md
BF16 はシャード分割されていますが、先頭(00001-of-00002)を指定すれば llama.cpp が自動で全パートをロードします。
llama-server(JCQ 用、Thinking OFF)
llama-server \
-m ~/models/qwen36-27b-unsloth/Qwen3.6-27B-UD-Q4_K_XL.gguf \
--host 0.0.0.0 --port 8080 \
-ngl 99 -fa on -c 4096 \
--jinja --reasoning-format deepseek \
--chat-template-kwargs '{"enable_thinking":false}'
JCQ 実行
python3 jcq_bench.py \
--model qwen36-27b-udq4kxl-nothink \
--max-tokens 8 \
--output results/jcq_qwen36-27b-udq4kxl-nothink.json