はじめに
Qwen 3.6-35B-A3B が 4 月 16 日にリリースされました。SNS では SWE-bench 73.4% のエージェントコーディング性能が話題ですが、ローカル推論環境での実測比較はまだあまり見かけません。公式ベンチマークだけを見ると Qwen 3.5 との差は「コーディングが強くなった」程度に見えます。しかし DGX Spark 上で llama.cpp を使って実測してみると、スペックシートには現れない改善が3つほど見つかりました。
本記事は前回の DGX Spark で Gemma 4 vs Qwen 3.5 MoE モデル対決ベンチマーク と同じ構成・スクリプトで、Qwen 3.5 → 3.6 の世代間比較を行ったものです。前回記事で取得した Gemma 4 の結果も参考値として併記しています。
結論
① 推論速度の世代間差は誤差範囲(±0.5%)
| 指標 | Qwen 3.5 | Qwen 3.6 | 差 | (参考) Gemma 4 F16 |
|---|---|---|---|---|
| pp512 (t/s) | 2,299.73 | 2,304.22 | +0.2% | — |
| tg128 (t/s) | 63.17 | 62.91 | -0.4% | — |
| JCQ レイテンシ (s/問) | 0.228 | 0.225 | -1.3% | 0.376 |
速度は完全に同等。移行によるデメリットはありません。Gemma 4 は F16(51 GiB)での測定のため tg が遅い点に注意してください。
② ロングコンテキストの pp 劣化率が 2.6 倍改善
LLM にとって「プロンプトが長くなるほど処理速度が落ちる」のは避けられない傾向です。pp 劣化率とは、短いプロンプト(pp512)を基準に、長いプロンプト(pp16384)で速度がどれだけ低下するかを示す指標です。この値が小さいほど、長文入力でも速度を維持できていることを意味します。
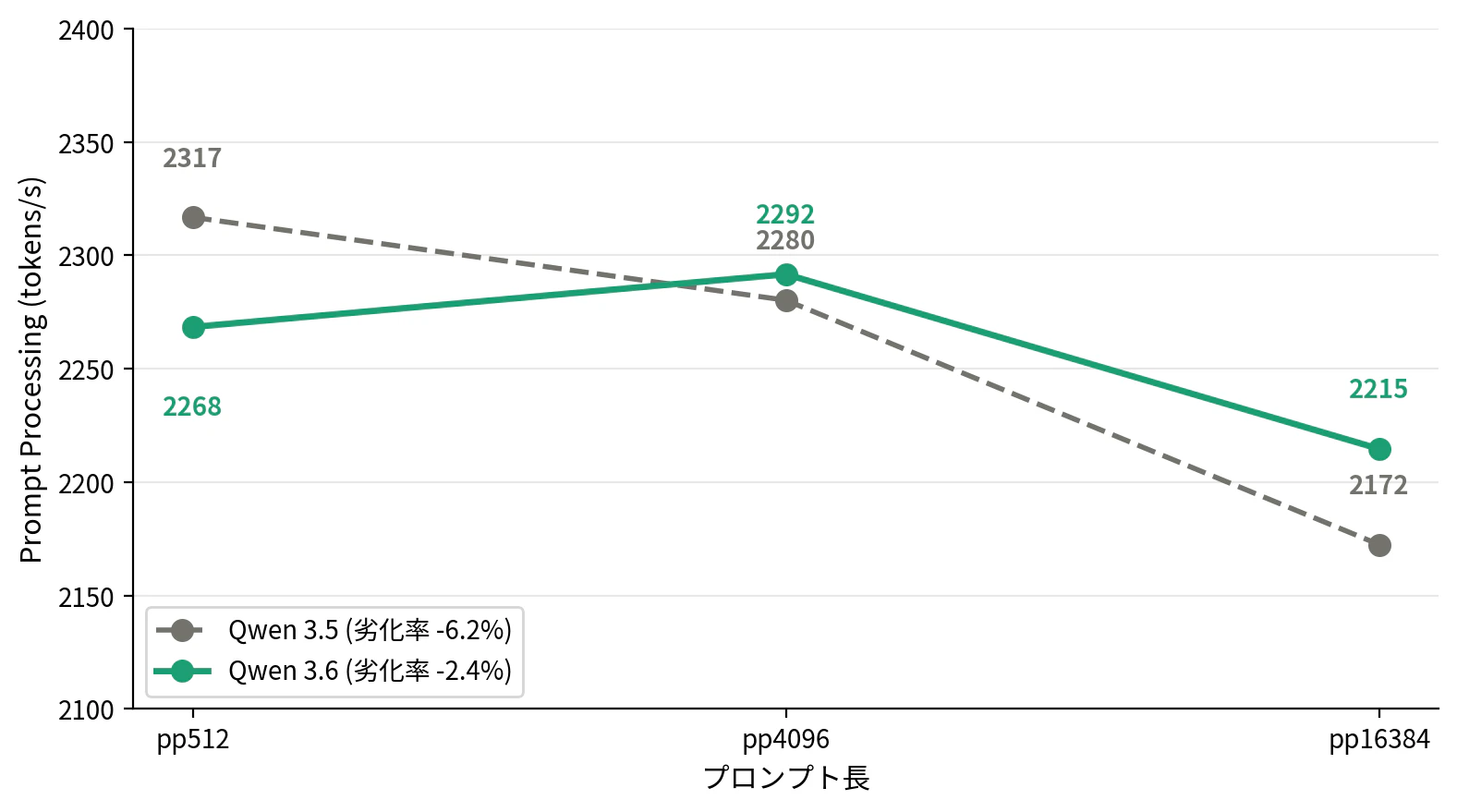
| プロンプト長 | Qwen 3.5 (t/s) | Qwen 3.6 (t/s) |
|---|---|---|
| pp512 | 2,316.82 | 2,268.44 |
| pp4096 | 2,280.22 | 2,291.70 |
| pp16384 | 2,172.44 | 2,214.62 |
| 劣化率 (512→16K) | -6.2% | -2.4% |
RAG や長文要約でコンテキストが長くなるシーンでは、この差が効いてきます。Qwen 3.6 は pp4096 の時点で 3.5 を逆転し、pp16384 でもその差を維持しています。公式ブログでは長コンテキスト対応の改善が言及されていますが、pp 劣化率として数値化された報告は見当たりませんでした。
③ Thinking モードの品質劣化が解消
Thinking モードとは、回答の前に ... タグ内で推論過程を生成させる機能です。複雑な問題では精度が上がることが期待されますが、Qwen 3.5 では知識系タスクで「考えすぎて」かえって間違える傾向がありました。思考トークンが長くなるほど、最初の直感的な正解から逸れてしまうためと考えられます。

| モデル | Thinking OFF | Thinking ON | 差 |
|---|---|---|---|
| Qwen 3.5 MXFP4 | 96.16% | 89.28% | -6.88pt |
| Qwen 3.6 MXFP4 | 95.98% | 96.43% | +0.45pt |
| (参考) Gemma 4 F16 | 96.51% | ❌ Bug | — |
Qwen 3.5 では Thinking ON にすると正解率が 6.88 ポイント劣化していました。Qwen 3.6 ではむしろ 0.45 ポイント改善。「考えさせても品質が落ちない」のは、Thinking を常用する環境で大きな安心材料です。
検証環境
| 項目 | 内容 |
|---|---|
| ハードウェア | NVIDIA DGX Spark (Grace Blackwell GB10, 128 GB 統合メモリ) |
| 推論エンジン | llama.cpp b8672 (ソースビルド, CUDA) |
| モデル (3.5) | Qwen3.5-35B-A3B-MXFP4_MOE.gguf (21 GiB) |
| モデル (3.6) | Qwen3.6-35B-A3B-MXFP4_MOE.gguf (21 GiB) |
| (参考) Gemma 4 | gemma-4-26B-A4B-it-f16.gguf (51 GiB) |
| 量子化 | MXFP4_MOE(MoE テンソルに MXFP4、残りに Q8) |
| 品質テスト | JCommonsenseQA v1.1(1,119 問、5 択、3-shot) |
| VLM テスト | キャプション生成 / JSON 抽出 / PPE 検出(8 画像) |
なぜ llama.cpp なのか
SNS で見かける Qwen 3.6 の速度報告の多くは Ollama ベースです。X で報告されている Qwen 3.5 の tg 速度は約 60 t/s ですが、本記事の llama.cpp native では 63 t/s(+5%) が出ています。
理由は 3 つです。
-
ビルドオプションの最適化: GB10 向けに
-DCMAKE_CUDA_ARCHITECTURES=121を指定してネイティブビルドできる - MXFP4_MOE 量子化の利用: Ollama のレジストリにはない量子化形式で、Blackwell の MXFP4 ハードウェアパスを活用できる
- llama-bench による純粋な速度計測: 推論エンジンのオーバーヘッドを含まない計測ができる
これらの条件が揃うことで、Ollama 経由では見えないモデル本来の性能差を引き出せます。特に今回の Qwen 3.5 → 3.6 のような微小な世代間差を検出するには、推論エンジン側のばらつきを排除できる llama.cpp が適していると思います。
セットアップ手順
1. llama.cpp のビルド
DGX Spark の GB10 GPU に最適化した llama.cpp をソースからビルドします。
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build \
-DGGML_CUDA=ON \
-DCMAKE_CUDA_ARCHITECTURES=121 \
-DGGML_CUDA_F16=ON \
-DGGML_NATIVE=ON \
-DCMAKE_BUILD_TYPE=Release
cmake --build build --config Release -j$(nproc) \
--target llama-server llama-cli llama-bench llama-mtmd-cli
各オプションの意味:
-
-DGGML_CUDA=ON: CUDA バックエンドを有効化 -
-DCMAKE_CUDA_ARCHITECTURES=121: GB10 の compute capability 12.1 向けにカーネルを最適化。これを指定しないと汎用ビルドになり、Blackwell 固有の命令(MXFP4 等)が使えない -
-DGGML_CUDA_F16=ON: CUDA の FP16 演算を有効化。GB10 は FP16 演算が高速なため、行列計算の精度を保ちつつ速度向上が期待できる -
-DGGML_NATIVE=ON: ホスト CPU(Grace Arm)のネイティブ命令セットに最適化 -
--target ...: 必要なバイナリだけをビルドして時間を短縮
ビルド確認:
./build/bin/llama-server --version
# version: 8672 (25eec6f32)
# built with GNU 13.3.0 for Linux aarch64
2. モデルのダウンロード
Python の仮想環境を作り、hf コマンドで GGUF ファイルをダウンロードします。
python3 -m venv ~/llm-test
source ~/llm-test/bin/activate
pip install huggingface_hub datasets httpx
# Qwen 3.5 MXFP4_MOE (21 GiB)
hf download noctrex/Qwen3.5-35B-A3B-MXFP4_MOE-GGUF \
--local-dir ~/models/qwen35/
# Qwen 3.6 MXFP4_MOE (21 GiB)
hf download unsloth/Qwen3.6-35B-A3B-GGUF \
--include "Qwen3.6-35B-A3B-MXFP4_MOE.gguf" \
--local-dir ~/models/qwen36/
# VLM 用 mmproj(Qwen 3.5 用)
hf download unsloth/Qwen3.5-35B-A3B-GGUF \
--include "mmproj-F16.gguf" \
--local-dir ~/models/qwen35/
# VLM 用 mmproj(Qwen 3.6 用)
hf download unsloth/Qwen3.6-35B-A3B-GGUF \
--include "mmproj-F16.gguf" \
--local-dir ~/models/qwen36/
ダウンロード後のディレクトリ構成:
~/models/
├── qwen35/
│ ├── Qwen3.5-35B-A3B-MXFP4_MOE.gguf (21 GiB)
│ └── mmproj-F16.gguf (858 MiB)
└── qwen36/
├── Qwen3.6-35B-A3B-MXFP4_MOE.gguf (21 GiB)
└── mmproj-F16.gguf (899 MiB)
3. llama-server の起動
ダウンロードしたモデルを使って推論サーバーを起動します。
テキスト推論(JCQ ベンチ / 日常利用):
~/llama.cpp/build/bin/llama-server \
-m ~/models/qwen36/Qwen3.6-35B-A3B-MXFP4_MOE.gguf \
-ngl 999 --jinja \
--reasoning off \
--port 8080 \
--temp 1.0 --top-p 0.95 --top-k 64
主要オプションの意味:
-
-ngl 999: GPU にオフロードするレイヤー数。999 を指定すると全レイヤーを GPU に載せる。DGX Spark の 128 GB 統合メモリなら余裕で収まる -
--jinja: Jinja2 テンプレートエンジンを使ってチャットテンプレートを処理する。Qwen 3.5/3.6 の Thinking 制御に必要 -
--reasoning off: Thinking モード(<think>...</think>による推論過程の出力)を無効化。応答が短く速くなる -
--reasoning on: Thinking モードを有効化。回答前に推論過程を生成するため遅くなるが、複雑なタスクでは品質が向上する場合がある -
--temp 1.0: 温度パラメータ。高いほどランダムな出力になる。Qwen 公式推奨値は 1.0 -
--top-p 0.95: 累積確率が 95% に達するまでのトークンから次のトークンを選択する(nucleus sampling)。公式推奨値 -
--top-k 64: 確率上位 64 トークンに候補を絞る。公式推奨値
VLM(マルチモーダル推論) — 画像入力を使う場合は mmproj を追加します:
~/llama.cpp/build/bin/llama-server \
-m ~/models/qwen36/Qwen3.6-35B-A3B-MXFP4_MOE.gguf \
--mmproj ~/models/qwen36/mmproj-F16.gguf \
-ngl 999 --jinja \
--reasoning off \
--port 8080
-
--mmproj: Vision Encoder(マルチモーダルプロジェクター)の GGUF ファイルを指定。これにより画像を含むリクエストを処理できるようになる
--chat-template-kwargs は deprecated です
llama.cpp b8672 以降では、Thinking モードの制御に --reasoning on/off を使います。旧方式の --chat-template-kwargs '{"enable_thinking":false}' も動作しますが、起動時に deprecation 警告が表示されます。旧方式はチャットテンプレートの内部パラメータを直接書き換える仕組みだったため、モデルごとにパラメータ名が異なる問題がありました。--reasoning はモデルに依存しない統一的なインターフェースです。
4. ベンチマークの実行
前回記事と同じスクリプトを使ってベンチマークを実行します。GitHub リポジトリ にスクリプトと結果 JSON があります。
git clone https://github.com/nabe2030/gemma4-vs-qwen35-dgx-spark.git
cd gemma4-vs-qwen35-dgx-spark
source ~/llm-test/bin/activate
JCommonsenseQA — まず 5 問テストで動作確認してから全問実行します:
# 5 問テスト(動作確認)
python3 jcq_bench.py \
--model qwen36-mxfp4-nothink \
--max-tokens 8 \
--output results/jcq_qwen36_mxfp4_nothink.json \
--limit 5
# OK なら全問実行(約 4.5 分)
python3 jcq_bench.py \
--model qwen36-mxfp4-nothink \
--max-tokens 8 \
--output results/jcq_qwen36_mxfp4_nothink.json
Thinking ON の場合はサーバーを --reasoning on で再起動し、--max-tokens 2048 に変更します。思考トークンが長くなるため約 3 時間かかります。tmux で実行してデタッチ(Ctrl+b d)するのがおすすめです。
# tmux 内で実行、約 3 時間
python3 jcq_bench.py \
--model qwen36-mxfp4-think \
--max-tokens 2048 \
--output results/jcq_qwen36_mxfp4_think.json
VLM ベンチ — llama-server を mmproj 付きで起動した状態で実行します:
python3 vlm_bench.py \
--model qwen36-mxfp4-vlm \
--image-dir ~/vlm-test-images \
--output results/vlm_qwen36.json
ベンチマーク結果
速度: llama-bench
llama-bench は llama.cpp 付属の純粋な速度計測ツールで、サーバーのオーバーヘッドを含まない生の推論速度を計測できます。
基本ベンチマーク (pp512 / tg128)
# Qwen 3.5
| Qwen3.5-35B-A3B-MXFP4_MOE | 20.21 GiB | 34.66 B | CUDA | 999 | pp512 | 2299.73 ± 18.23 |
| Qwen3.5-35B-A3B-MXFP4_MOE | 20.21 GiB | 34.66 B | CUDA | 999 | tg128 | 63.17 ± 0.07 |
# Qwen 3.6
| Qwen3.6-35B-A3B-MXFP4_MOE | 20.21 GiB | 34.66 B | CUDA | 999 | pp512 | 2304.22 ± 35.32 |
| Qwen3.6-35B-A3B-MXFP4_MOE | 20.21 GiB | 34.66 B | CUDA | 999 | tg128 | 62.91 ± 0.04 |
pp / tg ともにほぼ同一。アーキテクチャ(MoE 構成、GDN + Attention 比率)が同じなので当然の結果です。
ロングコンテキスト・スケーリング
プロンプト長を 512 → 4096 → 16384 と増やした際の Prompt Processing 速度の変化を計測しました。
pp512 pp4096 pp16384 劣化率
Qwen 3.5 2,316.82 2,280.22 2,172.44 -6.2%
Qwen 3.6 2,268.44 2,291.70 2,214.62 -2.4%
Qwen 3.6 は pp4096 で 3.5 を逆転し、pp16384 でもその差を維持しています。公式ブログでは長コンテキスト対応の改善が言及されていますが、pp の劣化率として数値化された報告は見当たりませんでした。
品質: JCommonsenseQA
JCommonsenseQA v1.1(1,119 問、5 択)で日本語の常識推論能力を評価しました。3-shot プロンプトで回答させ、選択肢番号の一致で正誤を判定しています。
Thinking OFF
| モデル | 正解率 | レイテンシ | tok/s |
|---|---|---|---|
| (参考) Gemma 4 F16 | 96.51% (1080/1119) | 0.376s | 26.7 |
| Qwen 3.5 MXFP4 | 96.16% (1076/1119) | 0.228s | 97.7 |
| Qwen 3.6 MXFP4 | 95.98% (1074/1119) | 0.225s | 98.4 |
Qwen 3.5 → 3.6 の差は 2 問(0.18 ポイント)で誤差範囲。前回記事の Qwen 3.5 結果(96.16%)と完全に一致しており、再現性も確認できました。Gemma 4 は F16(51 GiB)での測定のためレイテンシが長いですが、品質は最高です。
Thinking ON
| モデル | 正解率 | レイテンシ | tok/s |
|---|---|---|---|
| Qwen 3.6 MXFP4 | 96.43% (1079/1119) | 9.15s | 61.7 |
| (参考) Gemma 4 Q4_K_M | 95.80% (1072/1119) | 6.80s | 64.5 |
| Qwen 3.5 MXFP4 | 89.28% (999/1119) | 13.71s | 60.2 |
| (参考) Gemma 4 F16 | ❌ Bug (#21338) | — | — |
Qwen 3.6 は Thinking ON で Gemma 4 Q4_K_M を上回るスコアを出しました。レイテンシも 3.5 の 13.71s から 9.15s に 33% 短縮されており、思考トークン量が適正化された可能性があります。
Gemma 4 の F16 Thinking ON は llama.cpp で <unused49> トークンが氾濫するバグ(Discussion #21338)があり計測不可のままです。Q4_K_M では正常に動作します。
全モデル比較まとめ
| モデル | 量子化 | Thinking | JCQ 正解率 |
|---|---|---|---|
| (参考) Gemma 4 26B-A4B | F16 | OFF | 96.51% |
| Qwen 3.6 | MXFP4 | ON | 96.43% |
| Qwen 3.5 | MXFP4 | OFF | 96.16% |
| Qwen 3.6 | MXFP4 | OFF | 95.98% |
| (参考) Gemma 4 26B-A4B | Q4_K_M | ON | 95.80% |
| Qwen 3.5 | MXFP4 | ON | 89.28% |
| (参考) Gemma 4 26B-A4B | F16 | ON | ❌ Bug (#21338) |
VLM マルチモーダル
vlm_bench.py で、キャプション生成・JSON タグ抽出・PPE(保護具)検出の 3 タスクを評価しました。Gemma 4 は F16 での計測のため参考値です。
| タスク | Qwen 3.5 | Qwen 3.6 | 差 | (参考) Gemma 4 F16 |
|---|---|---|---|---|
| Caption 平均レイテンシ | 17.05s | 15.82s | 3.6 が 7% 速い | 41.68s |
| JSON 抽出 レイテンシ | 3.82s | 3.92s | ほぼ同じ | 41.31s (parse ✗) |
| PPE 検出 レイテンシ | 5.34s | 5.07s | 3.6 が 5% 速い | — |
| JSON parse 成功率 | 100% | 100% | 同じ | 0% |
| PPE parse 成功率 | 100% | 100% | 同じ | — |
| tok/s | ~61.4 | ~61.6 | 同じ | 25.7 |
Qwen 3.5 / 3.6 は VLM でも世代間差は微小です。Gemma 4 F16 は JSON 抽出のパース成功率が 0% でした(前回記事参照)。
なお、Unsloth の Discussion では Qwen 3.6 の llama.cpp VLM でセグメンテーションフォルトが報告されていますが、本環境(DGX Spark, b8672, mmproj-F16)では問題なく動作しました。
systemd サービス化
Qwen 3.6 に移行して常時起動させたい場合の systemd ユニットファイル例です。
# /etc/systemd/system/llama-server.service
[Unit]
Description=llama-server Qwen3.6-35B-A3B MXFP4 + Vision
After=network.target
[Service]
Type=simple
User=nabe
ExecStart=/home/nabe/llama.cpp/build/bin/llama-server \
-m /home/nabe/models/qwen36/Qwen3.6-35B-A3B-MXFP4_MOE.gguf \
--mmproj /home/nabe/models/qwen36/mmproj-F16.gguf \
--host 0.0.0.0 --port 8080 \
-ngl 999 --jinja --reasoning off
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target
sudo systemctl daemon-reload
sudo systemctl enable --now llama-server
まとめ
Qwen 3.6 は派手なスペック向上こそないものの、ローカル推論環境で効く改善が着実に入ったアップデートでした。
| 観点 | 評価 |
|---|---|
| 速度 | 同等(移行のデメリットなし) |
| ロングコンテキスト | 改善(pp 劣化率が 2.6 倍縮小) |
| Thinking 品質 | 大幅改善(-6.88pt → +0.45pt) |
| VLM | 同等(セグフォ報告あるが本環境では未発生) |
| モデルサイズ | 同一(21 GiB、GGUF を差し替えるだけ) |
Qwen 3.5 を MXFP4 で運用している環境なら、GGUF ファイルを差し替えるだけで移行できます。特に Thinking モードを常用している場合は、3.6 への移行を強く推奨します。