今年の10月からグロービスのデータサイエンスチームに配属され、2ヶ月間データ基盤構築をしてきました。実際やってきたことを踏まえて、データ基盤の構築時に気をつけるべきポイント7つを紹介していきたいと思います。
- 最強だと思う分析用データベースを選ぶ
- ワークフローエンジンでジョブを管理する
- ステークホルダーとの調整を優先度高くする
- 権限(IAM)の運用ルールを決める
- 監視設定を忘れずに
- メタデータ管理ツールを用意する
- SQL中心アーキテクチャを意識する
1. 最強だと思う分析用データベースを選ぶ
ここが一番大事です。自分が最強だと思う分析用のデータベースを選んでください。ちなみに、私はBigQuery信者なので、BigQueryを強くおすすめしますが、いろんなデータベースがあるので今の環境に一番あった分析用データベースを選んでください。
分析用データベースの全体像を掴むには渡部徹太郎さんの資料「ビッグデータ処理データベースの全体像と使い分け 2018年version」が参考になると思います。2018バージョンなので現在までの差分はキャッチアップしましょう。最近ではAzure Synapseなんかも発表されて、選択肢は広がってきていると思います。
グロービスでは、もともとデータ分析にBigQueryが採用されていたこともあり、あっさりBigQueryの採用が決まりました。
2. ワークフローエンジンでジョブを管理する
データ基盤を作るのであれば、ワークフローエンジンでジョブを管理するようにしましょう。ワークフローエンジンとは、ジョブ管理をいい感じでやってくれるツールで、有名なものだと、AirflowやDigDagなどがあります。依存ジョブの管理してくれたり、データのtransfer用のライブラリが充実してたり、ジョブのステータス管理用のWeb UIが提供されたりと、データ基盤のジョブ管理に便利なものが提供されます。@elyunim26さんの「2019年のワークフローエンジンまとめ」が大変参考になります。
よくある cron + DBのステータス管理ではすぐにつらみが出てくるので、ある程度の規模のデータ基盤であれば、早めにワークフローエンジンでジョブを管理することをお勧めします。とりあえず、、っていう感じでcron + DBのステータス管理でのジョブ管理を始めてしまうと、時間とともに管理コストも移行コストも高くなってしまいます。
グロービスではGCPが提供する、Cloud Composer(フルマネージドのAirflowクラスタサービス)を採用しました。最大の理由はフルマネージドで管理できることです。デプロイ管理や、監視、HA構成の構築など、今後ワークフローエンジンにかかるであろう開発コストを考慮して採用を決めました。とはいえ、Cloud Composerは結構高価(最低でも月4,5万かかる)なので、かなり悩みました。というか、まだ悩んでいます。ワークフローエンジンに関しては、運用しながら柔軟に決めていこうと思っています。
3. ステークホルダーとの調整を優先度高くする
おそらくここが一番大変だと思います。データ基盤はデータがないと意味がないので、様々な事業システムからデータをもらう必要があります。さらに、取得したデータの取り扱いに法的な問題がないかも、社内で確認しなければいけません。多くのステークホルダーと調整が必要なります。このあたりの調整は時間かかったり、長い待ちが発生するため、優先度高く、早め早めにやっていくべきです。
データ取得は負担がかからないところから
データを提供する事業システム側からすると、データ提供は面倒なものです。データ基盤構築初期には、柔軟なデータ取得システムを構築することは困難かもしれません。そういった場合は、事業システム側に負担にならない形でデータ取得を進めていくようにしましょう。少しでもデータ基盤活用のメリットを事業システム側に感じてもらうことができれば、さらに柔軟なデータ取得システムの構築を進めていけるはずです。
セキュリティ周りは慎重に
データ基盤構築で避けて通れないのはデータのセキュリティ管理です。セキュリティ周りは、特に慎重に調整する必要があります。データの運用に法律的な問題がないかをチェックできる運用ルールをステークホルダーを巻き込んで作っていきましょう。
どの程度のセキュリティ強度のデータをどこに置いて、誰がアクセスできるのか、それが法律的に問題ないなど確認していきましょう。データの活用に関しても、法律、規約的に問題ないのかをチェックできる共有フローを作りましょう。問題がある場合は、利用規約などを変更しなければならないケースもあるので、早めに動く必要があります。
4. 権限(IAM)の運用ルールを決める
セキュリティ周りの管理も含め、IAMの運用ルールはきちんと決めておきましょう。特に、データ基盤はアクセスする人が増えていくので、運用負荷がかからない方法でルール決めをしましょう。
グロービスでは、@kusuwadaさんの「中規模プロジェクトでの GCP権限管理(アクセス制御)ベストプラクティス」の記事を参考に、グーグルグループを利用したIAM運用ルールを定めました。
個人のアカウントへのIAM権限の直接付与を原則禁止し、グーグルグループの権限への追加、取り外しで権限コントロールができるようにしています。グループは以下のようなものを用意しました。
| グループ名 | 説明 | セキュリティ情報 |
|---|---|---|
| owner | 全ての権限を持つ | ○ |
| editor | IAM作成など一部の管理サービスを除く全ての編集権限 | ○ |
| developer | 開発に必要な編集権限をもつ | × |
| gcs_bq_developer | BQとGCSの編集権限をもつ | × |
| bq_viewer | BQの閲覧権限をもつ | × |
| pi_operator | セキュリティ情報へアクセスできる | ○ |
5. 監視設定を忘れずに
データ基盤の障害はユーザーへの影響が直接的ではないので、監視が後回しになりがちですが、忘れずにやっていきましょう。
グロービスでも以下の基本的な監視設定は行うようにしています。
| 項目 | 監視ツール |
|---|---|
| ワークフローエンジンのリソース監視 | StackDriver |
| BigQueryのslot監視 | StackDriver |
| プロジェクトの予算監視 | GCP予算アラート機能 |
| ユーザー/サービスアカウント毎のBigQueryの使用量の監視 | superQuery |
| BigQueryに高額クエリが投げられないように制御 | BigQueryのカスタムコスト管理 |
また、通知先はslackに集約し、以下の3つのチャンネルに通知を分けて飛ばすようにしています。
| チャンネル | 役割 |
|---|---|
| alart用チャンネル | 対応が必要な事象が起こった場合 |
| warn用チャンネル | すぐに対応はいらないが、システムの不調、不具合が発生した場合、もしくは、中期的に対応が必要な事象が起こった場合 |
| notification用チャンネル | 起動時のログや、処理成功のログなど、一応把握しておきたいもの |
6. メタデータ管理ツールを用意する
扱うデータが大規模になっていくにつれ、メタデータの管理の必要が出てきます。メタデータの概要については、尾崎弘宗さんの「データ利活用を進めるメタデータ」の資料がわかりやすいです。メタデータ運用には制約が多く、自前でメタデータツールを作っているところが多いようです。
グロービスではメタデータツールとして、GCPのデータカタログを採用しました。データカタログはGCPの提供するメタデータの管理ツールで、BigQueryやPub/Subのメタデータが自動で検索できるようになります。グロービスのデータ基盤がBigQueryで構築されているため、データカタログを採用することにより自動でメタデータの検索が可能になりました。
例えば、 project_code というカラムを持ったテーブルを探したい場合は、 データカタログ上でcolumn: project_code という検索をすると対象のテーブル一覧が取得できます。さらに、テーブルの説明やカラムの説明をBigQueryに登録すれば、これも検索対象となります。
データセット、テーブル、カラムの説明の記入などは、退屈な作業で避けがちなので、時間をとってチームでやってしまったり、担当を決めて持ち回りでやったりしていきましょう。
7. SQL中心アーキテクチャを意識する
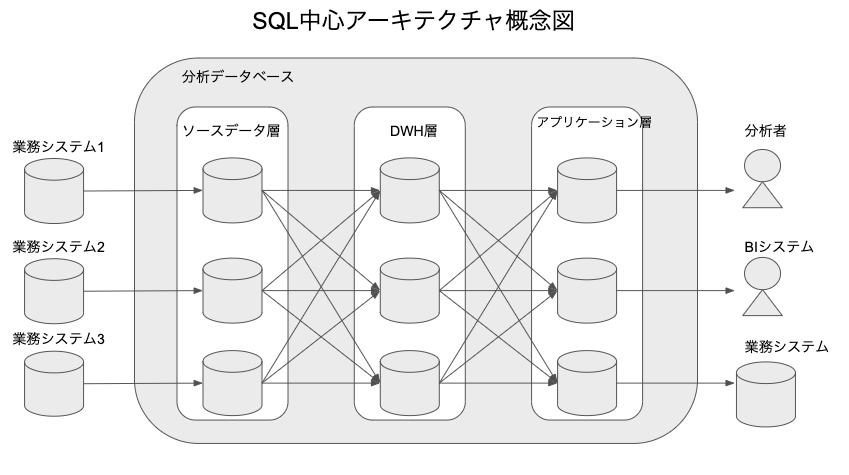
SQL中心アーキテクチャは、青木峰郎さんの「10年戦えるデータ分析入門」のという本で"理想の分析システム"として紹介されているものです。以下、本書からの引用です。
SQL中心アーキテクチャは以下の3つの条件を満たす分析システムです
- 必要なデータを1つのデータベースに集める
- データの加工には原則としてSQLだけを用いる
- データベース内を論理的にソースデータ層・DWH層・アプリケーション層の3つの層に区分する
さらに、3つの層について本書からの引用です。
ソースデータ層: 元データをそのまま格納した層
DWH層: 整理・統合された汎用共通データモデル層
アプリケーション層: 特定の分析やアプリケーションに特有のデータを格納する層(データマート)
SQL中心アーキテクチャの詳しいことや、利点などについてはここでは割愛しますが、非常にシンプルで汎用的、さらに実現的な分析システムとして提案されています。データ基盤を構築していく上では、このアーキテクチャを意識したものにすることをおすすめします。このあたりの議論は@yuzutas0さんの「データ基盤の3分類と進化的データモデリング」でも行われており、とても参考になります。
グロービスでは、BigQueryのデータセット管理や、命名規則にこのアーキテクチャの考え方を取り入れています。セキュリティ面や、IAMの運用を考慮して以下の4つのデータセットで運用しています。
| データセット名 | 説明 |
|---|---|
| unmasked_source | セキュリティ強度の高いデータであり、オーナーや編集者でないとアクセスできないデータセット |
| source | ソースデータ層にあたるデータセット |
| warehouse | DWH層にあたるデータセット |
| mart | アプリケーション層にあたるデータセット |
そして、テーブルの命名規則は ${service_name}__%{table_name} のようなルールで運用しています。
このような命名規則での運用を原則とし、出来るだけSQL中心アーキテクチャに乗っかるような運用となるように意識しています。
終わりに
以上、データ基盤構築の際に注意して欲しいポイントと、グロービスで実際やったことを紹介させてもらいました。実際の運用はこれからで、運用してみたら実はここが辛かったってことがいっぱい出てくると思います。そのあたりも、また別の機会で共有していきたいと思っています。皆様のデータ基盤構築の参考になれば嬉しいです。
参考資料まとめ
-
ビッグデータ分析のシステムと開発がこれ1冊でしっかりわかる教科書 渡部 徹太郎
- データ基盤構築全体を見渡す中で大変参考にさせていただきました
- ビッグデータ処理データベースの全体像と使い分け 2018年version 渡部 徹太郎
- 2019年のワークフローエンジンまとめ @elyunim26
- 中規模プロジェクトでの GCP権限管理(アクセス制御)ベストプラクティス @kusuwada
- データ利活用を進めるメタデータ 尾崎弘宗
- [10年戦えるデータ分析入門 青木峰郎]
(http://yuzutas0.hatenablog.com/entry/2018/12/02/180000) - 「データ基盤の3分類と進化的データモデリング @yuzutas0」