
概要
データパイプラインの管理にワークフローエンジンを導入したいのですが、今の要件に対してどれが合っているのか判断しきれない部分があるので整理してみました
最近の導入事例や発表をみるかぎりAirflow, Argo, Digdagあたりが人気なのかなと思います
ワークフローエンジンとは
ワークフローエンジンとは定期的なバッチ処理をうまく処理できるように、バッチ実行を管理してくれるソフトウェアのことです
古典的な実現方法としては適当なlinuxサーバーの上でcron実行させることが考えられますが、以下のような問題があります
- ジョブごとの依存関係を表現できない。cronの時間指定で実現させようとすると、タスクAを1時に開始してそれが完了するとみなして依存するタスクBを2時に開始するというような書き方をすることになるが、実際にタスクAが2時までに終わらなかった場合に処理が上手く実行できない
- タスクの成否の検知・可視化や、失敗した場合の調査用のログ閲覧の機構を作り込む必要がある
ワークフローエンジンを利用することにより上記の問題を解決できます
- ジョブごとの依存関係をdag(有向非巡回グラフ)の形で表現できる。タスクAが終了したら依存するタスクBを実行するように記述できる
- タスクの成否がGUI・CUIから確認できる。ログも保管され簡易に見れるようになっている
dagを扱えることは最近のワークフローエンジンであれば標準装備されています。またジョブの移植性・再現性を高めるためにコンテナ上でジョブを実行できる機能も最近のものには付いています
ワークフローエンジンを構成する機能
例えばデータベースから取得した情報の加工などのetl処理を実現するにあたり、下記のような要素が考えられます
(ジョブ単体をコンテナ化した場合に入れられるもの)
- DBへの入出力処理の抽象化
- DBに対するクエリ
- DBテーブルを作成する場合のスキーマ定義
- 個別のデータを整形するための前処理のコード
(ジョブ単体をコンテナ化した場合でも入れられないもの)
- ジョブの依存関係(dag)
- ジョブの起動タイミング(cron式など)
- 秘匿情報(APIキー)や共通設定・環境ごとに異なる値の読み込み
ジョブをコンテナ化することでジョブそのものの移植性は確保できます。しかしワークフローエンジンの機能である依存関係や実行タイミングはジョブの上位のレイヤーにあたり記述方法がプロダクトごとに異なります。そのためすべてを移植可能なものとすることはできず、一度選択したワークフローエンジンとはある程度付き合っていく覚悟が必要なものと思われます
ワークフローエンジンに必要な実行環境
- ジョブを実行するワーカーインスタンス
- ↑を管理するマスターインスタンス
- GUIの応答用インスタンス
- 状態を保存するDB
1つのインスタンスで複数の役割を兼ねることもありますが、計算リソースの他にDBストレージも必要になります
タスクの成否を保存するために状態を持つ必要があるためです
それぞれのワークフローエンジン
全てOSSです
Airflow
思想:オールインワン
用途:定期的(日次)に動かすデータパイプラインの記述に特化
ジョブの依存関係であるdagをpythonで記述するので最低限のpython力を前提にしているソフトウェアです
本体のソースコードもpythonです
WebUIの完成度に大きなアドバンテージがあります
- WebUIだけで失敗した特定のDAGの再実行が可能、タスク単位の実行もできる、ログも見れる
- 依存関係を考慮した各タスク × 日付ごとに表示できるTreeViewで進捗を一覧できる
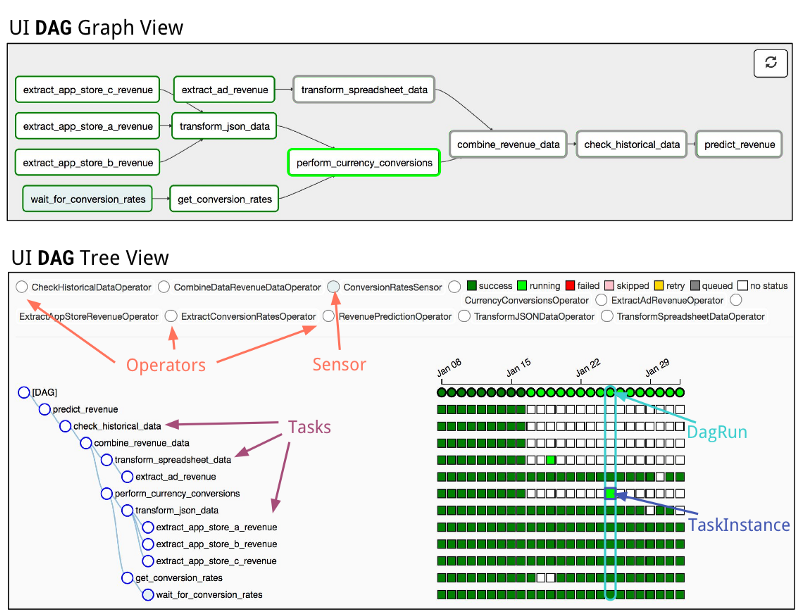
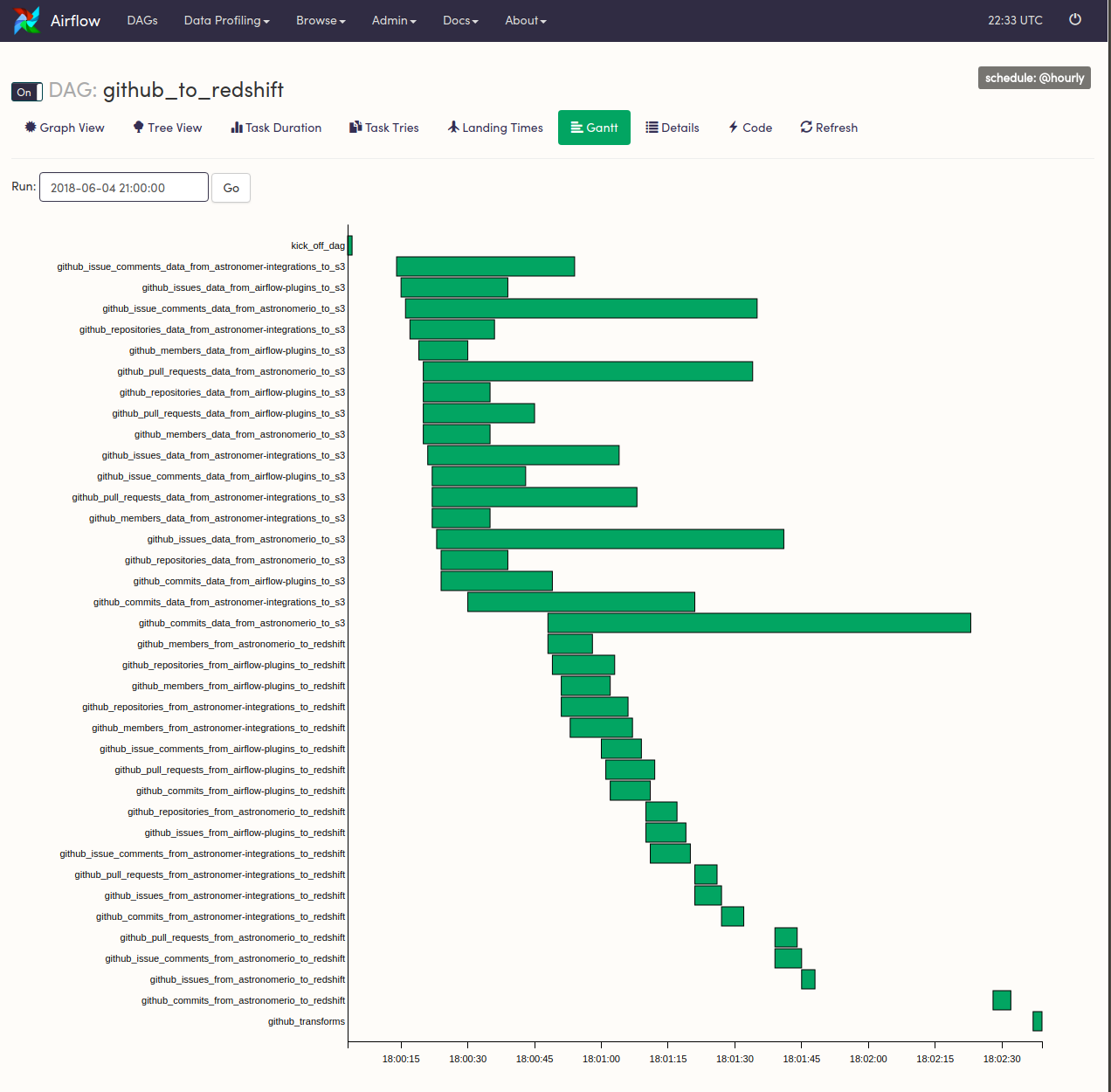
- タスクごとの実行時間を可視化できるGanttで実行時間を一覧できる
フルマネージドサービス
またCloud ComposerというGCPのフルマネージドサービスが出る程度に人気があります。ただし最小構成で3ワーカー立てられるのと本体部分のインスタンスが高額なので、立ち上げっぱなしにすると月額400$ほどかかってしまいます。運用を金で買うということですね
下記ページは総額がちゃんと書いてないので分かりづらいですが、us-central1の場合で本体部分のwebインスタンス+dbインスタンスで300$+ワーカーn1-standard-1が3つで100$ほどかかります
https://cloud.google.com/composer/pricing?hl=ja
豊富なOperator, Sensor
AWS, GCPのSaasとの接続SDKをラップした組み込みのOperator, Sensorが公式・非公式を含めたくさんあります
Operator
タスクを定義するもので多くはSaasのSDKをラップしたものです。
コントリビュートされたOperatorは下記から見れます
https://github.com/apache/airflow/tree/c720c352f0762a483fa1202e1477e740631a8184/airflow/contrib/operators
例えば次のような感じでGoogleCloudStrageからBigQueryにデータをインポートするタスクを定義できます
with DAG(job_name, default_args=dag_args, schedule_interval='@daily') as dag:
task_gcs_to_bq = GoogleCloudStorageToBigQueryOperator(
task_id='gcs_to_bq',
bucket="バケット名",
source_objects=["{{ task_instance.xcom_pull(task_ids='before_task') }}"],
destination_project_dataset_table="テーブル名",
schema_fields=json.load(open(schema_path)),
source_format='CSV',
create_disposition='CREATE_IF_NEEDED',
write_disposition='WRITE_TRUNCATE',
skip_leading_rows=1,
max_bad_records=100,
bigquery_conn_id='conn_id',
google_cloud_storage_conn_id='conn_id',
)
Sensor
Operatorと同じように扱うのですが、Operaorの前段として記述します。
特定の条件を満たすまでポーリングして、条件が満たされたら次のOperatorを発火するという処理が記述できます。
コントリビュートされたSensorは下記から見れます。
https://github.com/apache/airflow/tree/4d153ad4e85a945defca618d8fc3dc22b8535f93/airflow/contrib/sensors
使用例として下記のような感じでOperatorにつなげることができます。
https://gist.github.com/msumit/40f7905d409fe3375c9a01fa73070b73
Operatorの品質問題
上記の利点を裏返すと開発が活発であるがゆえにバグも多いというのがあります。全てのoperatorの品質が完全であるとは言えず、
- sdkの最新の更新に対応するのにラグがある
- cliを直で叩いたほうがcliの最適化が効いて早い場合がある (計測した環境ではS3ToGoogleCloudStorageOperatorを使うよりgsutil cpコマンドをBashOperatorから叩いたほうがファイルの移動が早かったです)
- Operatorの挙動が思い通りでない場合、パラメータの渡し方の誤りかラッパーコードのバグなのかが判断できず結局該当Operatorのソースコードを読むことになる
という問題もあります
https://medium.com/bluecore-engineering/were-all-using-airflow-wrong-and-how-to-fix-it-a56f14cb0753
上記記事はこの問題に言及しており、全てをk8s operatorで記述しコンテナ化されたジョブから直にcliを叩くプラクティスを紹介しています
k8sでジョブを動かすのであればArgoでいいのでは感もしているのですが、記述の煩雑さと引き換えにcliをそのまま叩くので何が問題かは分かりやすくなりそうです
Argo
思想:汎用的、疎結合
用途:ジョブをk8s上で動かすよう汎用的に記述
k8sネイティブにジョブ管理を行うためのソフトウェアです
k8sでの汎用的な記述(kind: Workflowという独自定義)でワークフローを表現しています。そのためyamlの大きさが大きくなりますが、helmなどのyaml生成ツールの支援を受けることができます
本体のソースコードはgoで書かれています
リポジトリは下記ですが、機能ごとにリポジトリを分割し、疎結合な設計になっています。
https://github.com/argoproj
k8sネイティブに設計された結果、スケジューラがジョブから分離しておりargo-eventsという別リポジトリになっています
argo-eventsはいまだpre-releaseの段階で安定していません。hookなどのイベント発火とschedulerの発火を同じように扱え汎用性は高いのですが、スケジューラにbackfill(データの初期投入等の場合に過去のある日付から今日までのジョブを順番に起動する機能)が無いので使い勝手に欠ける感じです。イベントを順番に起動させるスクリプトを書けばいいのですが
UIに関してもかなりシンプルでスケジューラとは分離されています。すなわち実行されたそれぞれのタスクが個別に見れるだけで、スケジューラ単位でジョブをまとめて見れる機能はなさそうです
Digdag
思想:シンプル
用途:定期的(日次)に動かすデータパイプラインの記述に特化
treasure data社が作成したOSSでtreasure dataとのコネクタが充実しています
AirflowほどOperatorがたくさんあるわけではなく(品質も安定していて)、Argoほど疎結合な設計でなくデータパイプラインの実行基盤として使いやすくつくられています。逆にAirflowほどビジュアライズが優れているわけでもないです
本体のソースコードはjavaで書かれています
結局どれを使えばいいのか
どれも一長一短があって用途次第ではあるのですが、試してみるのであればAirflowから触ってみるので良いのではないでしょうか
| Airflow | Argo | Digdag | |
|---|---|---|---|
| UI | ◎ | △ | ○ |
| フルマネージド | ○ | X | X |
| データパイプラインとしての機能 | ○ | △ | ○ |
| コネクタの品質 | △ | なし | ○ |
| k8sとの親和性 | X | ○ | X |
移行事例
両方向の移行事例があってどっちがいいとは言い切れないです
Digdag→Airflow
https://user-first.ikyu.co.jp/entry/2018/06/25/115452
UIの使いやすさがアドバンテージでログが見やすい、依存関係が把握しやすい、処理ごとのボトルネックが可視化できる
Airflow→Digdag
https://medium.com/@scott_64558/in-praise-of-digag-an-alternative-to-airflow-258a0eef83bc
昔airflowを使っていたけどdigdagに移行した。airflowはoperatorがいっぱいあるけど、バグがあるし、digdagから専用のソフトウェア(ex. spark)を呼んだほうが楽だった