この記事の目的
- とりあえずBigQueryのコスト管理・監視を最低限やっておきたい時の備忘録
- 記事の内容をやっておけば 「BigQueryのコスト管理・監視やってます」 と言える・・・多分。
前提
- 下記の各種操作ができる権限をもっているかの確認はお忘れなく
- BigQuery
- CloudLogging (ログルーター)
- Lookerを使える環境があればベター
- ベターであるので、アウトプットができる代替手段あれば問題なし
やる事とはBigQueryのクエリログを、分析用のデータセットに流し込んで分析するだけです。
本当に「とりあえず」なので、正確なものを求められる場合は、当記事の内容を更に掘り下げて見てもらえれば良いかと思います。
分析用データセットをBigQueryに作る
- ログを流し込む用のデータセットを作ります
- とりあえずなので単一リージョンで。
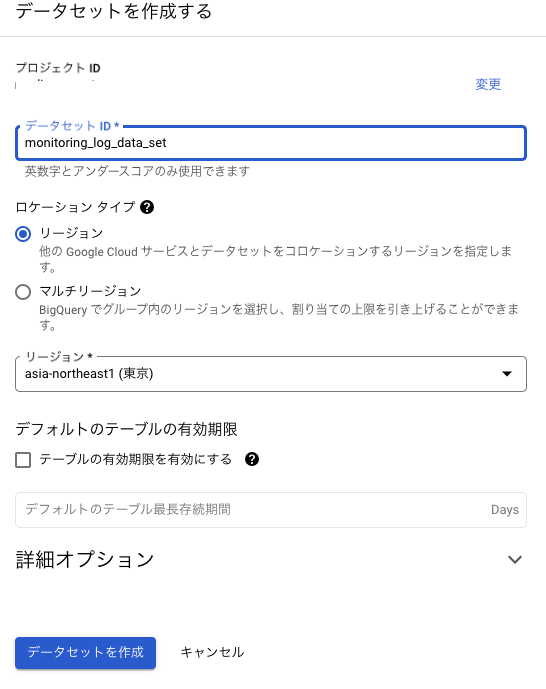
テーブルは自動で作られるので、今のところはここまで。
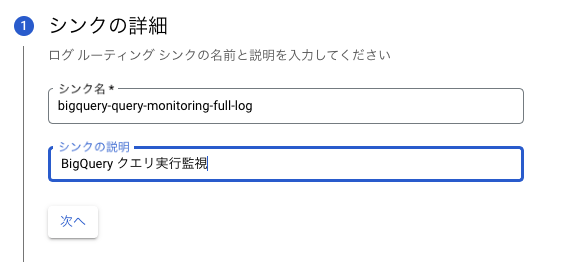
ログルーター
- CloudLoggingのBigQueryクエリログを、先ほどのテーブルセットに流し込む設定をします。
- シンク名と説明は適当に。
- シンクの宛先はBigQueryデータセットで、最初に作った分析用データセットを指定する。
-
「パーティション分割テーブルを使用」には必ずチェックをつけましょう!
- コスト管理の為のテーブルで、無駄にコストが発生しかねない本末転倒な事になります。

- コスト管理の為のテーブルで、無駄にコストが発生しかねない本末転倒な事になります。
-
「パーティション分割テーブルを使用」には必ずチェックをつけましょう!
- シンクに含めるログを設定します。
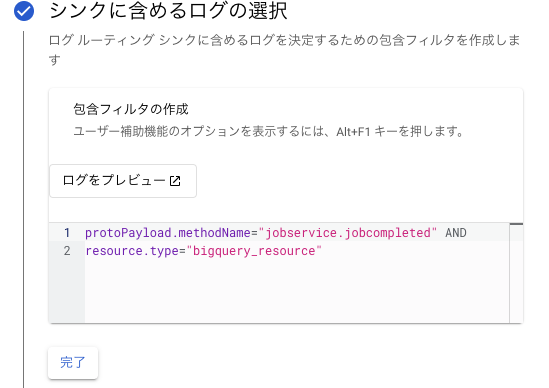
- フィルタは以下の設定なら、とりあえずは実行されているクエリ情報は集められます。
protoPayload.methodName="jobservice.jobcompleted" AND resource.type="bigquery_resource"- ログの量が多くなるので、1クエリあたりのデータ処理バイト数が大きいものに絞るのであれば「totalBilledBytes」のフィルタ条件を追加します。(下記は1GB以上のクエリ操作を対象とした場合)
- ただ1クエリあたりのバイト数が少なくても、発行数が多すぎてコストが膨らんでいるというパターンもありうるので、きちんと管理したいならバイト数でのフィルタリングは推奨しません。
protoPayload.methodName="jobservice.jobcompleted" AND resource.type="bigquery_resource" protoPayload.serviceData.jobCompletedEvent.job.jobStatistics.totalBilledBytes>="1073741824" - ログの量が多くなるので、1クエリあたりのデータ処理バイト数が大きいものに絞るのであれば「totalBilledBytes」のフィルタ条件を追加します。(下記は1GB以上のクエリ操作を対象とした場合)
- フィルタは以下の設定なら、とりあえずは実行されているクエリ情報は集められます。
ここまで設定したら、「シンクを作成」を実行
BigQueryのデータセット確認
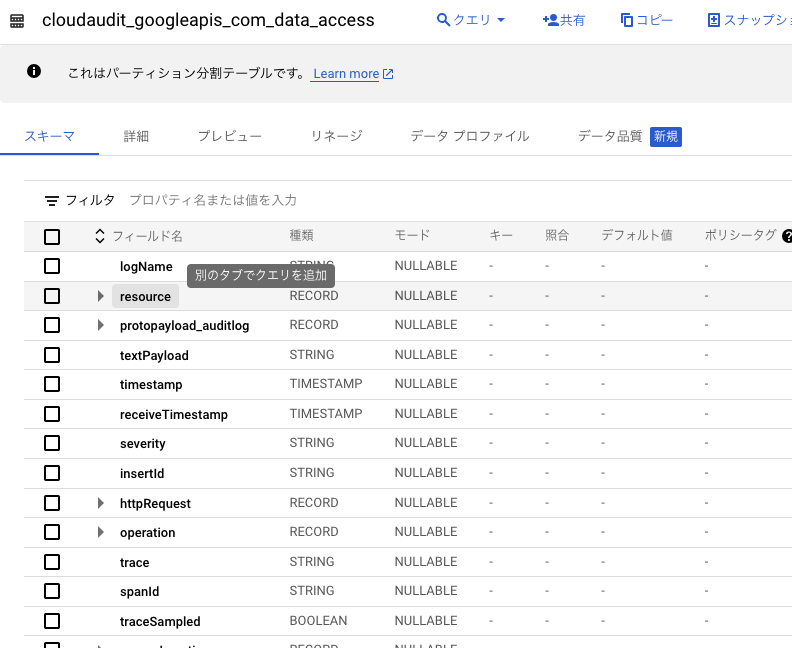
- ログルーターが正常に動いていれば、分析用データセットに「cloudaudit_googleapis_com_data_access」等テーブルが作成されています。

- テーブル構造は以下の通りですが、RECORD型のカラムもあり必要な情報だけを取得するのはなかなか面倒です。
データの確認
とりあえず重要そうな情報は、SELECTで以下の記述でカラム名を指定すればOKです。
| カラム | データ内容 |
|---|---|
| protopayload_auditlog.authenticationInfo.principalEmail | クエリを発行したユーザー(IAM) |
| protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobStatistics.totalBilledBytes | 課金対象データ処理バイト数 |
| protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobConfiguration.query.query | クエリ |
例
- データ処理バイト数はMB表記にするようにしています。
- WHERE句のtimestampによる絞り込み(パーティション適用)は忘れずに!
SELECT
timestamp,
protopayload_auditlog.authenticationInfo.principalEmail AS exe_user,
protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobConfiguration.query.query AS query,
ROUND(protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobStatistics.totalBilledBytes/1024/1024, 1) as billed_mb
FROM `xxxx.monitoring_log_data_set.cloudaudit_googleapis_com_data_access`
WHERE TIMESTAMP_TRUNC(timestamp, DAY) = TIMESTAMP("2023-12-24")

マテリアライズドビューの作成
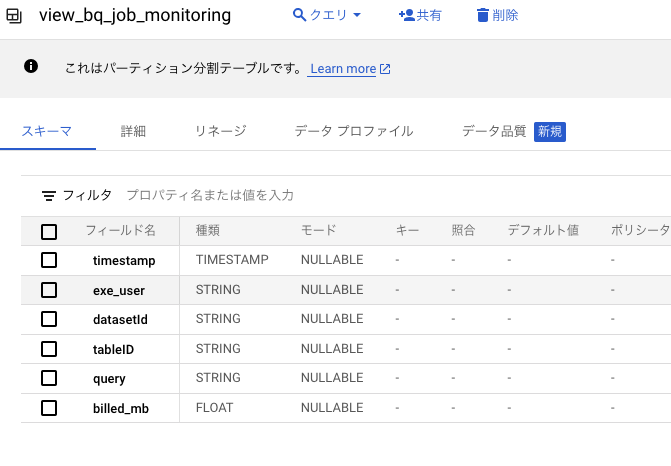
素のテーブルのままだと使い勝手が悪いので、必要な情報のみをピックアップしたビューを作成します。
- 前項の「クエリ発行ユーザー」「クエリ」「データ処理バイト数」に加え、「データセット名」と「テーブル名」を追加してビューにしています。
CREATE MATERIALIZED VIEW `xxx.monitoring_log_data_set.view_bq_job_monitoring`
PARTITION BY DATE(timestamp)
AS
SELECT
timestamp,
protopayload_auditlog.authenticationInfo.principalEmail AS exe_user,
e.datasetId as datasetId,
e.tableID as tableID,
protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobConfiguration.query.query AS query,
ROUND(protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobStatistics.totalBilledBytes/1024/1024, 1) as billed_mb
FROM `xxx.monitoring_log_data_set.cloudaudit_googleapis_com_data_access`, unnest(protopayload_auditlog.servicedata_v1_bigquery.jobCompletedEvent.job.jobStatistics.referencedTables) as e
- これをベースにしてコストを監視するイメージです。
クエリ例
- ユーザー別の処理データバイト数を把握する
SELECT exe_user, sum(billed_mb/1024) as billed_gb FROM `xxx.monitoring_log_data_set.view_bq_job_monitoring` WHERE TIMESTAMP_TRUNC(timestamp, DAY) = TIMESTAMP("2023-12-13") group by exe_user order by billed_gb DESC
- ユーザー x テーブル毎の処理データバイト数を把握する
SELECT exe_user,tableID, sum(billed_mb/1024) as billed_gb FROM `xxx.monitoring_log_data_set.view_bq_job_monitoring` WHERE TIMESTAMP_TRUNC(timestamp, DAY) = TIMESTAMP("2023-12-13") group by exe_user,tableID ORDER by billed_gb DESC
Looker Studioでのアプトプット例
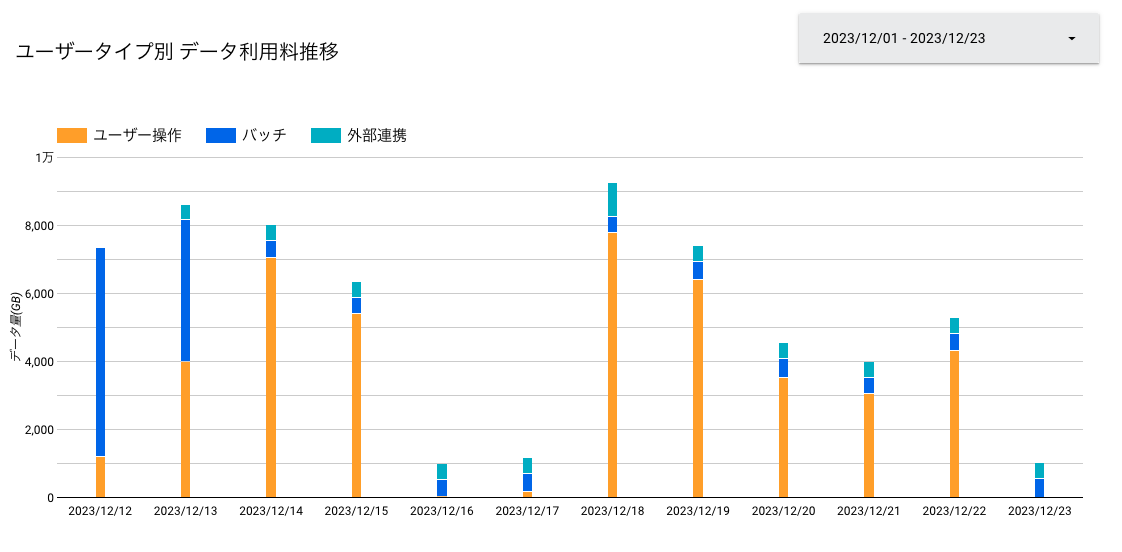
例1.クエリ発行元を分類で分けて、それぞれの比率を出す
- 日の課金対象となっている処理データバイト数の内訳を監視します
- この例は、12/13以前のバッチ処理が発行したクエリが過剰なバイト数を処理していたので調査し、12/14以降解消した時の推移です。(ユーザー操作によるデータ量が膨らんでますが・・・)
- 現在、何がBigQueryのコストに負担をかけているのかを一目で見ることができますね。
- 12/16-17は土日だったので、ユーザー操作はほぼ0なのもわかります。
- 12/16-17は土日だったので、ユーザー操作はほぼ0なのもわかります。
- 現在、何がBigQueryのコストに負担をかけているのかを一目で見ることができますね。
- この例は、12/13以前のバッチ処理が発行したクエリが過剰なバイト数を処理していたので調査し、12/14以降解消した時の推移です。(ユーザー操作によるデータ量が膨らんでますが・・・)
主な設定
- これは前項のビューを使っています
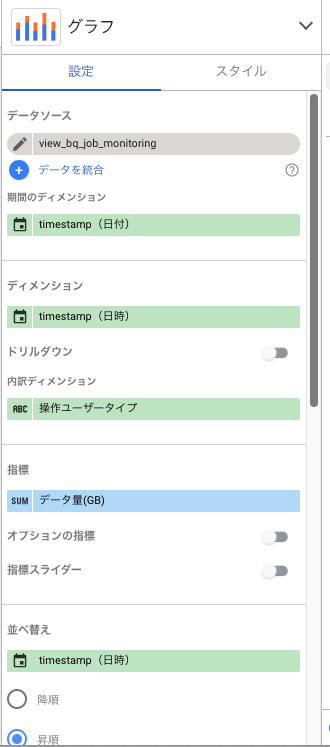
- 「フィールドを追加」 → 「グループ」追加で、クエリの発行元をグルーピングします
- 例の場合は、バッチと外部連携で個別のサービスアカウントを用意してBigQueryを使わせているのでこんな感じになります。
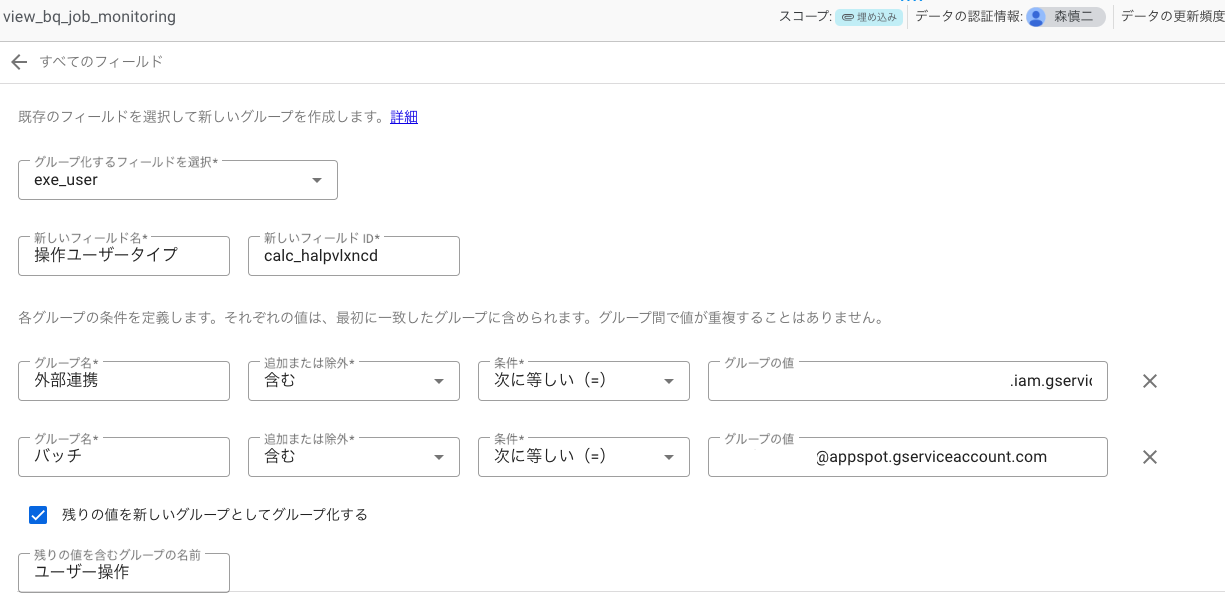
- 例の場合は、バッチと外部連携で個別のサービスアカウントを用意してBigQueryを使わせているのでこんな感じになります。
例2.1クエリで処理データバイト数が一定値以上のものを抽出する
マスキングしているので見た目悪いですが、
- 「誰が」
- 「どのテーブルに」
- 「どんなクエリを発行して」
- 「どれだけの課金データ量が発生した」
という情報をまとめています。
例だとテーブル名での絞り込みもできます。
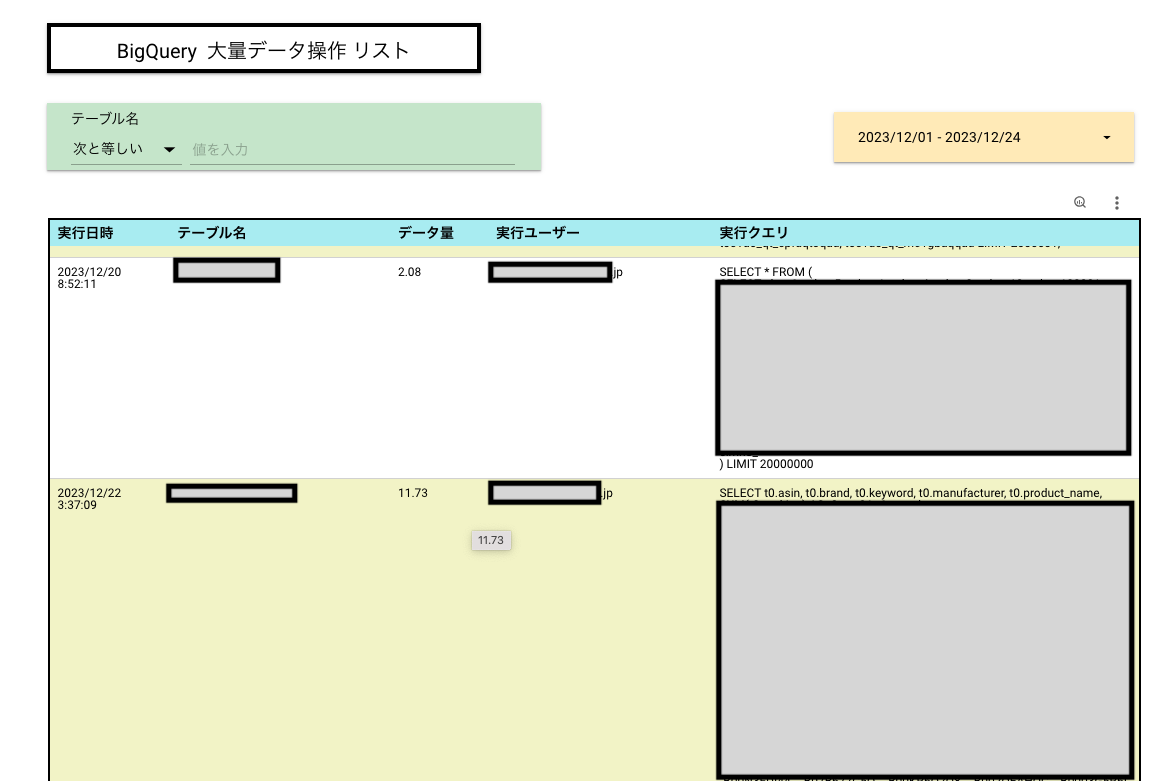
主な設定
- これも前項と同じビューを使っていますが、1GB以上を条件とするフィルタを追加しています。
※billed_gbという項目は、「計算フィールド」でbilled_mb項目をGB表記に変換した追加したものです


今回作成したビューをベースにすれば、例以外にも色々とやれる事はあるかと思います。
最後に
これで「気がついたらBigQueryのコストが訳もわからずコストが跳ね上がっていた」という事態は回避できるのではと。
とはいえ、まだやれる事はあるので、この記事の内容はあくまでコスト管理の第一歩です。
Monitoringで一定以上の処理データバイト数のクエリが走った時にslackに通知するアラートを作るとか、工数見合いで色々掘り下げて行ってもらえると幸いです。