もともと、顔を切り取るために頑張ってきたのに、着ている物を分類し始めて夢中になってしまった。
もう顔の切り取りはどうでもよくなってきた
(´,,・ω・,,`)
mAPってどんくらいなの?と知りたい人は、最後のほうを読んで。
過去にやってみた物体認識の記事
https://qiita.com/mokoenator/items/4d106d682f1b4bc7d0e3
https://qiita.com/mokoenator/items/3268ec162658efe82fb6
物体認識の教師データ作成は2018年7月から初めて、3か月になる。
会社員なので一日平均3時間睡眠、徹夜作業などを繰り返して頑張っている。
正直しんどいのでやめたいけど、自分で作った物が(といっても人のモデルですけど)ゴリゴリに人間をはるかに超えるスピードでやってのける快感はやばい。
機械学習はやってみないと面白さがわからない。
2019/07/09追記
この記事に書いたことを使ってファッション検索サービスファンネルを作りました。ファンネルではmAP80%を超えました![]() 。
。
YOLOを試してみる
物体認識でためしたものは
https://github.com/pierluigiferrari/ssd_keras
と
https://github.com/qqwweee/keras-yolo3
でやってみた。
複数枚GPUで動かない。
最終的に
https://github.com/AlexeyAB/darknet
で頑張ることにした。
教師データ作成が鬼畜でVoTTがとても貧弱
VoTTはここ
https://github.com/Microsoft/VoTT
アノテーションを作る作業が鬼畜作業。
VoTTがたぶん一番早くアノテーションが書けると思うが、とても貧弱。
JSON編集、ビューアツール、チェックツールを作らないと時間ばかり過ぎてしまう。
VoTTだけではアノテーションの検証ができないのは結構痛い。
結果が変だな?っと思ったらアノテーションがうまくいってないことが多い。
無料だから、足りないところは自作して補ってしまおう。
ちなみにVoTTのフォーマットをyoloに変換するのが超めんどくさいので
自作したほうがいいです。
2019/09/24追加:VoTT(version1系)のJSON順番がファイル名のソート順なんですが、癖があってASCII順かとおもったら
大文字小文字区別なしアルファベット順で記号(少なくともアンダースコア)はアルファベットより順序が後ろでした。
PYTHONで合わせるのはかなり苦労したのでハッシュコードとかでファイル名を統一しないと痛い目を見ます。
コツ
ミスなく教師データを作ることです。
細かな設定の仕方とかはAlexeyAB/darknetのREADME.mdにコツは書いてある。
めんどくさがらずに全部読もう。
読まなくても、サイクル回すと気が付くけど・・・無駄に時間が過ぎてしまう。
複数GPUをうまく利用するために
手元に用意した環境
ASUS Z270 EXTREME4
CPU i5 7500
メモリ 24G
GPU GTX-1070ti*3(玄人志向とPalit)
PCの写真

(緑に光るPalitが2枚と、外に出ている玄人志向が1枚)
こんな状態で学習開始したところ・・・
PCIEx1をライザーカードというもので延長したもんだから、2台で学習するより遅くなってしまった。
なんでこんな状態かというと、マザボの構造上刺さりません。
買っちゃったGPUが「Palit GeForce GTX1070Ti Super JetStream 」なもんで3スロットも占有してしまう。
だからどんなマザボを買ってもGPU4枚刺しとかできないんですよね・・たぶん・・・。
で・・
PCIEx16の延長ケーブルを買ってみました。

これならマザーボードのx16形状のスロットに刺さります。
CPUZで見てみたら、どうやらx16で動いてなさそう
x8,x8,x4で動いとる・・。
i5-7500の「PCI Express 構成」っぽい。つまり、安いCPU買うからや。(´・ω・`)
マザボもダメなのかなぁ。
GPUをうまく使うためにcfgをどうしたら最速で学習できるのか?
subdivisionsの値がGPUに影響しそうな値なので変化させて計測しました。
画像数5000枚くらいで100バッチ回した時間(秒)です。
PはPalit
玄は玄人志向
subはcfgのsubdivisionsの値です。(batch=64は変えないほうがいいっぽい)
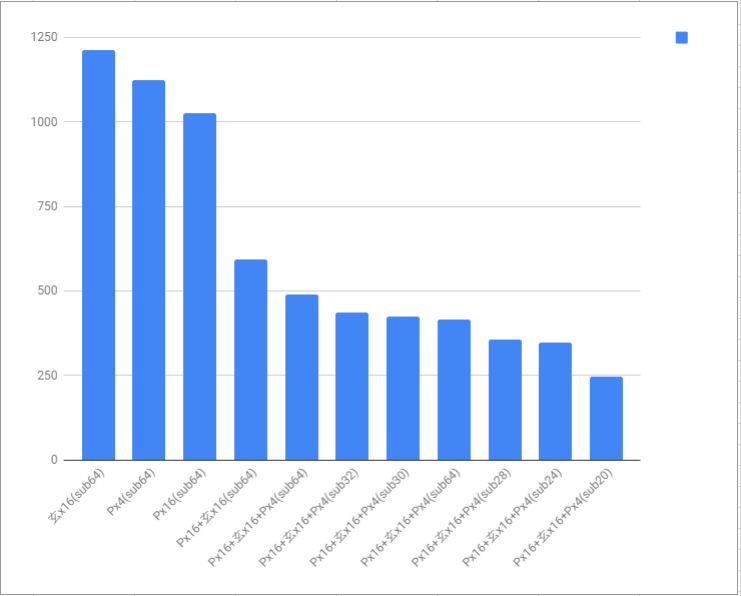
(それぞれ一回だけの計測なので・・・あまりあてになりません)
結果をもとに長時間学習をしてみたら・・
CUDA Error(failure?)がでて止まってしまい、何度か再実行するがやっぱり止まる。
他に、CUDA Error Out Of memory、カーネル実行タイムアウト・・・エラーまつりや。
failure系のエラーはたぶんPCIEx16の延長ケーブルが原因だと思っている。
カーネル実行タイムアウト対策として
HKEY_LOCAL_MACHINE/SYSTEM/CurrentControlSet/Control/GraphicsDrivers
HKEY_LOCAL_MACHINE/SYSTEM/CurrentControlSet/Control/GraphicsDrivers/DCI
の二つに
TdrLevel(REG_DWORD)に3(回復する)
TdrDdiDelay(REG_DWORD)30(秒)
TdrDelay(REG_DWORD)30(秒)
をセットして再起動
あとドライバがCUDAのインストーラで入れたものじゃないので再度CUDAを入れる。
それでも45000バッチ実行するとCUDA Error Out Of memoryが出てしまう。
20000バッチくらいで出ちゃうんだよなぁ。
HOSTメモリが24Gしかないから??
ユニファイドメモリでガンガン転送してたら、HOSTも食うの??
それでCUDA Error Out Of memory?なのか?
YOLOのメモリっってGPU<>HOSTで同じデータを保持しにかかってるんかな?
時間があったらユニファイドメモリかどうかソースを確認してみよう。
え?そうなん?1
README.mdのHow to train with multi-GPU:ブロックに書かれている
Then stop and by using partially-trained model /backup/yolov3-voc_1000.weights run training with multigpu (up to 4 GPUs): darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg /backup/yolov3-voc_1000.weights -gpus 0,1,2,3
の意味が分からなかった・・・・最初の1000回はシングルGPUで学習して、そのあとで複数枚で頑張れって意味らしい。
詳しくはココ
https://groups.google.com/forum/#!msg/darknet/NbJqonJBTSY/Te5PfIpuCAAJ
でもうちの環境だと変わらないので、最初からフルパワーです。
→2018/11/19追記 うそでした。1000回かどうかは物によります。loss が5以下になってから変えたほうがいいかも。
実験中!(^^)!
→2019/09/19追記 最終的にTITAN RTXを買ってしまったので実行を途中で止めることもなく楽に学習してます。
え?そうなん?2
README.mdのHow to improve object detection:ブロックに書かれている
detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416
これで再計算、cfgに設定しろってことらしい。
画像を追加したら毎回変更したほうがよさそう。地味にめんどくさい。
サイズを606にして学習した場合はどうなんだろうか?
そもそもcfgのwidth 、height は学習に関係しているのか??README.mdには「関係してる」と解釈できることが書いてあるしなぁ・・・
-width 416 -height 416>>ここはかえなくていいのか不明だ。
→2019/09/19追記 変えたほうがいい。しかし・・そもそもanchorを再計算しても精度の変化を体験できないのでanchors自体を変えてない。ただし一般的な物体を認識しようとしているので細長い棒とかをガンガン学習するならダメっぽい。
mAPだしてみた。
45000バッチ実行しました。
時間は55時間かかりました。
lossグラフ
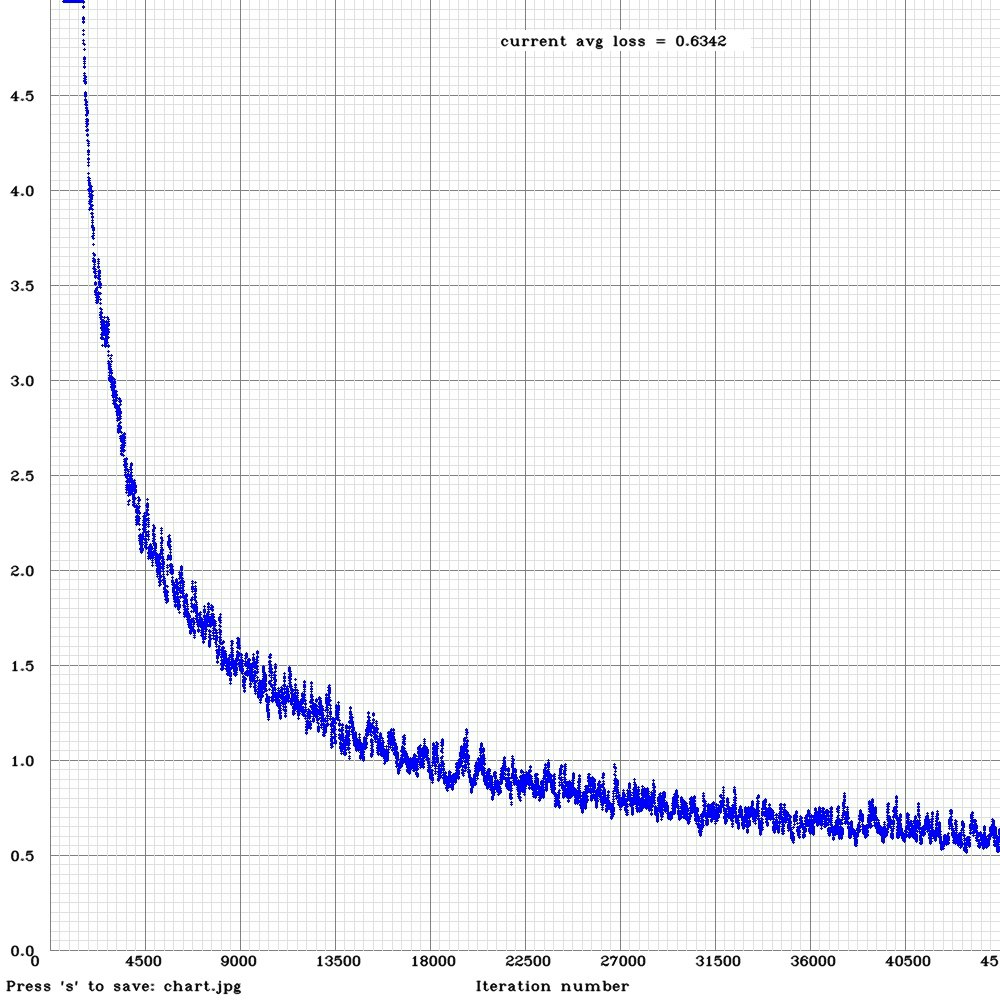
あんまり精度でてない。
ここからmAPです。
CLASSネームの右の数字は準備した教師オブジェクト数
(beauty-man,beauty-womanは整ってる顔をしたclassです)
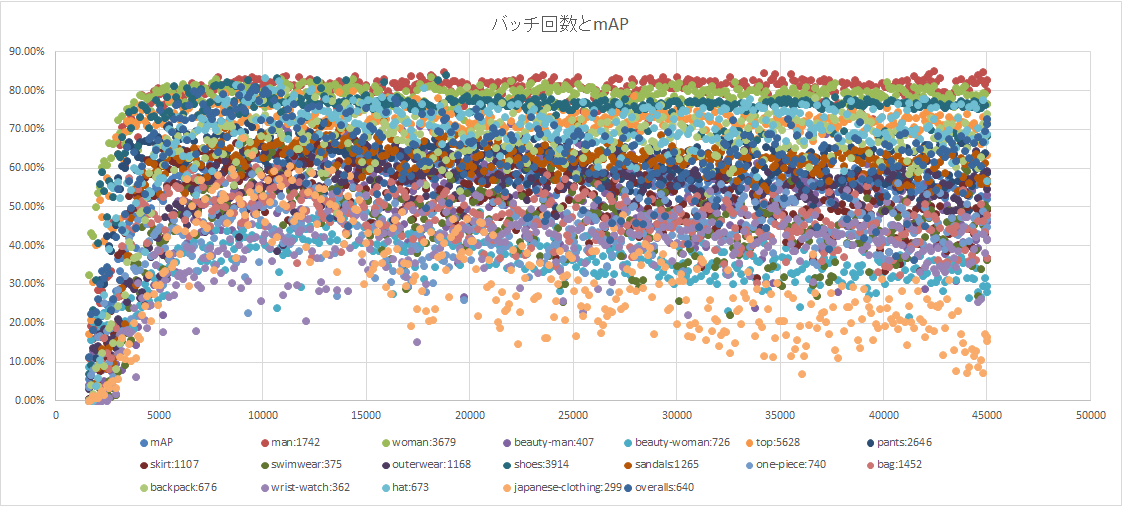
これを見る限りlossグラフ意味ないやん・・・
下のグラフは個別に出したグラフ
1枚目
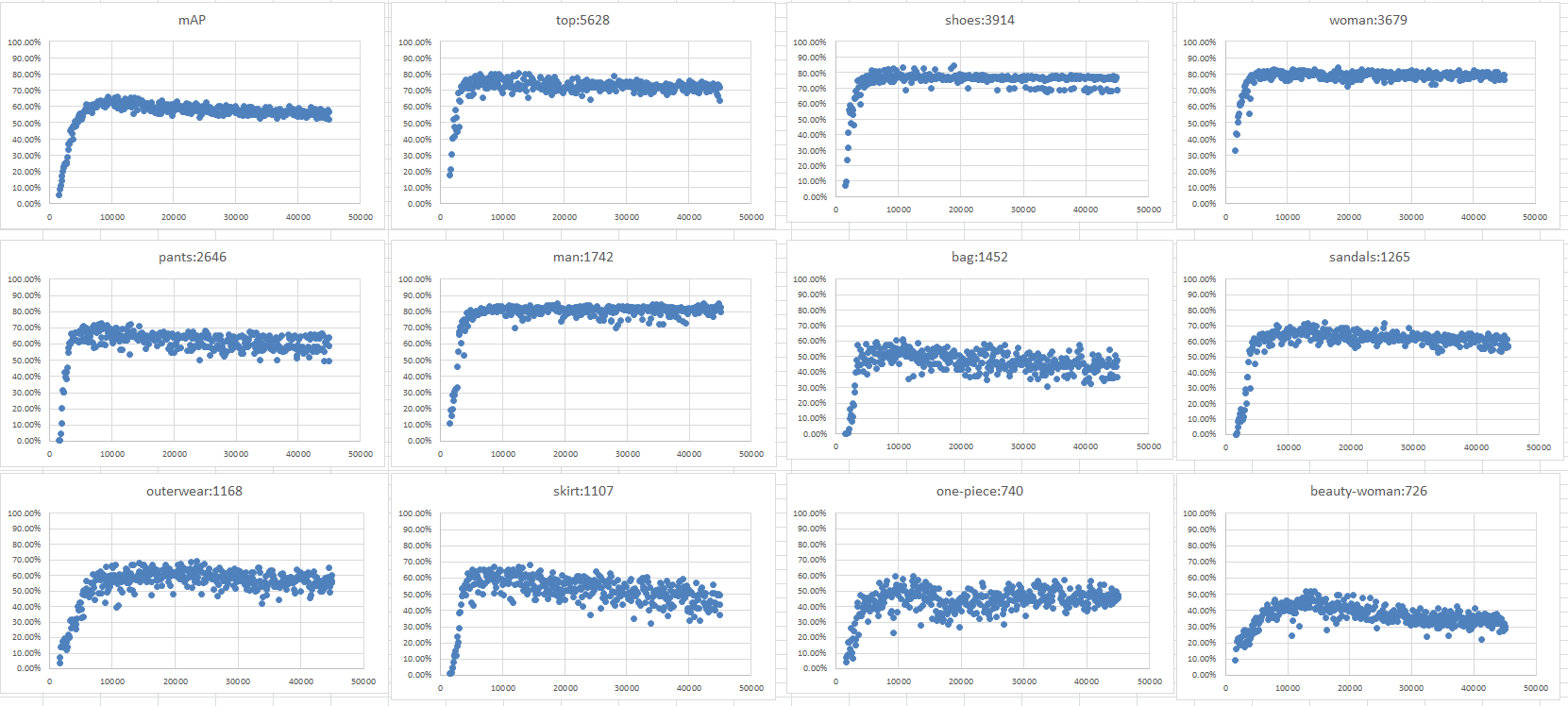
2枚目
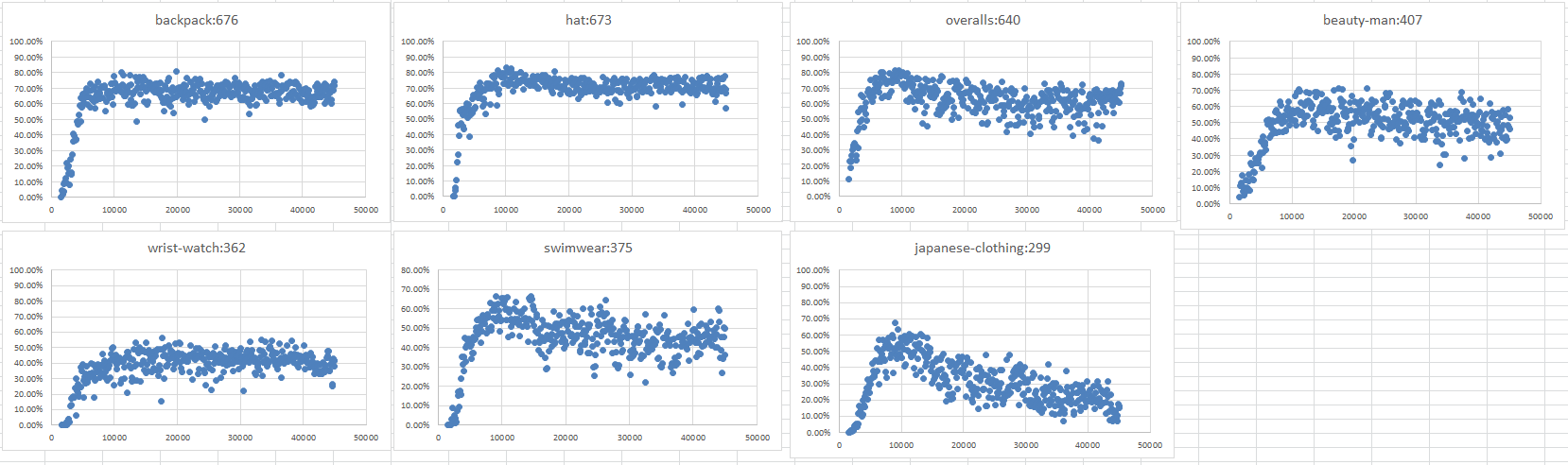
お・・・・
mAP単体だけでみると9000前後でピークがでてあとは効果なし。
9000回で学習がピークならsubdivisionsも少なくできそうだ。(回数とエラーに相関があるかわからない)
教師オブジェクト数とCLASSの性質?に一定の関係があるっぽい。
たぶん柔らかい、固いが関係してそう。
教師オブジェクト数が少ない物は絶望的。
このグラフでlossが下がらない原因らしい物がわかったし!
どんな画像が必要なのかが分かるのでこれで頑張れる!
当面は和服と水着だ!
そうだ、京都行こう!
(´,,・ω・,,`)