とりあえず使ってみて!
服が写った画像を投げると商品を検索できる「画像でファッション検索サービス」です。
Fashiontechってやつですかね?
回遊率UP、滞在時間UP、コンバージョン率UPを期待できる仕組みです。
今のところ検索エンジンサイト、ポータルサイトとして利用できます。
将来的にセラーサイト内部で使ってもらえるように仕組み化していきます。![]()
![]()

※開発中の画面です
物体認識して、画像の類似度を算出して、検索する。ただそれだけです。
ファッションサーチ funnel
「ファッションサーチ」でGoogle検索すると一番上にでてくるよ

ここまでくるのに約1年かかりました。
つらい、くるしい、睡魔に耐え続ける日々を乗り越えて作りました・・・![]()
サラリーマンですので、休日か睡眠時間をあてるしかありません。![]()
表側は依頼して作ってもらいました。![]()
https://qiita.com/yagi8888
yagiさんありがとう。
現段階では大人数がアクセスすることを想定して作ってないので、表示に時間がかかるかも。
簡単な説明
服の写真を投げると商品を検索できます。
インフルエンサーの写真などで検索してみましょう。
さらに商品から商品を検索できます。
ほしい商品が見つかったら画像をクリックしてショップに行き買いましょう。
イラストや絵を入れても検索できます。
物によっては不思議な商品を返してくることもあります。(精度UP努力中)
ファッションサーチ funnel
とりあえず使えばなんとなくわかります。
精度とか仕組みとか
※開発中の画面です
左の画像を入力(クエリ画像)すると、右の結果がでてきます。
クエリ画像は物体認識にかけられて服だけが切り取られ、特徴量を算出します。
(開発中の画面なので箱を描画してます)
切り取った画像とセラーデータベースをみんな大好きコサイン類似で計算してスコアが高い順にならべます。

※開発中の画面です
私の靴で検索してみました。
それっぽいものが出てきているので良好です。
概要図
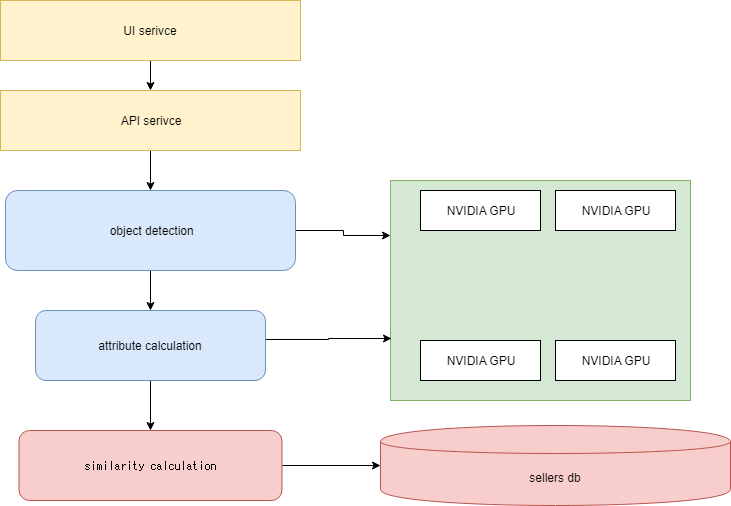
この構成は、お金が燃えるんだよ!!![]()

![]()
![]()
![]()
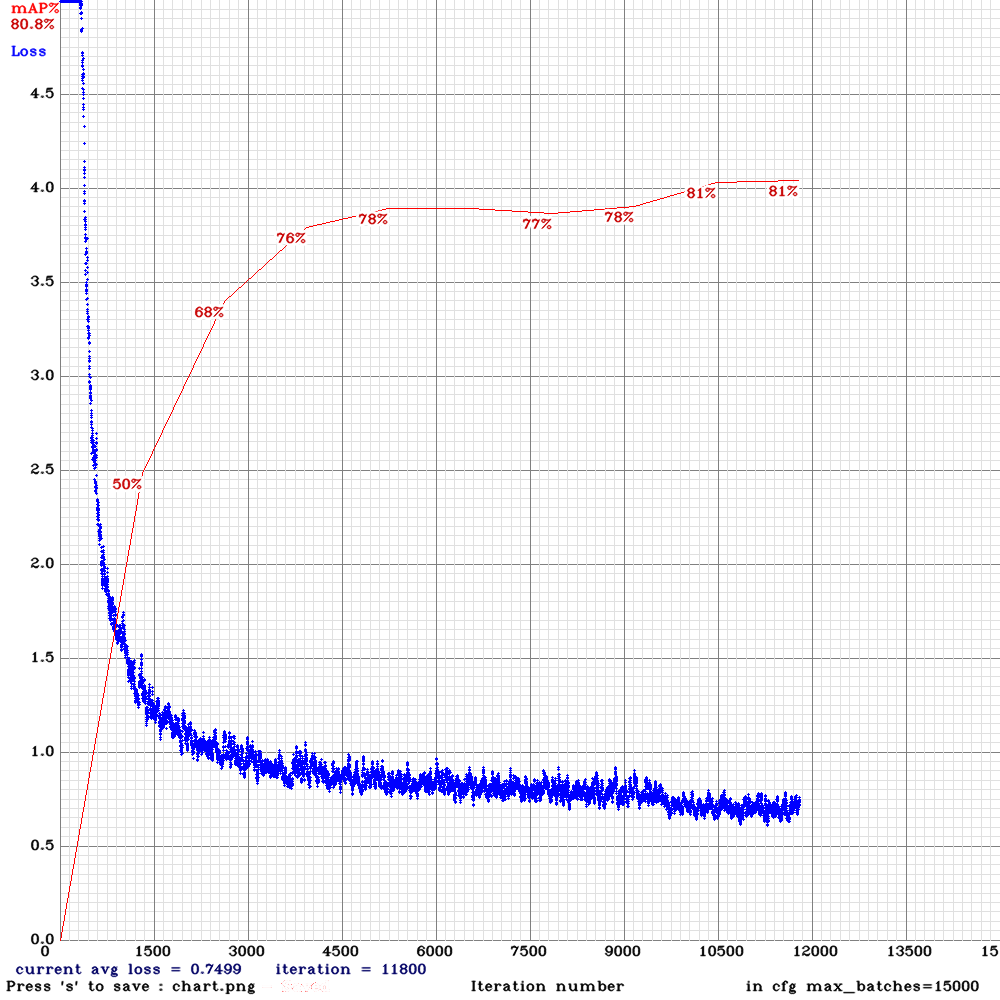
物体認識(YOLOだよ)はmAP(50)80%を超える

※開発中の画面です
https://github.com/AlexeyAB/darknet
をベースに細かいところを自分に合わせて修正して使ってます。
画像数約14,000枚、CLASS数16のアノテーションを12カ月間一人で作りました。
気が狂いそうになる作業を毎日繰り返し・・・![]()
mAP(50)は80%を超えるモデルが出来上がりました。
個人的には驚異的な数字だと思ってます。
自作のモデルは男女顔検出+整っているかどうか?(主観)も判定します。
openCVの顔検出だとイライラしますが、自作モデルは顔が斜めだろうが、逆さだろうがなんでもござれです。
マスクしてても、サングラスしててもある程度検出します。
YOLO V3のコツはhttps://github.com/AlexeyAB/darknet
に書いてあることを忠実に試してみることです。
Issuesも可能な限り読みました。
標準のデータ拡張では回転してくれないのでオフラインで拡張します。
オンライン実装ではコーディングを完成させるだけで2カ月くらいかかりそうだと思ったのでやめました。
Issuesでは「意味がないからやらないよ」って書いてあったがファッションでは確実にmAPは上がります。
ただし回転させると、良くないBOXが教師データとしてできる。45度で最悪なBOXができるのでよく考える必要がある。
※
cfgにangle の項目はあるけどこの設定はYOLOには意味がない。ソースコードを見る限りYOLOのデータ拡張に渡していないし、YOLOのデータ拡張関数に回転しているコードがない。
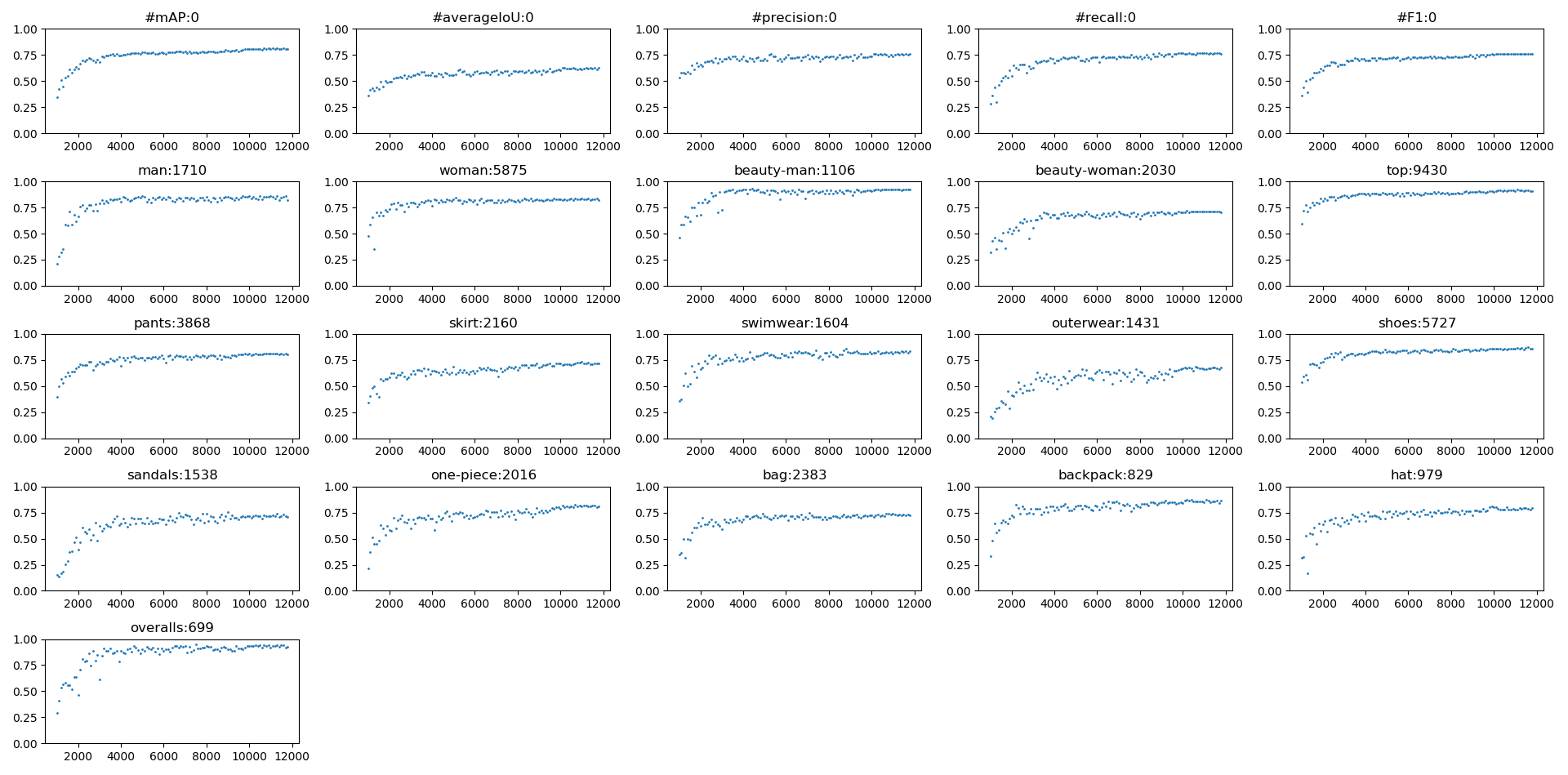
グラフタイトルの数字はオブジェクト数ですが、めんどくさくてカウントしなくなったので昔の値です。(だいぶ近いとは思います)
特徴量の算出
KERASでサクッと使える学習済みのVGG16、InceptionV3などの特徴量ではだめで、どうしても良い感じの距離がでない。
同じCNNに距離が近い画像を2枚読み込んで・・・距離を近くなるように損失関数をゴニョゴニョすれば?と思いついたので、
GOOGLE先生でしらべてみたら・・・3枚読み込んで学習するtriplet lossを発見しました。
世界はすごい。![]()
どんぴしゃな情報を発見
https://arxiv.org/abs/1404.4661#
ここで浅いCNNを平行で使うんやで![]() ・・・って書いあるんです。(PDFのリンク)
・・・って書いあるんです。(PDFのリンク)
そして鬼畜作業
データ集め、整理をコツコツ一人で4カ月間・・・![]()
![]()
![]()
YOLOと違って箱を書く必要はありませんので楽です。
あまり精度がでなかったので
ハンドメイドで・・3枚の画像の組み合わせをコツコツ一人で作って・・・・![]()
![]()
![]()
(ハンドメイド3枚組み合わせ画像を作るのは意味がなかったです)
精度がよくならないし・・・本当につらみしかない![]()
![]()
![]()
まったく違うクラスが高いスコアで出てこないようにするのが大変でした。
「え!これ?」ってのがまだ出てくるんですが・・・今後の課題
もっと楽な方法?にArcFaceというのがあるんですが、これはちょっと用途てきに違うかもしれんのでパス。
機会があれば試したいです。
画像検索ようのDBMSを自作(距離を算出するお仕事)
画像検索RDBMS的な物は世の中にないので(あるにはあるけど・・・)、自作します。
オブジェクト同士の距離を計算することでこのサービスは成り立っているので、どれだけ高速化するかが今後の課題でもあります。
平均的な全身写真で6オブジェクトあり、これを30000枚の画像を対象に計算するのに100msecかかります。
画像を増やしても時間はリニアに増えないです。
CPU使用率は10%前後です。80%まで使えるとして1秒あたり8接続はいける・・・
メモリは30000枚の特徴量を読み込んでもたったの5.4Gしか食いません。
セラーデータベース作成にも機械学習
セラーの商品を検索できるようにするためには、データを作る必要があります。
そのためには画像を収集して登録します。でも・・単純に画像を収集しても、なんのやくにもたちません。
たとえば・・
-
複数の画像を一つの商品として取り扱う。
-
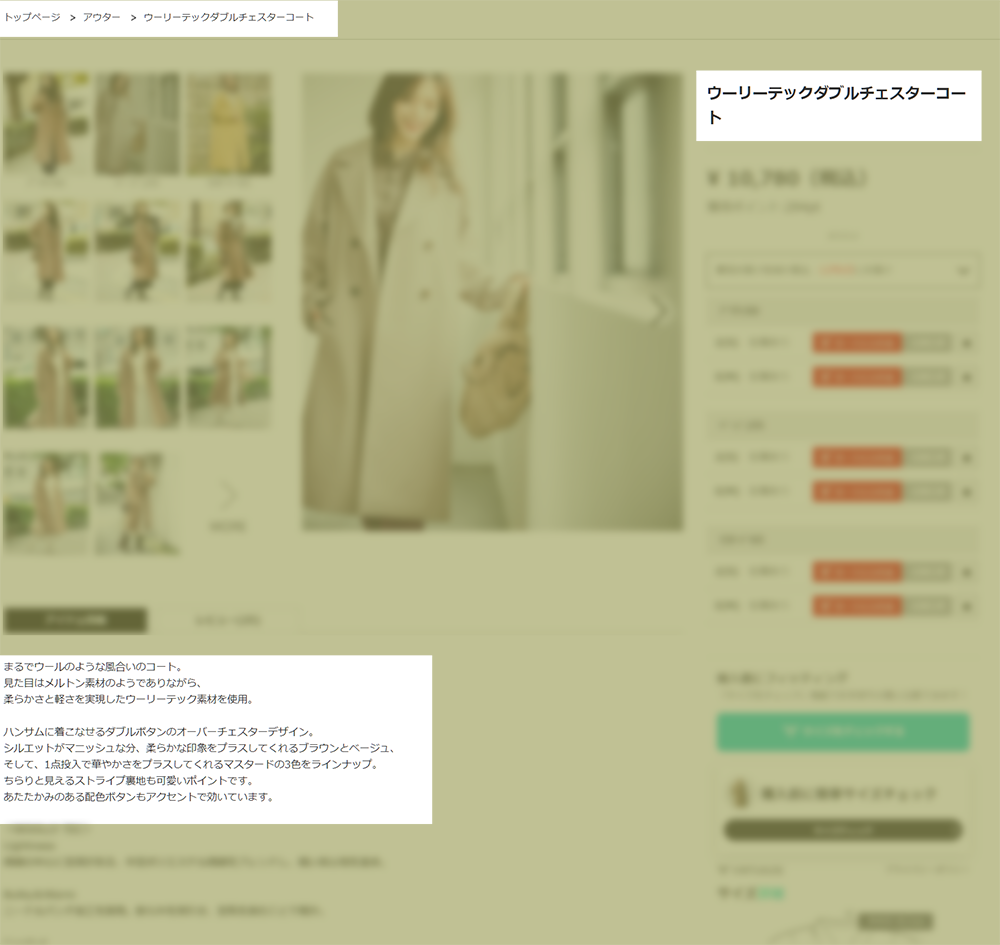
その商品が何を売っているのか??ワンピース、ブラウス?
商品ページ↓からボカシがかかっていない部分の文章から何を売っているのか判別する。
-
商品は男性向け?女性向け?
-
このサービスにふさわしくない画像(サイズ表、テクスチャ、部分アップ)を排除してアピールしたい画像だけを登録。以下のような画像は不要。

-
1枚の画像にはファッションの要素がたくさん詰まっているので、「売りたい服」を切り出す必要があります。
-
過去に登録した商品と被ってないか?同じセラーで被っていたら重複しないようにします。
これを大量に行うには人が必要ですが、機械学習で自動化できます。![]()
でも・・・ものすごく大変です。
けっこうモリダクサンです。
寝不足で死んじゃいそうです。![]()
![]()
![]()
セラーデータベースediter
画像以外の商品情報のediter
サクサク変更できるようにDBのGUIもちゃっちゃと作ります
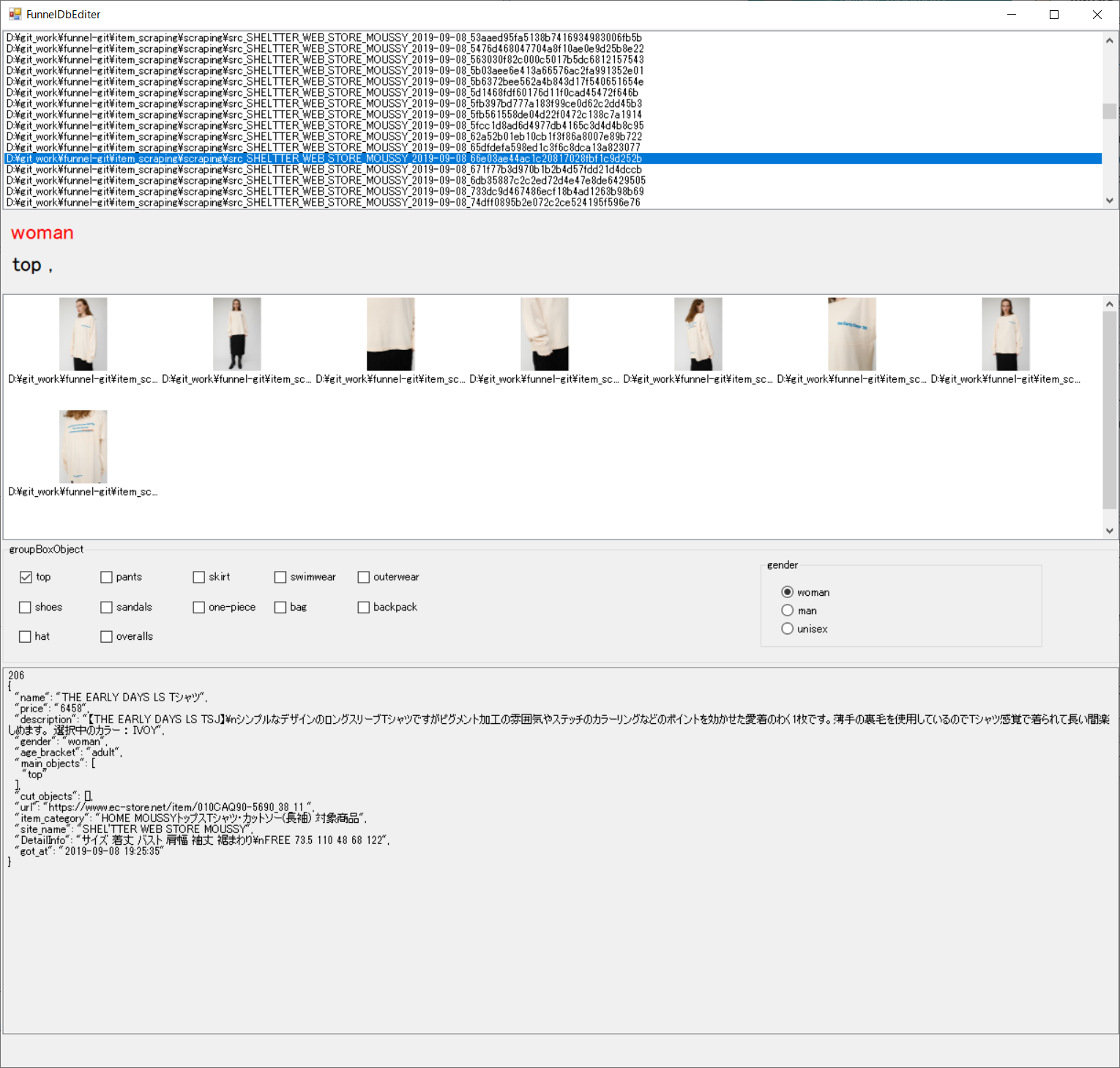
自分しか使わないので超適当。
今後の展開
- セラー数、商品数の向上
- 物体認識と類似スコア精度の向上
- バックエンドはAPIでできているので、本物のセラーサイト(ショップ)に利用できるような仕組みづくり
- 顔認証、顔識別のモデルを作ってモデルさんの顔検索やモデルさん軸に回遊できるようにする
- 自動化率の向上をおこないメンテフリーでこのサイトを成長させる
感想
ファッションに全く関心ないおっさんがやってみた感想です。
製作中はつらみ![]() しかなかったが、色々不思議な体験ができました。
しかなかったが、色々不思議な体験ができました。
たとえば・・・
同じ商品がZOZOとSHOPLISTに存在して価格が大きく違う。
価格の変化が早い。
同じ柄なんだけどTシャツとパーカーがある。
商品名が無い(あるんだけど説明やカテゴリに近い)
多色はわかりにくい。赤、赤いピンク、ピンク、薄いピンク・・・![]()
境がない。サロペットはワンピースなのかオーバーオールなのか?下着じゃんって水着と、水着じゃんって下着。
業界的?既存の言葉を新しい語で言いまわす習慣が根付いている。
ブランドがたくさんある
メンズは・・・画像検索する必要ないと思うくらい種類?表現が少ない。
服を売ってるセラーとライフスタイルを売っているセラーがいる。
そして・・・
技術的に思いついたことを検索すると、論文がでてくるGoogleってすごい。
出典
セラー画像はSHOPLIST、ZOZO、
クエリ画像は「ぱくたそ」
2020/03/22 追記 9カ月ほど運用してきてイロイロ分かったこと
9カ月ほど運用してきてイロイロ分かったことがある。
・文章カテゴライズ
商品の自動分類に文章カテゴライズを使っている。
文章カテゴライズ精度が向上しなくて、最初の7,8カ月は苦しかった。
教師データが少ない(体感的に2000くらい)場合はBatchSizeは少ないほうが精度が高くなり(8が一番良かった)、
教師データが多く(体感的に10000くらい)なるとBatchSizeを多くした方がよかった(64が一番よかった)。
クロールした生データをみて判別するような作業ではとんでもなく時間がかかる。
上のEditerを使いやすくして速度向上をした。↓
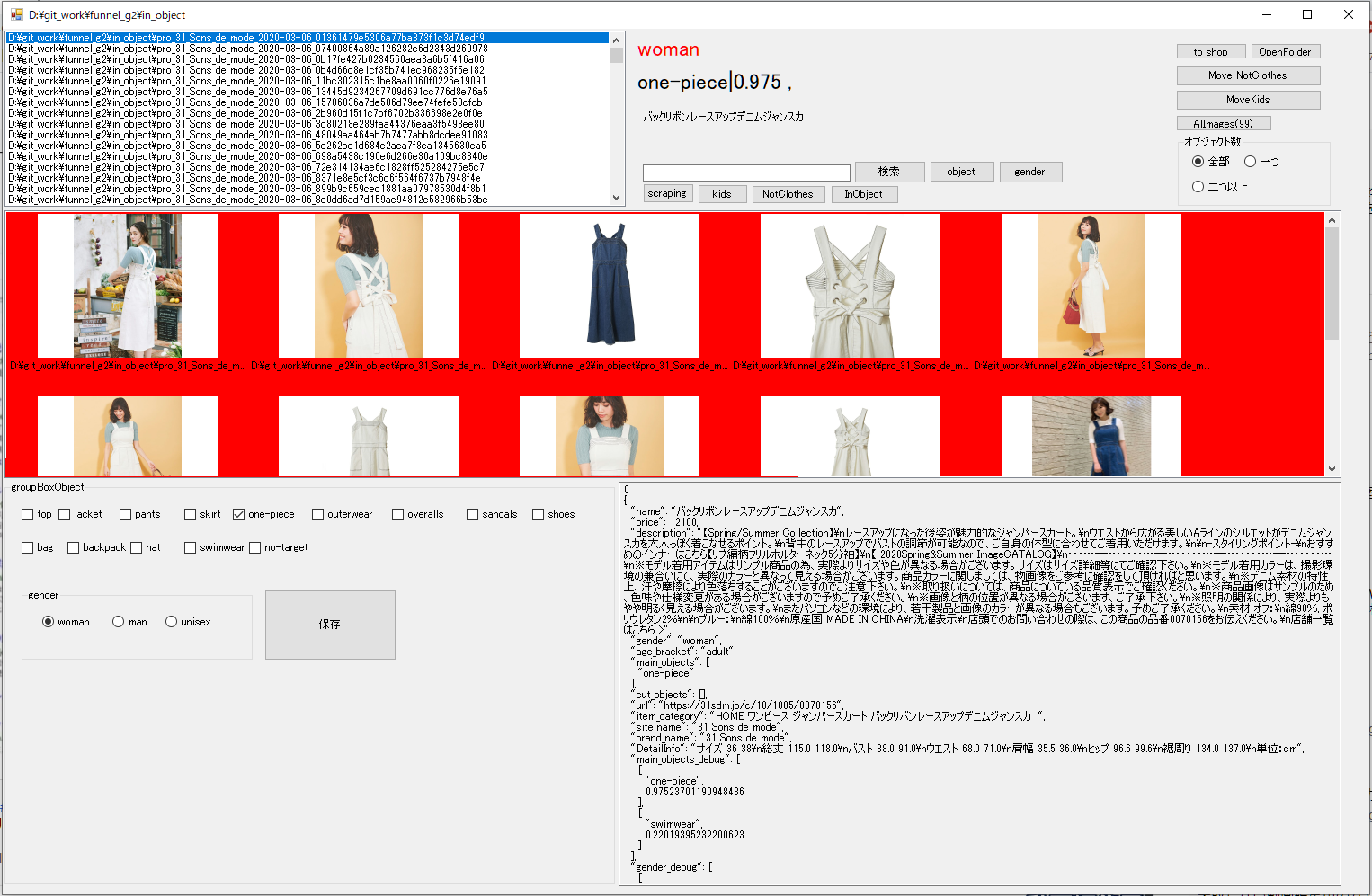
しばらくは教師データ=運用データなので、結構きれい目にデータを手当てする必要がある。(よくも悪くも・・)
・必要画像、不要画像の分類
コツコツ15万枚程度の教師データを作り・・・満足いくモデルができた。
15万枚をあいてにするにはコツがいる。![]()
とにかく自動化!![]()
ツールを作って人間の負荷をへらす。![]()
脳みそを有効活用するために、同時に一つ以上の作業をしない。![]()
(してもいいけど教師データにミスが発生しやすくなる)
学習時は過剰にデータ拡張しないほうがよかった。
取り扱う問題にクローズアップ排除があるので、切り取りするようなデータ拡張はしないようにする。
ベースモデルはInceptionV3を使っている。
・2重登録チェック
クロール時には原稿とURLをチェックして取り込む必要があるか?をチェックしているが、
原稿やURLチェックでは抜けてしまう。
画像は同じか少し足している場合もあるので、画像がどのくらい重複しているかを計算する。
全く同じ画像だから消そう!!と思っても、1枚にスカートとジャケットがある場合は2商品に使われている可能性がまぁまぁ高い。
なので、画像がどのくらい重複しているかを計算して取り込まないようにする。
そのために、O(n^2)の計算量がかかるので、すごくメンドクサイ。
InceptionV3の全結合層の特徴量をannoyに入れて検索しているから早いはずだが・・・遅い。。。。
annoyインデックスをつくるのにすごく時間がかかる。
差分更新しているけど、JSONで特徴量保存していたのでこれが失敗。
最初からhdf5で管理すればよかった。
・運用してみた感想
運用といってもSEOしたり、デザインに注力したりなどはしていない。
ひたすら、商品を取り込むスピードを上げるノウハウを構築しただけ。
ファッション用語に苦戦しながらこれはなんやろ?と繰り返す毎日。
Elasticsearch用のファッション用語シノニムを集めたりしていた。
SSLやらドメインが結構めんどくさかった
「 お名前.コム」はやめとけと言いたい。
ドメインなんてどこも一緒やろ~~![]() と思わないで!
と思わないで!
・今後
・クローラーからFunnelインデックスに乗せるまでを自動化する
・画像の特徴量を出すtriplet lossモデルの精度UPはほぼやってないので今後はtriplet lossの教師データをガンガン作る
・顔検索できるようにしたい
・Funnelの使い勝手、検索のさせ方をもっと向上させたい
・デザイン、SEOを頑張ろうかな
2020/05/10 追記
出典:ぱくたそ
YOLO V4へ
YOLO V4を使ってみた記事はこちら
https://qiita.com/mokoenator/items/84b519dcb38c70c518e7
物体を正しく検出する精度がとても上がったので体感的にもきもちいい。![]()
これなら、検索投入時に一番大きい物体で検出したクラスで検索しても良いくらいになった。
精度UPの理由はYOLO V4にしたからではなく、教師データを丁寧に修正した事が大きいと思っている。
教師データ作成のコツはひたすら見直すこと。
ウォーリーを探せバリに隠れているので探し出してアノテーションを付ける。
アノテーションのつけ間違えも絶対に見逃してはならない![]()
例

カメラを認識させたいカスタムモデルを作る場合、女性が持っているカメラだけにマークすると良くないデータになる。
マークしないということは、それはカメラではないことを同時に学習させていることになる。

左にひっそりと置いてあるカメラもマークしてあげよう。
triplet loss
triplet lossの教師データをひたすら修正した。
最初の教師データは無修正で適当に放り込んでた
例1

この2枚の画像は同じ洋服を着ていて背景が違う。人物と撮影カメラが異なれば100点の素材なんだけど・・・
この教師データでもそこそこ学習してくれるんだけど・・・
さらに賢くなるために修正↓↓↓↓

例2

トップスが同じなだけであとはダメダメ。
背景が同じ、左の写真は人物が二人、人物が同じで何一ついいところがない。
これではチェックっぽいおじいちゃんと、女性のトップスを同じだよと教えていることになりそう。
それでも何とか利用したい。
さらに賢くなるために修正↓↓↓↓

こんな感じで・・・「YOLOに選んでほしいなぁ」を基準にガンガントリミングする。
(実際の運用ではYOLO切り取り→triplet lossで計算なのでYOLO基準が正しい)
YOLOにやってもらおうかと思ったけど、90点台のトリミングになってしまうので手でやりました。![]()
結果
検索してみる
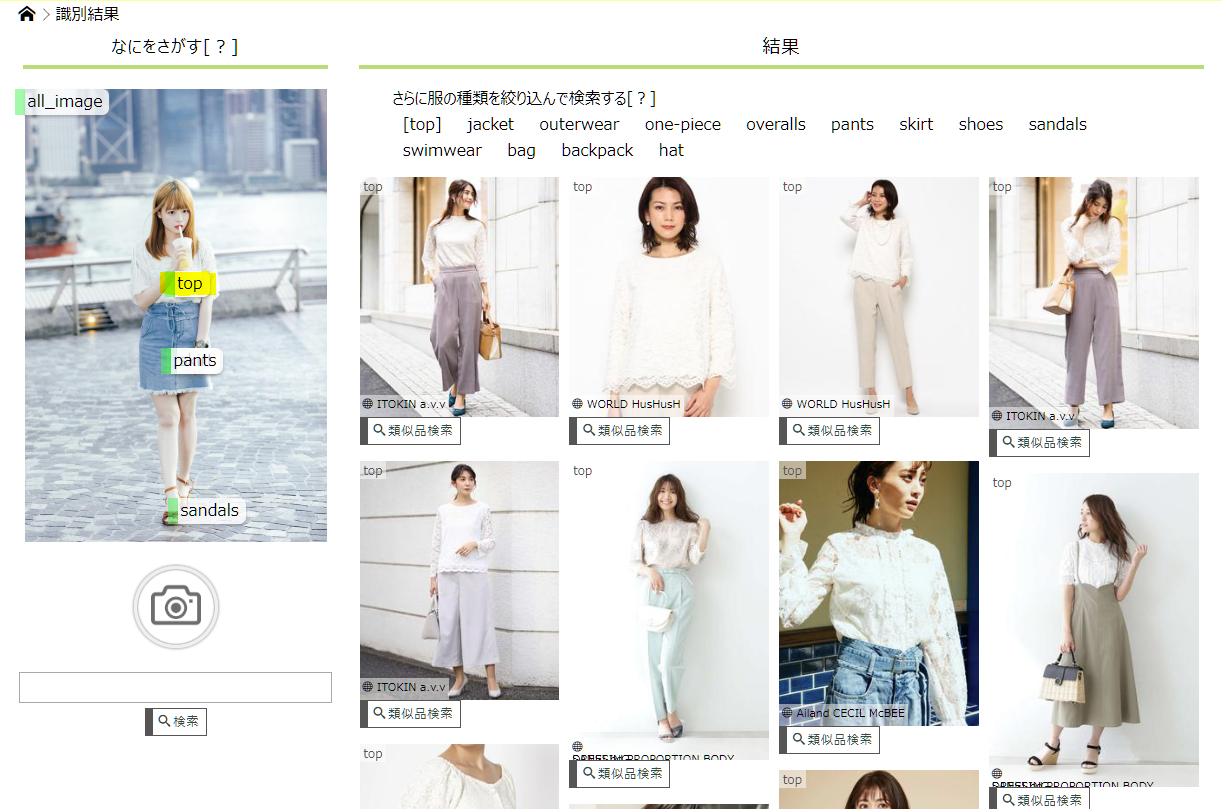
↑↑↑↑TOPで検索。まぁまぁかな![]()
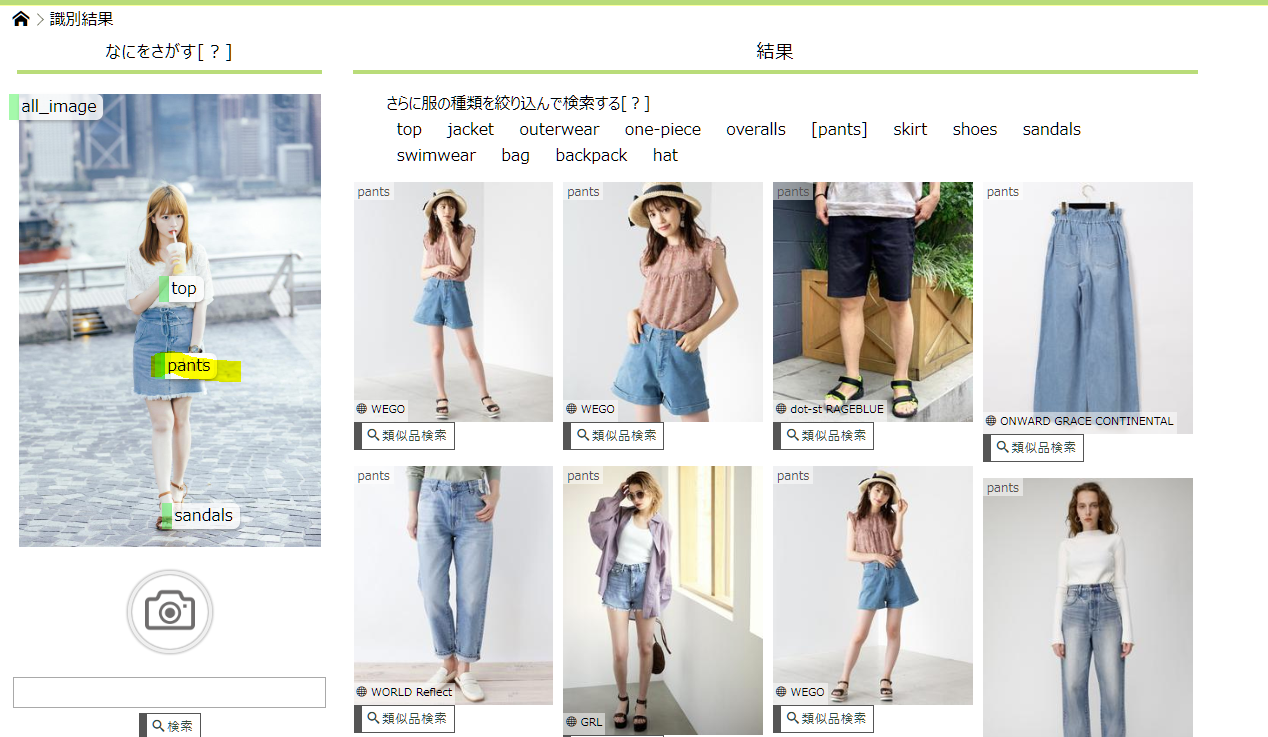
↑↑↑↑スカートのタグがパンツで押せなくなってる・・・![]()
しょうがないのでパンツで検索。
気持ちはわかる![]()
![]()
![]()
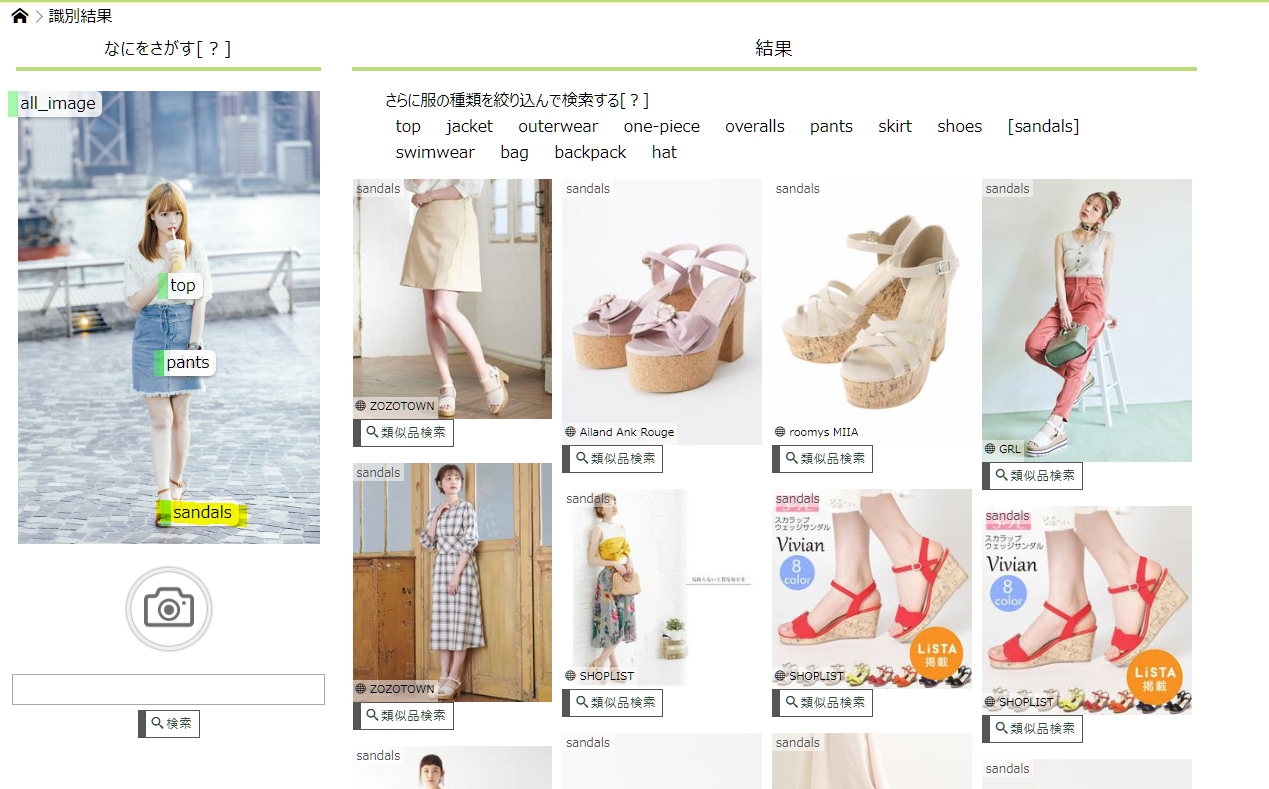
↑↑↑↑サンダルで検索。
ええやん。![]()
2020/05/10 追記 まとめ
物体認識とtriplet lossの教師データをただひたすらに修正する苦行、モデルの修正、学習スピードを上げる工夫を行う半年間でした。
合計で3万枚程度の画像をひたすら手で処理していく。こんな苦行は本当にやりたくありません。![]()
短時間睡眠で毎日毎日・・・![]()
![]()
![]()
つぎはライトアウター分類の追加、顔検索を追加したい・・