顔の識別、検索をしたいがデータを集めて切り取りする作業があまりにも鬼畜な作業なので自動化したくて頑張ってみる。
open cv では傾いた顔を認識しない、顔じゃないものを顔と認識するなどなどイマイチ。
物体検出というものがあるらしい
ここ
https://github.com/pierluigiferrari/ssd_keras
にあるコードが自分の環境(TensorFlow 1.x、Keras 2.x)で動きそうだったので試してみた。
ssd300_inference.ipynbかssd512_inference.ipynbに従ってポチポチコピペして実行してみる
とくに何の問題もなく実行できる。
ssd512_inference.ipynbの方が精度は高いみたい。
残念ながら顔は認識しなかった。
精度がすごく高い。えげつない。
こんなところに人がいたんだ!!!って物も見つけてくる。
VOCを学習させてみる
教師データ「To train the original SSD300 model on Pascal VOC:」をダウンロードしてssd300_training.ipynbに従ってポチポチと実行する。
特に問題なく学習が始まる。
終わらない。
(環境はWindows,CPU i5 7500,GPU GTX-1070ti,メモリ 24G)
GPUのLOADがあまり上がらない。CPUは全コア100%を指している。
画像のジェネレータが重いのかも?。
複数GPUにしてみたが、そもそもCPUが限界だから速度はあがらないしmodelの保存で失敗(エポック毎に保存)するし、なかなか厳しい
ジェネレータ周辺のソースをcythonにしてみたが変わらない。
単騎で戦うしかない(´・ω・`)
Ryzen Threadripper 2990WXが欲しいよ・・
ssd512のほうはやってみたが失敗する。
ipynbにはSSD300と変わんねーから説明しない!と書いてある。
細かいパラメータを合わせてもepoch-01でエラー。
動かない。
ファインチューンのやり方も書いてあるけど、いまいちピンとこなかった。
もともとのClass idを生かして学習しろ~って書いてあるけど、元のclassは使いたくない。
最初から学習だ。最初はVGG16の重みを読み込むってあるので、まっさらな状態でもないみたい。
顔認識教師データをつくる
画像のどこの部分(四角で指示)が顔だよって教師データを用意してあげればいい。
VOCのデータをみてみるとXMLでダーーーーっとかいてある。
これと同じものを作ればいい。
これをアノテーションと言うみたい。
あれ?また鬼畜作業?
(´・ω・`)
VoTTで鬼畜作業
Visual Object Tagging Toolというツールを使ってアノテーションを作るのが一番らくだった。
人の画像を集めてVoTTで四角を手で書きまくる。
(´,,・ω・,,`)どうせ書くなら
ファッションにつながる物を抽出しちゃおう!
トップ、スカート、アウター、シューズみたいな感じでアノテーションを作って行く
20枚も書くと飽きてくる。
100枚も書くと吐き気がするよ。
↓鬼畜なアノテーション作成作業
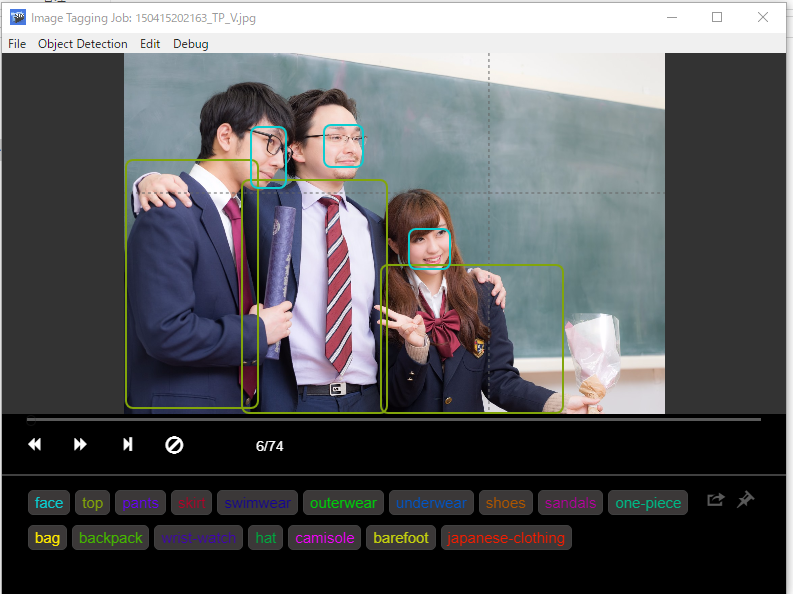
ぱくたそをまた使いました。
一万枚くらいやればええですか・・・(´・ω・`)
アノテーションをやり始めた頃と数百枚作業したあとではBOXの書きっぷりが違うので・・・
最初に戻って微調整する。これがまた鬼畜。やりたくない。
途中結果
400程度枚の画像をepoch-19まで学習した結果

ぱくたそ です
やってみてわかったことは
・画像収集がやっぱりめんどくさい
・最初は100毎程度でちゃんと動いてるか?途中で確認したほうがいい。
・当たり前だけど間違った教師データや、抜けデータがあると精度が悪くなる。とくに顔があるのに、顔の指示が無い場合とか多くなりがち。
・教師データを何度も確認。
そのた注意点
・background classは最初にちゃんといれよう。(LISTの一番最初をbackgroundと認識する)
・n_classes = は自分のクラス数に合わせて書き換える
・VOCのフォーマットとVoTTのフォーマットが微妙に違うので修正する
・trainval.txt>トレーニングのデータみたい。こいつを作る必要がある
・test.txt>確認のデータみたい。こいつを作る必要がある。
・VoTTはファイル名でソートされた順番で記録されているのでファイルを消したり足したりするとズレる(補正する機能がない)
・SSDが*.jpg以外は変だったので全部*.jpgにする(フォーマットもファイル名も*.jpg)
・VoTTがjpegだとexportで変だったので全部*.jpgにする(フォーマットもファイル名も*.jpg)
VGG16を学習させるのと違ってすごくめんどくさい
今後
1万枚くらい学習させたいので
学習>推定>VoTTのフォーマットで結果を保存>人間が修正
を繰り返して教師データを増やしていく
(´,,・ω・,,`)忍耐