背景
YouTubeを見ていて、見ている動画と似た雰囲気の動画が見たいなーと思うことがあります。
しかし、YouTubeで対象動画の関連で調べることはできますが、類似度で検索するのは不可能。
ということで、1つの動画を渡したら、同じような雰囲気の動画を提案してくれる分析システムを作成します。
最終的に
YouTubeのURLを入力することで、対象動画に対して類似の動画上位10件をHTML形式として出力できるようになりました。

コードと苦労した点も含めて以下に記載します。
環境
- Python 3.9.16
- Windows
- Google Chrome
- Google Colaboratory
使用技術
- MeCab
- NEologd
- Google SpreadSheet
- YouTube Data API v3
- tf-idf
- Transformer
- BERT
- MultiIndex
- COS類似度
- css
- HTML
- matplotlib
対象チャンネル
今回はデカキンさんのチャンネルに投稿されている動画をもとに分析を行いました。
理由としては以下の点が挙げられます。
- 動画の分類分けが分かりやすく行われている
- クレーンゲーム、1万円円企画、キャンプ、食品サンプル企画など
- 私がよく視聴している
対象データを選択する際に一番重視した点は、動画の分類分けが既に分かりやすく行われていることです。
この分析システムの結果として、類似度の高い動画一覧を出力するのですが、全体的に同じような雰囲気の動画や、ゲーム実況のみの動画しか投稿されていないチャンネルだと、分析された結果を提示された際、本当に類似度が高いのか、というのが判断しにくいと考えました。
また、この分析システムでは字幕を使用するため、大食い動画や料理動画だと環境音が大きく字幕の邪魔になってしまうため、対象チャンネルの候補として外しています。
その点、デカキンさんの動画は、分類分けが既に行われている動画が多く、環境音もそこまで多くないため、今回のシステムと相性が良いと考えた次第です。
分析システム
以下の流れで実装を行います。
- 1. インストール
- 2. ユーザー辞書の作成
- 3.YouTubeデータ取得
- 4. YouTubeの字幕取得と自然言語処理
- 5. ベクトル化
- 6. YouTubeコメント取得に進む前に少し脱線
- 6. YouTubeコメント取得
- 7. 対象データ決定
- 8. 類似度算出と感情分析
- 9. HTML化
- 10. 図での表示
- 実行結果
- 最終的な結果
1. インストール
最初に環境構築を行います。
# YouTube関連のインストール
!pip install youtube-transcript-api
!pip install google-api-python-client
# MeCab辞書のインストール
!sudo apt install mecab
!sudo apt install libmecab-dev
!sudo apt install mecab-ipadic-utf8
# Mecabのインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# Neologdのインストール
!pip install neologdn emoji mojimoji
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
!./mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a -y
# Transformerのインストール
!pip install transformers
!pip install sentence_transformers
!pip install fugashi
!pip install ipadic
# YouTubeAPIのインストール
!pip install google-api-python-client
2. ユーザー辞書の作成
YouTubeのタイトルや字幕を形態素解析する際にMeCabを使用するのですが、NEologdを使用してもカバーしきれない単語があります。
特に人物名は間違った状態で分割されます。
そのため、NEologdを使用しつつ、ユーザー辞書を使用するようにしました。
ちなみに形態素解析ツールとしてMeCabとJanomeがありますが、今回、MeCabを選択した理由の1つとして、NEologdとユーザー辞書を併用できるという点があります。
単語説明
形態素解析
自然言語処理の一部。自然言語で書かれた文を、文法や辞書の単語の品詞等の情報にもとづき、言語上で意味を持つ最小単位(=形態素)に分け、それぞれの品詞や変化などを判別すること。
MeCab
京都大学情報学研究科 日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジンNEologd
MeCab用のシステム辞書Web上の言語資源から得た新語を追加し、カスタマイズしている。
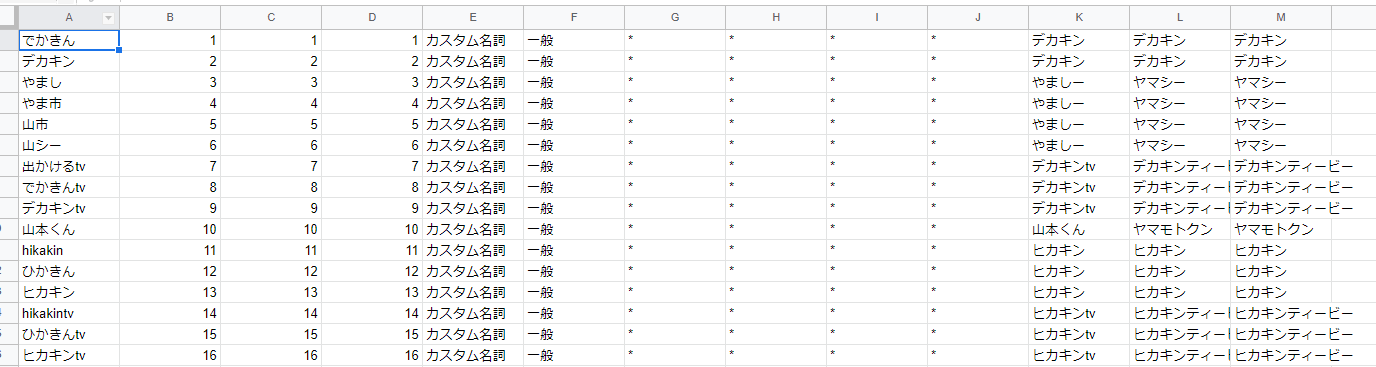
1. Google SpreadSheet作成
ユーザー辞書の基になるデータをGoogle SpreadSheetに設定します。
左の列から、「表層形」「左文脈ID」「右文脈ID」「コスト」「品詞」「品詞細分類1」「品詞細分類2」「品詞細分類3」「活用型」「活用形」「原形」「読み」「発音」になります。
ちなみに実用を考える場合、このデータ量をもっと増やす必要があるのですが、今回は「とりあえず作ってみる」を目的としているため、設定している単語数がかなり少なくなっています。
ユーザー辞書を充実させる場合、YouTubeの字幕やコメントから固有名詞を抜き出し、単語に対して行われる変換を全て記載する必要がありそうな気がしています。
2. csvファイル作成
Google SpreadSheetの内容を取得し、csvファイルとして保存します。
ちなみに、Google SpreadSheetの内容を取得するためには、以下のような認証処理を走らせます。

# ユーザー辞書の作成
from google.colab import auth
from oauth2client.client import GoogleCredentials
from google.auth import default
import gspread
import pandas as pd
# GoogleSpreadSheet
spreadUrl = 'https://docs.google.com/spreadsheets/d/XXXXXXXXXX/XXXXXXXXXX'
key = spreadUrl.split('/')[5]
# 認証処理
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)
# GoogleSpreadSheetからデータを取得
sh = gc.open_by_key(key)
worksheet = sh.get_worksheet(0)
# DataFrameに変換
df_spread = pd.DataFrame(worksheet.get_all_values())
# csvとして保存
df_spread.to_csv('userdic.csv', header=False, index=False, encoding='utf8')
3. ユーザー辞書の作成と追加
csvファイルをdicファイルに変換し、MeCabで使用できるようにします。
MeCabもdicファイルも初めて扱うため、苦労しました。
また、参考にしていたサイトに記載されている内容だとGoogle Colaboratoryで実行できないということが多く、試行錯誤の繰り返しでした。
# ファイル作成
!mkdir -p /var/lib/mecab/dic/userdic
# csvからdicファイル作成
!/usr/lib/mecab/mecab-dict-index \
-d /usr/share/mecab/dic/ipadic \
-u /content/userdic.dic \
-f utf-8 \
-t utf-8 /content/userdic.csv
!mv -f /content/userdic.dic /var/lib/mecab/dic/userdic/userdic2.dic
# ユーザー辞書を追加
!echo "userdic = /var/lib/mecab/dic/userdic/userdic2.dic" >> /etc/mecabrc
!cat /etc/mecabrc
import MeCab
3. YouTubeデータ取得
チャンネルIDを指定して、チャンネルの動画データを全件取得します。
今回の場合はだいたい1,300件ほどの取得になります。
YouTube Data APIには以下の制限があるため、考慮した取得をする必要があります。
- 1回の取得で最大50件しか取得できない
- 取得期間を設定しないと最大500件しか取得できない
- 1日に使えるクォータの量は10,000となるため、無制限にAPIを使えるわけではない
1. 動画一覧取得
publishedAfter、publishedBeforeを指定し、1年間の動画を取得する処理を繰り返すように対応しました。
publishedAfter、publishedBeforeとは、それぞれ取得する期間の開始と終了です。
1年前と2年前に取得できる動画が1件もなければ、繰り返しが終了するようになっています。
実行する前に対象のチャンネルIDと自身のYouTubeAPIキーを取得している必要があります。
# YouTube用
from apiclient.discovery import build
from youtube_transcript_api import YouTubeTranscriptApi
# 日付用
from datetime import datetime, date, timedelta
from dateutil.relativedelta import relativedelta
import calendar
# その他
import numpy as np
import pandas as pd
# YouTube検索
def search_youtube(afterDate, beforeDate, pageToken):
search_result = youtube.search().list(
channelId = 'XXXXXXXXXX',
part = 'snippet',
type = 'video',
maxResults = 50,
order = 'date',
publishedAfter = afterDate,
publishedBefore = beforeDate,
pageToken = pageToken
).execute()
return search_result
# 定数
YOUTUBE_API_KEY = 'XXXXXXXXXX'
PATH = '/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd'
# 日付取得
today = datetime.today()
year = today.year
month = today.month
after_date = date(year, 1, 1)
before_date = date(year, 12, calendar.monthrange(year, month)[1])
fmt_after_date = after_date.strftime('%Y-%m-%dT%H:%M:%S.%fZ')
fmt_before_date = before_date.strftime('%Y-%m-%dT%H:%M:%S.%fZ')
print(fmt_after_date)
print(fmt_before_date)
# youtubeデータ取得
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
endFlg1 = False
endFlg2 = False
youtubeList = []
while True:
nextPageToken = ''
# 年毎に取得
search_year_top = search_youtube(fmt_after_date, fmt_before_date, '')
print(search_year_top)
# 1回目/2回目の取得件数が0件の場合終了
year_top_cnt = search_year_top['pageInfo']['resultsPerPage']
if endFlg1 == False and year_top_cnt == 0:
endFlg1 = True
if endFlg1 == True and year_top_cnt == 0:
endFlg2 = True
if endFlg1 == True and endFlg2 == True:
break
# データ追加
if year_top_cnt != 0:
if len(youtubeList) == 0:
youtubeList.append(search_year_top['items'])
else:
youtubeList = np.append(youtubeList, search_year_top['items'])
# 年毎データが50件以上ある場合
if 'nextPageToken' in search_year_top:
nextPageToken = search_year_top['nextPageToken']
while True:
# 年毎に繰り返し取得
search_year_for = search_youtube(fmt_after_date, fmt_before_date, nextPageToken)
print(search_year_for)
# データ追加
youtubeList = np.append(youtubeList, search_year_for['items'])
# 50件以上取得データがない場合は繰り返し終了
if 'nextPageToken' in search_year_for:
nextPageToken = search_year_for['nextPageToken']
else:
break
# 前年の日付取得
after_date = after_date - relativedelta(years=1)
before_date = before_date - relativedelta(years=1)
fmt_after_date = after_date.strftime('%Y-%m-%dT%H:%M:%S.%fZ')
fmt_before_date = before_date.strftime('%Y-%m-%dT%H:%M:%S.%fZ')
print(fmt_after_date)
print(fmt_before_date)
# 取得データ表示
df_list = pd.DataFrame([x for x in youtubeList])
display(df_list)
2. DataFrame化
「1. 動画一覧取得」で取得したデータをDataFrame化し、視認性をあげます。
# 取得結果をDataFrame変換
df_id = pd.DataFrame(list(df_list['id']))['videoId']
df_snippet = pd.DataFrame(list(df_list['snippet']))
# 取得結果を結合
df_searchData = pd.concat([df_id, df_snippet], axis=1)
display(df_searchData)
実行すると以下のようにデータが表示されます。
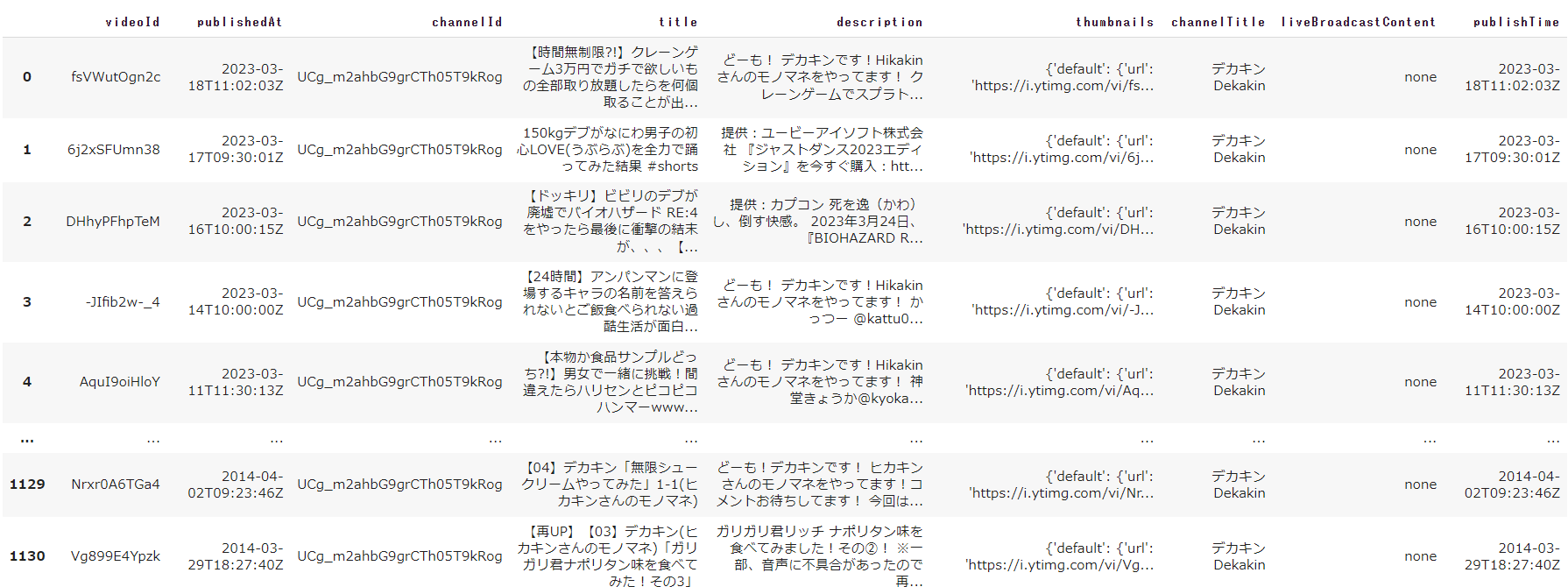
今回の分析システムの中で使用する項目は「videoId」と「title」くらいになります。
※「description」についても分析を行おうと思っていましたが、住所やURL等、動画に関係ない記載が多く、分析してみた結果、類似度の高いYouTubeを提案するという今回の目的にあわなかったため、対象から外しています。
4. YouTubeの字幕取得と自然言語処理
「3. YouTubeデータ取得」で取得したデータを使用し、字幕取得と自然言語処理を同時に行っていきます。
ソースが長いため、全文を記載する前に部分毎に分けて記載します。
字幕取得
今回は、手動字幕ではなく自動字幕を取得するようにしています。
理想としては、日本語の手動字幕があれば手動字幕を取得、なければ日本語の自動字幕を取得とするのですが、YouTube Data APIの制限の上限を超えたくないので、自動字幕の取得のみにしています。
最後の返却値を「reSub」で囲っていますが、今は一旦無視してください。
その他、気を付けた点は以下の通りです。
- find_generated_transcript()に ['ja'] を指定することで日本語の自動字幕を取得
- try - catch を記載することで、自動字幕の取得が行えなかった動画については、ブランク値を返すよう対応
def getSubTitles(videoId):
try:
transcript_list = YouTubeTranscriptApi.list_transcripts(videoId)
transcript = transcript_list.find_generated_transcript(['ja'])
subtitles = ''
for tr in transcript.fetch():
subtitles = subtitles + tr['text']
return reSub(subtitles)
except:
return ''
ちなみに、tr['text']をsubtitlesという変数に結合し、文字列を作成していますが、tr['text']は必ずしもしっかりとした1文になるとは限りません。
ここでいう「しっかりとした1文」というのは、「○○○で、○○○だ。」のように必ず「。」が文章の最後に設定される、1つのまとまった意味を言い表した一続きの言葉という意味です。
字幕を1度でも見たことがある人なら分かるかもしれませんが、字幕は口語に対応して生成されるため、文章として中途半端な状態になっていることも往々にしてあります。
自然言語処理
1. 前処理
形態素解析を行う前に文章の正規化を行います。
先ほど字幕取得で使用していた「reSub」は正規化の関数になります。
ここでは、文章の表記揺れを最低限にするようにします。大文字を小文字に変換したり、全角を半角に変換したり等です。
また、字幕では [音楽] や [拍手] といった環境音を [] で表すのですが、今回はノイズになるため、 [] を含んだ文字列を除くように対応しています。
def reSub(subtitles):
subtitles = neologdn.normalize(subtitles)
subtitles = subtitles.lower()
subtitles = re.sub("\[[^\]]*\]", "", subtitles) # []を除く
return subtitles
2. 形態素解析
MeCabでの形態素解析を行います。
ユーザー辞書を使用したことにより、ユーザー辞書で設定した単語はカスタム名詞と判定されます。
カスタム名詞と判定された単語は原型列に該当する単語を、名詞と判定された単語はそのままの値を取得します。
上記対応を行うことで、例えば名詞で「出かけるtv」と取得されていても「デカキンtv」として取得できるようになります。
def getWordList(subtitles):
subtitles = reSub(subtitles)
# MeCabで形態素解析
wordList = []
mecab = MeCab.Tagger(f'-Odump -d {PATH}')
mecab.parse('')
node = mecab.parseToNode(subtitles)
while node:
# 品詞を取得
pos = node.feature.split(",")[0]
if pos == 'カスタム名詞':
wordList.append(node.feature.split(",")[6])
elif pos == '名詞':
wordList.append(node.surface)
node = node.next
return wordList
3. ストップワードの除去
形態素解析後の単語リストに対し、ストップワードの除去を行います。
ストップワードとは「あれ」「これ」「さん」のような、一般的であるが故に自然言語処理の対象外となる単語です。
urlから日本語用のストップワードがまとまっているテキストファイルをダウンロードし、ローカルで使用できるようにしています。
txtPath = '/content/Japanese.txt'
url = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
if not os.path.exists(txtPath):
urllib.request.urlretrieve(url, txtPath)
with open(txtPath, 'r') as f:
lines = f.read().splitlines()
wordList.append([word for word in titleWord if word not in lines and len(str(word)) != 1])
ソース全文
以下の順番で処理を行います。
- タイトルの正規化
- タイトルを形態素解析し、名詞を取得
- タイトル名詞のストップワード除去
- 字幕の取得
- 字幕の正規化
- 字幕を形態素解析し、名詞を取得
- 字幕名詞のストップワード除去
# 字幕取得用
from youtube_transcript_api import YouTubeTranscriptApi
# 形態素解析用
import MeCab
import neologdn
# 正規化
import re
# ストップワード用
import os
import urllib.request
# 名詞取得
def getWordList(subtitles):
subtitles = reSub(subtitles)
# MeCabで形態素解析
wordList = []
mecab = MeCab.Tagger(f'-Odump -d {PATH}')
mecab.parse('')
node = mecab.parseToNode(subtitles)
while node:
# 品詞を取得
pos = node.feature.split(",")[0]
if pos == 'カスタム名詞':
wordList.append(node.feature.split(",")[6])
elif pos == '名詞':
wordList.append(node.surface)
node = node.next
return wordList
# 字幕取得
def getSubTitles(videoId):
try:
transcript_list = YouTubeTranscriptApi.list_transcripts(videoId)
transcript = transcript_list.find_generated_transcript(['ja'])
subtitles = ''
for tr in transcript.fetch():
subtitles = subtitles + tr['text']
return reSub(subtitles)
except:
return ''
# 正規化
def reSub(subtitles):
subtitles = neologdn.normalize(subtitles)
subtitles = subtitles.lower()
subtitles = re.sub("\[[^\]]*\]", "", subtitles) # []を除く
return subtitles
# ストップワード取得
txtPath = '/content/Japanese.txt'
url = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
if not os.path.exists(txtPath):
urllib.request.urlretrieve(url, txtPath)
with open(txtPath, 'r') as f:
lines = f.read().splitlines()
# 動画毎に字幕/名詞取得
youtube_wordList = []
for data, row in df_searchData.iterrows():
wordList = []
# タイトル名詞取得
titleWord = getWordList(row['title'])
wordList.append([word for word in titleWord if word not in lines and len(str(word)) != 1])
# 字幕取得
subtitles = getSubTitles(row['videoId'])
wordList.append(subtitles)
# 字幕名詞取得
subtitlesWord = getWordList(subtitles)
wordList.append([word for word in subtitlesWord if word not in lines and len(str(word)) != 1])
# データ追加
youtube_wordList.append(wordList)
# YouTubeデータと字幕データを結合
df_all = pd.concat([df_searchData, pd.DataFrame(youtube_wordList, columns=['titles_word', 'subTitles', 'subTitles_word'])], axis=1)
display(df_all)
実行すると以下のようにデータが表示されます。

「3. YouTubeデータ取得」で取得したデータに、タイトル名詞、字幕、字幕名詞を追加しています。
5. ベクトル化
タイトル名詞と字幕名詞を使用し、各単語の特徴量をベクトル化します。
使用するのは「tf-idf」になります。
単語説明
tf-idf
各文書中に含まれる各単語が「その文書内でどれくらい重要か」を表す統計的尺度の1つ具体的には「ある文書内」で「ある単語」が「どれくらい多い頻度で出現するか」を表すtf値と、「全文書中」で「ある単語を含む文書」が「(逆に)どれくらい少ない頻度で存在するか」を表すidf値を掛け合わせた値のことである。
# ベクトル用
from sklearn.feature_extraction.text import TfidfVectorizer
# タイトル重み取得
vectorizer_title = TfidfVectorizer(use_idf=True, token_pattern='(?u)\\b\\w+\\b')
vecs_title = vectorizer_title.fit_transform(df_all['titles_word'].astype(str))
df_feature_title = pd.DataFrame(vecs_title.toarray(), columns=vectorizer_title.get_feature_names_out()).set_index(df_all['videoId'])
display(df_feature_title)
# 字幕重み取得
vectorizer_subTitle = TfidfVectorizer(use_idf=True, token_pattern='(?u)\\b\\w+\\b')
vecs_subTitle = vectorizer_subTitle.fit_transform(df_all['subTitles_word'].astype(str))
df_feature_subTitle = pd.DataFrame(vecs_subTitle.toarray(), columns=vectorizer_subTitle.get_feature_names_out()).set_index(df_all['videoId'])
display(df_feature_subTitle)
実行すると以下のようにデータが表示されます。
-
タイトルのベクトル化
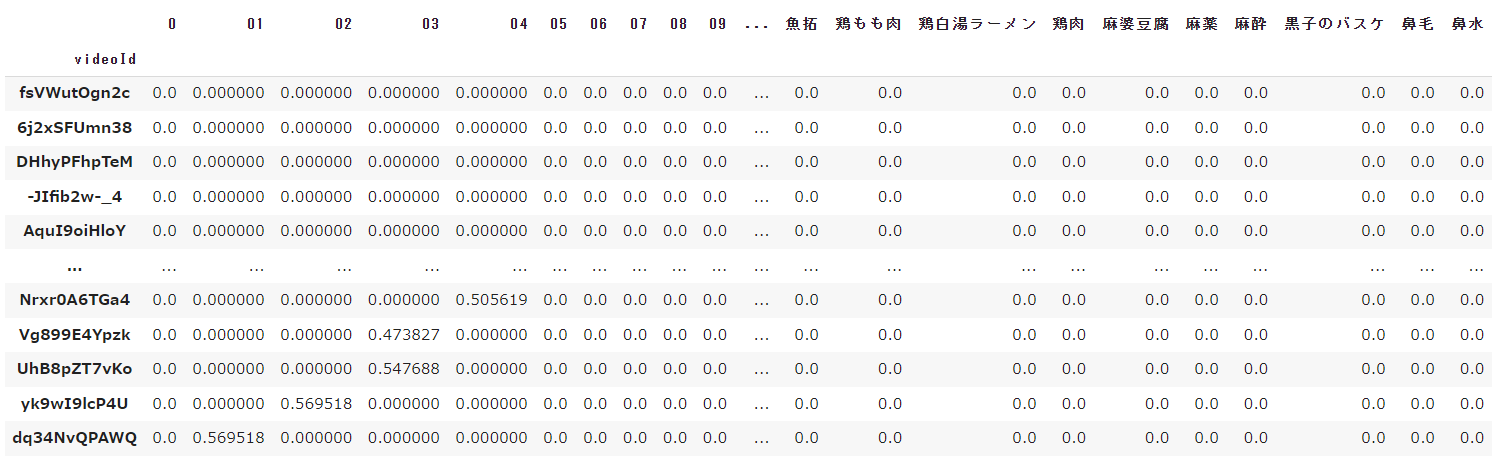
-
字幕のベクトル化
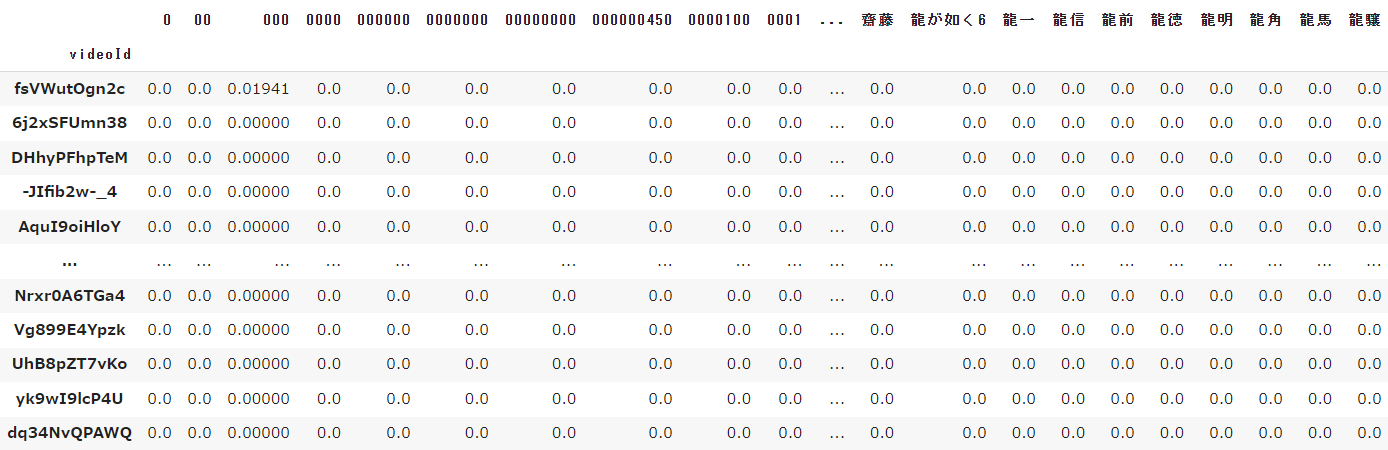
字幕のベクトル化では特に顕著ですが、字幕を使用しベクトル化している単語が約52,500個あるため、一部分のデータの切り取りでは全て値が0になってしまいます。
6. YouTubeコメント取得に進む前に少し脱線
今まではMeCabを主に使用していましたが、「YouTubeコメントの取得」で取得したコメントを使用し、「Transformer」と「BERT」を使用してみようと思います。
単語説明
Transformer
2017年に発表された"Attention Is All You Need"という自然言語処理に関する論文の中で初めて登場した深層学習モデル並列化によって学習時間を大幅に短縮できる。
大規模な学習データを学習することが可能であり、BERTやGPTなどの大規模な学習データを使ったモデルに応用される。
BERT
Google社が発表した自然言語処理モデル特徴として、「文脈を読めるようになったこと」が挙げられる。
Transformerというアーキテクチャを組み込むことによって、文章を文頭・文末の双方向から学習し、文脈を読めるようになった。
そもそも、なぜ字幕を「BERT」で分析しなかったかといえば、字幕自体の精度が悪いという一点になります。
どの技術にもいえるのかもしれませんが、自然言語を分析する際、分析対象となる文章がちゃんとした文章であること、が大前提となっている気がします。
ここでいう「ちゃんとした文書」というのは、日本語として正しいとか、文法が正しいとかいうのではなく、人間がその文を読んで理解できる文章であるかということです。
例えば、取得した字幕の一文を紹介します。
クレーンゲームで行っサテンととってあるんでそれでは描キンが降ったセントがこちらです
これは口語にすると「クレンゲームでとったテントがあるんで。それではデカキンがとったテントがこちらです」という文になりますが、字幕にすると上記のようになります。
人間が理解できない文章は、下準備がなければ、どんな技術でも分析に繋げることは難しいでしょう。
そのため、字幕では、形態素解析で名詞を抽出し、tf-idfによる特徴量のベクトル化を行いました。
(もしかしたら、形態素解析した名詞を使用してBERTで特徴量のベクトル化をできたのかもしれませんが、データ分析初心者のため、分かりやすいという点でtf-idfを選んだのも理由の1つです)
長くなりましたが、本題に戻ります。
動画に投稿されたコメントを分析するため、一定の精度が保たれます。
また、MeCabやtf-idfを使用した経験を一応積んだため、何も分からない初心者ではなく、ある程度のことはなんとなく分かるようになってきました。
ということで、ようやく「YouTubeコメントの取得」で取得したコメントを使用して、「Transformer」と「BERT」を使ってみようという最初の話に戻ります。
ちなみに、当初、YouTubeで取得したコメント全てに対してBERTで感情分析をしようと思っていたのですが、相当な時間がかかってしまったため、類似度の高い上位10件の動画に対してのみ行うよう構想を変更しています。
(10件の動画で3分かかったため、1000件の動画で考えると300分かかる計算になります)
そのため、BERTが出現するのはもう少し後の「8. 類似度算出と感情分析」になります。
6. YouTubeコメント取得
動画毎に繰り返し、対象の動画のコメントを取得します。
こちらもYouTube Data APIを使用しているのですが、動画データの取得時と異なり、1回の取得で最大100件のコメントが取得できます。
本来であれば、動画に投稿されたコメントを全件取得するのが良いとは思いますが、YouTube Data APIの上限を超えたくないため、1つの動画につき、評価数やグッド数が高い順に100件取得するようにしています。
import requests
import json
# コメント取得
def print_video_comment(videoId):
params = {
'key': YOUTUBE_API_KEY,
'part': 'snippet',
'videoId': videoId,
'order': 'relevance',
'textFormat': 'plaintext',
'maxResults': 100,
}
response = requests.get(comURL + 'commentThreads', params=params)
resource = response.json()
commentList = []
if 'items' in resource.keys():
for comment_info in resource['items']:
commentList.append(comment_info['snippet']['topLevelComment']['snippet']['textDisplay'])
return commentList
# 定数
comURL = 'https://www.googleapis.com/youtube/v3/'
# 動画毎にコメント取得
commentList_videoId=[]
for videoId in df_all['videoId']:
commentList = print_video_comment(videoId)
commentList_videoId.append(commentList)
# 取得データ表示
df_comment = pd.DataFrame(commentList_videoId).set_index(df_all['videoId'])
display(df_comment)
実行すると以下のようにデータが表示されます。

7. 対象データ決定
Google Colaboratory上に以下のような疑似フォームを作成し、類似度算出の基になる動画を決定します。
パラメータの説明は以下の通りです。
- youtubeURL
- 類似度算出の基になる動画のURLを設定することでvideoIdを取得します
- titleFlg
- 類似度が最も高い動画を判定をする際にタイトルの類似度を考慮にいれるかのフラグ
- subTitlesFlg
- 類似度が最も高い動画を判定する際に字幕の類似度を考慮にいれるかのフラグ
- word
- 対象の単語を含む動画を抽出し、類似度が最も高い動画として判定する
wordは複数指定できるようにしたかったのですが、時間がなかったため、今回は1単語のみ指定できるようになっています。
#@title 対象データ取得
youtubeURL = "https://www.youtube.com/watch?v=u7Fg8haPWLY" #@param {type:"string"}
titleFlg = True #@param {type:"boolean"}
subTitlesFlg = True #@param {type:"boolean"}
word = "" #@param {type:"string"}
def get_videoId(url):
target_videoId = ''
pattern_watch = 'https://www.youtube.com/watch?'
pattern_short = 'https://youtu.be/'
# 通常URLのとき
if re.match(pattern_watch,url):
yturl_qs = urllib.parse.urlparse(url).query
vid = urllib.parse.parse_qs(yturl_qs)['v'][0]
return vid
# 短縮URLのとき
elif re.match(pattern_short,url):
# "https://youtu.be/"に続く11文字が動画ID
vid = url[17:28]
return vid
else:
print('URLは\"https://www.youtube.com/watch?\"か"https://youtu.be/\"で始まるURLを指定してください。')
return ''
# URLからvideoId取得
target_videoId = get_videoId(youtubeURL)
print(target_videoId)
if target_videoId in df_all['videoId'].values:
print('対象データがあります。')
else:
print('対象データはありません。')
8. 類似度算出と感情分析
対象データ
「7. 対象データ決定」で決定した対象データに対して、処理を行います。
ソースが長いため、全文を記載する前に部分毎に分けて記載します。
1. 正規化
「4. YouTubeの字幕取得と自然言語処理の1. 前処理」で行った正規化とほぼ一緒の内容です。
def reSub(commentList):
reSub_commentList = []
for comment in commentList:
comment = neologdn.normalize(comment)
comment = comment.lower()
comment = re.sub("\[[^\]]*\]", "", comment) # []を除く
reSub_commentList.append(comment)
return reSub_commentList
2. 対象データの取得
対象データを抽出します。
抽出したデータをもとに、videoId、title、urlを取得します。
urlをiframeにしているのは、後々HTML化した際に、YouTubeを埋め込み表示したいためです。
また、Multiindexを使用したいため、get1とget2の列を2つ追加しています。
Multiindexについては後述で記載します。
# 対象データ取得
df_target = df_all[df_all['videoId'] == target_videoId]
df_target_index = df_all.query('videoId == "{}"'.format(target_videoId)).index[0]
# 対象データ列追加
comList = list(filter(None, df_comment.loc[target_videoId].to_list()))
select_df_target = df_target.loc[:, ['videoId', 'title']]
select_df_target['url'] = '<iframe \
src="https://www.youtube.com/embed/{}" \
title="YouTube video player" \
frameborder="0" \
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" \
allowfullscreen> \
</iframe>'.format(target_videoId)
select_df_target['comment'] = '{:.1%}'.format(get_commentScore(comList) / len(comList))
select_df_target['get1'] = 'タイトル'
select_df_target['get2'] = '字幕'
3. 感情分析
BERTにて、コメントの感情分析を行います。
動画毎にコメント数が異なるため、コメント全件の点数 ÷ コメント数を計算し、1つのコメントの点数の平均を取得しています。
コメントによる感情分析のスコアも分析対象にいれたかったのですが、今回は実装を見送っています。(理由については先述に記載済み)
そのため、感情分析による点数は1つの情報としてしか扱われません。
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
model = AutoModelForSequenceClassification.from_pretrained("kit-nlp/bert-base-japanese-sentiment-irony")
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# commentのscore取得
def get_commentScore(commentList):
sumScore = 0
# 正規化
reSub_commentList = reSub(commentList)
# 感情分析
for score in nlp(reSub_commentList, truncation=True):
if 'score' in score.keys():
sumScore += score['score']
return sumScore
Noneのデータを除外しないとエラーとなるため、除外した状態で対象データのコメントリストを取得しています。
comList = list(filter(None, df_comment.loc[target_videoId].to_list()))
select_df_target['comment'] = '{:.1%}'.format(get_commentScore(comList) / len(comList))
4. 上位単語取得
「5. ベクトル化」で算出した特徴量の点数の高い順にタイトル、字幕それぞれで5つ単語を取得します。
上記を取得することで、対象データの特徴が視覚化されます。
get1やget2をgetに名称変更しているのは、Multiindex対応です。
# 変数
topCnt_title = 5
topCnt_subTitle = 5
# タイトル
# 対象データの上位単語取得
topList_title_target = [word for word, score in df_feature_title.loc[target_videoId].nlargest(topCnt_title).items() if score != 0]
clmList_title_target = list(range(1, len(topList_title_target)+1, 1))
topList_title_target = np.array(topList_title_target).reshape(-1, len(topList_title_target))
# DataFrame作成
df_title_base_target = pd.DataFrame(select_df_target.loc[:, ['videoId', 'title', 'comment', 'get1']], columns=['videoId', 'title', 'comment', 'get1']).reset_index(drop=True).rename(columns={'get1':'get'})
df_title_feature_target = pd.DataFrame(topList_title_target, columns=clmList_title_target).reset_index(drop=True)
df_title_target = pd.concat([df_title_base_target, df_title_feature_target], axis=1)
# 字幕
# 対象データの上位単語取得
topList_subTitle_target = [word for word, score in df_feature_subTitle.loc[target_videoId].nlargest(topCnt_subTitle).items() if score != 0]
clmList_subTitle_target = list(range(1, len(topList_subTitle_target)+1, 1))
topList_subTitle_target = np.array(topList_subTitle_target).reshape(-1, len(topList_subTitle_target))
# DataFrame作成
df_subTitle_base_target = pd.DataFrame(select_df_target.loc[:, ['videoId', 'title', 'comment', 'get2']], columns=['videoId', 'title', 'comment', 'get2']).reset_index(drop=True).rename(columns={'get2':'get'})
df_subTitle_feature_target = pd.DataFrame(topList_subTitle_target, columns=clmList_subTitle_target).reset_index(drop=True)
df_subTitle_target = pd.concat([df_subTitle_base_target, df_subTitle_feature_target], axis=1)
ソース全文
以下の順番で処理を行います。
- 感情分析モデルの作成
- 対象データ抽出
- 対象データに列追加
- コメントの正規化
- コメントの感情分析
- 対象データのタイトルで特徴量の高い上位単語を取得
- 対象データの字幕で特徴量の高い上位単語を取得
- 表示用DataFrameの作成
# 感情分析
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
# COS類似度
from sklearn.metrics.pairwise import cosine_similarity
# その他
import math
# 正規化
def reSub(commentList):
reSub_commentList = []
for comment in commentList:
comment = neologdn.normalize(comment)
comment = comment.lower()
comment = re.sub("\[[^\]]*\]", "", comment) # []を除く
reSub_commentList.append(comment)
return reSub_commentList
# commentのscore取得
def get_commentScore(commentList):
sumScore = 0
# 正規化
reSub_commentList = reSub(commentList)
# 感情分析
for score in nlp(reSub_commentList, truncation=True):
if 'score' in score.keys():
sumScore += score['score']
return sumScore
# 感情分析
model = AutoModelForSequenceClassification.from_pretrained("kit-nlp/bert-base-japanese-sentiment-irony")
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 変数
topCnt_title = 5
topCnt_subTitle = 5
# 対象データ取得
df_target = df_all[df_all['videoId'] == target_videoId]
df_target_index = df_all.query('videoId == "{}"'.format(target_videoId)).index[0]
# 対象データ列追加
comList = list(filter(None, df_comment.loc[target_videoId].to_list()))
select_df_target = df_target.loc[:, ['videoId', 'title']]
select_df_target['url'] = '<iframe \
src="https://www.youtube.com/embed/{}" \
title="YouTube video player" \
frameborder="0" \
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" \
allowfullscreen> \
</iframe>'.format(target_videoId)
select_df_target['comment'] = '{:.1%}'.format(get_commentScore(comList) / len(comList))
select_df_target['get1'] = 'タイトル'
select_df_target['get2'] = '字幕'
# タイトル
# 対象データの上位単語取得
topList_title_target = [word for word, score in df_feature_title.loc[target_videoId].nlargest(topCnt_title).items() if score != 0]
clmList_title_target = list(range(1, len(topList_title_target)+1, 1))
topList_title_target = np.array(topList_title_target).reshape(-1, len(topList_title_target))
# DataFrame作成
df_title_base_target = pd.DataFrame(select_df_target.loc[:, ['videoId', 'title', 'comment', 'get1']], columns=['videoId', 'title', 'comment', 'get1']).reset_index(drop=True).rename(columns={'get1':'get'})
df_title_feature_target = pd.DataFrame(topList_title_target, columns=clmList_title_target).reset_index(drop=True)
df_title_target = pd.concat([df_title_base_target, df_title_feature_target], axis=1)
# 字幕
# 対象データの上位単語取得
topList_subTitle_target = [word for word, score in df_feature_subTitle.loc[target_videoId].nlargest(topCnt_subTitle).items() if score != 0]
clmList_subTitle_target = list(range(1, len(topList_subTitle_target)+1, 1))
topList_subTitle_target = np.array(topList_subTitle_target).reshape(-1, len(topList_subTitle_target))
# DataFrame作成
df_subTitle_base_target = pd.DataFrame(select_df_target.loc[:, ['videoId', 'title', 'comment', 'get2']], columns=['videoId', 'title', 'comment', 'get2']).reset_index(drop=True).rename(columns={'get2':'get'})
df_subTitle_feature_target = pd.DataFrame(topList_subTitle_target, columns=clmList_subTitle_target).reset_index(drop=True)
df_subTitle_target = pd.concat([df_subTitle_base_target, df_subTitle_feature_target], axis=1)
# 表示データ作成
df_display_target = pd.concat([df_title_target, df_subTitle_target])
df_display_target = df_display_target.set_index(['videoId', 'title', 'comment', 'get'], append=True)
display(df_display_target.droplevel(0))
上記を実行すると以下のデータが表示されます。

comment列には、動画に対してのコメントの平均されたネガポジ点数が表示されます。
71.3はポジティブなコメントが多いことを示しています。
MultiIndexの設定をしているため、1つの動画に対して2行のデータを紐づけるような表示を実現しています。
MultiIndexとは、1つの列、もしくは1つの行に対して、複数のラベルをつけるIndexオブジェクトです。
上記の例でいうと、videoId、title、coomment、getに対してラベルをつけることで、videoId > title > comment > get の順にグループ分けされます。
1つの動画に対して、タイトルと字幕でそれぞれ特徴量の高い単語があるため、getで2つにグループ分けされ、それぞれに紐づくデータが表示されるようになります。
対象外データ
「7. 対象データ決定」で決定したデータ以外のデータに対して、処理を行います。
ソースが長いため、全文を記載する前に部分毎に分けて記載します。
また、「対象データ」で記載した内容と重複する場合は省きます。
1. 対象外データの取得
対象外データを抽出します。
「7. 対象データ決定」でwordを設定している場合は、設定した単語を含む動画も抽出しています。
# 対象外データ取得
df_except_target = df_all[df_all['videoId'] != target_videoId]
if len(word) != 0:
# 検索単語が設定されている場合
df_select_except_target_title = df_except_target[df_except_target['title'].str.contains(word)]
df_select_except_target_subTitle = df_except_target[df_except_target['subTitles'].str.contains(word)]
df_select_except_target = pd.concat([df_select_except_target_title, df_select_except_target_subTitle])
df_select_except_target.drop_duplicates(subset='videoId', inplace=True)
2. COS類似度算出
COS類似度とは、2つのベクトルが「どのくらい似ているか」という類似性を表す尺度のことです。
今回は、以下のCOS類似度を算出しています。
- 対象データのタイトル特徴量と対象外データのタイトル特徴量
- 対象データの字幕特徴量と対象外データの字幕特徴量
vecs_titleとvecs_subTitleは「5. ベクトル化」で特徴量をベクトル化した際に取得しています。
# 特徴量取得
feature_target_titles = vectorizer_title.transform(df_target['titles_word'].astype(str))
feature_target_subTitles = vectorizer_subTitle.transform(df_target['subTitles_word'].astype(str))
# COS類似度取得
similarity_titles = cosine_similarity(feature_target_titles, vecs_title)[0]
similarity_subTitles = cosine_similarity(feature_target_subTitles, vecs_subTitle)[0]
3. 上位10件取得
COS類似度の高い順に対象データを除いて上位10件取得します。
上位10件を判定する基になる類似度を、タイトルと字幕でそれぞれ算出した類似度と、「7. 対象データ決定」で設定した「titleFlg」「subTitlesFlg」を基に決定します。
判定方法は以下の通りです。
- 「titleFlg」「subTitlesFlg」がどちらもチェックONの場合
- タイトルの類似度 + 字幕の類似度
- 「titleFlg」のみチェックONの場合
- タイトルの類似度
- 「subTitlesFlg」のみチェックONの場合
- 字幕の類似度
similarity = 0
if titleFlg == True:
similarity += similarity_titles
if subTitlesFlg == True:
similarity += similarity_subTitles
基にする類似度が決まったら、上位10件の類似度動画データを取得します。
「7. 対象データ決定」でwordを設定している場合は、「1. 対象外データの取得」で抽出した「wordを含む動画」を対象に上位10件取得するようにしています。
# 上位10件取得
top_index = np.argsort(-similarity)
if len(word) != 0:
# 検索単語が設定されている場合
topData = [index for index in top_index if index != df_target_index and index in df_select_except_target.index.values][:10]
else:
# 検索単語が設定されていない場合
topData = top_index[top_index != df_target_index][:10]
ソース全文
以下の順番で処理を行います。
- 対象外データ抽出
- wordを含むデータ抽出
- 特徴量取得
- COS類似度取得
- 上位10件取得
- 上位10件に対して列追加
- コメントの正規化
- コメントの感情分析
- 上位10件のタイトルで特徴量の高い上位単語を取得
- 上位10件の字幕で特徴量の高い上位単語を取得
- 表示用DataFrameの作成
# 正規化
def reSub(commentList):
reSub_commentList = []
for comment in commentList:
if comment is not None:
comment = neologdn.normalize(comment)
comment = comment.lower()
comment = re.sub("\[[^\]]*\]", "", comment) # []を除く
reSub_commentList.append(comment)
return reSub_commentList
# commentのscore取得
def get_commentScore(commentList):
sumScore = 0
# 正規化
reSub_commentList = reSub(commentList)
# 感情分析
for score in nlp(reSub_commentList, truncation=True):
if 'score' in score.keys():
sumScore += score['score']
return sumScore
# 対象外データ取得
df_except_target = df_all[df_all['videoId'] != target_videoId]
if len(word) != 0:
# 検索単語が設定されている場合
df_select_except_target_title = df_except_target[df_except_target['title'].str.contains(word)]
df_select_except_target_subTitle = df_except_target[df_except_target['subTitles'].str.contains(word)]
df_select_except_target = pd.concat([df_select_except_target_title, df_select_except_target_subTitle])
df_select_except_target.drop_duplicates(subset='videoId', inplace=True)
# 特徴量取得
feature_target_titles = vectorizer_title.transform(df_target['titles_word'].astype(str))
feature_target_subTitles = vectorizer_subTitle.transform(df_target['subTitles_word'].astype(str))
# COS類似度取得
similarity_titles = cosine_similarity(feature_target_titles, vecs_title)[0]
similarity_subTitles = cosine_similarity(feature_target_subTitles, vecs_subTitle)[0]
similarity = 0
if titleFlg == True:
similarity += similarity_titles
if subTitlesFlg == True:
similarity += similarity_subTitles
# 上位10件取得
top_index = np.argsort(-similarity)
if len(word) != 0:
# 検索単語が設定されている場合
topData = [index for index in top_index if index != df_target_index and index in df_select_except_target.index.values][:10]
else:
# 検索単語が設定されていない場合
topData = top_index[top_index != df_target_index][:10]
similarity_list = []
len_title_except_target = 0
topList_title_except_target = []
len_subTitle_except_target = 0
topList_subTitle_except_target = []
isClmCreate = False
for top in topData:
if similarity[top] <= 0:
continue
# 上位10件の基本データ設定
similarity_item_list = []
prm = df_all.iloc[top]
vId = prm['videoId']
comList = list(filter(None, df_comment.loc[vId].to_list()))
similarity_item_list.append(vId)
similarity_item_list.append(prm['title'])
similarity_item_list.append('<iframe \
src="https://www.youtube.com/embed/{}" \
title="YouTube video player" \
frameborder="0" \
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" \
allowfullscreen> \
</iframe>'.format(prm['videoId']))
similarity_item_list.append('{:.1%}'.format(get_commentScore(comList) / len(comList)))
similarity_item_list.append('タイトル')
similarity_item_list.append('字幕')
similarity_list.append(similarity_item_list)
# 対象データの上位単語取得
# タイトル
topList_title = [word for word, score in df_feature_title.loc[vId].nlargest(topCnt_title).items() if score != 0]
topList_title.insert(0, '{:.1%}'.format(similarity_titles[top]))
topList_title_except_target.append(topList_title)
if len(topList_title) > len_title_except_target:
len_title_except_target = len(topList_title)
# 字幕
topList_subTitle = [word for word, score in df_feature_subTitle.loc[vId].nlargest(topCnt_subTitle).items() if score != 0]
topList_subTitle.insert(0, '{:.1%}'.format(similarity_subTitles[top]))
topList_subTitle_except_target.append(topList_subTitle)
if len(topList_subTitle) > len_subTitle_except_target:
len_subTitle_except_target = len(topList_subTitle)
# 列ヘッダ作成
clmList_title_except_target = list(range(1, len_title_except_target, 1))
clmList_title_except_target.insert(0, 'score')
clmList_subTitle_except_target = list(range(1, len_subTitle_except_target, 1))
clmList_subTitle_except_target.insert(0, 'score')
# DataFrame作成
df_similarity = pd.DataFrame(similarity_list, columns=['videoId', 'title', 'url', 'comment', 'get1', 'get2'])
# タイトル
df_title_base_except_target = \
pd.DataFrame(df_similarity.loc[:, ['videoId', 'title', 'comment', 'get1']], columns=['videoId', 'title', 'comment', 'get1']).reset_index(drop=True).rename(columns={'get1':'get'})
df_title_feature_except_target = pd.DataFrame(topList_title_except_target, columns=clmList_title_except_target).reset_index(drop=True)
df_title_except_target = pd.concat([df_title_base_except_target, df_title_feature_except_target], axis=1)
# 字幕
df_subTitle_base_except_target = \
pd.DataFrame(df_similarity.loc[:, ['videoId', 'title', 'comment', 'get2']], columns=['videoId', 'title', 'comment', 'get2']).reset_index(drop=True).rename(columns={'get2':'get'})
df_subTitle_feature_except_target = pd.DataFrame(topList_subTitle_except_target, columns=clmList_subTitle_except_target).reset_index(drop=True)
df_subTitle_except_target = pd.concat([df_subTitle_base_except_target, df_subTitle_feature_except_target], axis=1)
# 表示データ作成
df_display_except_target = pd.concat([df_title_except_target, df_subTitle_except_target])
df_display_except_target = df_display_except_target.set_index(['videoId', 'title', 'comment', 'get'], append=True)
display(df_display_except_target.sort_index().droplevel(0).fillna(''))
上記を実行すると以下のデータが表示されます。
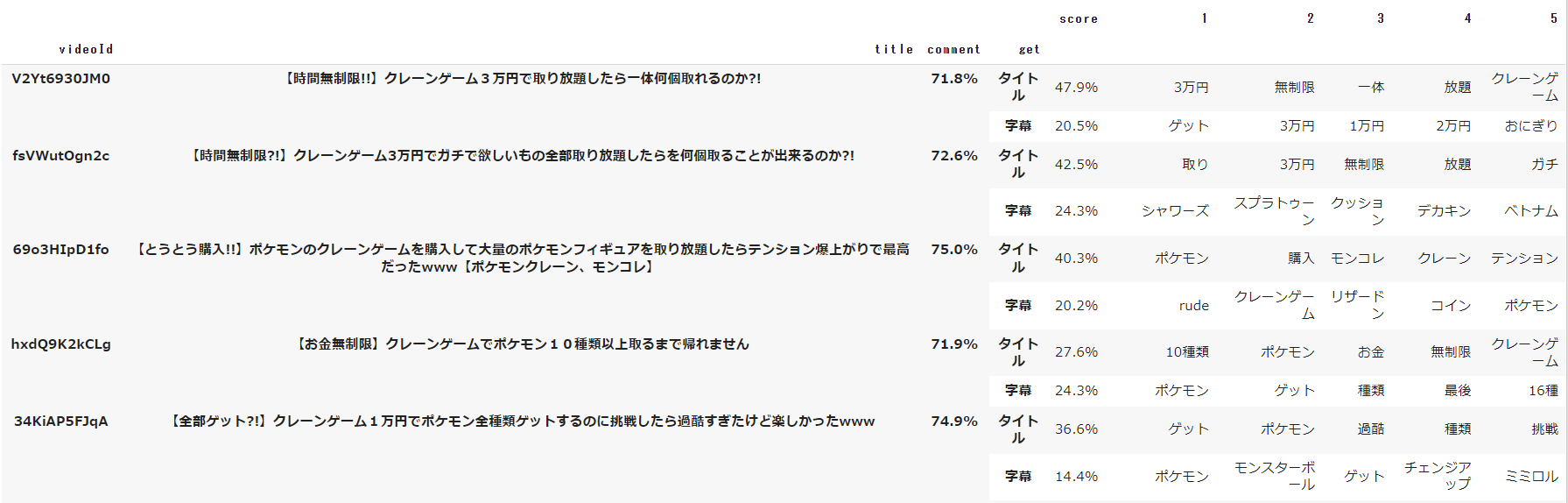
scoreは、対象データと上位10件の類似データのタイトルと字幕が、それぞれがどれだけ類似しているかを表しています。
9. HTML化
DataFrameをHTMLテーブルとしてレンダリングできるため、Google Colaboratory上でHTML表示できるようにします。
CSS作成
HTML化して表示するためにCSSファイルを作成します。
1行毎に背景色を変更するコードも書いていたのですが、Google Colaboratory上ではうまく動かなかったため、削除しました。
# CSS作成
css = """
html {
font-size : 80%;
font-family : MS Pゴシック;
font-weight : normal;
}
h2 {
padding : 1rem 2rem;
color : #000000;
background : #eaf4fc;
border-left : solid 10px #164a84;
margin-top : 20px;
}
table {
width : 100%;
margin-top : 10px;
margin-left : auto;
margin-right : auto;
vertical-align : middle;
border-collapse : collapse;
table-layout : fixed;
}
th, td {
border-top : 1px solid #666;
border-bottom : 1px solid #666;
vertical-align : middle;
padding : 8px;
}
table thead tr th {
color : #ffffff;
font-size : 20px;
border : 1px solid #ffffff;
background-color : #274a78;
height : 30px;
text-align : center;
vertical-align : middle;
}
iframe {
width : 100%;
height : 100%;
}
table th:nth-of-type(1){
width : 30%;
}
table th:nth-of-type(2){
width : 15%;
}
table th:nth-of-type(3){
width : 5%;
}
table th:nth-of-type(4){
width : 5%;
}
td {
text-align: center;
width : 55%;
}
.container_et table td:nth-of-type(1){
font-size : 18px;
font-weight : bold;
}
"""
with open("類似youtube.css", "w") as f:
f.write(css)
HTML作成
HTML化を行います。
実装してみた感想としては、DataFrameのHTML化とMultiIndexは非常に相性が悪いなと思いました。
MultiIndexのため、見出しのtrが2行に分かれますが、colspanが設定されないため見栄えが悪いです。
そのため、見出しのtr箇所については、コード上で作り直して置換しています。
# HTML作成
from xml.sax.saxutils import unescape
from IPython.display import HTML
html_template = """
<!doctype html>
<html lang="ja">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<link rel="stylesheet" type="text/css" href="類似youtube.css" /
</head>
<body>
<script src="https://code.jquery.com/jquery-3.2.1.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js"></script>
<h2>対象データ</h2>
<div class="container_t">
{0}
</div>
<h2>類似データ</h2>
<div class="container_et">
{1}
</div>
</body>
</html>
"""
# テーブルヘッダの置換
def get_tableTr(tableList, thead_template):
fmtTable = ''
isReplaceFlg = False
isEndFlg = False
for item in tableList:
if '<thead>' in item:
fmtTable = fmtTable + item + '\n'
isReplaceFlg = True
elif '</thead>' in item:
fmtTable = fmtTable + item + '\n'
isReplaceFlg = False
elif isReplaceFlg == False:
fmtTable = fmtTable + item + '\n'
if isReplaceFlg and not isEndFlg:
fmtTable = fmtTable + '<tr>\n' + ''.join(thead_template) + '</tr>\n'
isEndFlg = True
return fmtTable
# 対象データ
# HTML用のDataFrame作成
# タイトル
df_title_base_target = pd.DataFrame(select_df_target.loc[:, ['title', 'url', 'comment', 'get1']], columns=['title', 'url', 'comment', 'get1']).reset_index(drop=True).rename(columns={'get1':'get'})
df_title_target = pd.concat([df_title_base_target, df_title_feature_target], axis=1)
# 字幕
df_subTitle_base_target = pd.DataFrame(select_df_target.loc[:, ['title', 'url', 'comment', 'get2']], columns=['title', 'url', 'comment', 'get2']).reset_index(drop=True).rename(columns={'get2':'get'})
df_subTitle_target = pd.concat([df_subTitle_base_target, df_subTitle_feature_target], axis=1)
# 表示データ作成
df_display_target = pd.concat([df_title_target, df_subTitle_target])
df_display_target = df_display_target.set_index(['title', 'url', 'comment', 'get'], append=True)
# HTML作成
# ヘッダ列作成
headClm_target = [name for name in df_display_target.index.names if name != None]
headClm_target = np.append(headClm_target, df_display_target.columns.values)
thead_template_target = ['<th>' + str(th) + '</th>\n' for th in headClm_target]
# テーブル作成
df_html_target = df_display_target.droplevel(0).fillna('')
table_target = df_html_target.to_html(classes=["table", "table-bordered", "table-hover"])
table_target = unescape(table_target).replace('<tr style="text-align: right;">', '<tr>').replace('border="1" ', '')
tableList_target = table_target.split('\n')
fmtTable_taget = get_tableTr(tableList_target, thead_template_target)
# 対象外データ
# HTML用のDataFrame作成
# タイトル
df_title_base_except_target = pd.DataFrame(df_similarity.loc[:, ['title', 'url', 'comment', 'get1']], columns=['title', 'url', 'comment', 'get1']).reset_index(drop=True).rename(columns={'get1':'get'})
df_title_except_target = pd.concat([df_title_base_except_target, df_title_feature_except_target], axis=1)
# 字幕
df_subTitle_base_except_target = pd.DataFrame(df_similarity.loc[:, ['title', 'url', 'comment', 'get2']], columns=['title', 'url', 'comment', 'get2']).reset_index(drop=True).rename(columns={'get2':'get'})
df_subTitle_except_target = pd.concat([df_subTitle_base_except_target, df_subTitle_feature_except_target], axis=1)
# 表示データ作成
df_display_except_target = pd.concat([df_title_except_target, df_subTitle_except_target])
df_display_except_target = df_display_except_target.set_index(['title', 'url', 'comment', 'get'], append=True)
# HTML作成
# ヘッダ列作成
headClm_except_target = [name for name in df_display_except_target.index.names if name != None]
headClm_except_target = np.append(headClm_except_target, df_display_except_target.columns.values)
thead_template_except_target = ['<th>' + str(th) + '</th>\n' for th in headClm_except_target]
# テーブル作成
df_html_except_target = df_display_except_target.sort_index().droplevel(0).fillna('')
table_except_target = df_html_except_target.to_html(classes=["table", "table-bordered", "table-hover"])
table_except_target = unescape(table_except_target).replace('<tr style="text-align: right;">', '<tr>').replace('border="1" ', '')
tableList_except_target = table_except_target.split('\n')
fmtTable_except_taget = get_tableTr(tableList_except_target, thead_template_except_target)
# HTML生成
html = html_template.format(fmtTable_taget, fmtTable_except_taget)
with open("類似youtube.html", "w") as f:
f.write(html)
# CSSファイル読み込み
cssFile = open('/content/類似youtube.css', 'r')
css = '<style>\n' + cssFile.read() + '</style>\n'
cssFile.close()
# 表示
HTML(css + html)
上記を実行すると以下の結果が表示されます。
urlでiframeを設定したため、YouTubeが埋め込まれていることが確認できます。(もちろん再生もできます)
途中で切っていますが、類似データは10件表示されています。
10. 図での表示
HTML化して上位10件の類似データはどういった動画が取得され、どういった特徴があるかの視覚化は行えましたが、全体データから見て上位10件の類似データがどういったデータなのかは分かりません。
図で対象データ、上位10件の類似データ、それ以外のデータを表示し、視覚化します。
x軸にindexを指定し、y軸に「9. 類似度算出/感情分析の対象外データの3. 上位10件取得」で取得した類似度を設定します。
# 図での出力
import numpy as np
import matplotlib.pyplot as plt
from operator import itemgetter
# 図表示用のデータ作成
# 全件
x_subTitle = list(range(0, len(similarity), 1))
y_subTitle = np.array(similarity)
# 対象データ
x_subTitle_target = df_target.index.values
y_subTitle_target = np.array(similarity[df_target.index.values])
# 類似度上位データ
x_subTitle_except_target = topData
y_subTitle_except_target = itemgetter(*topData)(similarity)
# 図設定
plt.figure(figsize=(30, 5))
plt.title('SubTitles')
plt.xlabel('index')
plt.ylabel('similarity')
plt.grid(True)
# 図表示
plt.scatter(x_subTitle, y_subTitle, s=30, marker='.', label='exceptTarget')
plt.scatter(x_subTitle_target, y_subTitle_target, s=100, color='red', label='target')
plt.scatter(x_subTitle_except_target, y_subTitle_except_target, s=100, color='orange', label='similarity')
plt.legend(loc='upper left', labelspacing=1, prop={'size':10,})
plt.show()
上記を実行すると以下の図が表示されます。
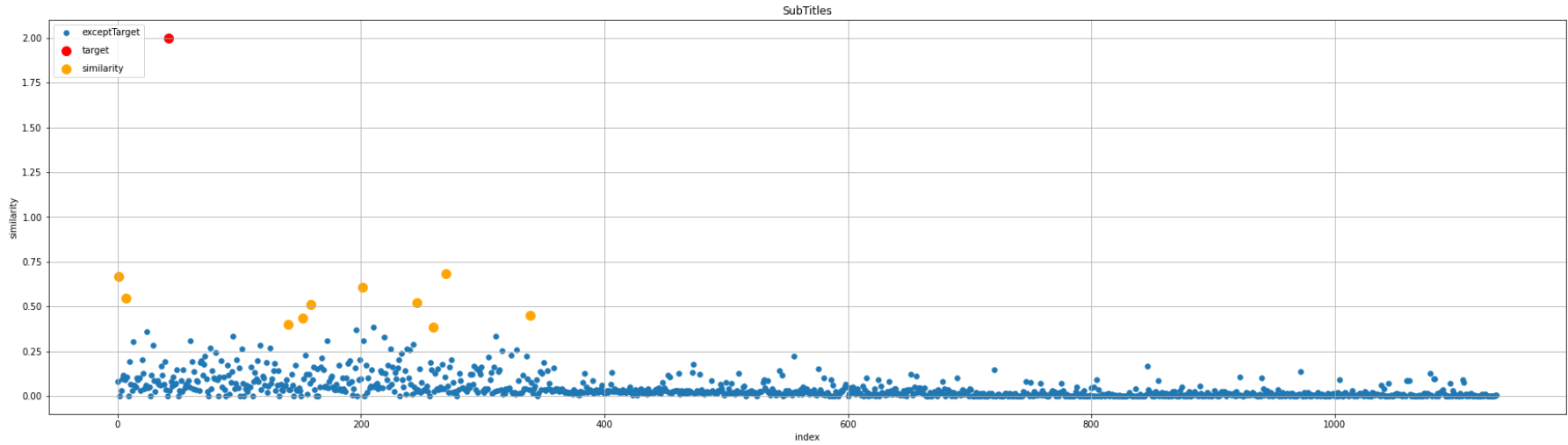
赤色の点が対象データ、オレンジ色の点が上位10件データ、青色の点が全件です。
図をみると、全件データの中でも類似度の高いデータが抽出されているのが分かります。
実行結果
作成した分析システムを使用して、実行結果の比較を行ってみます。
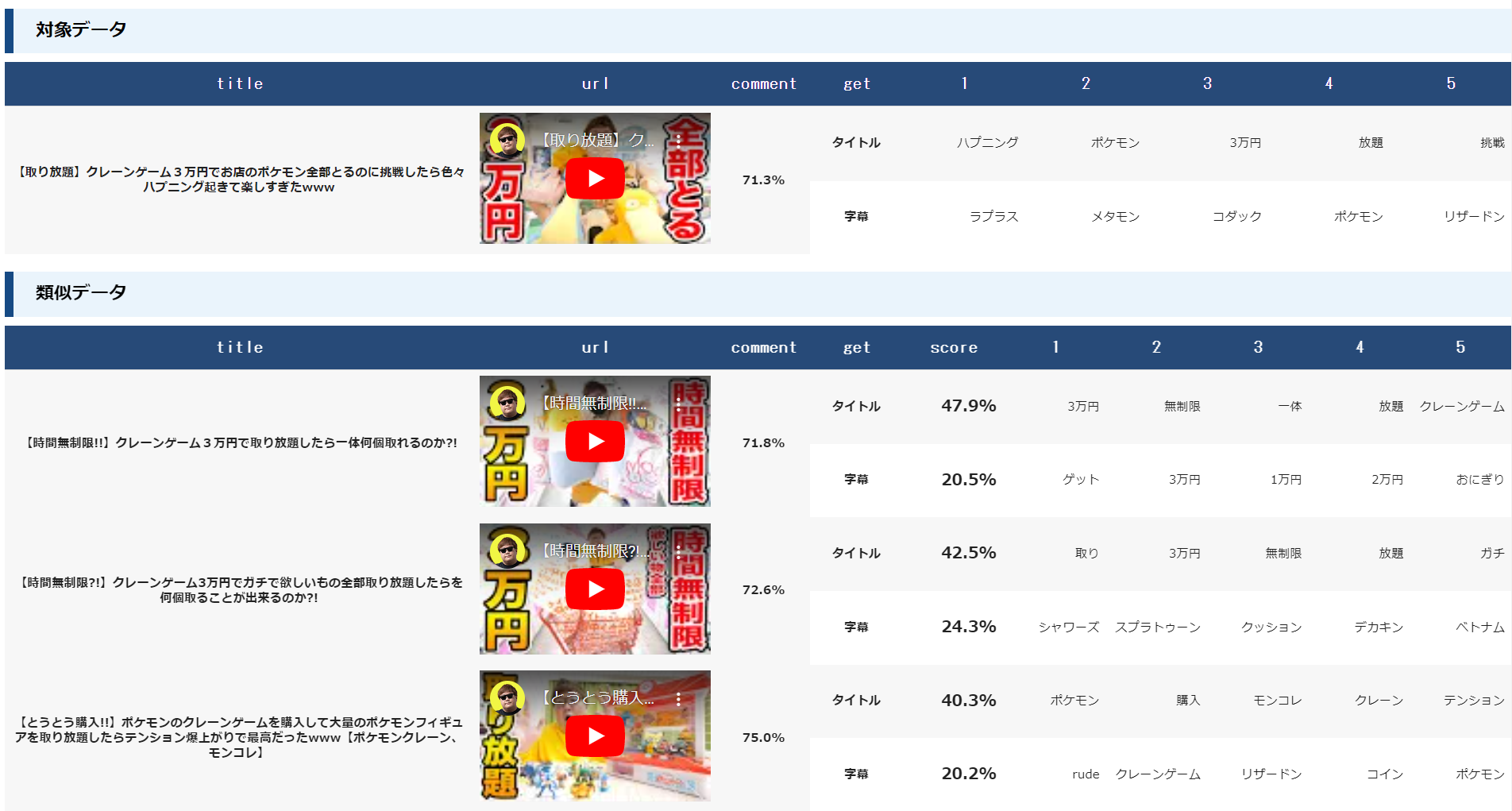
対象データ
対象データは以下の通りです。
タイトルや字幕を見た限りでは、クレーンゲームやポケモン関連の単語が設定されている動画が上位結果になりそうかなと予想しました。

タイトル・字幕で類似度算出
タイトルと字幕どちらも類似度算出の対象とします。
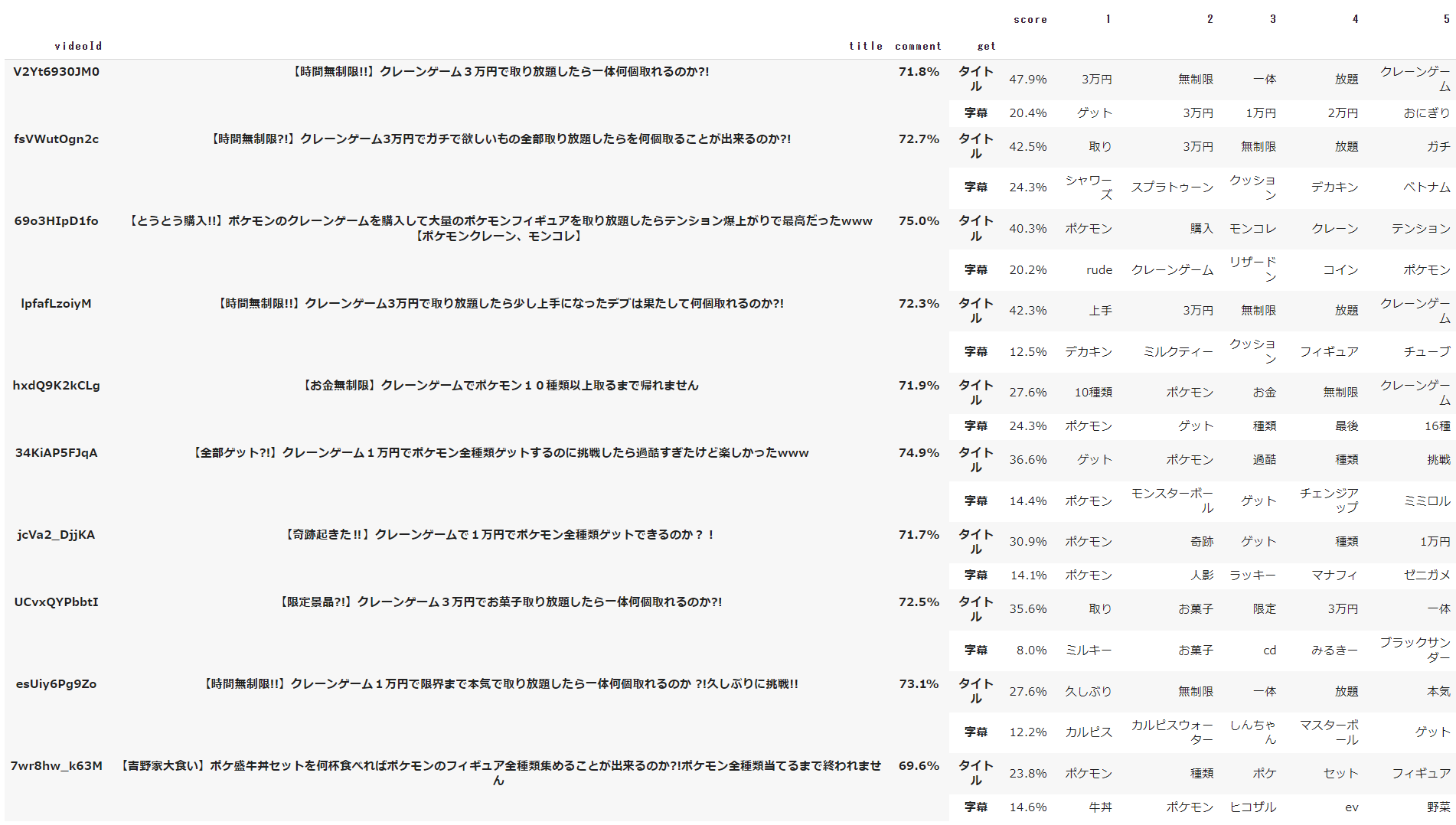
1位と2位の結果をみると、クレーンゲームと3万円企画の動画が取得されています。
3位はクレーンゲームとポケモンといった、対象データと似た単語の動画が取得されています。
4位になると、再びクレーンゲームと3万円企画の動画が取得され、5位~7位になるとクレーンゲームとポケモンの動画が取得されています。
上記をふまえると、クレーンゲームと3万円企画を行っていて、字幕内にポケモン関連の単語が存在する場合、上位結果として挙げられるようです。
試しに1位の動画と4位の動画を見てみましたが、1位の動画ではポケモン関連のグッズが登場していましたが、4位の動画ではポケモン関連のグッズは登場していませんでした。
この結果からみるに、ベクトルの特徴量の高さとして クレーンゲーム ≧ 3万円企画 > ポケモン とはなりますが、字幕内にポケモン関連の単語がない、もしくは少ない場合、順位が落ちることが分かりました。
図としては、類似度の高い動画が取得されていることが分かります。
DataFrame
図
タイトルのみで類似度算出
タイトルのみ類似度算出の対象とします。
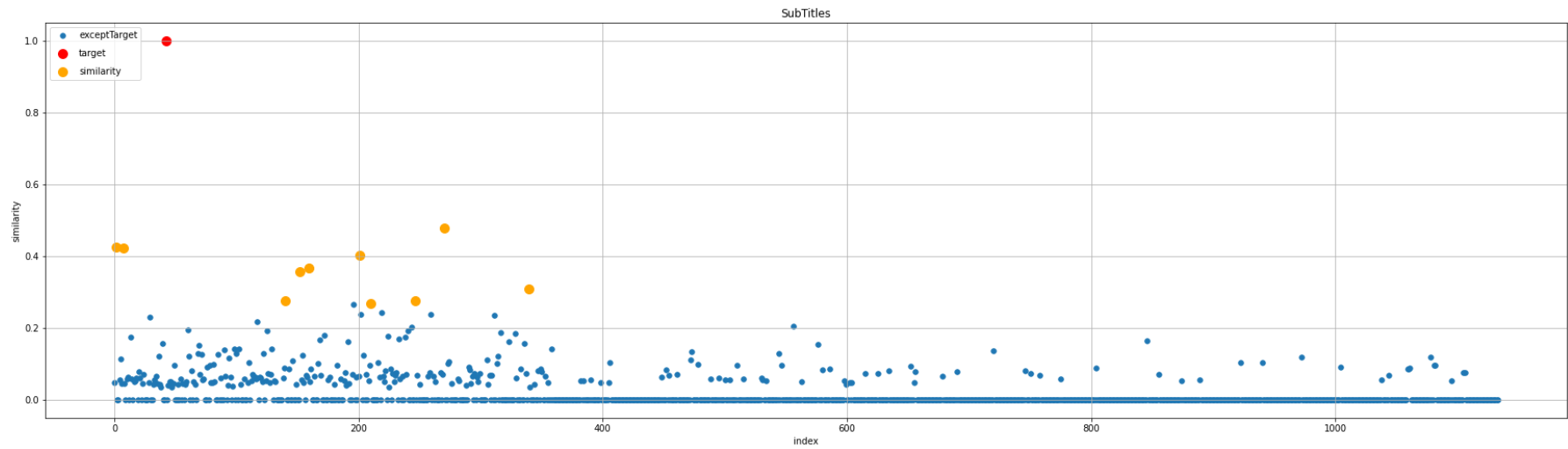
タイトル・字幕で類似度算出した際の結果と比べると3位と4位の結果が逆になっています。
3位と4位の違いは字幕内にポケモン関連の単語があるか、ないかの違いとなります。
ベクトルの特徴量の高さとしては、クレーンゲーム ≧ 3万円企画 > ポケモン のため、字幕を類似度算出の対象としない今回は順位が逆になります。
また、5位と7位はほぼ同じ動画タイトルですが「www」の違いがあります。
今回の対象動画のタイトルに「www」がはいっているため、「www」が動画タイトルとして設定されている分、順位が上となること分かります。
図としては、タイトル・字幕で類似度算出した時と同様、類似度の高い動画が取得されていることが分かります。
DataFrame

図
字幕のみで類似度算出
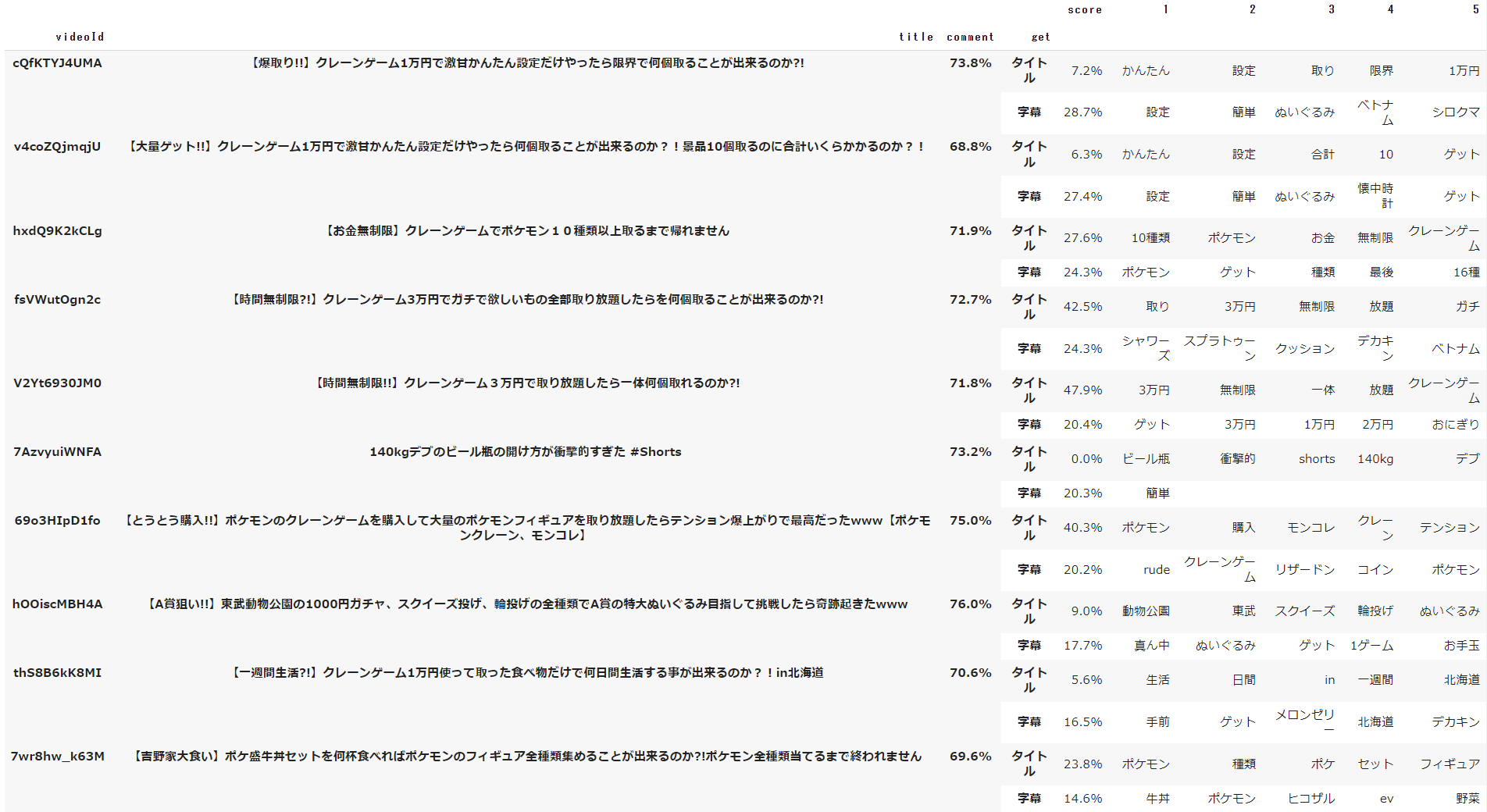
字幕のみ類似度算出の対象となります。
今までの取得結果と全く異なる動画が1位、2位となっていて、今まで1位だった動画は5位にまで落ちています。
対象データでは、クレーンゲームにある「かんたん設定」を使用する箇所があるのですが、1位、2位の動画を見るとどちらも「かんたん設定」を使用しています。
上記をふまえると、字幕内のベクトル特徴量の高さは 簡単 = かんたん ≧ 設定 > クレーンゲーム ≧ 3万円企画 > ポケモン になっていることが分かります。
「簡単」や「設定」という単語の点数が高いため、6位の動画はクレーンゲームやポケモンという単語が一切ないにも関わらず、6位に挙げられています。
また、3位~5位を確認すると、字幕の中で特徴量の高いポケモン関連の単語があるかどうかで順位が変動していることが分かります。
図としては、タイトル・字幕で類似度算出した時と同様、類似度の高い動画が取得されていることが分かります。
DataFrame
図
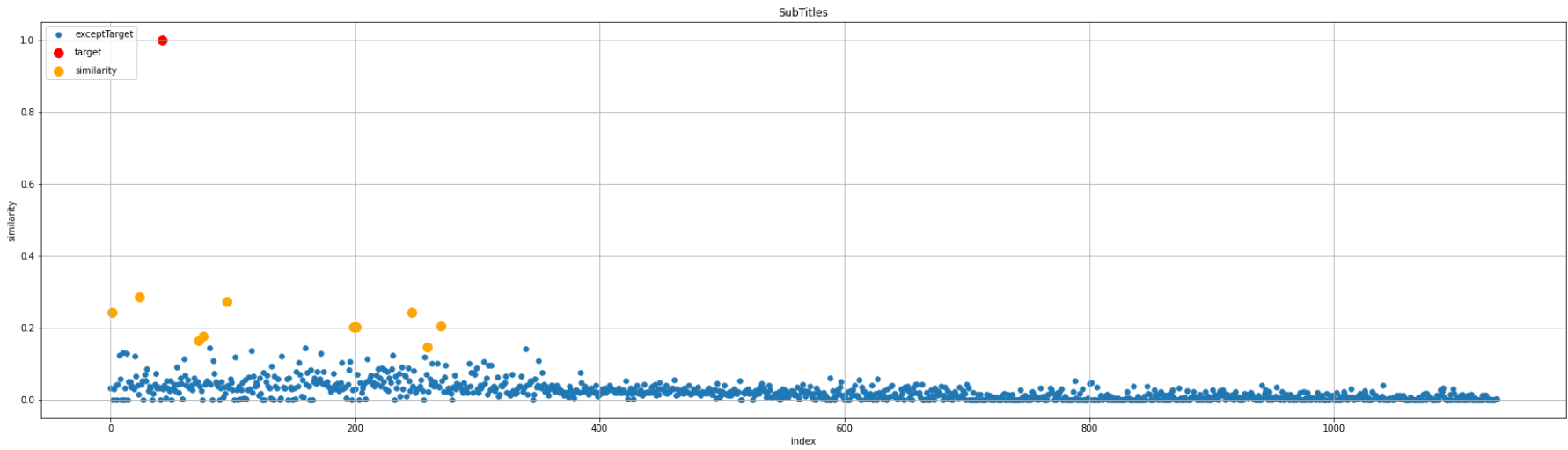
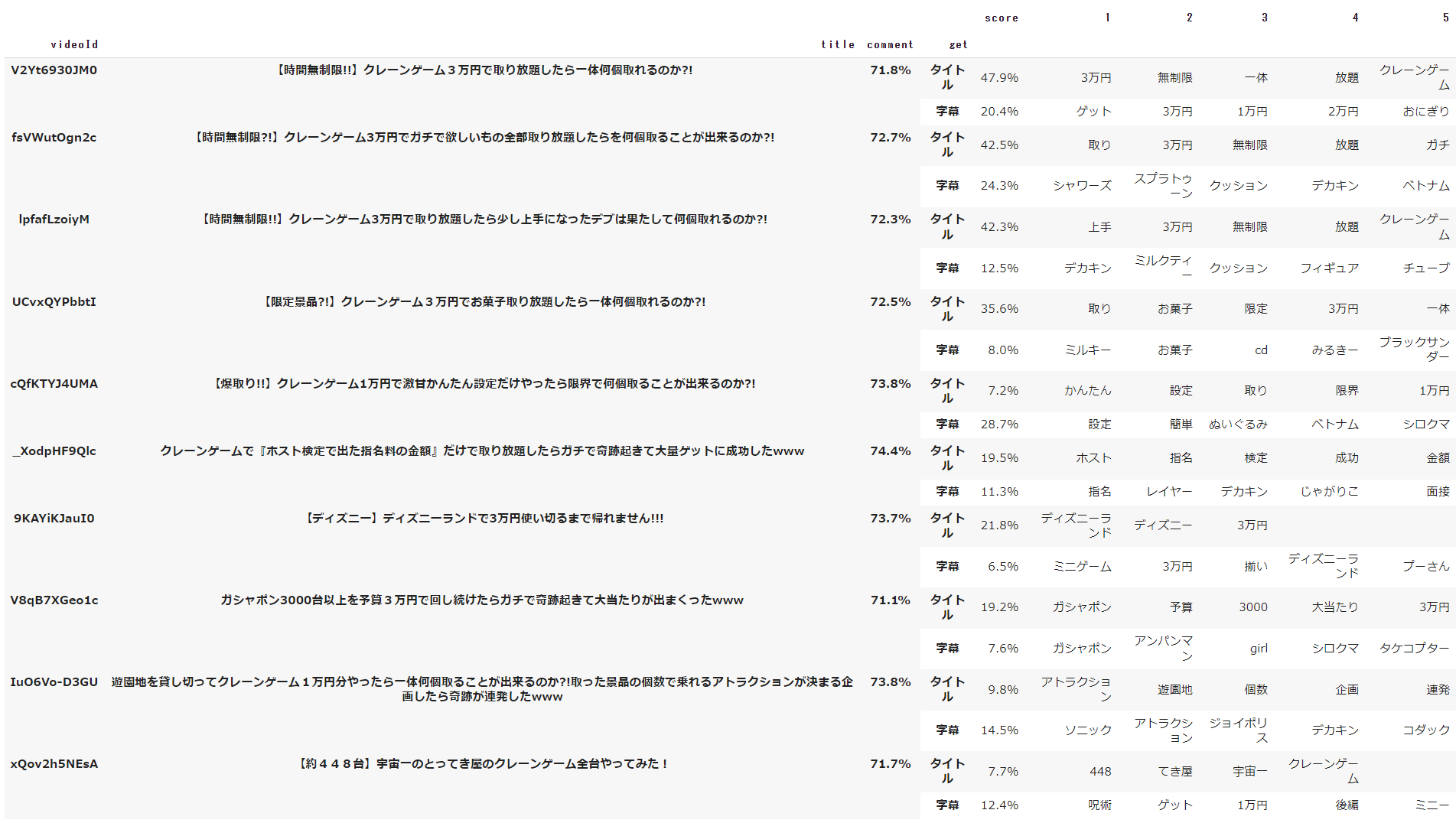
単語を指定して類似度算出
タイトルと字幕どちらも類似度算出の対象としますが、「3万円」という単語がタイトル、もしくは、字幕に設定されている動画のみを取得します。
1位、2位はタイトルと字幕どちらも類似度算出した結果と同じですが、3位の結果が異なります。
タイトルと字幕どちらも類似度算出した際の3位の動画には、3万円という単語が存在しなかったため、今回は対象外となっていることが確認できました。
図としては、単語を指定した場合、類似度が低くても上位10件の対象となることが分かります。
DataFrame
図
結果
試してみた結果ですが、対象データと類似した動画を探す場合は、基本的にタイトルと字幕どちらも類似度算出の対象としたほうが良いかなと思いました。
また、単語を指定して類似度算出が個人的には便利に感じました。
YouTubeの単語検索は、おそらく動画内の字幕まで検索していないため、タイトルや動画詳細だけでは抜けてしまう動画も対象にできるのが非常に良かったです。
最終的な結果
この分析システムを作るにあたり、最初に掲げた目標は以下の通りでした。
- YouTubeの字幕を取得し、動画のキーワードや感情を抽出する
- 好みの動画を1つ選択した場合に、同じような特徴を含む動画を3つほど挙げる
- 感情分析での類似度や、動画字幕での類似度を算出する
- 好きか嫌いかを実際に選択することで、より好みにあった動画を挙げるようにする
結果はこうなりました。
- 〇 : YouTubeの字幕を取得し、動画のキーワードや感情を抽出する
- 〇 : 好みの動画を1つ選択した場合に、同じような特徴を含む動画を3つほど挙げる
- △ : 感情分析での類似度や、動画字幕での類似度を算出する
- ✕ : 好きか嫌いかを実際に選択することで、より好みにあった動画を挙げるようにする
YouTubeの字幕を取得し、動画のキーワードや感情を抽出する
YouTubeのタイトル、字幕から動画のキーワードを取得し、コメントから感情分析を行いました。
字幕でBERTを使ってみたり、動画全件のコメントに対してBERTを使ってみましたが、1件につき1分以上かかるため、1000件以上の動画を分析するには時間がかかりすぎるということで今回は実装しませんでした。
調査すればBERTで膨大な処理を行う方法が実装できたのかもしれませんが、簡単に調査した限りでは有用な情報を見つけることができませんでした。
また、BERTはまだまだ手探り状態だったため、今回は上位10件と対象データのみに限り実装を行いました。
上記以外の点では、実装したかったことを実装できたかなという気がしています。
好みの動画を1つ選択した場合に、同じような特徴を含む動画を3つほど挙げる
当初、上位3件程を取得する予定でしたが、上位3件だと類似度算出の対象をタイトルだけ、字幕だけ、と絞った時に差が分かり難かったため、10件としました。
分析結果を調査するには10件程候補が欲しいですが、単純に似た動画を知りたいなと思った時は3件程でいい気もするので、疑似フォームで何件取得するかを選べるようにするのもいいかなと思いました。
基本的には、タイトルと字幕の両方で類似度判定するのが、自分の想像していた分析結果に近い気がします。
感情分析での類似度や、動画字幕での類似度を算出する
上の方でも記載しましたが、1000件以上の動画を分析するには時間がかかりすぎるということで、今回はBERTの使用範囲をかなり絞りました。
できることなら、BERTの学習を行い、カスタマイズされた状態で結果を出したかったのですが、時間が足りませんでした。
ただ、個人的にはBERTを使えたので満足ではあります。
また、BERTの感情分析はネガポジ分析なので、ML-Askを使用し、10種類の感情分析もしてみたかったなというのが少し心残りです。
好きか嫌いかを実際に選択することで、より好みにあった動画を挙げるようにする
この実装の目的としては、ディープラーニングを使用したかったという背景があります。
ただ、講師陣に相談した際、アプリで実装できるねと言われてしまったので、今回は実装対象外としました。(時間もそこまでなかったですし)
今回取得した結果で出来ることといえば、今後どのような動画が投稿されるかの予測ができるかなという気がしています。
感想
開発に関して
この分析システムは2月10日頃から取り掛かり、3月18日辺りに完成しました。
だいたい期間としては1ヶ月と少しで、開発にかかった時間は正直分かりません。
平日は20時、21時から23時まで、休日は1日開発していたこともあれば、平日と同じ時間開発していたこともあります。
1日2時間換算とすると 2 × 37 の74時間程度なので、だいたい80時間~100時間くらいかと思われます。
開発は基本的にめちゃくちゃ楽しかったです。
pythonや分析システム自体初めてだったため、実装したいゴールはあるのに、どう実装すればいいか分からなくて方法を調べているときは、少し辛かったです。
まあ、初めての言語を触る際は誰しも通る道ではあると思いますが。
ただ、実装方法が分かって、自分なりにコードをカスタマイズしたり、結果が表示できるようになると成長を実感しましたし、二度目になりますが楽しかったです。
「最終的な結果」にも記載しましたが、この分析システムを作る際に自然言語処理とディープラーニングを使ってみたいと思って始めました。
(分析のさわりを学習して、面白いと思ったのがこの2つだったからです)
結果的に自然言語処理についてはだいぶ原理が分かりましたが、ディープラーニングについてはまだまだ分からないことだらけです。
学習に必要なデータを取得する処理までは作れたので、このデータを学習し、次にどの動画が投稿されるかを予測したり、どういうコメントがつきやすいか予測したり、できることは色々とあるので、やる気がある時にでも作っていこうかなと思っています。
開発環境や技術革新に関して
今回、Google Colaboratoryを使用して分析システムを作成しました。
Google Colaboratory自体は使いやすいのですが「参考資料を探す」という点においては割と苦労しました。
実装方法は記載されているが、実際にGoogle Colaboratoryで行ってみると動かない、ということが多々あり、その都度、解決方法を探すのに時間を費やしました。
また、技術の廃れの速度にも驚きました。
特に詰まったのはBERTで感情分析をする際に、使用例を調べるのですが、大多数のサイトでモデルに「daigo/bert-base-japanese-sentiment」を指定しています。
しかし、今、「daigo/bert-base-japanese-sentiment」を使用するとエラーになります。
その原因がなかなかつかめず、かつ理由を記載しているサイトもなく、python初心者ではエラーの内容もよく分からず、大変苦労しました。
結果、Hugging Faceに「daigo/bert-base-japanese-sentiment」というmodelがなくなっていることをようやく見つけ、最終的に異なる「bert-base-japanese-sentiment」のモデルを使用するよう変更しました。
上記はあくまで一例で、バージョンによって使えないコードがあったりということは何度かありました。
今まで使用していた言語で、1年前に記載した記事が現行の環境で使えなくなっているという事象に出会ったことがなかったため、非常に衝撃を受けました。
きっと、この記事も1年後にはエラーになっている箇所があるんだろうなあと思うと、技術革新や、廃れの速度がとんでもなく早いなと思う次第です。
なるべく追いついていきたいですが、ようやく「なんとなく分かる」「なんとなく自分で作れる」というところまで成長できたので、引き続き理解しながら学んでいきたいと思います。
参考資料
今回の分析システムを作るにあたり非常に多くの方の記事を参考にしました。
ありがとうございました。
- デカキンさんのチャンネル
- 形態素解析
- Mecab
- NEologd
- Google SpreadSheet
- ユーザー辞書
- チャンネルID
- YouTubeAPIキー
- YouTube Data API
- YouTube字幕取得
- YouTubeコメント取得
- DataFrame
- 正規化
- ストップワード除去
- tf-idf
- 疑似フォーム作成
- Transformer
- BERT
- MultiIndex
- COS類似度
- CSS
- HTML化