はじめに
先日から河川水位と雨量のデータを読み込む記事を投稿していましたが、いろいろなご意見を頂き、今回はその二つのデータを重ねてみたいと思います。
また、先日の豪雨の様子も同時にわかるであろうと考えると、結構タイムリーかなとも思っています。
データ読込
これまで作成した以下の記事をもとにそれぞれのデータを読み込む関数を作成します。
# ライブラリ
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL内の特定のタグを取得
def get_tag_from_html(urlName, tag):
url = requests.get(urlName)
soup = BeautifulSoup(url.content, "html.parser")
return soup.find_all(tag)
# カタログページからデータページのURLを取得
def get_page_urls_from_catalog(urlName):
urlNames = []
elems = get_tag_from_html(urlName, "a")
for elem in elems:
try:
string = elem.get("class")[0]
if string in "heading":
href = elem.get("href")
if href.find("resource") > 0:
urlNames.append(urlBase + href)
except:
pass
return urlNames
# データページからCSVのURLを取得
def get_csv_urls_from_url(urlName):
urlNames = []
elems = get_tag_from_html(urlName, "a")
for elem in elems:
try:
href = elem.get("href")
if href.find(".csv") > 0:
urlNames.append(href)
except:
pass
return urlNames[0]
# 取得したCSVのデータを加工
def data_cleansing(df):
print("set timestamp as index.")
df.index = df["観測所"].map(lambda _: pd.to_datetime(_))
df = df.sort_index()
print("replace words to -1.")
df = df.replace('未収集', '-1')
df = df.replace('欠測', '-1')
df = df.replace('保守', '-1')
print("edit name of columns.")
cols = df.columns.tolist()
for i in range(len(cols)):
if cols[i].find("name") > 0:
cols[i] = cols[i-1] + "_累積"
df.columns = cols
print("change data type to float.")
cols = df.columns[1:]
for col in cols:
df[col] = df[col].astype("float")
return df
# 雨量データの取得
def get_rain_data():
urlName = urlBase + "/db/dataset/010009"
urlNames = get_page_urls_from_catalog(urlName)
urls = []
for urlName in urlNames:
urls.append(get_csv_urls_from_url(urlName))
df = pd.DataFrame()
for url in urls:
# 10分毎データのみを対象とする
if url.find("10min") > 0:
df = pd.concat([df, pd.read_csv(url, encoding="Shift_JIS").iloc[2:]])
return data_cleansing(df)
# 河川水位データの取得
def get_level_data():
urlName = urlBase + "/db/dataset/010010"
urlNames = get_page_urls_from_catalog(urlName)
urls = []
for urlName in urlNames:
urls.append(get_csv_urls_from_url(urlName))
df = pd.DataFrame()
for url in urls:
df = pd.concat([df, pd.read_csv(url, encoding="Shift_JIS").iloc[6:]])
return data_cleansing(df)
# ドメインのURLを設定
urlBase = "https://shimane-opendata.jp"
今回は雨量のデータにある降雨量と累積雨量の両方を使えるようにしています。
上記の関数を利用して、以下のように河川水位と雨量のデータを取得します。
df_rain = get_rain_data()
df_level = get_level_data()
可視化
準備
グラフで日本語が文字化けしないように準備をしておきます。
# 可視化の準備
!pip install japanize_matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
雨量
5つだけ抜粋してグラフ化してみます。
cols = df_rain.columns[1:]
df_rain[cols[:5]].plot(figsize=(15,5))
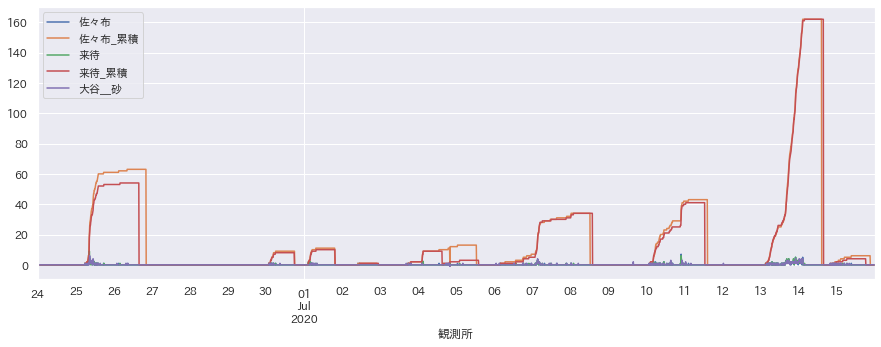
13日からの雨の量がとても多いことがわかります。
河川水位
同じようにいくつか抜粋してグラフ化してみます。
cols = df_level.columns[1:]
df_level[cols[:5]].plot(figsize=(15,5))
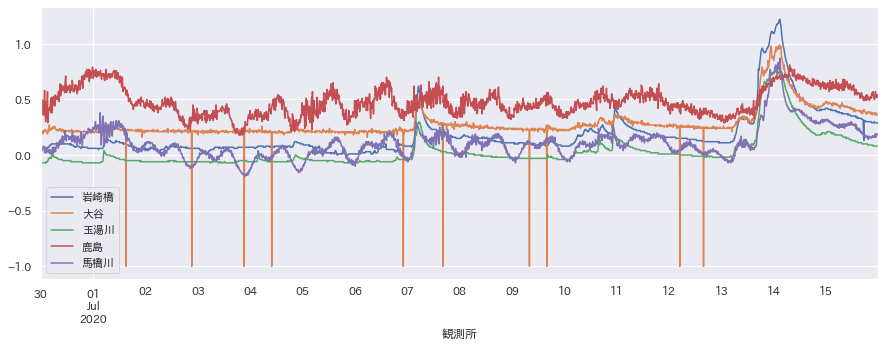
同じく、雨量が多いと水位も上昇していることがわかります。
重ね合わせ
データの日付情報において、河川水位と雨量の両方が存在する範囲を取得。
idx_min = df_rain.index.min()
idx_max = df_rain.index.max()
idx_min = idx_min if df_level.index.min() < idx_min else df_level.index.min()
idx_max = idx_max if df_level.index.max() > idx_max else df_level.index.max()
河川水位と雨量のデータについて、列名を指定して取得する関数を作成。
def get_marged_dataframe(cols_rain, cols_level):
df = pd.DataFrame()
df = df_rain[idx_min:idx_max][cols_rain]
new_cols = []
for col in cols_rain:
new_cols.append(col + "_雨量[mm]")
df.columns = new_cols
for col in cols_level:
df[col + "_水位[cm]"] = df_level[idx_min: idx_max][col] * 100
df.tail()
return df
上記の関数を使って、列名を指定してグラフ化する関数を作成。
def plot(cols_rain, cols_level):
df = get_marged_dataframe(cols_rain, cols_level)
# 全ての範囲を描画
df.plot(figsize=(15,5))
plt.show()
# 7月12日以降を描画
df["2020-07-12":].plot(figsize=(15,5))
plt.show()
適当な列を指定してグラフを描画。
cols_rain = ["松江_河_累積"]
cols_level = ["京橋川"]
plot(cols_rain, cols_level)

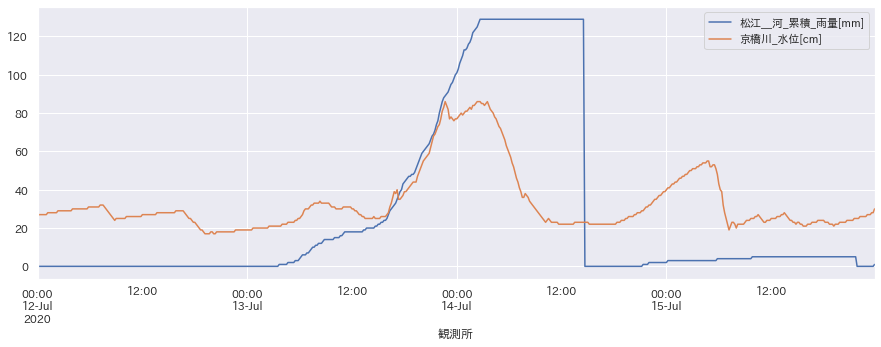
ここでは河川水位が雨量と相関のありそうな部分となさそうな部分にわかれているように見えます。
もしかすると、満潮時の増水などの影響が雨量より大きいのかもしれません。
また、雨量も一定レベルを超えると影響の出るようなものなのかもしれません。
...専門家ではないのではっきりわかんないですね。汗
なにはともあれ、データがあれば簡単に可視化し、別々のデータを重ねて検討できることがわかりました。
そういうニーズがある方がおられましたらご連絡お待ちしております!
また、もしデータを持っておられるのであれば同じように公開してもらえると色々できて楽しそうだなって思います。