はじめに
一昨日から引き続き、島根県さんの公開されているデータを使って何かできないかと考えていて、雨量データが広い範囲にわたって公開されているようなので、これを可視化してみました。
手順確認
公開ページの構成を見る
カタログページ
まず、カタログページがあります。
雨量ページ
カタログページの中に「雨量データ」のページがあります。
日別のデータページ
日別で10分おきに保存された雨量データがCSVで保存されているようです。
例えば、6月30日のデータをダウンロードしようと思うと以下のURLにアクセスします。
7月1日は...
あれ?
日別にURLが大きく異なります。
日別のCSV
さらにCSVのURLは...
はい、使いにく〜い!
手順
ということで、以下の手順で可視化作業を行ってみることにします。
- 雨量データのページから日別ページのURLを取得
- 日別のURLページからCSVのURLを取得
- 取得したCSVのURLからデータを取得
- データの加工
- 可視化
ちなみに、今回もColaboratoryを使用して実行します。
日別ページのURLを取得
以下のスクリプトで日別ページのURLを取得します。
import requests
from bs4 import BeautifulSoup
urlBase = "https://shimane-opendata.jp"
urlName = urlBase + "/db/dataset/010009"
def get_tag_from_html(urlName, tag):
url = requests.get(urlName)
soup = BeautifulSoup(url.content, "html.parser")
return soup.find_all(tag)
def get_page_urls_from_catalogpage(urlName):
urlNames = []
elems = get_tag_from_html(urlName, "a")
for elem in elems:
try:
string = elem.get("class")[0]
if string in "heading":
href = elem.get("href")
if href.find("resource") > 0:
urlNames.append(urlBase + href)
except:
pass
return urlNames
urlNames = get_page_urls_from_catalogpage(urlName)
print(urlNames)
CSVのURLを取得
以下のスクリプトでCSVのURLを取得します。
def get_csv_urls_from_url(urlName):
urlNames = []
elems = get_tag_from_html(urlName, "a")
for elem in elems:
try:
href = elem.get("href")
if href.find(".csv") > 0:
urlNames.append(href)
except:
pass
return urlNames[0]
urls = []
for urlName in urlNames:
urls.append(get_csv_urls_from_url(urlName))
print(urls)
URLからデータを取得してデータフレームを作成
上記で取得したURLからデータを直接読み込みます。
ただし、10分毎と1時間毎のCSVが混在しているので、ここでは10分毎のみを対象とします。
ちなみに、文字コードがShift JISになっていることに注意し、最初の2行にデータ以外の情報が入っているのでそれを除きます。
import pandas as pd
df = pd.DataFrame()
for url in urls:
if url.find("10min") > 0:
df = pd.concat([df, pd.read_csv(url, encoding="Shift_JIS").iloc[2:]])
df.shape
データの確認と加工
df.info()
上記を実行すると列の情報が取得できます。
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2880 entries, 2 to 145
Columns: 345 entries, 観測所 to Unnamed: 344
dtypes: object(345)
memory usage: 7.6+ MB
...345列もありますね。
ダウンロードしたデータをExcelで見てみると、一つの観測所につき10分雨量と累積雨量があり、累積雨量の列が空欄になっているということがわかりますので、累積雨量の列を除くことにします。
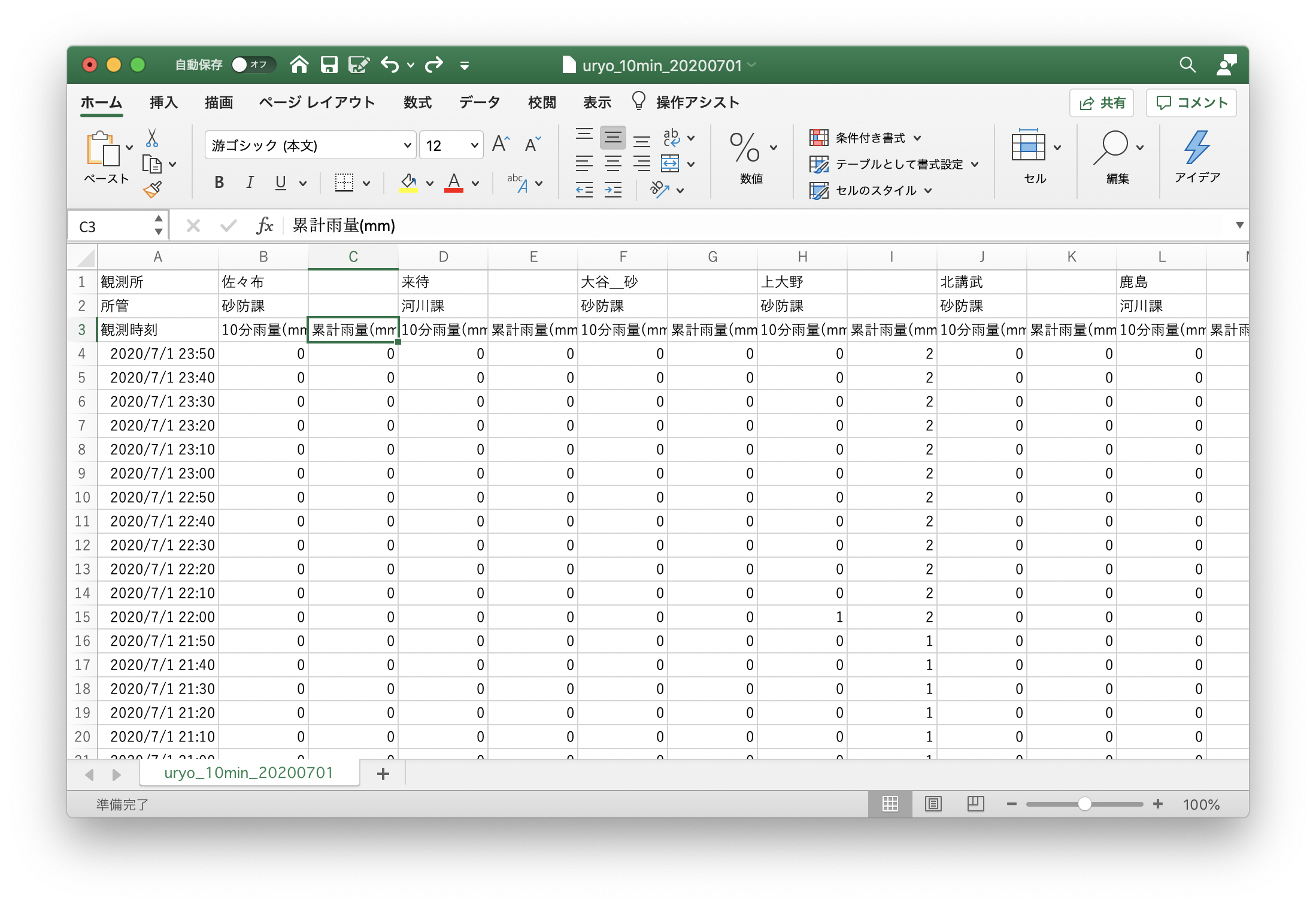
ちなみに、累積雨量の説明は以下のとおりです。
累積雨量とは、雨の降り始め時刻から降り終わり時刻までの雨量を累積したものです。
降り始めの定義は、雨量が0.0mmから0.5mm以上となった時点で、降り終わりの定義は、雨量がカウントされなくなってから6時間を超えた時とし、降り終わりの時点で累積雨量をリセットします。
みんなDtypeがobjectになっているから、数値データが文字列になっているみたい...
また、少し中を見てみると「未収集」「欠測」「保守」という文字列が入っているようです。
それらの文字情報を取り除いた上で実数値に変換します。
日時のデータも文字列なので、これもシリアル値に変換しないといけないですね。
ということで、以下のスクリプトを実行。
for col in df.columns:
if col.find("name") > 0:
df.pop(col)
df.index = df["観測所"].map(lambda _: pd.to_datetime(_))
df = df.sort_index()
df = df.replace('未収集', '-1')
df = df.replace('欠測', '-1')
df = df.replace('保守', '-1')
cols = df.columns[1:]
for col in cols:
df[col] = df[col].astype("float")
可視化
日本語表示がおかしくならないよう環境設定をしてからグラフを描画してみます。
!pip install japanize_matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
df[cols[:5]].plot(figsize=(15,5))
plt.show()
df["2020-07-12":][cols[:5]].plot(figsize=(15,5))
plt.show()
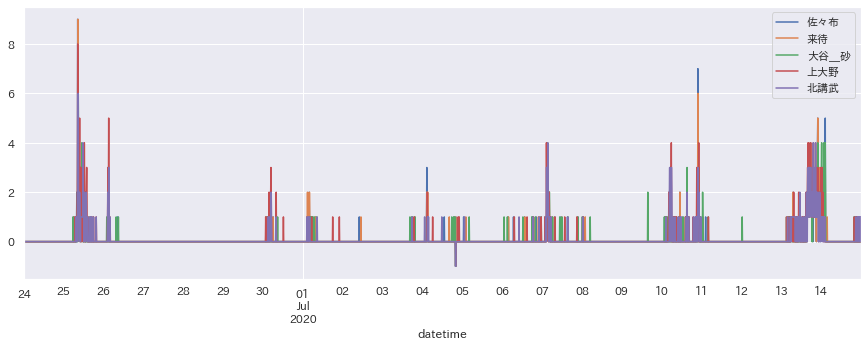
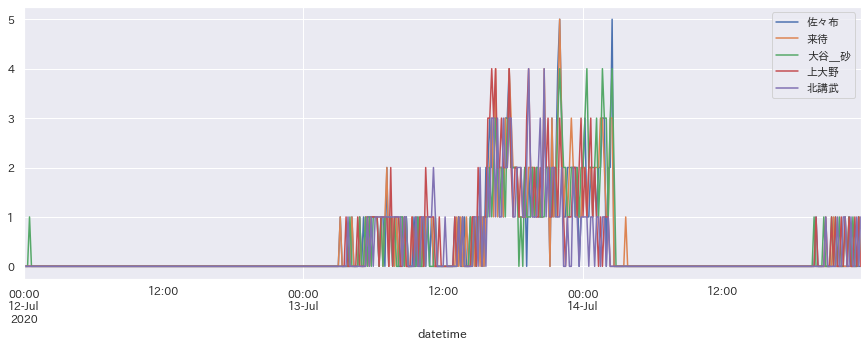
ここ数日の雨の様子が一目瞭然ですね。
さて、これから何をするかな〜。