この記事は「fukuoka.ex Elixir/Phoenix Advent Calendar 2019」17日目です。
昨日の「fukuoka.ex Elixir/Phoenix Advent Calendar 2019」は @zacky1972 さんの「どうやら Erlang をコンパイルした時のCコンパイラによって Elixir の性能がかなり異なるようだ」でした。
はじめに
本エントリーではElixirでディープラーニングフレームワークを作ってる時に発生したメモリ使用量の爆発に対する対応に関して簡単に書きました。
お前は誰だ?
去年の今頃からfukuoka.exに巻き込んで頂き、会社のYouTubeでElixirでのレイトレーサーの実装の話をしたり、今年はElixirConf JP2019でデータ構造の話をしてたElixirっぽくない(webが強いなのにCPUバウンドな処理ばかりな)話をする人です。現在、Elixirは「なにもわからない」フェーズです。いや、そうなのか?そうと信じたい。会社でもElixirを扱っている製品もありますが、僕はノータッチで仕事ではC++で音声認識エンジン周りの開発を行っています。Elixirは現状、あくまで趣味なので、ここでの見解や書いているコードは会社とは一切関係ありません。一応、防壁を張っておきます。
Elixirでディープラーニング
レイトレーサーの話をした時、ゼロから作るDeep Learningの内容をベースとしたフレームワークを作りながら学びたいと思っていました。言語を変えて書いたら更に理解は深まるんじゃないか、とか…しかし、Erlangの本とかも読んでますが、CGとかも分散処理に向いてる、と同時にErlang/Elixirに向いてない(大量の計算処理は得意じゃない的な)と書いてあり、”やっべ、レイトレーシング語っちゃったよ…"と、やってしまった感はあったのですが、まぁ、pythonにも勝ってたし!と思いDeep Learningフレームワークも作っています。今見るとあのレイトレーサー、全然関数型っぽくないですね…。
しかし、ディープラーニングでは速度全然で、結局の所、レイトレーサーでpythonに勝ってたのは純粋な浮動小数点演算だけを並列化して勝負したからで、行列演算になるとnumpyクソ強いです。C++でもフレームワーク作ったりしてますが、numpyの方が速いです。裏Cだしなぁ…。その辺の話は1/15の会社のピザパーティ兼セミナーで詳しく話したいと思います。今回は公開前のプロジェクトが対象なので、若干抽象度が高めかも知れませんが、ご容赦下さい。
ディープラーニングでのメモリ量
まず実行していた処理はCIFAR10という10種類のカテゴリの画像を当てる課題の学習です。
自分で作っている1/15公開予定のDLフレームワークで、使っていたモデルは
| Layer | 活性関数 | その他 | パラメータ数 |
|---|---|---|---|
| Convolution2D | ReLU | 3x3フィルター32, stride: 1, padding: 1 | 896 |
| Convolution2D | ReLU | 3x3フィルター32, stride: 1, padding: 1 | 9,248 |
| MaxPooling2D | - | stride: 2, padding: 0 | - |
| Dropout | - | ratio: 0.25 | - |
| Convolution2D | ReLU | 3x3フィルター64, stride: 1, padding: 1 | 18,496 |
| Convolution2D | ReLU | 3x3フィルター64, stride: 1, padding: 1 | 36,982 |
| MaxPooling2D | - | stride: 2, padding: 0 | - |
| Dropout | - | ratio: 0.25 | - |
| Affine | ReLU | 4320 x 512 | 2,216,160 |
| Dropout | - | ratio: 0.5 | - |
| Affine | Softmax | 512 x 10 | 5,632 |
Convolution2D が畳み込み層で Affine は全結合層、他はまぁ、ゼロから作るDeep Learningをご参照下さい(雑)。上記のような構成でElixirの浮動小数は倍精度なので、パラメータ一つに8バイト(64bit)使う感じになります。大体モデルだけで18MBとかなはずなんですが…。Forwardの処理からBackwardに持ち越す部分を多く見積もっても2倍の36MB程度+訓練データが全体で50000x3x28x28で900MB程度(これをシャッフルして100個取って4並列)でテストデータは1000x3x28x28。シャッフルで2倍になりそうなくらいで他はそこまで重くならないと思ってました。
観測した現象
Macのアクティビティモニタが…。
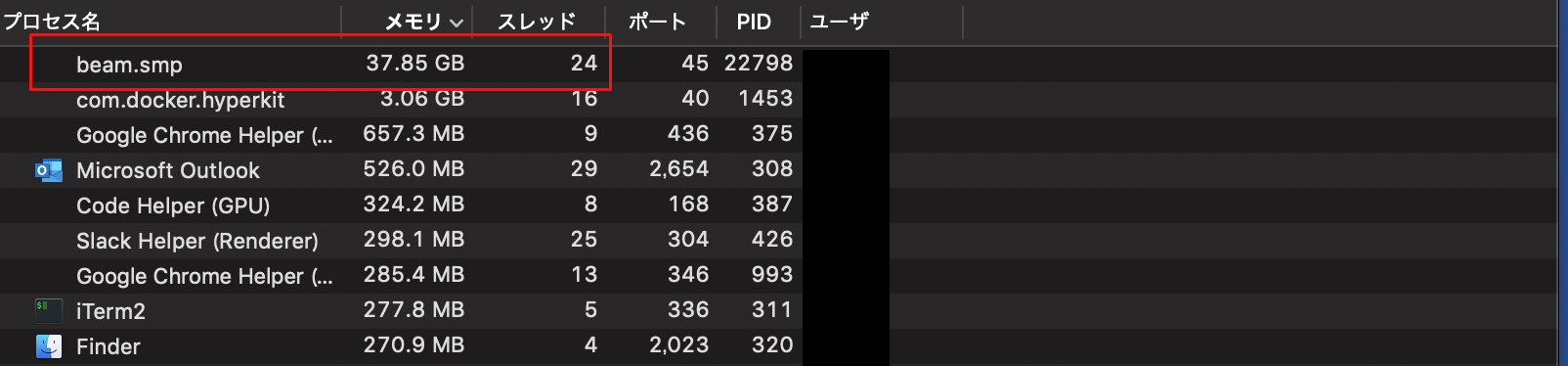
なんだこれ!!
ちなみに一時52GB行ってました。なかなか強いマシンです。
…そんなマシン持ってたか?!実際積んでるのは16GBなので、ほとんどスワップしてらっしゃる…。これで処理が進む気がしない。計算中は一番重いデータが、ミニバッチになってるものの各レイヤーの行列演算の過程の中間状態で膨らんでるんだと思いますが、徐々に増えるとは如何に。
メモリ状況の確認
さっそく、原因の特定作業に入りました。
:erlang.memory/1
幸いErlangではVMの状況を知る方法が多数提供されています。
最初に使ったのは :erlang.memory/1です。 :total でいけば取れるのでは?とやってみましたが、
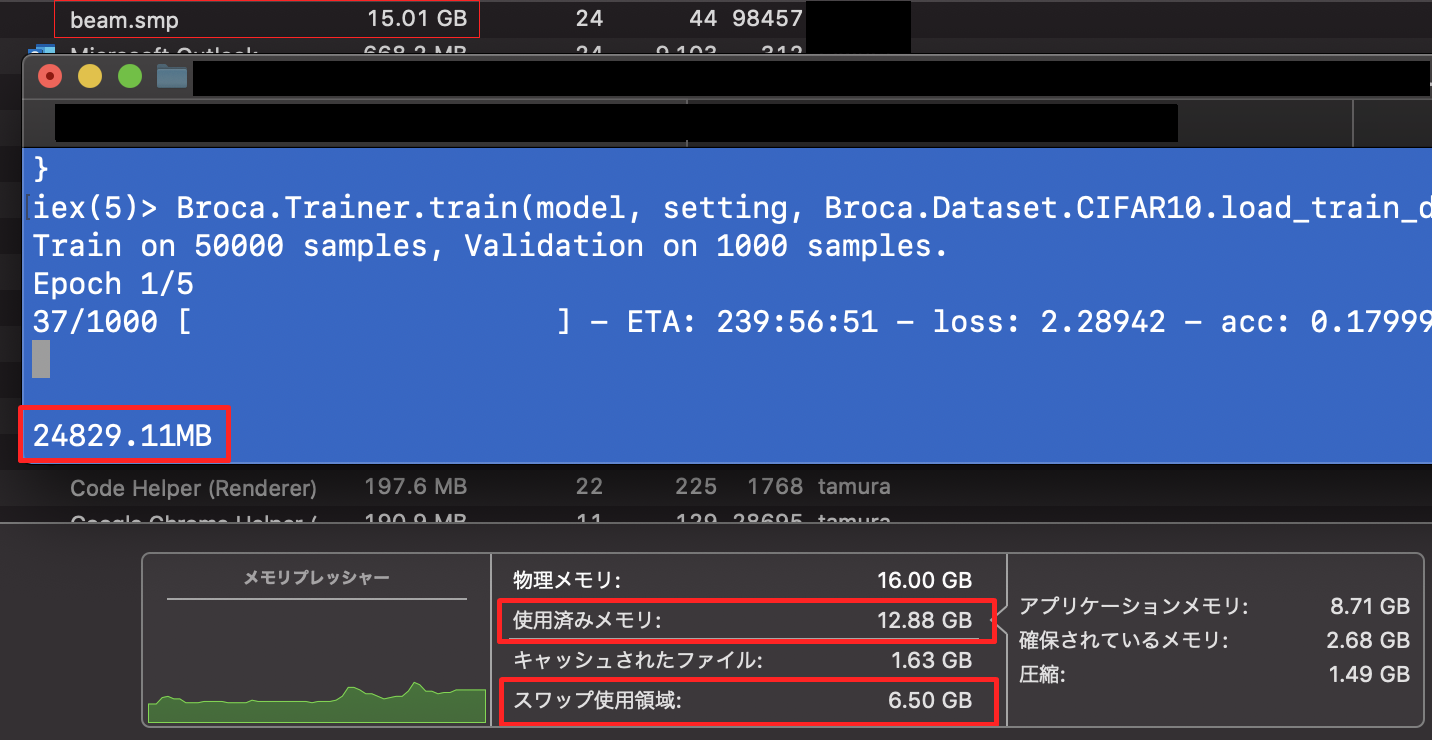
なんかOSとずれてんな、という感じのつぶやきをしたところ、
Erlang in Angerの5章に軽く解説があるので、読んでみるといいかもしれないです
— ずーみん (@okka0928) December 8, 2019
とのことで、Erlang in Anger読んでみました。ずーみんさんありがとうございます!
recon_alloc
ここで出ていたのが recon というツールで、調べたらElixirでも使えそう。システムツール的な役割なので、 hexdocsでも何やら趣が違います。
利用するにはまず、mix.exsに
defp deps do
[
...
{:recon, "~> 2.5.0", only: :dev}
]
end
で deps.get とかやって、今回はUtilとして下記のような非同期処理を入れました。
defmodule Util do
defmodule ProcessChecker do
defp loop(interval) do
usage = :recon_alloc.memory(:usage)
allocated = :recon_alloc.memory(:allocated)
details = :recon_alloc.memory(:allocated_types)
IO.puts(
" "
)
IO.puts(
" "
)
IO.puts(
"Usage: #{Float.floor(usage * 100, 1)}%, Allocated: #{Float.floor(allocated, 2)} MB, "
)
IO.puts(
"binary:#{Float.floor(details[:binary_alloc], 2)}, driver:#{
Float.floor(details[:driver_alloc], 2)
}, eheap:#{Float.floor(details[:eheap_alloc], 2)}, ets:#{
Float.floor(details[:ets_alloc], 2)
}, fix:#{Float.floor(details[:fix_alloc], 2)}, ll:#{Float.floor(details[:ll_alloc], 2)}, sl:#{
Float.floor(details[:sl_alloc], 2)
}, std:#{Float.floor(details[:std_alloc], 2)}, temp:#{
Float.floor(details[:temp_alloc], 2)
} \e[1A\e[1A\e[1A\e[1A"
)
Process.sleep(interval)
loop(interval)
end
def check(interval \\ 3000) do
:recon_alloc.set_unit(:megabyte)
loop(interval)
end
def run(interval) do
spawn(Broca.Util.ProcessChecker, :check, [interval])
end
end
end
テキトーにこんな感じ。3秒寝ては recon_alloc を呼び出す子です。
入力欄の2行下にメモリの使用状況を細かく出してくれます。ただし、タイミングで微妙に表示が残ってしまったりするので、どこかのタイミングで recon で取れる情報を自動でPhoenixにグラフィカルにフィードしてくれるツールとか作りたいなぁ、と思ったり。
現状、

こんな感じで、3秒おきにレポートしてくれます。カーソルずらすどうでもいい小技とか使ってます。
非同期なので、出力のタイミングが悪いと文字が残ってしまいます(なるべくホワイトスペースで潰そうとしましたが)。
メモリ問題を解決する
Erlang in Angerの情報から状況を把握したところ、Usageが90%以上なので、フラグメンテーションが起きてるというより純粋にメモリを消費してそう。参ったぞ。
関数型っぽくする
元々のフレームワークの動作として、各種Layer(ConvolutionとかAffineとか)が持ち回る必要があるデータを defstruct して、処理は Layer のprotocolとして forward, backward とパラメータを更新する update とかを各Layerモジュールに defimpl して呼び分けてた(そのまま関数呼ぶと戻りのモジュールの型がわからない)んですが、ちょっとオブジェクト指向の呪いが強いので、これを「変更されるパラメータ(重みやバイアス)」、「レイヤーに固有のパラメータ(フィルター数とか)」と「Forwardで作られるBackwardのみで必要なデータ」、「Optimizerに関するパラメータ」に分解してKeyword化、各Layerのモジュールはただの関数として処理を第一引数のatomでパターンマッチするようにしました。詳細は会社のセミナー(動画配信もあり)で話すつもりですが、結構これは効いたっぽいです。
これは仮説で、詳細は潜れていませんが、例えば
defstruct a: xx, b: xx, c: xx, d: xx,...
のようなモジュールがあったとして
t = %Test{t | c: xxx}
とした時に、 tは置き換えられますが、実態としては下の図の様になっています。

tが再バインドされているので置き換わってはいますが、この時にCはBからの繋がりがあるため使用されないものの参照があると見なされたままでメモリ上に残ってるのではないかと思います。もしそうだとすると構造体を使う際の更新は気を付けないといけないですね。
プロセスを切ってみる
これで多少の改善はあったものの、それでもメモリは少しずつ増加していました。
そこで、ElixirというかErlang的にプロセスが確保したメモリはプロセス終了時にVMでなくOSに返されるのはよく知られた話なので、プロセス切ってみました。候補はいくつかありましたが、戻りが必要な場合メッセージパッシングとかより Task が楽そうに見えました。
task = Task.async(Trainer, :iterate, [i, model, train_data, setting])
Task.await(task, :infinity)
非同期走らせた直後で await/2 を呼んでるのは本来の使い方と違う気もしますが…。
ちなみに、ここではそのまま結果を返してるので受け取っていませんが、await で非同期処理の結果が返ってきます。
結果
どこまで効果があるか測りきれていない暫定対応ではありますが、この2つを実装した結果、メモリ使用量が安定して、Taskが終わったタイミングでメモリがTask開始前と同じ状態になりました(厳密には一瞬変更前と変更後が共存するので2倍になりますが)。どちらも片方だと徐々に上がる状態だったので、短期的にでもスワップが発生しないようにするにはどちらも対応する必要のある要素だと思います。
まとめ
-
recon便利なので使いましょう(recon_alloc以外にもrecon_traceとかも良さげ) -
defstructはメモリの肥大化に繋がりそうなのでなるべく関数型な実装を心がける - メモリ的に重い処理はメモリを切るとGCを意図的にコントロールできるので即お片付けを心がけましょう
- Elixirのパフォーマンス・チューニングにおいてもErlang in Angerは有用
今後について
これでもメモリ14GBとか使ってしまうので今後も省メモリ化を進めたいです。
しかしながら、Chainerがメンテナンスフェーズに入ったり、TensorFlowとEdge TPU辺り、とPyTorchの勢いを見るとDLフレームワークってもうその辺で良い気はしますが、自分で中を作ることで学ぶものは多いし、ElixirはAbstract Syntax Treeが取れてエコシステムに昇華させやすいことからPelemayや @takasehideki 先生のコカトリスとかの環境が整ってきたら面白くなってくるのでは、と思って進めています。
明日の「fukuoka.ex Elixir/Phoenix Advent Calendar 2019」は @im_miolab さんです。お楽しみに!