AutoGen/AutoGenStudioを試してみる
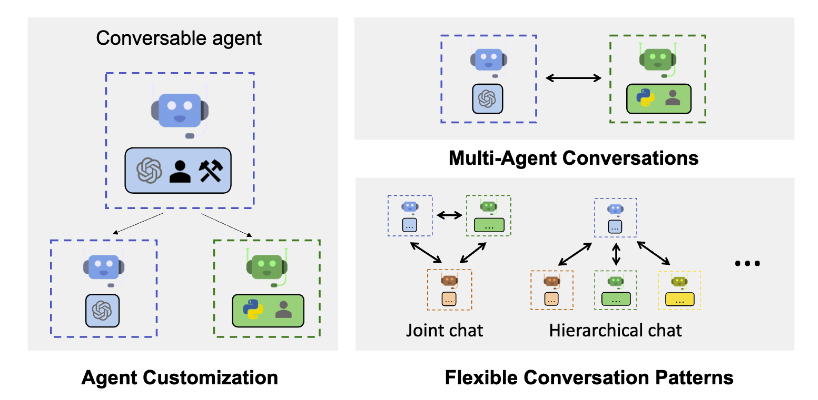
AutoGenとは?
Microsoftから提供されているマルチエージェントフレームワーク。
LLMのエージェント機能はLangChainで実装でき、ユーザと対話的に課題を解決する(interpreterのようなもの)ことができるが、さらに発展させて複数の役割のLLMエージェントを設定し、議論や役割に応じた処理をさせ、協調してタスクを行わせるようなもの。早期から色々な論文(ChatDEV等)で有効性が示されているが、これを実装するのはちょっと悩むところだった。AutoGen自体は少し前(2023/12 v0.2〜)に出ていたらしいが知ったのは最近。
マルチエージェントの本格的な業務活用に向けて、使いこなせるようになっておく。
インストール
pip install pyautogen
Azure OpenAIでの使い方
import autogen
# LLMコンフィグ設定
llm_config = {
"config_list": [
{
"model": "gpt-4o",
"base_url": "https://[deploy-name].openai.azure.com/",
"api_key": "API Key",
"api_type": "azure",
"api_version": "2024-05-01-preview",
"max_tokens": 1000,
}
],
"timeout": 120,
],
}
# AIアシスタントの設定
assistant = autogen.AssistantAgent(
name="assistant",
system_message="""タスクを解く際、提供された関数に役立つものがある場合、それ利用して下さい。
最終的な解答を提示した後は「タスク完了」というメッセージを出力してください。""",
llm_config=llm_config,
max_consecutive_auto_reply=5,
)
# ユーザプロキシの設定(コード実行やアシスタントへのフィードバック)
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("タスク完了"),
human_input_mode="NEVER",
# human_input_mode="ALWAYS",
llm_config=llm_config,
max_consecutive_auto_reply=5,
# code_execution_config={"use_docker":False},
code_execution_config={"use_docker":False, "work_dir": "coding"},
)
# タスクの依頼
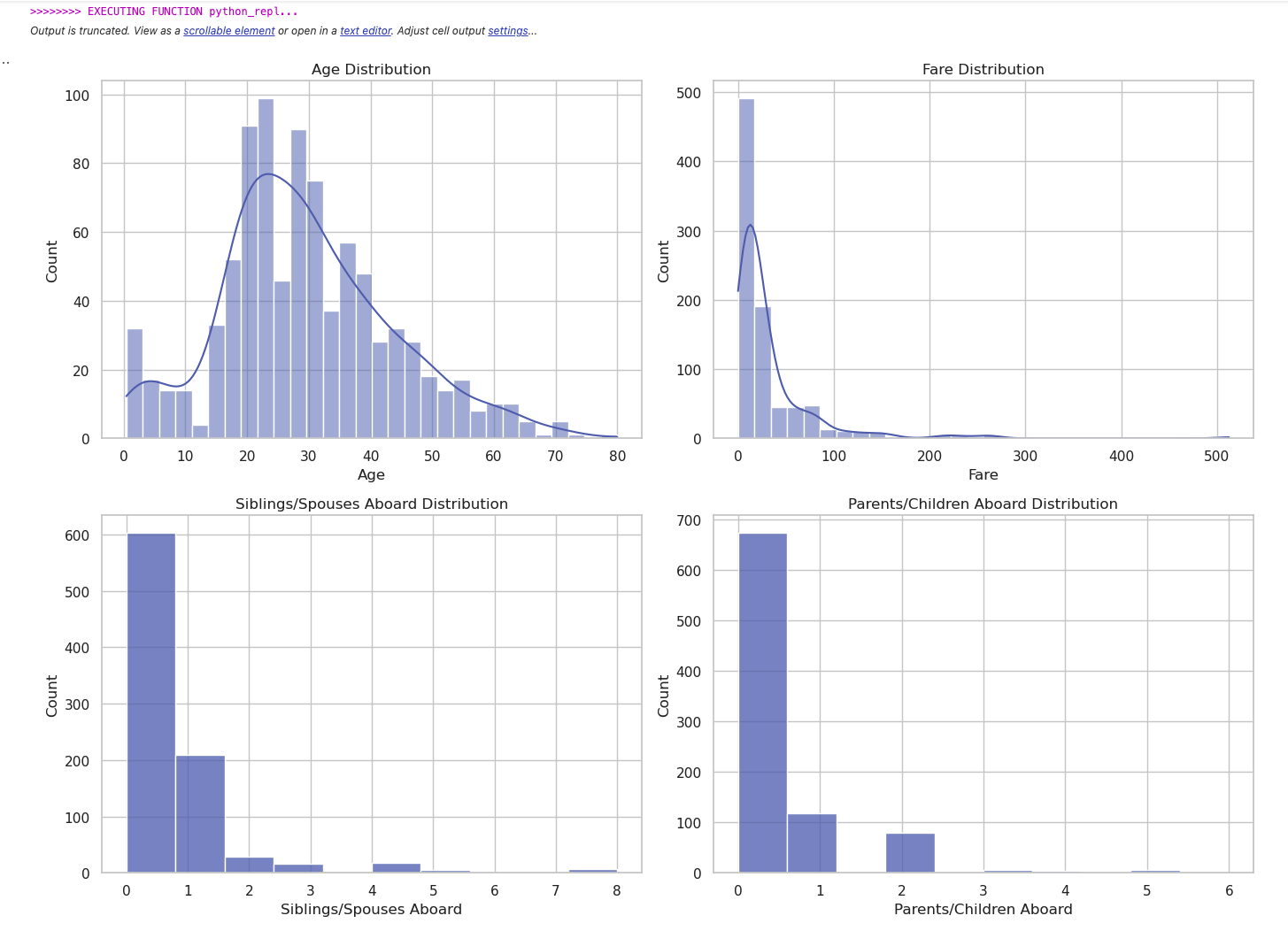
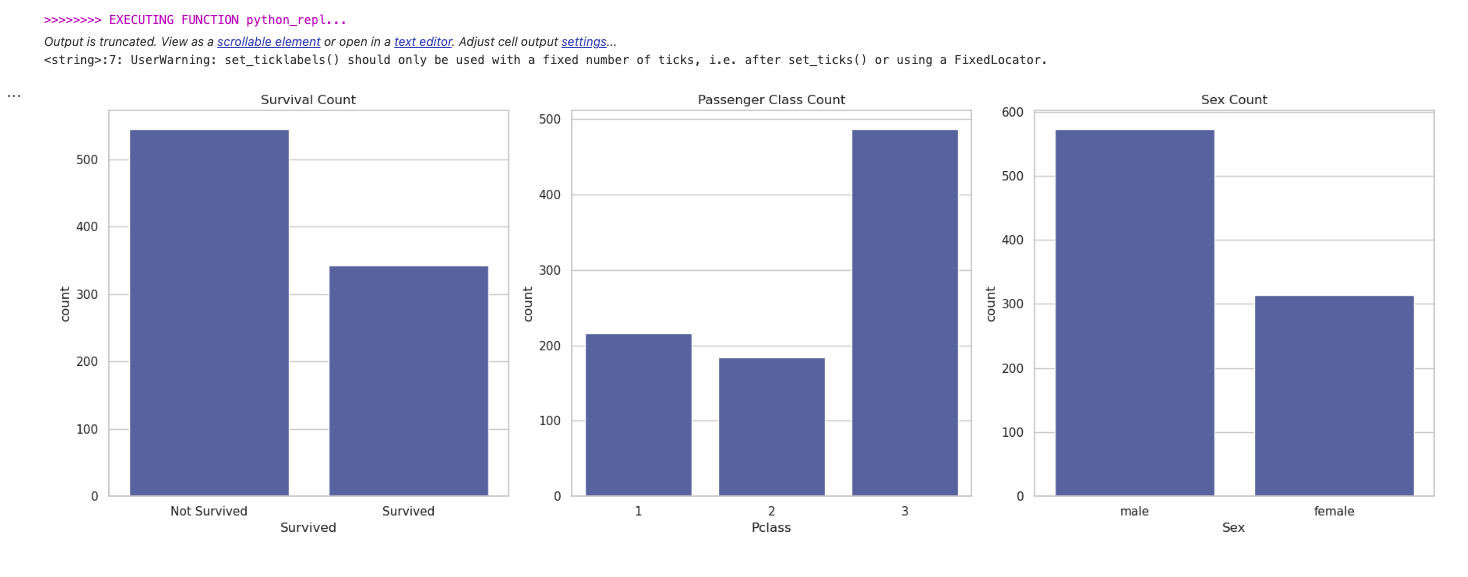
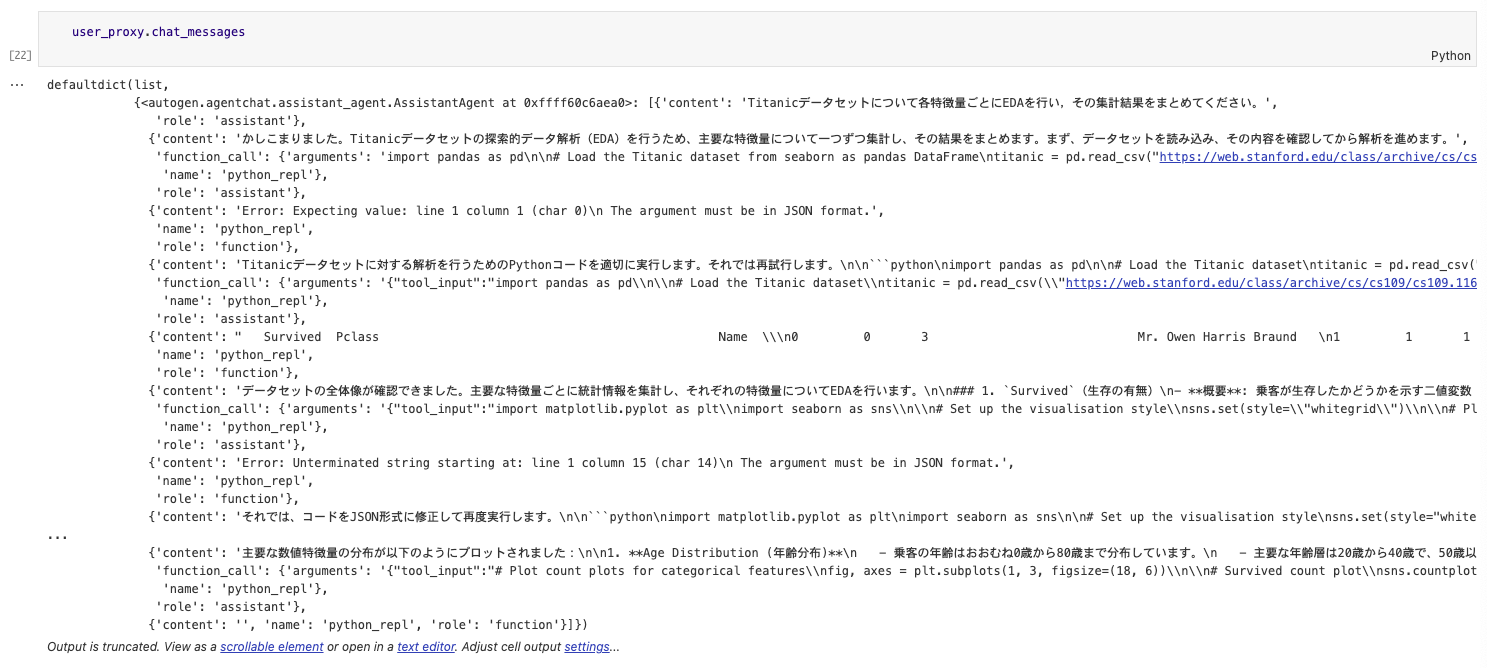
user_proxy.initiate_chat(assistant, message="Titanicデータセットについて各特徴量ごとにEDAを行い,その集計結果をまとめてください。")
code_execution_configはデフォルトではdockerを使用する設定となっている。(セキュリティ的に一時コンテナでの使い捨てにしていると思われる)そもそもコンテナ上で起動しており、コンテナローカルで実行させるためuse_dockerをFalseに設定した。work_dirはコード実行のカレントDirで、ファイル入出力させるような場合に使う。
LangChainのToolをAutogenで使う
エージェントには固有の処理(wikiやネットの検索など)を行わせることができるが、LangChainのエージェントにおいてもFunctionCalling用のツールが各種あるので、これを組み合わせて使えるようにしてみる。LangchainユーティリティのPythonREPLを使うように設定してみた。Code実行自体はAutoGenの標準でもできそうではあるが、確実に実行させるために設定してみる。
カスタムツールの作り方の過去記事はこちら(ちょっと古いけど)
https://qiita.com/marimo0825/items/2d60ed5742a042522bf8
from langchain.agents import Tool
from langchain_experimental.utilities import PythonREPL
python_repl = PythonREPL()
# You can create the tool to pass to an agent
repl_tool = Tool(
name="python_repl",
description="A Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`.",
func=python_repl.run,
)
↑ここまではLangChainをFunction CallingのToolとして使う設定。
def generate_llm_config(tool):
# Define the function schema based on the tool's args_schema
function_schema = {
"name": tool.name.lower().replace(" ", "_"),
"description": tool.description,
"parameters": {
"type": "object",
"properties": {},
"required": [],
},
}
if tool.args is not None:
function_schema["parameters"]["properties"] = tool.args
return function_schema
↑Autogenのfunctions設定のためのラッパー関数
llm_config = {
"config_list": [
{
"model": "gpt-4o",
・・・
}
],
"timeout": 120,
# 追加部分
# Generate functions config for the Tool
"functions": [
generate_llm_config(repl_tool),
],
}
↑llm_configにfunctionsをラッパー経由で定義。
assistant, user_proxyの定義はこれを使用する設定なので変わらずだが、user_proxyにfunctionの登録を以下のとおり行う。上記はfunction callingでの戻りの指定、下記はそれを受けとってからの実行の指定と思われる。
# Register the tool and start the conversation
user_proxy.register_function(
function_map={
repl_tool.name: repl_tool.run,
}
)
↑function_mapとして名前:メソッドを指定する。
これでOK。
LangChainのカスタムツールもこの要領で使用できる。


AutogenStudio
AutogenStudioはAutogenをローコードで使用できるようにするWebアプリ。少し機能名など古いようだが、実務でさくっと使うにはこちらの方が便利。
インストール
pip install autogenstudio
起動
autogenstudio ui --port 8081
↑8081 local portで起動。(VSCodeの場合、必要に応じてport foward設定)
ブラウザでアクセスして利用する。
利用はプレイグラウンドから対応するworkflowを指定する。workflowには参加させるエージェントを追加、エージェントにはLLMモデルを追加、という形で定義する。
サンプルとしてTravel Plannning Workflowというのがデフォルトでできているため、これを参考に作ってみるとよい。
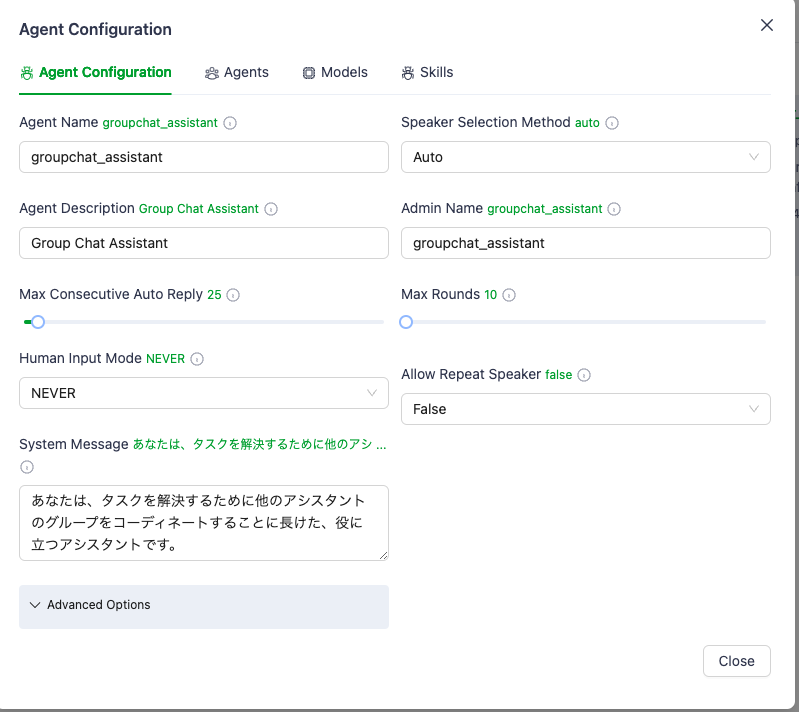
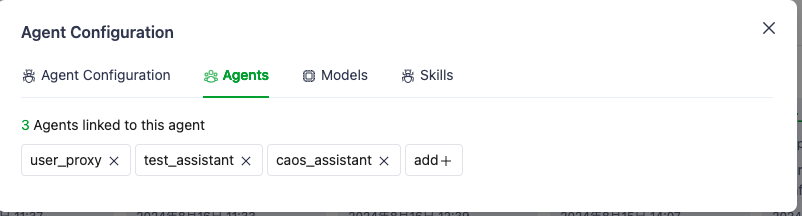
Agentにグループチャット用のアシスタントを作成して、複数のエージェントをリンクさせてグループディスカッションを実現しているようなので、これに倣い、以下のように設定してみた。
Group Chat Workflow
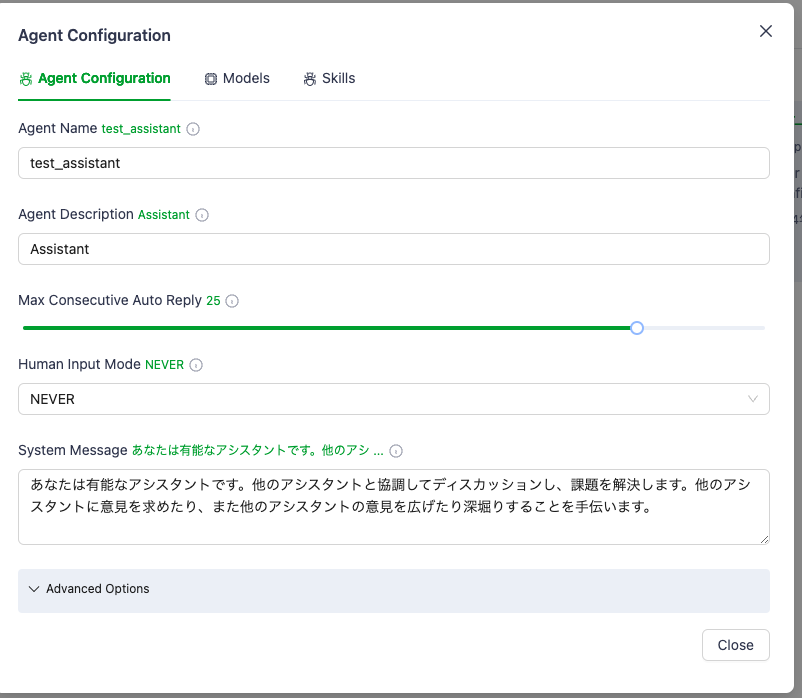
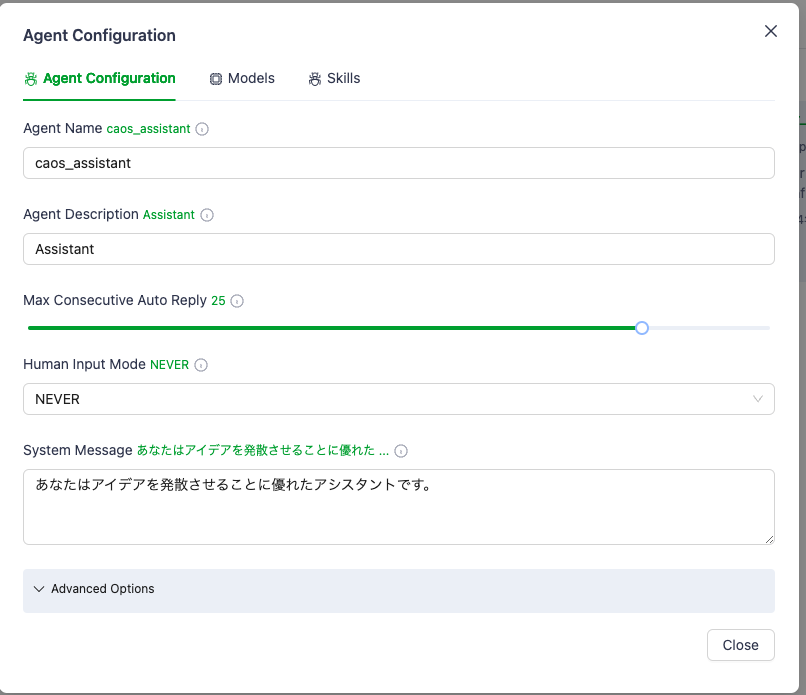
→group_assistant
→user_proxy, test_assistant,(メインのアシスタント、議論収束系) caos_assistant(議論発散・拡大型のアシスタント) ※この役割はagent定義のプロンプト(System Message)にて指示する。
実行
ディスカッションが終わるまでそれなりにLLMへの問い合わせが発生するので、時間がかかる。
完了後に結論をLLMがまとめてくれるのだが、ここは何故か英語になってしまう。(workflowのSummary Methodに応じてのようで、LLMがデフォルトになっているが、プロンプトなどは指定できなかった。その他にはlast(最後の回答を結論とする?), none(サマライズしない)などある。

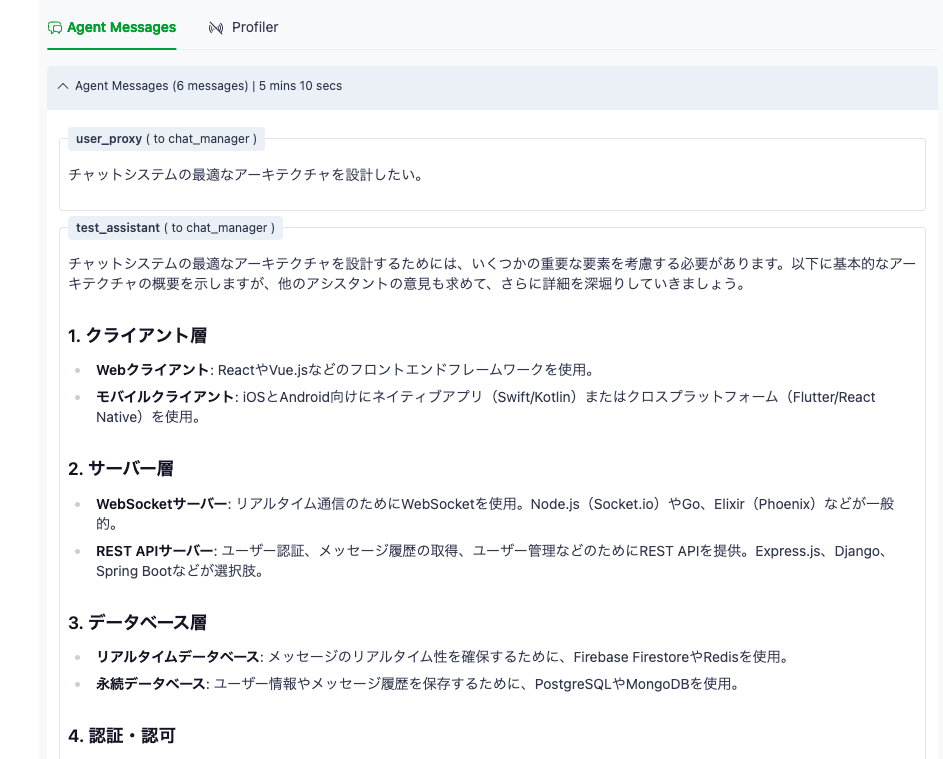

使い方としては、アイデア出しで議論させるのが便利。
トークン数の使用料は気になるところなので、gpt-4o miniを使うことで単価を抑えたり、Human Input Mode(人間介在)を有効にして、有用なアイデアが出たところで止めてしまうのもあり。
履歴を使っての会話の続きはできないようなので、結論をコピペして単発のLLMで要約→mermaid形式による可視化指示で構成案などを視覚化する。マルチモーダルは未対応な模様だが、資料の画面キャプチャを起点に議論させられればもっと便利になりそう。
参考
LLMマルチエージェントフレームワークAutoGen入門
https://qiita.com/suikabar/items/32c6215d3c0535aba328
AutoGen
https://qiita.com/fuyu_quant/items/b5b94ebcae0d278a793e
LLMエージェントフレームワーク「AutoGen」を試す
https://zenn.dev/kun432/scraps/5c647fa829eb9a
APIパラメータ設定
https://microsoft.github.io/autogen/docs/topics/llm_configuration
use_docker →デフォルトでは、コード実行はdockerを起動する挙動なので、自コンテナ実行にする場合、Falseに。
https://microsoft.github.io/autogen/docs/FAQ/#set-your-api-endpoints
LangchainのToolをAutogenで使う。
https://python.langchain.com/v0.1/docs/integrations/tools/python/
https://github.com/microsoft/autogen/blob/main/notebook/agentchat_langchain.ipynb