AutoGenとは
AutoGenは、MicroSoftによるLLMマルチエージェント処理を手軽に実装できるフレームワークです。
マルチエージェントとは、複数のLLMエージェントが相互作用する仕組みのことです。例えば、単一のLLMエージェントにとっては遂行が難しい複雑なタスクでも、固有のロールを持った複数のLLMエージェントに協調して解かせることで、遂行能力が高まることが期待されます。
このようなマルチエージェントの処理をスクラッチで実装しようとすると大きな労力がかかりますが、AutoGenを利用することで手軽に複数エージェントのインタラクションを実装することができます。
AutoGenは非常にカスタマイズ性が高く、簡単な設定を通して、LLMエージェントに以下のような振る舞いを持たせることができます。
- Pythonコードの提案、またその実行
- カスタム関数のツールとしての呼び出し
- インタラクションの中での人間の介入(Human-in-the-loop)
AutoGenの具体的なユースケースとして、論文では以下の6つの例が紹介されています。
- 数学の問題の解決
- RAGに基づくコード生成・質問回答
- テキスト環境における意思決定
- 複数エージェントによるコーディング
- グループチャット
- チェスの対局
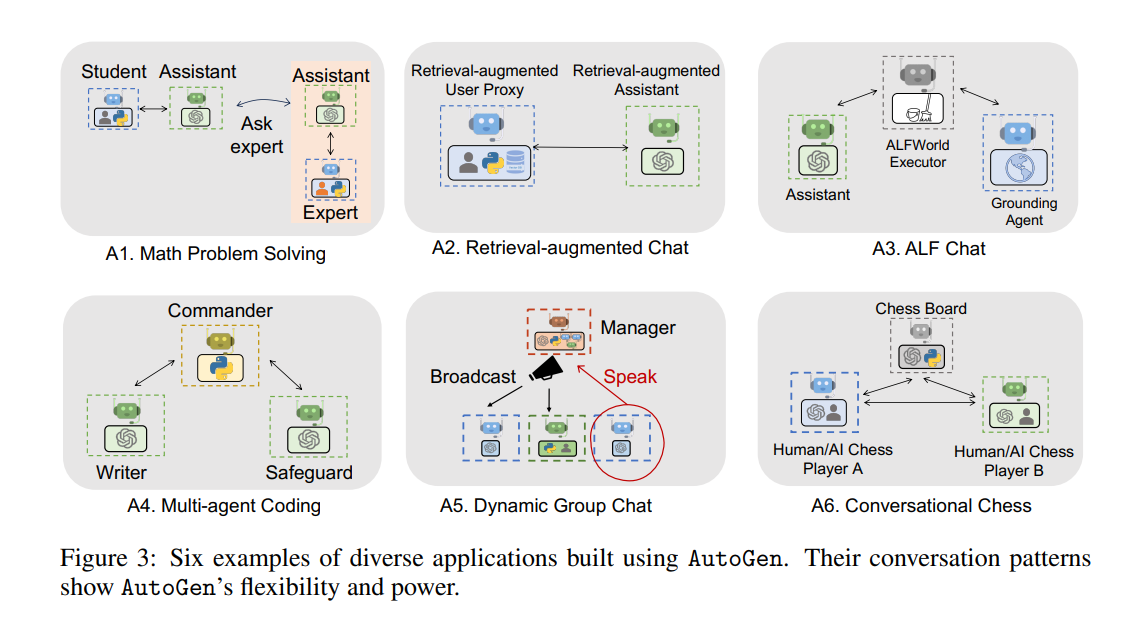
Wu et al. (2023)より引用
このように、AutoGenはカスタマイズ性が高く汎用的なフレームワークとなっており、マルチエージェント処理が求められる様々な場面で利用することができます。
言語モデルとしてはOpenAI(あるいはAzure OpenAI)のモデルが利用可能です。
使い方
メインコンポーネント
ConversableAgent
AutoGenで中心的な役割を果たすのがこのConversableAgentで、互いに会話することができるLLMエージェントです。抽象クラスのAgentを継承しています。
ConversableAgentは他のエージェントと対話するインターフェースとして、以下のようなメソッドを備えています。
-
send(message, recipient: Agent):他のエージェントにメッセージを送信する -
recieve(message, sender: Agent):他のエージェントからメッセージを受信する
ConversableAgentは非常にカスタマイズ性が高く、コンストラクタに以下のような引数を設定することで、エージェントに様々な振る舞いを持たせることができます。
| 引数 | 内容 |
|---|---|
system_message |
エージェントのロールを指示するシステムメッセージ。 |
is_termination_msg |
会話の終了条件を定義する関数。 |
max_consective_auto_reply |
返答を返す回数。会話のやり取りの回数の上限を設定できる。 |
human_input_mode |
エージェント間のインタラクションに人間による入力を介在させるかどうかのオプション。例えば"ALWAYS"と設定するとメッセージが届くたびに返答内容の入力をユーザーに求める。 |
code_execution_config |
Pythonコードの実行を有効化するかどうかのオプション。有効化すると、受信したメッセージのPythonコードブロックを検知してコードの実行を行う。 |
llm_config |
LLMによる返答を有効化するかどうかのオプション。無効化することで、例えばPythonコードを実行するだけの役割を持たせることなども可能(後述のUserProxyAgentはデフォルトではこの振る舞いが設定されている)。 |
このようにConversableAgent自体をカスタマイズすることで様々な振る舞いを持つエージェントを実装することも可能ですが、一般的なユースケースに適する組み込みのエージェントとして、AssistantAgentとUserProxyAgentの2つのサブクラスが提供されています(論文でもまずはこの2つを利用してみることを推奨しています)。
AssistantAgent
AIアシスタントとしての役割を担うエージェントです。デフォルトの振る舞いとして、コードの実行は自身では行わず、実行はユーザー(あるいはその代理としてのUserProxyAgent)に委ねる形として、タスクの実行に必要なコードの作成や修正を行うことが指示されています。
デフォルトのシステムメッセージ
DEFAULT_SYSTEM_MESSAGE = """You are a helpful AI assistant.
Solve tasks using your coding and language skills.
In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute.
1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself.
2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly.
Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill.
When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can't modify your code. So do not suggest incomplete code which requires users to modify. Don't use a code block if it's not intended to be executed by the user.
If you want the user to save the code in a file before executing it, put # filename: <filename> inside the code block as the first line. Don't include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use 'print' function for the output when relevant. Check the execution result returned by the user.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible.
Reply "TERMINATE" in the end when everything is done."""
UserProxyAgent
人間の代理として、コードの実行やアシスタントへのフィードバックを行う役割を担うエージェントです。デフォルトの振る舞いとして、返答をLLMにより行わず、人間による入力を求める仕様となっています。また、コードの実行機能が有効化されています。
実際にエージェント間の会話を開始する際にはinitiate_chatを利用します。これを呼び出すことで、2つのエージェントによる会話が開始します(内部的には、上記のsendやrecieveが設定された終了条件に達するまで継続して呼び出されています)。
assistant = autogen.AssistantAgent(...)
user_proxy = autogen.UserProxyAgent(...)
user_proxy.initiate_chat(assistant, message="some messages")
以上の2つのエージェントをベースにしつつ、振る舞いをカスタマイズすることで多様なマルチエージェント処理を実行することができます。
グループチャット
GroupChatManager
AutoGenでは、多数のエージェントによるグループチャットを実現するための機能として、GroupChatManagerが提供されています。こちらもConversableAgentのサブクラスであり、複数のエージェントによるチャットを制御する役割を担います(GroupChatManager自身は会話の中には登場しません)。
以下のようにチャットの振る舞いを決める設定オブジェクトGroupChatをGroupChatManagerに渡して初期化します。そして上の例と同様、initiate_chatをトリガーとして複数エージェントによるグループチャットが開始されます。
user_proxy = autogen.UserProxy(...)
assistant_1 = autogen.AssistantAgent(...)
assistant_2 = autogen.AssistantAgent(...)
groupchat = autogen.GroupChat(
agents=[user_proxy, assistant_1, assistant_2], messages=[], max_round=10
)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=llm_config)
user_proxy.initiate_chat(manager, message="some messages")
GroupChatには以下のような引数が設定でき、これをカスタマイズすることでグループチャットに様々な振る舞いを持たせることができます。
| 引数 | 内容 |
|---|---|
agents |
チャットに参加するエージェントのリスト。 |
max_round |
チャットをやり取りする最大回数。 |
speaker_selection_method |
チャット内で次の発言者を決める規則。以下のようなオプションがある。 ・ "auto":LLMによって自動的に選択・ "manual":ユーザーの入力にしたがって次の発言者を選択・ "random":ランダムに選択・ "round_robin":agentsに与えた順番にしたがって発言 |
allow_repeat_speaker |
同じエージェントが連続して発言することを許可するかどうかのオプション。 |
ツールの利用
エージェントがfunction callingに基づきツールを利用する仕組みも提供されており、カスタムツールを与えることで様々なユースケースに対応できます。実装も非常に簡単で、作成した自作関数に次のデコレータを付けるだけで、利用可能なツールであることをエージェントに認識させることができます。
-
ConversableAgent.register_for_llm:利用可能な関数の情報をエージェントに登録する -
ConversableAgent.register_for_execution:関数を実行対象としてエージェントに登録する
user_proxy = UserProxyAgent(...)
assistant = AssistantAgent(...)
@user_proxy.register_for_execution()
@assistant.register_for_llm(description="description of a function")
def some_useful_function(x: Annotated[str, "description of a parameter"]) -> str:
....
return result
上記のように、型ヒントAnnotatedの情報を通して、引数の説明がregister_for_llmで登録したエージェントに渡されます。登録された関数のスキーマはassistant.llm_config["tools"]より確認できます。
assistant.llm_config["tools"]
[
{
'type': 'function',
'function':
{
'description': 'description of a function',
'name': 'some_useful_function',
'parameters': {
'type': 'object',
'properties': {
'x': {
'type': 'string',
'description': 'description of a parameter'
}
},
'required': [
'x'
]
}
}
}
]
LangChainによって提供されているToolも再利用可能なようです(実装はこちらのノートブックを参照)。
使用例
非常に簡単な例として、温度を摂氏から華氏に変換するタスクをマルチエージェントに解かせてみます。
まずOpenAI APIを利用するためのAPIキーの設定を行います。設定方法はいくつか方法がありますが、今回は.envファイルから読み込む形とします。
env_path = "path to .env"
config_list = autogen.config_list_from_dotenv(
dotenv_file_path=env_path,
filter_dict={"model": {"gpt-4", "gpt-3.5-turbo"}},
)
llm_config = {"config_list": config_list, "timeout": 120}
次にAssistantAgentとUserProxyAgentの2つのエージェントを生成します。今回はエージェントの振る舞いを以下のように設定しました。
- いずれも最大の返答回数は5回
-
UserProxyAgentはLLMにより返信する(人間は介在しない) - 「タスク完了」というキーワードで終わるメッセージを受信したタイミングで会話を停止する
assistant = autogen.AssistantAgent(
name="assistant",
system_message="""タスクを解く際、提供された関数に役立つものがある場合、それ利用して下さい。
最終的な解答を提示した後は「タスク完了」というメッセージを出力してください。""",
llm_config=llm_config,
max_consecutive_auto_reply=5,
)
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("タスク完了"),
human_input_mode="NEVER",
llm_config=llm_config,
max_consecutive_auto_reply=5,
)
次に、摂氏から華氏へと変換する関数をエージェントに登録します。
@user_proxy.register_for_execution()
@assistant.register_for_llm(description="摂氏から華氏へ変換する関数")
def celsius_to_fahrenheit(celsius: Annotated[float, "温度(摂氏)"]) -> float:
return (celsius * 9/5) + 32
以上の設定の上で、2人のエージェントによるチャットを開始します。
user_proxy.initiate_chat(assistant, message="摂氏15度を華氏に変換して下さい。")
出力は以下のようになります。
user_proxy (to assistant):
摂氏15度を華氏に変換して下さい。
--------------------------------------------------------------------------------
assistant (to user_proxy):
***** Suggested tool Call (call_2eKAf0hzoNu3RL7mnvzVW5UB): celsius_to_fahrenheit *****
Arguments:
{
"celsius": 15
}
**************************************************************************************
--------------------------------------------------------------------------------
>>>>>>>> EXECUTING FUNCTION celsius_to_fahrenheit...
user_proxy (to assistant):
user_proxy (to assistant):
***** Response from calling tool "call_2eKAf0hzoNu3RL7mnvzVW5UB" *****
59.0
**********************************************************************
--------------------------------------------------------------------------------
assistant (to user_proxy):
摂氏15度は華氏59度です。
タスク完了
--------------------------------------------------------------------------------
-
user_proxyからassistantへ最初のメッセージが送信される -
assistantが登録された関数の情報を踏まえ、関数を実行を提案する -
user_proxyが関数を実行する -
assistantが関数の実行結果を踏まえ、最終的な回答を行う
という流れで処理が進んでいることがわかります。
会話の履歴はchat_messageで取得できます。
user_proxy.chat_message
defaultdict(
<class 'list'>,
{
<autogen.agentchat.assistant_agent.AssistantAgent object at 0x7bdf30b6f940>: [
{
'content': '摂氏15度を華氏に変換して下さい。',
'role': 'assistant'
},
{
'tool_calls': [
{
'id': 'call_2eKAf0hzoNu3RL7mnvzVW5UB',
'function': {
'arguments': '{\n "celsius": 15\n}',
'name': 'celsius_to_fahrenheit'
},
'type': 'function'
}
],
'content': None,
'role': 'assistant',
},
{
'content': 'Tool Call Id: call_2eKAf0hzoNu3RL7mnvzVW5UB\n59.0',
'tool_responses': [
{
'tool_call_id': 'call_2eKAf0hzoNu3RL7mnvzVW5UB',
'role': 'tool',
'content': '59.0'
}
],
'role': 'tool'
},
{
'content': '摂氏15度は華氏59度です。\n\nタスク完了',
'role': 'user'
}
]
}
)
以上、AutoGenの簡単な使用例を確認しました。この例は非常に単純なので、マルチエージェント化する利点があまり感じられないかもしれませんが、より実用的なユースケースについては公式のExamplesにサンプルコード付きで提供されていますので、そちらをご覧ください。
その他
-
gpt-3.5-turboを利用する場合、モデルのパフォーマンスの問題により、目的のタスクを完遂した後、終了条件を忘れて互いに讃え合い続ける「感謝のループ」に入ることがあるようです。ドキュメントではこれを防止するためのサンプルプロンプトが提供されています。 - 論文では、最初の段階では
UserProxyAgentに対してhuman_input_mode="ALWAYS"と設定する(つまり、毎回人間の手で返答を返す)ことを推奨しています。これは、まずは人間によるインタラクションを通してAssistantAgentの能力の有効性を確認することから始めましょう、という意図のようです。
おわりに
以上、AutoGenの基本的な使い方について説明しました。実装が簡単でありながらカスタマイズ性が高く、応用範囲が広そうなフレームワークだと思いました。LLMマルチエージェント自体ホットなトピックなので、今後の発展が楽しみです。