はじめに
今回はAutoGenの紹介になります.AutoGenはMicorsoftが開発しているOSSで,LLM,ツール,人間を統合できるLLMフレームワークや最適なコストで推論能力を向上させるチューニングの機能などがあります.また様々なシチュエーションに対応できるようなLLMを使ったフレームワークも紹介されていました.複数のエージェント間のチャット、コードを介してツールを使用する必要があるタスクの実行、人間のフィードバックを受けながらタスクを実行させることなどができるそうです.
記事に誤り等ありましたらご指摘いただけますと幸いです。
1. AutoGen
ライセンス:CC-BY-4.0 LICENSE,MIT LICENSE-CODE
(ドキュメントやデータがCC-BY-4.0でコードがMITライセンスという解釈で正しいと思います)
リポジトリ:https://github.com/microsoft/autogen
公式サイト:https://microsoft.github.io/autogen/
論文:https://arxiv.org/abs/2308.08155
AutoGenはFLAMLというOSSのプロジェクトのスピンオフでMicorsoftが開発しています.AutoGenでは主に以下の3つの用途が掲載されています.
- Multi-Agent Conversation Framework
- LLM、ツール、人間を統合でき、カスタマイズ可能な会話可能なエージェントを構築するためのLLMフレームワークです。複数のエージェント間のチャットを自動化し、コードを介してツールを使用する必要があるタスクを行なったり、あるいは人間のフィードバックを受けながらエージェントにタスクを実行させることもできます。
- https://microsoft.github.io/autogen/docs/Use-Cases/agent_chat
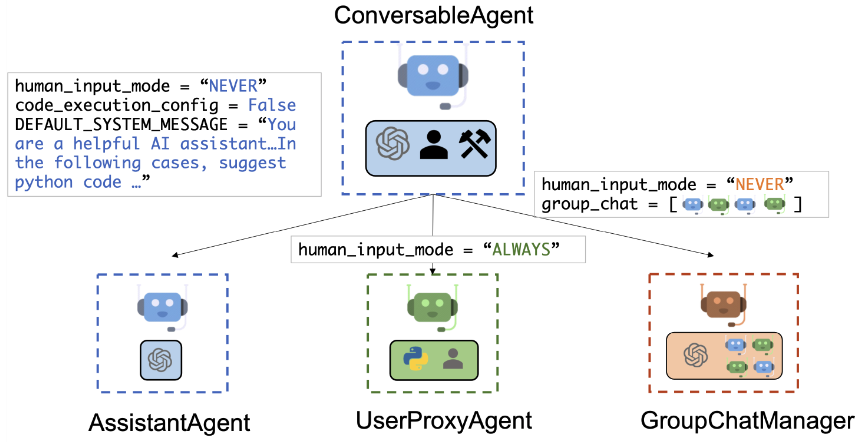
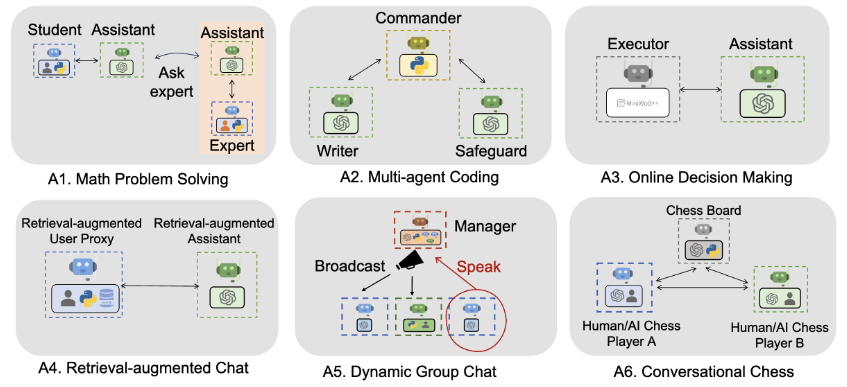
- Easily Build Diverse Applications
- 様々なアプリケーションを簡単に構築するためのLLMのフレームワークが紹介されています.
- ここのリンクに様々な応用例が掲載されています.
- 以下の図はいくつかの例になります.
- Enhanced LLM Inference & Optimization
- コストを抑えLLMの推論のパフォーマンスを向上させるチューニングを行うことができるそうです.
- 費用対効果の高いハイパーパラメータ最適化手法であるEcoOptiGenというものも提供しています.
- https://microsoft.github.io/autogen/docs/Use-Cases/enhanced_inference
2. 使い方
今回はMulti-Agent Conversation Frameworkを使いタスクを実行させます.
すぐに試したい方はData Science WikiのページまたはColabのリンクから実行してみてください

![]()
必要なライブラリは以下のみです.
また環境変数にOpenAIのAPI keyを設定する必要があります.
!pip install pyautogen
from autogen import AssistantAgent, UserProxyAgent, config_list_from_json
以下では様々な設定を行なっていますが詳細については今後追記していく予定です.
- LLMの推論の設定
config_list = config_list_from_json(
"OAI_CONFIG_LIST",
filter_dict={
"model": ["gpt4", "gpt-4-32k", "gpt-4-32k-0314", "gpt-4-32k-v0314"],
},
)
llm_config={
"request_timeout": 600,
"seed": 42,
"config_list": config_list,
"temperature": 0,
}
- AssistantAgentの設定
assistant = AssistantAgent(
name="assistant",
llm_config={"config_list": config_list}
)
- UserProxyAgentの設定
user_proxy = UserProxyAgent(
name = "user_proxy",
human_input_mode="TERMINATE",
max_consecutive_auto_reply=20,
code_execution_config={"work_dir": "coding"},
llm_config=llm_config,
system_message="""Reply TERMINATE if the task has been solved at full satisfaction.
Otherwise, reply CONTINUE, or the reason why the task is not solved yet."""
)
- タスクの実行
user_proxy.initiate_chat(
assistant,
message="Titanicデータセットについて各特徴量ごとにEDAを行い,その集計結果をまとめてください."
)
- 出力結果
[33muser_proxy[0m (to assistant):
Titanicデータセットについて各特徴量ごとにEDAを行い,その集計結果をまとめてください.
--------------------------------------------------------------------------------
[33massistant[0m (to user_proxy):
まずはPythonのデータ分析ライブラリpandasを使用するために、データセットを読み込みましょう。Pythonの可視化ライブリーmatplotlibとseabornも使用します。そしてTitanicのデータセットはSeabornライブラリに組み込まれていますので、そこから直接ロードできます。以下のPythonコードを実行してください。
# Python Code
# Necessary Libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Loading built-in Titanic dataset
titanic = sns.load_dataset('titanic')
# Displaying the top rows of the loaded dataset
print(titanic.head())
# Descriptive Analysis
print("\nDescriptive Analysis:")
print(titanic.describe(include='all'))
# Checking for null values
print("\nNull Values check:")
print(titanic.isnull().sum())
# Checking the Survival rate group by Sex
print("\nSurvival Rate by Sex:")
print(titanic.groupby('sex')['survived'].mean())
# Checking the Survival rate group by Classes
print("\nSurvival Rate by Classes:")
print(titanic.groupby('class')['survived'].mean())
# Checking the number of passengers in each class
print("\nNumber of passengers in each class:")
print(titanic['class'].value_counts())
# Graphically representing the number of male and female passengers
sns.countplot(x='sex',data=titanic)
plt.show()
# Graphically representing the number of survivors
sns.countplot(x='survived',data=titanic)
plt.show()
これにより、以下の情報を得ることができます:
- データセットの最初の数行
- 各列の記述統計
- 各列のヌル(または欠損)値の数
- 性別ごとの生存率
- クラスごとの生存率
- 各クラスの乗客数
- 男性乗客と女性乗客の数の可視化
- 生存者数の可視化
以上の情報がTitanicデータセットに関する基本的なEDA(探索的データ分析)です。
--------------------------------------------------------------------------------
[31m
>>>>>>>> USING AUTO REPLY...[0m
[31m
>>>>>>>> EXECUTING CODE BLOCK 0 (inferred language is python)...[0m
[33muser_proxy[0m (to assistant):
exitcode: 0 (execution succeeded)
Code output:
survived pclass sex age ... deck embark_town alive alone
0 0 3 male 22.0 ... NaN Southampton no False
1 1 1 female 38.0 ... C Cherbourg yes False
2 1 3 female 26.0 ... NaN Southampton yes True
3 1 1 female 35.0 ... C Southampton yes False
4 0 3 male 35.0 ... NaN Southampton no True
[5 rows x 15 columns]
Descriptive Analysis:
survived pclass sex age ... deck embark_town alive alone
count 891.000000 891.000000 891 714.000000 ... 203 889 891 891
unique NaN NaN 2 NaN ... 7 3 2 2
top NaN NaN male NaN ... C Southampton no True
freq NaN NaN 577 NaN ... 59 644 549 537
mean 0.383838 2.308642 NaN 29.699118 ... NaN NaN NaN NaN
std 0.486592 0.836071 NaN 14.526497 ... NaN NaN NaN NaN
min 0.000000 1.000000 NaN 0.420000 ... NaN NaN NaN NaN
25% 0.000000 2.000000 NaN 20.125000 ... NaN NaN NaN NaN
50% 0.000000 3.000000 NaN 28.000000 ... NaN NaN NaN NaN
75% 1.000000 3.000000 NaN 38.000000 ... NaN NaN NaN NaN
max 1.000000 3.000000 NaN 80.000000 ... NaN NaN NaN NaN
[11 rows x 15 columns]
Null Values check:
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
Survival Rate by Sex:
sex
female 0.742038
male 0.188908
Name: survived, dtype: float64
Survival Rate by Classes:
class
First 0.629630
Second 0.472826
Third 0.242363
Name: survived, dtype: float64
Number of passengers in each class:
class
Third 491
First 216
Second 184
Name: count, dtype: int64
Figure(640x480)
Figure(640x480)
--------------------------------------------------------------------------------
[33massistant[0m (to user_proxy):
実行結果を見てみましょう:
1. データセットは15のフィールドを持っています。最初の5行に基づくと、これらのフィールドは'Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'Class', 'Who', 'Adult_male', 'Deck', 'Embark_town', 'Alive', 'Alone'です。
2. 記述分析では、それぞれの数値フィールドについてカウント、平均、標準偏差、最小値、25%、50%、75%、最大値が求められています。
3. `age`, `deck`, `embarked` および `embark_town` フィールドにはnull値があります。`deck`フィールドのnull値が他のフィールドよりも大きく、データセット内のメジャーな部分を占めています。
4. 男性と女性の生存率が計算され、女性の生存率が男性の生存率よりも高いことが分かります。
5. 各クラスの生存率も計算されました。ここでは、第一クラスの乗客の生存率が最も高く、第三クラスが最も低くなっています。
6. 各クラスの乗客数もチェックされました。第3クラスには一番多くの乗客がおり、次に第1クラス、最後に第2クラスが続きます。
7. 最後に、可視化を通じて性別別と生存者数の分布を確認できました。これらのビジュアルは、それぞれのカテゴリに存在する観測値の数を比較するのに役立ちます。
以上の情報を通じて、Titanicデータセットの各特徴量に関する基本的な探索的データ分析(EDA)を行うことができました。
TERMINATE
--------------------------------------------------------------------------------
[31m
>>>>>>>> USING AUTO REPLY...[0m
[33muser_proxy[0m (to assistant):
TERMINATE
--------------------------------------------------------------------------------
上記のようにデータ解析を行い最終的な出力を得ることができました.今回は命令が少し雑すぎたの命令通り分析結果をまとめてくれています.
3. おわりに
今回はAutoGenの紹介でした.LLM同士だけではなく人間が参加することを前提に構築されたフレームワークなのがとても面白く,社会実装される際も非常に役に立つと思いました.Easily Build Diverse Applicationsでは非常に多くの応用例がノートブックで記載されているので今後はこの辺りについて深くみていきたいです.
記事に誤り等ありましたらご指摘いただけますと幸いです。