シリーズ目次
AWSでデータ分析基盤構築をサクッと始めてみる(1.データカタログ作成編(行指向))
AWSでデータ分析基盤構築をサクッと始めてみる(2.行指向から列指向に変換編)
AWSでデータ分析基盤構築をサクッと始めてみる(3.データカタログ作成編(列指向))
AWSでデータ分析基盤構築をサクッと始めてみる(4.Athenaでアドホック分析編)
AWSでデータ分析基盤構築をサクッと始めてみる(5.Lambdaで分析自動化編)
2. 行指向から列指向に変換編
本章では、行指向(CSV形式)→列指向(parquet形式)にデータ変換しようと思ってます。
それでは、GlueのETLジョブ(Spark)を使って、parquet形式変換にチャレンジしましょう!
(1)ジョブの作成
GlueよりETL jobを選択し”Visual with a source and target”を選択していることを確認し作成("Create"ボタン押下)
図)”ETL jobs”画面
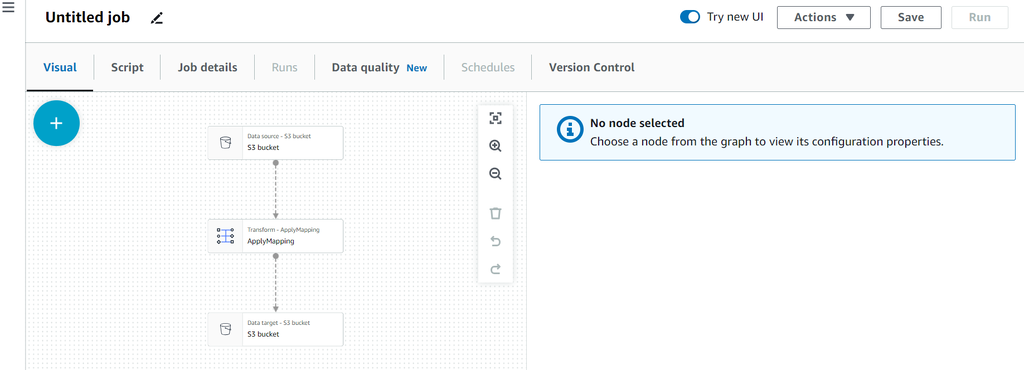
図)”Visual”タグの初期画面
①Data Source(S3 bucket)の設定
・Name:S3 bucket input ←名前はなんでもいいです
・S3 Source type:
・S3locationの場合、S3に保管したファイルを入力
ex.) s3://test_bucket/input/
・Data Catalog tableの場合、前章で作成したテーブルを選択
・Data format:CSV
・Delimiter:Comma(,)
・Quote character:Disable ←適切なものを選択
図)”Data source properties - S3”画面

②Transform ApplyMappingの設定
※必要があれば、ここでスキーマのカラムのデータ型を変更
③Data Target(S3 bucket)の設定
・Name:S3 bucket output ←名前はなんでもいいです
・Format:Parquet
・Compression Type:Uncompressed ←とりあえず圧縮しない
・“S3 Target Location”にparquet形式後のファイルを保管する用のフォルダのS3 URLを指定
ex.) s3://test_bucket/output/
図)”Data target properties - S3”画面

図4)設定完了後・・・すべてに完了チェックが入っている

④あとは、”Job details”タグにて必要項目を埋めて”Save”ボタン押下
・JobName:適当なジョブ名を指定
・IAM Role:適切なロールを指定
・Type:デフォルト(Spark)
・Glue version:デフォルト(spark 3.3, Python 3)
・Language:デフォルト(Python 3)
※2023/08時点で最新のもの(デフォルト)
(2)ジョブの実行
”Run”ボタン押下
“Run”タブよりジョブが成功していることを確認したらS3に移動しparquet形式後のファイルを保管する用のフォルダにparquet形式のファイルが格納されていることを確認
本章はこれで終わりです。どうもお疲れ様でした。
引き続き、次の章にチャレンジしてください!
AWSでデータ分析基盤構築をサクッと始めてみる(3.データカタログ作成編(列指向))
参考文献
- AWS公式サイト
AWS Glue