この記事はリンク情報システムの「TechConnect!2022年2月」のリレー記事です。
engineer.hanzomon のグループメンバによってリレーされます。
(リンク情報システムのFacebookはこちらから)
TechConnect!2022年2月のインデックスはこちら
はじめに
アドベントカレンダー何日目でしょう。土日祝日挟んだからわからないです。
ほんとは今回のアドベントカレンダー用になんか作ろうと思ってたのですが、時間作れませんでした。(自分の怠惰な心に負けただけともいう。)
面白い記事は超えられない壁があります。(前回も今回もニヤニヤしながら読みました。)
なので、業務で得た知見を使います。
ちなみに、内容チェックするから一週間前くらいに出せって言われてたのにもう前々日の深夜です。(まじですみません)
以下本文
他システムとの兼ね合いで、別プロジェクトにあるGCSのファイルをBigQueryに連携する必要がありました。
そのときハマったことなんかを共有できればと思います。
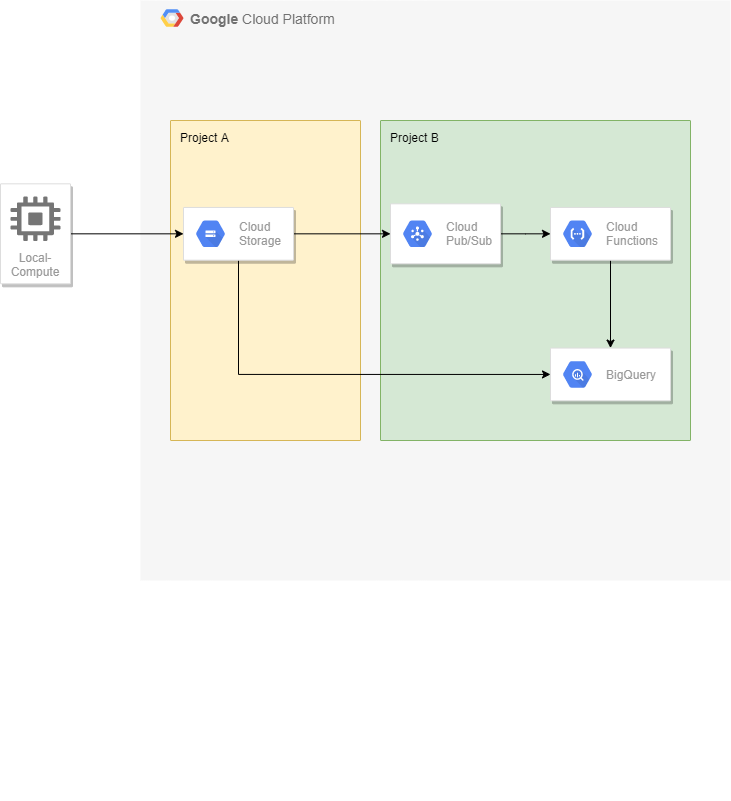
システム構成
今回の構成はこんな感じ。図のBのprojectのリソースを作っていきます。
図に入ってないものとして、functionsビルド用のGCSバケットもBのprojectに構築します。(後述)
前提
作成済みのものとかバージョン
- BQ用のプロジェクトがすでにあり、必要なAPIを有効化している
- GCS用のプロジェクトがすでにあり、GCSバケットが作成されている
- Terraform 1.0.2
- Go 1.13
ディレクトリ構成
先に入れるべきか後に入れるべきか…
bigquery
└ bq.json
functions
└ GcsToBq
├ function.go
├ go.mod
└ go.sum
terraform
└ qiita
├ bigquery.tf
├ functions.tf
├ iam_gcs.tf
├ notification_gcs.tf
├ terraform.tfvars
└ variables.tf
BQスキーマ
今回は簡単にこれだけ
詳しくはここを参照してください
[
{
"description": "文字データ",
"name": "string_data",
"type": "STRING",
"mode": "REQUIRED"
},
{
"description": "整数データ",
"name": "int_data",
"type": "INT64",
"mode": "REQUIRED"
},
{
"description": "null許可整数データ",
"name": "nullable_int_data",
"type": "INT64",
"mode": "NULLABLE"
}
]
処理
GCSにファイルが置かれたことをトリガーにします。(設定については後述)
今回はcsvファイルのみを対象にします。
gzip形式でも別に処理はそのまま使えるのですが、圧縮と非圧縮では処理にかかる時間が大幅に違います。
CloudFunction使う場合、最大でも540秒でタイムアウトして処理が止まってまうため、非圧縮状態を読み込むのがおすすめです。
一括で読み込めるデータ量の制限に関しても「非圧縮は 5 TB 」、「圧縮は 4GB 」とおそらく非圧縮の方が多くのデータを一括でインポートできます。
BQの読み込みジョブを作成してデータをインポートさせます。
BQは「データの保存にかかるストレージ容量」と「クエリで処理するデータ量」に対して課金されるのですが、読み込みジョブではデータの処理に関しては無料です。ストレージ容量に関しては課金されます。
function
実際の処理例
//// Package p contains a Google Cloud Storage Cloud Function.
package p
import (
"context"
"log"
"os"
"time"
"fmt"
"regexp"
"strings"
"encoding/json"
"cloud.google.com/go/pubsub"
"cloud.google.com/go/bigquery"
)
var (
DatasetId = os.Getenv("DATASET_ID")
TableId = os.Getenv("TABLE_ID")
BucketId = os.Getenv("BUCKET_ID")
)
var bqClient *bigquery.Client
type GCSEvent struct {
Bucket string `json:"bucket"`
Name string `json:"name"`
Size string `json:"size"`
Metageneration string `json:"metageneration"`
ResourceState string `json:"resourceState"`
TimeCreated time.Time `json:"timeCreated"`
Updated time.Time `json:"updated"`
}
func GcsToBQ(ctx context.Context, m *pubsub.Message) error {
var e GCSEvent
err := json.Unmarshal(m.Data, &e)
if err != nil {
log.Printf("message read error: %v",err)
return nil
}
fileName := string(e.Name)
fileSize := string(e.Size)
// ファイルサイズが0なら処理終了(GCSfuse対策)
if "0" == fileSize {
log.Printf("skip because file size : %v", fileSize)
return nil
}
log.Printf("filename: %v", fileName)
bqClient, err = bigquery.NewClient(ctx, ProjectId)
if err != nil {
fmt.Errorf("bigquery.NewClient: %v", err)
panic(err)
}
// 拡張子がcsvならインポート
csvFileNameFormat := regexp.MustCompile(`\.csv$`)
if (csvFileNameFormat.MatchString(fileName)) {
err = importCsv(ctx, fileName)
if err != nil {
fmt.Println(outputLog("ERROR",fmt.Sprintf("import error :%v",err )))
}
} else {
log.Printf("skip because file name: %v", fileName)
}
return nil
}
func importCsv(ctx context.Context, fileName string) error {
gcsUri := []string{"gs:/", BucketId, fileName}
gcsRef := bigquery.NewGCSReference(strings.Join(gcsUri, "/"))
gcsRef.SourceFormat = bigquery.CSV
gcsRef.SkipLeadingRows = 0
loader := bqClient.Dataset(DatasetId).Table(TableId).LoaderFrom(gcsRef)
loader.WriteDisposition = bigquery.WriteTruncate
job, err := loader.Run(ctx)
if err != nil {
return err
}
status, err := job.Wait(ctx)
if err != nil {
return err
}
if status.Err() != nil {
return status.Err()
}
return nil
}
// エラー出力用
func outputLog(logLevel, message string) string {
entry := map[string]string{
"severity": logLevel,
"message": message,
}
bytes, _ := json.Marshal(entry)
return string(bytes)
}
ここは正規表現なので、ファイル名絞りたいとかcsv以外も取り込みたいときは変えてください。
csvFileNameFormat := regexp.MustCompile(`\.csv$`)
GCSfuse対策
GCSfuseでマウントしたディレクトリに対してファイルおいて連携されたときに、
「0バイトのファイルが作成され、その後データの入ったファイルが作成される」
という動作をしていて(ナンデダロウネ)、ファイル連携時にfunctionが二回起動していたので以下の処理を入れています。
gsutilやWebコンソール上からファイル置いたときには起こりませんでした。
if "0" == fileSize {
log.Printf("skip because file size : %v", fileSize)
return nil
}
Terraformでの構築
tfvars(変数に値を入れるファイル)は自分の環境に合わせて作成してください。
余談ですが、terraform.tfvarsと*.auto.tfvarsファイルは自動で読み込まれますが
それ以外はterraform applyするときに-var-fileで渡してやらないと読み込まれないので、
複数の環境にapplyしたい場合はtfvarsを複数作成して使い分けるといいらしいです。
provider "google" {
project = var.target_project
region = var.region
}
provider "google-beta" {
project = var.target_project
}
変数
variable target_project {
description = "BQとGCFのプロジェクト"
type = string
}
variable region {
description = "リソースを作るリージョン(GCSバケットとおなじもの)"
type = string
}
variable zone {
description = "使いたいゾーン"
type = string
}
variable gcs_project {
description = "GCSバケットがあるプロジェクト"
type = string
}
variable bucket_name {
description = "GCSバケット名"
type = string
}
BigQuery
GCSバケットと同じリージョンにしてやる必要があります。
resource "google_bigquery_dataset" "dataset" {
dataset_id = "qiita"
delete_contents_on_destroy = true
location = var.region
}
resource "google_bigquery_table" "table_qiita" {
dataset_id = google_bigquery_dataset.dataset.dataset_id
table_id = "qiita"
schema = file("../../bigquery/bq.json")
deletion_protection = false
}
権限
functionを実行するサービスアカウントに対象のGCSバケットのオブジェクトを操作する権限を与えます。
data "google_app_engine_default_service_account" "sa_functions" {
}
resource "google_storage_bucket_iam_binding" "binding_gcs_ulog" {
bucket = "${var.bucket_name}"
role = "roles/storage.objectAdmin"
members = [
"serviceAccount:${data.google_app_engine_default_service_account.sa_functions.email}",
]
}
GCS通知
CloudFunctionsのトリガーにはGCSバケットへのファイル連携がありますが、別プロジェクトのバケットは指定できないので、GCSバケットへのファイル連携通知(Pub/Sub トピック)を作成し、それをトリガーにしてやります。
resource "google_pubsub_topic" "topic_notification_gcs" {
name = "topic-notification-gcs"
}
resource "google_storage_notification" "notification_gcs" {
bucket = "${var.bucket_name}"
payload_format = "JSON_API_V1"
topic = "${google_pubsub_topic.topic_notification_gcs.id}"
event_types = ["OBJECT_FINALIZE"]
depends_on = [google_pubsub_topic_iam_binding.binding]
}
data "google_storage_project_service_account" "gcs_account" {
project = "${var.gcs_project}"
}
resource "google_pubsub_topic_iam_binding" "binding" {
topic = google_pubsub_topic.topic_notification_gcs.id
role = "roles/pubsub.publisher"
members = ["serviceAccount:${data.google_storage_project_service_account.gcs_account.email_address}"]
}
CloudFunctions
zip化されたソースとそれを置くGCSバケットが必要なので作成しています。
GCSバケット名は一意のものである必要があるため、ランダムな文字列を末尾につけています。
data "archive_file" "archive_gcf_source" {
type = "zip"
source_dir = "../../functions/GcsToBq"
output_path = "../../functions/zip/gcf_gcs_to_bq.zip"
}
resource "random_id" "suffix" {
count = 1
byte_length = 2
}
resource "google_storage_bucket" "gcs_gcf_source" {
name = "bkt-gcf-source-qiita-${random_id.suffix[0].hex}"
location = "${var.region}"
storage_class = "STANDARD"
uniform_bucket_level_access = true
force_destroy = true
}
resource "google_storage_bucket_object" "source_gcf" {
name = "functions/zip/GcsToBq/${data.archive_file.archive_gcf_source.output_md5}.zip"
bucket = "${google_storage_bucket.gcs_gcf_source.name}"
source = "${data.archive_file.archive_gcf_source.output_path}"
}
resource "google_cloudfunctions_function" "gcf_gcs_to_bq" {
name = "gcf-gcs-to-bq"
runtime = "go113"
timeout = 540
entry_point = "GcsToBq"
event_trigger {
event_type = "providers/cloud.pubsub/eventTypes/topic.publish"
resource = "${google_pubsub_topic.topic_notification_gcs.name}"
}
source_archive_bucket = "${google_storage_bucket.gcs_gcf_source.name}"
source_archive_object = "${google_storage_bucket_object.source_gcf.name}"
environment_variables = {
PROJECT_ID = "${var.target_project}"
DATASET_ID = "${google_bigquery_dataset.dataset.dataset_id}"
TABLE_ID = "${google_bigquery_table.table_qiita.table_id}"
BUCKET_ID = "${var.bucket_name}"
}
}
結果
GCSバケットにcsvを置いてみます。
"aaaa",4,4
"bbb",5,
"ccccc",87438,
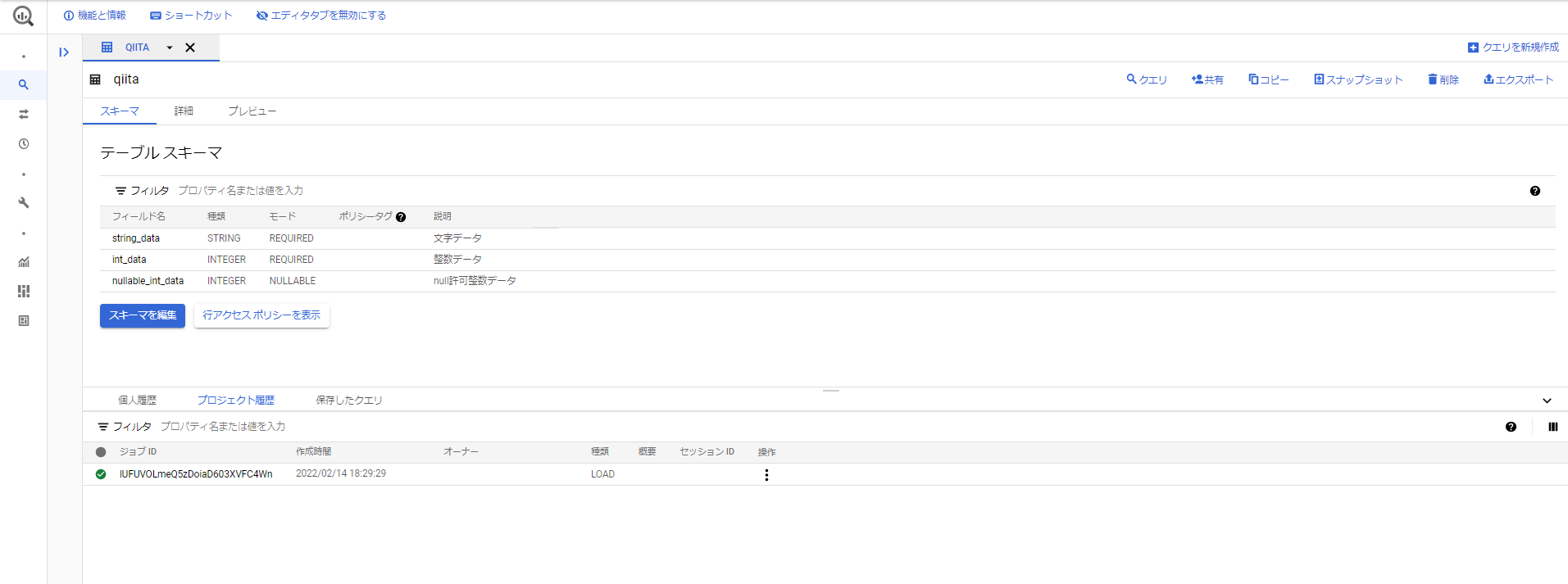
BigQueryを開いてページ下部の「プロジェクト履歴」から処理の結果を見ることができます。
うまくインポートしてくれたようです。
参考
偉人に感謝