背景
PowerPoint の資料Reviewで一部のフォントが間違っていると指摘をいただきました。
100ページ以上のスライドのどこのフォントが違っているかを、一つずつチェックして修正…。
目検でやりたくなかったですし、これから先も同様の作業をする可能性があるので効率的にできないか…と思いました。
python-pptx
今の時代 python でできないことなんてないやろ!
調べてみると、python-pptx で python から PowerPoint のファイルが操作できることがわかりました。
公式ページ:python-pptx
オブジェクトのイメージ
Qiitaの偉大な先駆者様達の記事を参考に、公式の Getting Start を少し触りました。
なんとなくイメージがついたので、下記にDumpします。
(間違っていたらご指摘をお願いいたします…)
全体の俯瞰図
Presentation > slides[] > shapes[] > text_frame.paragraphs[] > runs[]
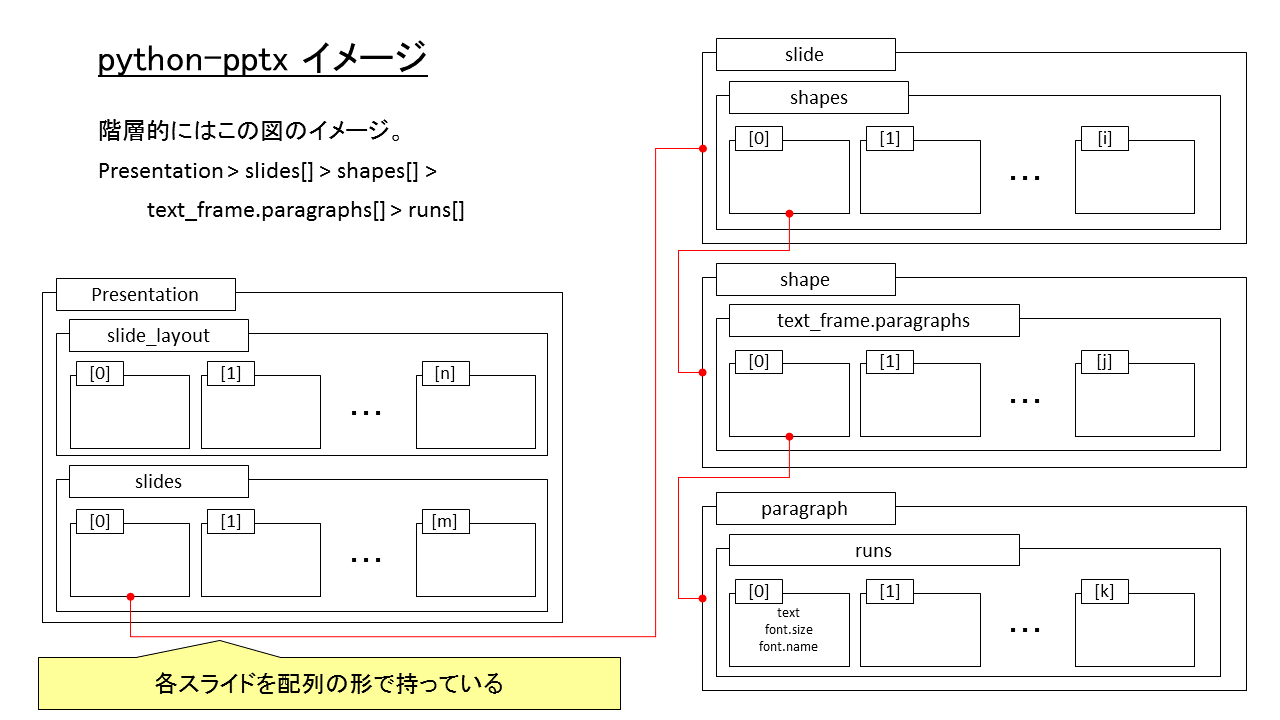
shapes[] とスライドの対応
slide はそのスライド内のオブジェクトを shapes[] に配列の形で持っている。
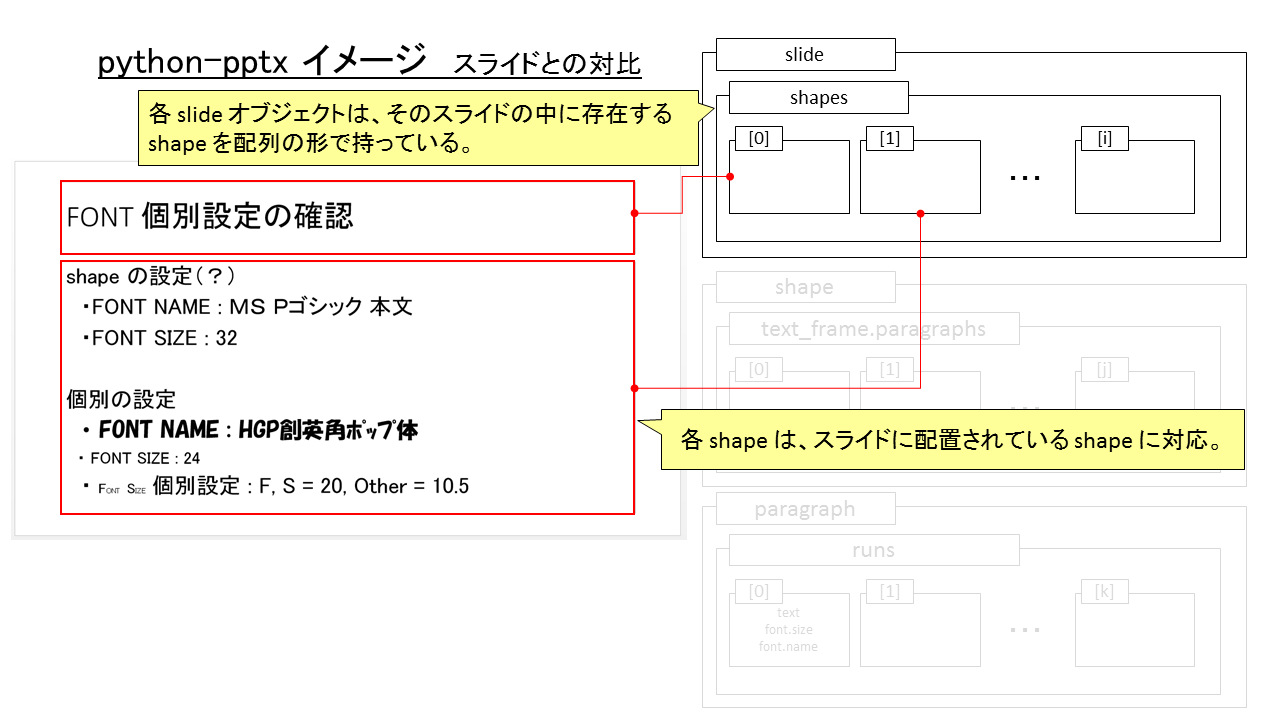
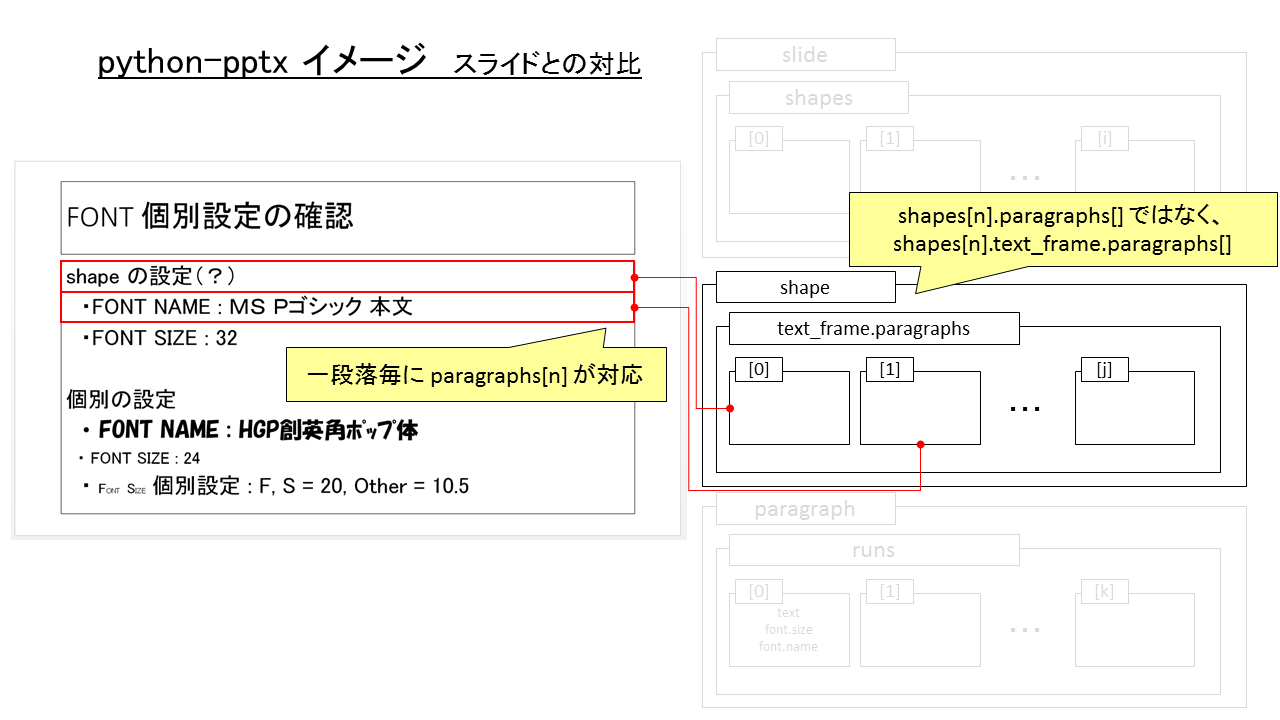
text_frame.paragraphs[] とスライドの対応
shape の中で、文字を持てるもの(?)は text_frame.paragraphs[] を持てる。
よく shapes[n].paragraphs[m] でアクセスしようとしてエラーになってました…。
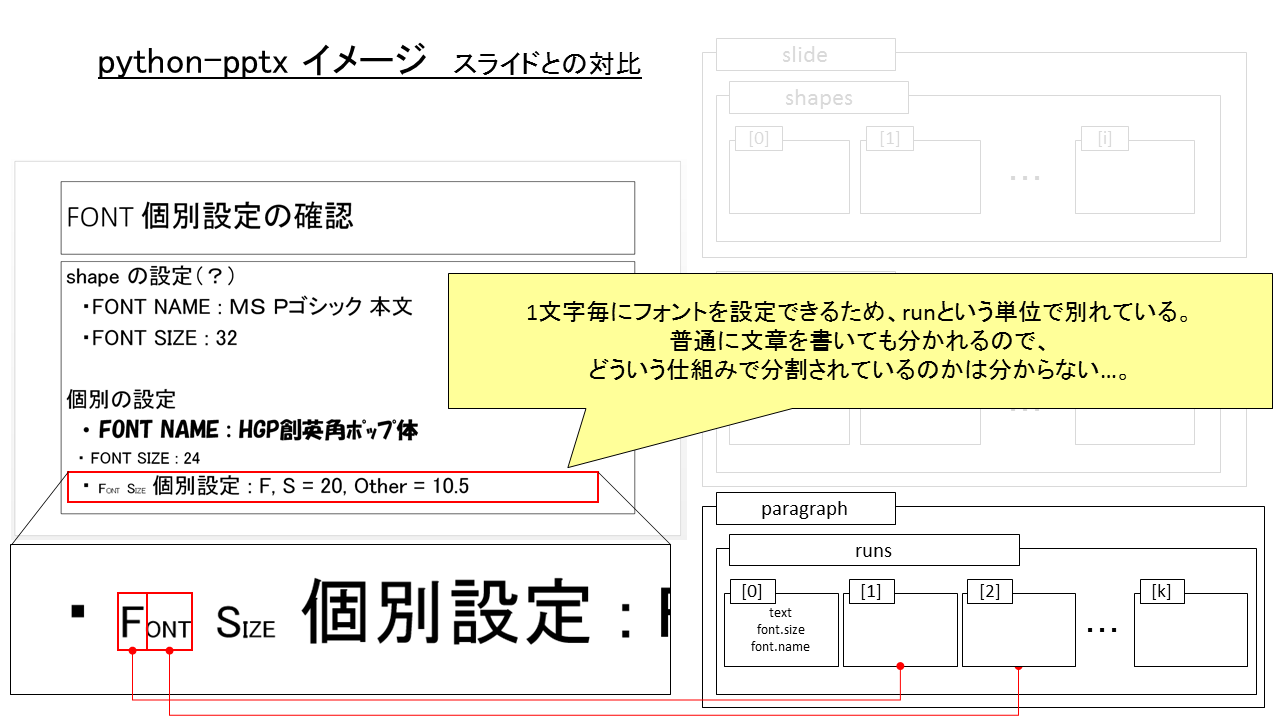
runs[] とスライドの対応
1文字毎にフォントを変えられますが、どうやって持っているんだろう…と、前々から疑問でした。
run という単位で持っているようで、それぞれにフォントが設定できます。
作ったもの
全スライドの全 paragraphs と runs を csv に dump。
TARGET_FILE_PATH には対象の powerpoint ファイルへのパスを、OUTPUT_FILE_PATH には出力の csv のファイルへのパスを設定。
from pptx import Presentation
from pptx.util import Pt
import csv
TARGET_FILE_PATH = './targetFile/targetFile.pptx'
OUTPUT_FILE_PATH = './output.csv'
FONT_SIZE_DIVESER = 12700
# ["pptxFile名","slide番号","object番号","run番号","オブジェクトタイプ"," font.name"," font.size"," text"]
def export_slide_fonts_and_text():
outputArray = []
outputArray.append(["pptxFile名","slide番号","object番号","paragraph番号","run番号","オブジェクトタイプ"," font.name"," font.size"," text"])
# ppt file の読み込み
prs = Presentation(TARGET_FILE_PATH)
slide_number = 0
# スライドの読み込み
for slide in prs.slides:
shape_number = 0
# shape ごとに処理
for shape in slide.shapes:
if not shape.has_text_frame:
shape_number = shape_number + 1
continue
paragraph_number = 0
# paragraph の段階で一旦出力
for paragraph in shape.text_frame.paragraphs:
if(paragraph.font.size != None):
fontSize = paragraph.font.size/FONT_SIZE_DIVESER
else:
fontSize = None
outputArray.append([TARGET_FILE_PATH, slide_number, shape_number,paragraph_number, "-","paragraph", str(paragraph.font.name), str(fontSize), paragraph.text])
run_number = 0
# runを各々出力
for run in paragraph.runs:
if(run.font.size != None):
fontSize = run.font.size/FONT_SIZE_DIVESER
else:
fontSize = None
outputArray.append([TARGET_FILE_PATH, slide_number, shape_number,paragraph_number, run_number, "run", str(run.font.name), str(fontSize), run.text])
run_number = run_number + 1
paragraph_number = paragraph_number + 1
shape_number = shape_number + 1
slide_number = slide_number +1
# 書き込み
with open(OUTPUT_FILE_PATH, 'w', encoding="shift-jis") as f:
wirter = csv.writer(f, lineterminator='\n', quoting=csv.QUOTE_ALL)
wirter.writerows(outputArray)
if __name__ == "__main__":
export_slide_fonts_and_text()
出力されたものを少し加工
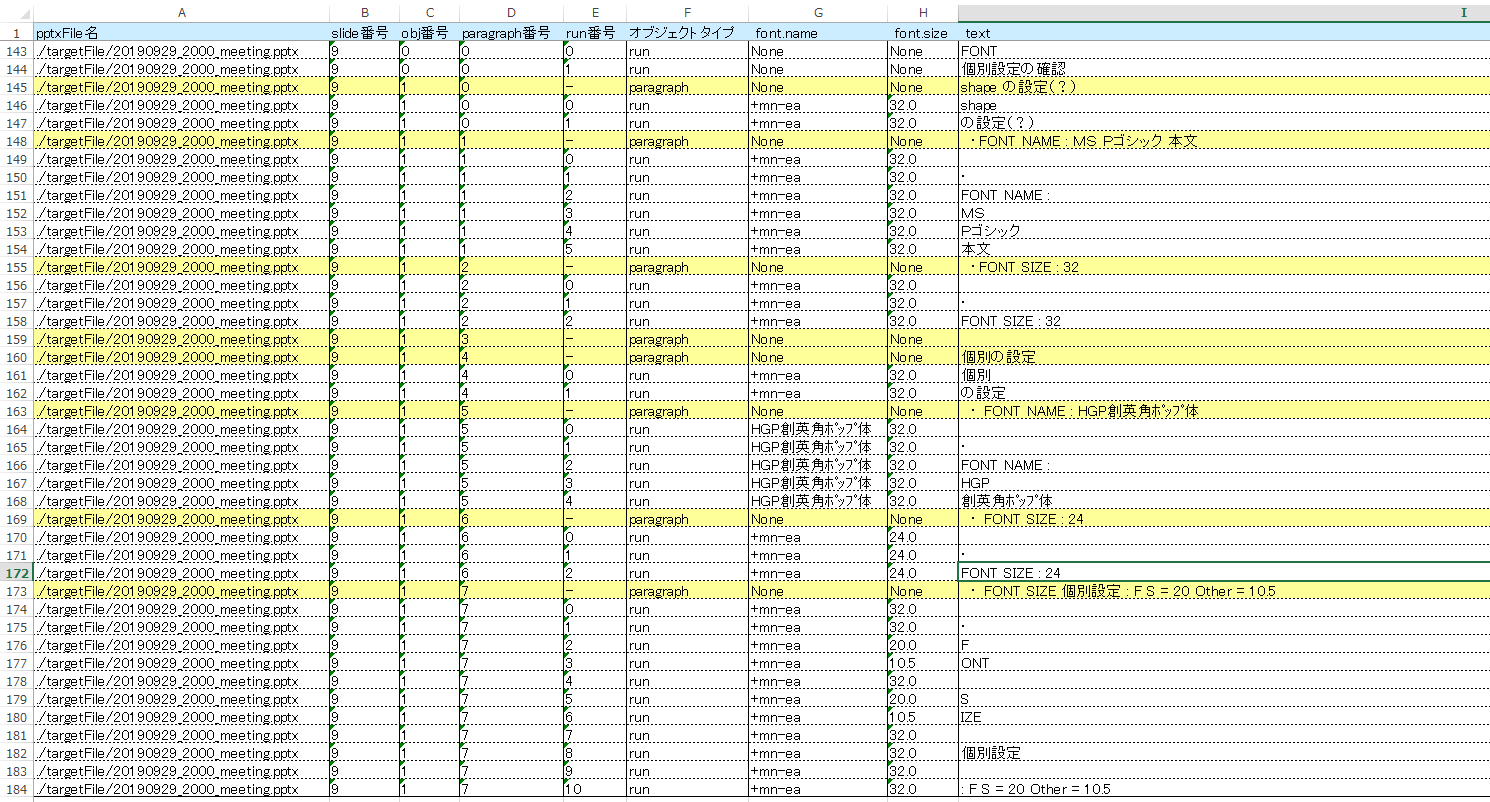
csv で出力されたものを、Excel に貼って色を付けて見たものが下記です。
大体ですが、やりたいことができていそうな感じです!
ToBe
デフォルトの値を取ってくる
上記のExcelにある通り、フォント名やフォントサイズが「None」となっているところが多くあります。
値が設定されていない場合デフォルトの値を参照するそうです。
placeholder にアクセスすることで取得できそうなのですが…もう少し調べてみたいと思います。
参考にさせていただいた先駆者様
ありがとうございます…。
圧倒的感謝…!
python-pptxまとめ
python-pptxでレポーティングを自動化する
[Python]爆速で報告パワポを生成する!
Pythonを使ったレポートの自動作成【PowerPoint】【python-pptx】
https://qiita.com/code_440/items/22e8539da465686496d3