はじめに
データ分析を行っているとたくさんのグラフやデータが出力されますよね。そんな時に体裁の整ったスライドをサクッと生成できれば、非エンジニアの上司への説明や自分で振り返る時、ライトニングトーク等で役に立ちます。そこで、Pythonからパワポを生成する時に便利な関数を用意しました。
出力サンプル



パワポを生成するライブラリ
今回使うモジュールはこれです。製作者に感謝。
インストール方法は
pip install python-pptx
もしくは
conda install -c conda-forge python-pptx
そして、利用している記事もいくつか存在します。
Pythonで簡単なパワポファイルの作成 - Qiita
Pythonでパワポの説明資料(報告書)を生成する - Qiita
python-pptxまとめ - Qiita
今回、関数を作った理由
モジュールが高機能かつ複雑で、サクッと利用できなくてモヤモヤしました。
そこで、シンプルなAzusaをベースに、基本的なスライド様式を生成できるようにしました。
前準備
今回は以下のテンプレートを利用してスライドを作ります。
とりあえずいい感じになるPowerPointテンプレート「Azusa Colors 改」を作った | Webale
ダウンロードして以下の変更を加えました。
- 名前の変更
- 全スライドの削除(削除しない場合、スライドが追加されます)
- スライドマスターの変更
- タイトルスライドを中央揃え
- メインスライドのプレースホルダの中央配置
- メインスライドのプレースホルダから段落記号を削除
便利関数
よく使うモジュールの機能をまとめました。
function
# タイトルスライド挿入
def ppt_title(prs,slide_layout,title="タイトル",name="名前"):
prs.slides.add_slide(slide_layout)
prs.slides[-1].placeholders[0].text = title
prs.slides[-1].placeholders[1].text = name
return prs
# check_placeholdes
def layout_placeholders(prs,layout_num):
temp = copy.deepcopy(prs)
slide_layout = temp.slide_layouts[layout_num]
temp.slides.add_slide(slide_layout)
for shape in temp.slides[-1].placeholders:
print('%d %s' % (shape.placeholder_format.idx, shape.name))
# get_size_list
def get_size_list(shape):
top = shape.top
left = shape.left
height = shape.height
width = shape.width
size_list = [top,left,height,width]
return size_list
# プレースホルダサイズ取得
def get_size_placeholders(prs,slide):
temp = copy.deepcopy(prs)
shape = temp.slides[slide].placeholders[1]
top,left,height,width = shape.top,shape.left,shape.height,shape.width
size_list = [top,left,height,width]
return size_list
# メインスライド挿入
def ppt_main(prs,slide_layout,title="タイトル"):
prs.slides.add_slide(slide_layout)
prs.slides[-1].placeholders[0].text = title
return prs
# プレースホルダにテキスト挿入
def add_txt(prs,level,size,bold=False,text="main",font_name=False,layout=1):
tf = prs.slides[-1].placeholders[layout].text_frame
p = tf.add_paragraph()
p.level = level
run = p.add_run()
run.text = text
font = run.font
if font_name:
font.name = font_name
font.size = pptx.util.Pt(size)
font.bold = bold
return prs
# プレースホルダに最初の段落にテキスト挿入
def add_txt_f(prs,level,size,bold=False,text="main",layout=1):
tf = prs.slides[-1].placeholders[layout].text_frame
tf.text = text
tf.paragraphs[0].font.size = pptx.util.Pt(size) # font size
tf.paragraphs[0].font.bold = bold # font bold
return prs
# 複数段落分割
def split_txts(txts):
# txt = ["level0",0,"level1",1]
txt_list = [txts[idx:idx + 2] for idx in range(0,len(txts), 2)]
txt_list = [ i + [40,False] for i in txt_list]
return txt_list
# 複数行入力
def add_txt_multi(prs,txt_list,font_name=False):
for i in txt_list:
text,level,size,bold = i
prs = add_txt(prs,level=level,size=size,text=text,bold=bold,font_name=font_name,layout=1)
return prs
# 画像インメモリ保存
def save_memory_PIL(PIL_image):
item = io.BytesIO()
PIL_image.save(item,"png")
item.seek(0)
return item
# 横長アスペクト比チェック
def aspect_yokonaga(width,height):
result = True
if int(height/width):
result = False
return result,height/width
# プレースホルダ縮小
def shrink_size(size_list,h_mag=1,w_mag=1):
top,left,height,width = [int(i) for i in size_list]
height_sh = int(height * h_mag)
width_sh = int(width * w_mag)
top,left = (top+height)-height_sh,(left+width)-width_sh
height,width = height_sh,width_sh
size_list = [top,left,height,width]
size_list = [pptx.util.Length(i) for i in size_list]
return size_list
# プレースホルダ分割
def split_size(size_list,h_split,w_split,margin=0):
result = []
top,left,height,width = size_list
mar_i = pptx.util.Cm(margin)
for i in range(1,h_split+1,1):
for j in range(1,w_split+1,1):
top_s = top + height*((i-1)/h_split)
left_s = left + width*((j-1)/w_split)
height_s = height*(1/h_split)
width_s = width*(1/w_split)
top_s,left_s,height_s,width_s = top_s + mar_i ,left_s+mar_i,height_s-2*mar_i,width_s-2*mar_i
split_temp = top_s,left_s,height_s,width_s
split_temp = [pptx.util.Length(x) for x in split_temp]
result.append(split_temp)
return result
# 画像貼り付け
def image_plot(PIL_img,prs,size_list):
item = save_memory_PIL(PIL_img)
slide = prs.slides[-1]
top,left,height,width = size_list
img = Image.open(item)
place_aspect_bool,place_aspect = aspect_yokonaga(width,height)
image_aspect_bool,image_aspect = aspect_yokonaga(*img.size)
if place_aspect>=image_aspect:
pic = slide.shapes.add_picture(item, left=left, top=top,width=width)
else:
pic = slide.shapes.add_picture(item, left=left, top=top,height=height)
pic.left = pic.left+pptx.util.Length((width-pic.width)/2)
pic.top = pic.top+pptx.util.Length((height-pic.height)/2)
return prs
# add table
def df_to_table(prs,df,size_list,font_size,RGB=[0,0,0],index=False):
slide = prs.slides[-1]
top,left,height,width = size_list
if index:
df = df.reset_index()
row, col = df.shape
shape = slide.shapes.add_table(rows=row+1, cols=col, left=left, top=top, width=width, height=height)
table = shape.table
def iter_cells(table):
for row in table.rows:
for cell in row.cells:
yield cell
# columns
for i,j in enumerate(df.columns):
cell = table.cell(0,i)
cell.text = j
# value
for i in range(0,len(df),1):
for j in range(0,len(df.columns),1):
cell = table.cell(i+1,j)
cell.text =str(df.iat[i,j])
# font_size
for cell in iter_cells(table):
for paragraph in cell.text_frame.paragraphs:
for run in paragraph.runs:
run.font.size = pptx.util.Pt(font_size)
run.font.color.rgb = pptx.dml.color.RGBColor(*RGB)
return prs
スライドに入れるデータの準備
スライドに張り付ける画像と表を用意しておきます。
# generate_image
from PIL import Image, ImageDraw, ImageFont
im_list = []
for i in range(1,5,1):
im = Image.new("RGB",(128,128),"red")
draw = ImageDraw.Draw(im)
font = ImageFont.truetype("arial.ttf", 128)
draw.text((24,0),str(i),size=100,font=font)
im_list.append(im)
# generate_df
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
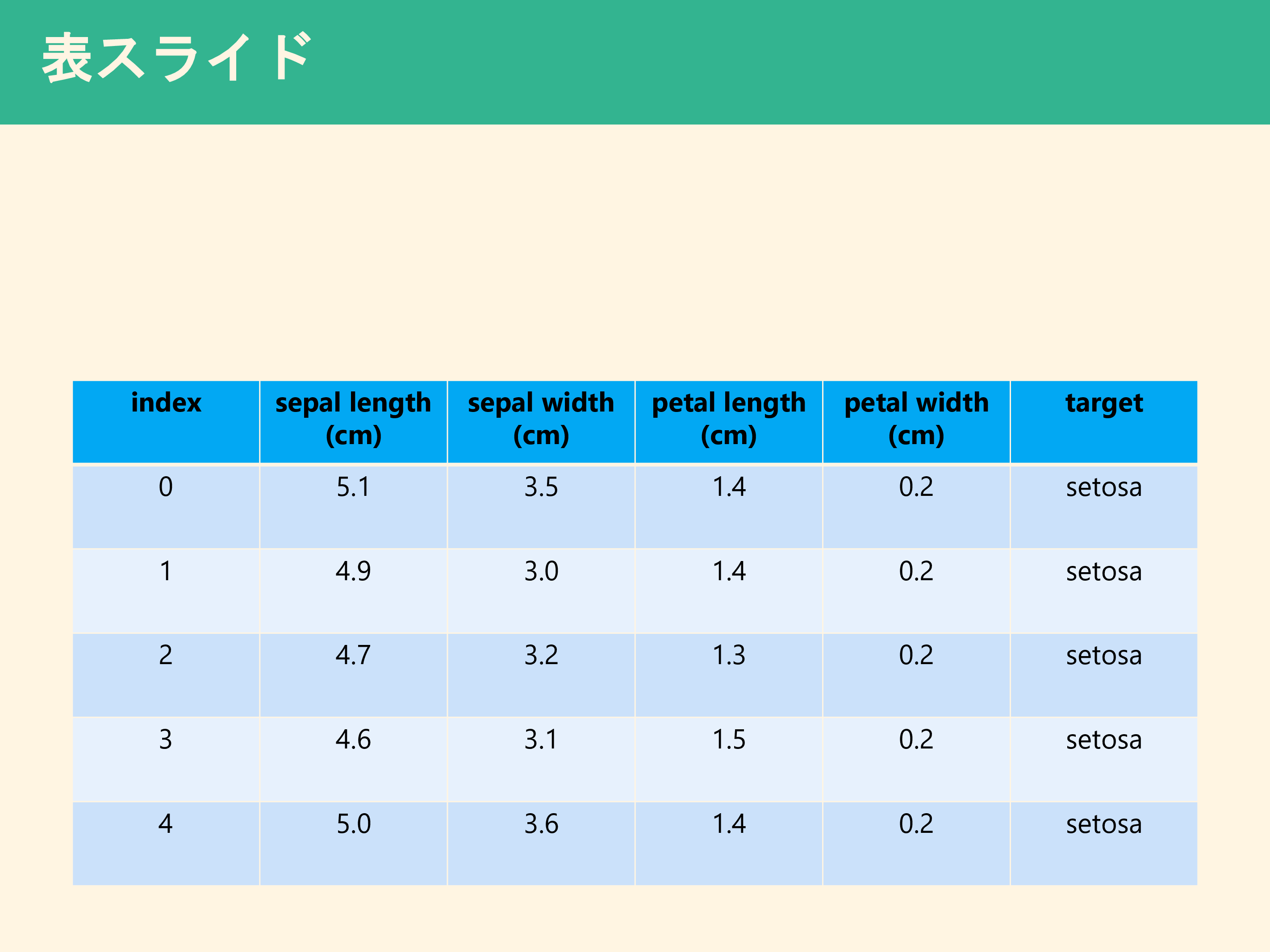
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target_names[iris.target]
df = df.head()
スライド生成
以下のコードを実行するとスライドを生成することができます。
import pptx
import copy
import subprocess
import io
import PIL
temprate_pptx = "./azusa.pptx"
p_exe = r"C:\Program Files (x86)\Microsoft Office\root\Office16\POWERPNT.EXE"
# set temprate
prs = pptx.Presentation(temprate_pptx)
# set_layout
title_slide_layout = prs.slide_layouts[0]
main_slide_layout = prs.slide_layouts[3]
# add title slide
prs = ppt_title(prs,slide_layout=title_slide_layout)
# add main slide
prs = ppt_main(prs,slide_layout=main_slide_layout)
prs = add_txt_f(prs,0,40,text="first")
prs = add_txt(prs,0,40,text="second")
txts = ["level-0",0,"level-1",1,"level-2",2,"改行_lve\nl-2",2]
txt_list = split_txts(txts)
prs = add_txt_multi(prs,txt_list)
# add image
prs = ppt_main(prs,slide_layout=main_slide_layout,title="単一画像スライド")
size_list = get_size_placeholders(prs,-1)
prs = add_txt(prs,0,40,text="画像説明")
size_list = shrink_size(size_list=size_list,h_mag=0.7)
item = save_memory_PIL(im)
prs = image_plot(im_list[0],prs,size_list)
# add multi image
prs = ppt_main(prs,slide_layout=main_slide_layout,title="マルチ画像スライド")
prs = add_txt(prs,0,40,text="画像説明")
size_list = get_size_placeholders(prs,-1)
size_list = shrink_size(size_list=size_list,h_mag=0.7)
size_lists = split_size(size_list,2,2,margin=1)
for i,j in zip(im_list,size_lists):
prs = image_plot(i,prs,j)
# add df to table
prs = ppt_main(prs,slide_layout=main_slide_layout,title="表スライド")
slide = prs.slides[-1]
size_list = get_size_placeholders(prs,-1)
size_list = shrink_size(size_list=size_list,h_mag=0.7)
prs = df_to_table(prs,df,size_list,22,index=True)
# export pptx
export_file = "./test.pptx"
prs.save(export_file)
# show pptx
subprocess.Popen([p_exe,export_file])
まとめ
これからデータサイエンスが盛んになってくる時代に、如何にデータ出力から結果アウトプットまで爆速で回せるかが大切になります。
この記事を参考にしてもらって、より良いアウトプットを皆ができるようになればと思います。