さあ、謎解きの始まりだ
元記事:ディープラーニングさえあれば、競馬で回収率100%を超えられる
まずは動かしてみる
早速プログラムを購入して動かしてみます。
説明にも書かれてある通り、基本的にはコピペで動作しましたが、以下2箇所はそのままでは動かなかったので、こちらで修正しました。
- 日付データのパースをしているところ
- 学習・推論に利用する特徴のカラム名
ランダム要素を含むため全く同じとはなりませんが、グラフも概ね同じような動きになったので、再現したようです。
記事に書いてあるような、**"3着指数が60以上、かつオッズが高すぎない一部の範囲(55〜60あたり)"**を購入するようにすると、僕の手元でも100%を超えました。
レース数・レコード数が増えているのは先週(エリザベス女王杯の週)の分かと思われます。
僕が実行した結果
| 項目 | 結果 |
|---|---|
| 対象レース数(※) | 3672 |
| 対象レコード数 | 42299 |
| 購入数 | 74 |
| 的中数 | 13 |
| 的中率 | 17.57% |
| 回収率 | 172.97% |
元記事での結果
| 項目 | 結果 |
|---|---|
| 対象レース数(※) | 3639 |
| 対象レコード数 | 41871 |
| 購入数 | 98 |
| 的中数 | 20 |
| 的中率 | 20.4% |
| 回収率 | 213.3% |
どういう馬が予測されているのだろう
どういう馬を買って100%を超えたのだろう?メインレースより条件戦の方を狙っているのかな? 競馬ファンなら気になりますよね。
ところが検証用データのDataFrameには馬名が入っておらず、馬番や人気なども前処理加工された値ばかりが入っており、オッズもrawデータではなかったためとてもわかりにくかったです。別途データを作成しなければ、調べることができませんでした.
ディープラーニングから他のモデルに変更してみる
これは僕が変更したコードです。
シンプルなニューラルネットワークと比較しても、もっとシンプルなロジスティック回帰に変更してみます。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(C=2.0, penalty='l1', random_state=42, multi_class="auto")
model.fit(df_train, train_labels)
今度はこのモデルの出力model.predict_proba(df)[:, 1]を3着指数として、先ほどと同じように"3着指数が60以上、かつオッズが高すぎない一部の範囲(55〜60あたり)" を購入するようにしてみます。
| 項目 | 結果 |
|---|---|
| 購入数 | 175 |
| 的中数 | 21 |
| 的中率 | 12.0% |
| 回収率 | 127.26% |
| すごいです. ロジスティック回帰でも100%を超えました! | |
| ちなみにランダムフォレストだと196%となりました! |
データがおかしい?
どうもディープラーニング云々ではなくデータに何らかのバイアスがかかっているような気がします。
購入方法を検討しているところは、以下のようになっています。
# オッズ(標準化)が1〜8の範囲を購入するなら0.01〜0.08を設定
if win3_pred >= 0.60 and 0.01 <= odds < 0.08:
return 1
else:
return 0
win3_predは100倍する前の3着指数です。
オッズを標準化したままなのが気になります(0.01〜0.08は、普通の単勝オッズ55〜60あたりに相当)が、ここで以下のように書き換えてみます。
if 0.01 <= odds < 0.08:
return 1
else:
return 0
3着指数を全く使わずに単勝オッズが55〜60倍の時に複勝馬券を購入するシュミレーションです。
| 項目 | 結果 |
|---|---|
| 購入数 | 778 |
| 的中数 | 68 |
| 的中率 | 8.74% |
| 回収率 | 90.67% |
| 複勝馬券の控除率は20%のため、単純にオッズのみで範囲を指定してもある程度回収率80%付近になるのが自然です。大穴馬券であれば一発が大きいので、ブレはあるでしょうが90%は少し高いような気もします。 | |
| もしかしたら、検証用データ自体に問題があるかもしれません。 | |
| 前処理・データ加工しているところを調べてみましょう。 |
過去5走の戦績が揃わない馬は捨てる
まず引っかかったのはここです
# 情報不足行を削除
df = df.dropna(subset=[
'past_time_sec1', 'past_time_sec2', 'past_time_sec3',
'past_time_sec4', 'past_time_sec5'
]).reset_index(drop=True)
past_time_sec1〜past_time_sec5はその馬の過去5走のタイムを表します。
ということは、過去5走のタイムがすべて揃っていない馬はここで捨てられています。
特に2, 3歳戦では各馬の出走数にばらつきがあるものです。例えば先週2019/11/10の福島10R福島2歳Sだと、出走馬14頭(https://race.netkeiba.com/?pid=race_old&id=c201903030410) ですが、過去5走のタイムが揃っているのは3頭であり、実際に削除後のdataframeには3頭しかいませんでした。
このdropnaで、レコード数は471500件 -> 252885件 となりました。
**なんと半分近くのデータが捨てられています。**ここで捨てられたデータは2, 3歳馬、地方馬(地方競馬はデータを取得していないため)、2010年のデータ(2009年のデータがないため前走情報が取得できない)が中心でした。
適切とは思えないのですが推論時も同じルールで除外することができるため、致命的なミスでもありません。
複勝は何着まで払い戻される?
複勝馬券は、出走頭数が8頭以上の場合3着までが当たり、5〜7頭の場合は2着までが当たり、4頭以下の場合は発売がありません。
以下の処理を検証用データに対して行なっていました。
# 複勝2頭以上、全5頭以上レースに絞る
win3_sums = df.groupby('race_id')['win3'].sum()
win3_races = win3_sums[win3_sums >= 2]
win3_races_indexs = win3_races.index.tolist()
win3_counts = df.groupby('race_id')['win3'].count()
win3_races2 = win3_counts[win3_counts >= 5]
win3_races_indexs2 = win3_races2.index.tolist()
race_id_list = list(set(win3_races_indexs) & set(win3_races_indexs2))
この処理によってレコード数は 48555 -> 42999 となり、11.4%のデータが捨てられます。
本来捨てたいのは、複勝の払い戻しのなかったレースのはずですが、どう考えても多すぎます。
実際には、2018〜2019年にJRAで4頭以下の競争は行われていません(少なくとも僕のkeibadbではそうなっている)
この処理は問題です。
何が起こっているのだろう
何が問題なのでしょう。
win3は複勝圏内の着順に入ったかどうかを表す目的変数なので、上の処理では複勝圏内に入った馬を数えて2頭以上、かつ出走頭数を数えて5頭以上としています。
でも、思い出してください。過去5走の戦績が揃わない馬はすでに捨てているため、本来消すべきではない馬が消えています.
少しわかりにくいですが、具体的に見てみましょう。例えば2019年11月2日の京都12R。
https://race.netkeiba.com/?pid=race&id=p201908050112&mode=shutuba
4番ボッケリーニ、7番サンレイポケット、9番ナリタブルー、10番テーオーアマゾン、12番メトロポールの5頭は、近5走のレースタイムが揃わないため事前にレコードは除外されており、8頭立てのレースと捉えることになります。
このレースの着順は、4-3-7となりました.13頭立てのレースなので、複勝は4, 3, 7が当たりです。
しかし4、7番の馬はすでにDataFrameから消されているため、このレースで複勝馬券になったのは1頭だけということになるため、このレースでは複勝圏内の馬が1頭ということになり、検証データから除外されます。
レース前にどの馬が複勝馬券になるか当然わからないため、この操作は未来のレースに対して行うことができません
ちなみにこのレースの5番ニホンピロヘイローは単勝オッズが60倍でしたが負けてしまいました.(検証データ的には55〜60倍で負ける馬を1頭買わなくて良くなった)
少しずつ見えてきました。学習モデルに関係なく、検証データから消えている馬たちがいて、どうやらバイアスがかかっていそうです。
正しいデータで検証しよう
では不適切な絞り込みをせずに推論を行ってみます。
2018〜2019年に複勝払い戻しのなかったレースは存在しないため、さきほどの検証データに対する絞り込みは必要ありません。コメントアウトして絞り込んでいない検証データに対して購入のシミュレーションをしてみましょう
| 項目 | 結果 |
|---|---|
| 対象レース数(※) | 5384 |
| 対象レコード数 | 48555 |
| 購入数 | 88 |
| 的中数 | 13 |
| 的中率 | 14.77% |
| 回収率 | 145.45% |
この145%という回収率は、
- 3着指数(ディープラーニングのモデルの予測値)
- 前5走のタイムが揃っていない馬は買わない
- 単勝オッズ55〜60倍
この三つの条件で達成されています.
的中率・回収率ともに下がりましたが、普通に儲かる計算です.これがディープラーニングの実力なのでしょうか?
どういう馬を高く評価しているのだろう
どういう時に3着指数が高くなるのでしょう?
3着指数が0.5より大きいか小さいかというクラスを正解データとして、はDecisionTreeで学習してみました。
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(max_depth=3)
clf = clf.fit(df[all_columns], df.win3_pred > 0.5)
できた木を可視化してみます。
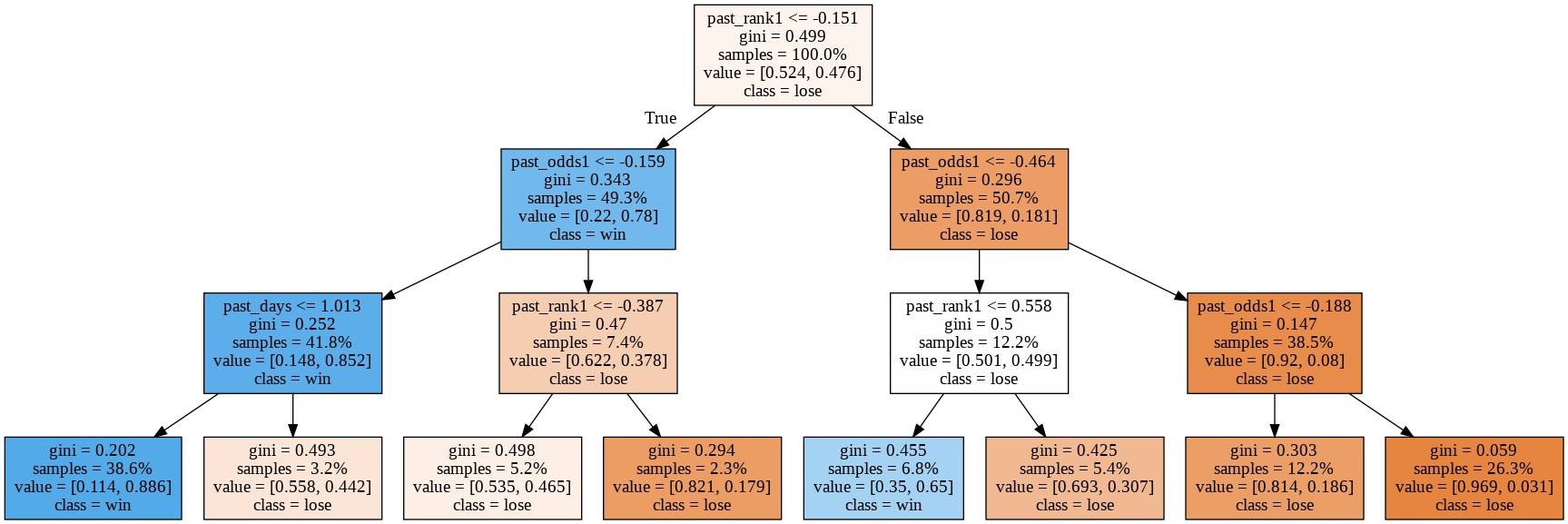
どうやら、past_odds1つまり、前走の単勝オッズや前走の着順が重要なように見えます。
今度は購入条件の3着指数を単純にルールベースの前走の単勝オッズ10倍以下と指定してみます。
# if win3_pred >= 0.60 and 0.01 <= odds < 0.08:
if raw_past_odds1 <= 10 and 55 <= raw_odds <= 60:
| 項目 | 結果 |
|---|---|
| 購入数 | 115 |
| 的中数 | 15 |
| 的中率 | 13.04% |
| 回収率 | 147.22% |
ディープラーニングによって学習されたモデルの出力を使わずに、たった一つのルールを使っても同等の回収率が出せました。
もう一度全データを見直す
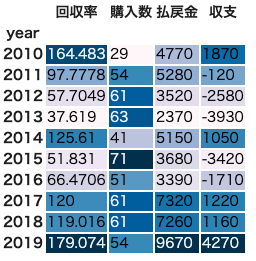
単勝オッズ55〜60倍のデータに対して2018〜2019年だけでなく、2010年まで遡ってみてみましょう。
全レコード471500件について、単勝オッズ55〜60倍の馬
pivot_df = df2[(df2['odds'] >= 55) & (df2['odds'] <= 60)].groupby('year') \
.fukusho.agg(["mean", "count", "sum"])
pivot_df.columns = ["回収率", "購入数", "払戻金"]
pivot_df['収支'] = pivot_df['購入数'] * (-100) + pivot_df['払戻金']
pivot_df.style.background_gradient()
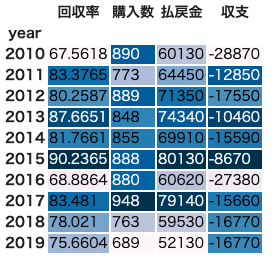
2015年の回収率が高いですが、概ね80%くらいです。
検証データである2018〜2019年も80%を切っており、特に高くはありません。
全5走のタイムが揃っていない馬かつ単勝オッズが55〜60倍の馬
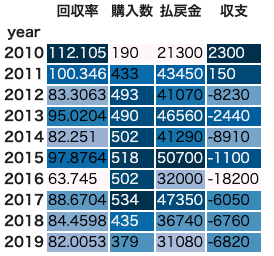
検証用データはこの状態です。
2016年だけ回収率が下がりましたが、それ以外の年については回収率が上がりました。
検証データである2018〜2019年も上がり、80%を超えました。
単勝オッズ55〜60倍かつ前走のオッズが10倍以内の馬
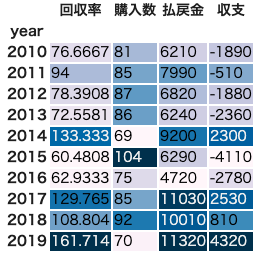
左が全データに対して、右が全5走の絞り込みありのデータに対してです。
先ほどディープラーニングと同等の数字を出した条件の各年ごとの成績(147.22%)は右の表の2018年と2019年を合わせたデータとなります。
同じ条件で購入しても、回収率が60%を下回るような結果となる年もあることがわかります。
結論
3着指数を前走単勝オッズ10倍以内に置き換えた条件が147.22%となったのは、2018〜2019年であるからこそであって、このルールで今後回収率100%を達成することは厳しそうです。
では3着指数はどうでしょう。3着指数と、前走オッズの関係をプロットすると...
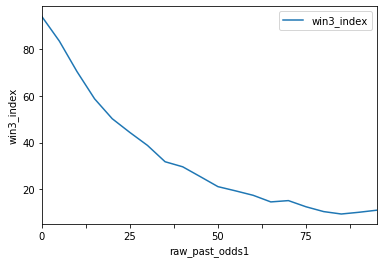
もちろん他の特徴も利用していますが、前走のオッズが低いほど3着指数も高くなることがわかります。
DecisionTreeが教えてくれた通りでした。
元記事は、「ディープラーニングさえあれば、競馬で回収率100%を超えられる」というタイトルでしたが、
実際には、「過去5走のタイムが揃っていない馬を除去して、単勝オッズ55〜60倍の馬の2018〜2019年11月の複勝馬券を購入するシミュレーションをすると回収率100%を超えるのは別にディープラーニングでなくルールでもできるし、たまたま」
といった内容ではないかと思います.
ディープラーニングがあるからといって、競馬で回収率100%を簡単に超えられるわけではないのではないでしょうか?
(一気に分析して一気に書いてしまったのでどこか間違えているかもしれません。間違えていたら教えてください)
データへの愛が足りない
この記事を通して言いたいことは、データをもっときちんと見ようということです。
今回の検証、謎が解けていくような感覚があって楽しかったです。基本的にデータは面白いものだと思っています。いろんな見方があるものですし、いろんな発見があるものです。タイタニック号の生存分析のデータだって、眺めているだけで面白いです。
データに対してきちんと向き合う中で、いろいろなことが見えてきます。そうやって良いモデルができるのであって、いくらディープラーニングや優れたアルゴリズムを使ったとしても、データを大事にしていないモデルは優れたAIとはなりません。
データと仲良くなってみたいけど何から始めたらいいかわからないという人がいたら、競馬場へ行ってみましょう!!儲からなくても楽しいですよ!!!