クラスを条件とした画像生成モデルであるAC-GANを使って、アニメ顔の画像生成してみました。
AC-GANとは
理論的な解説はこちらの記事で書いたので省略。一言でいうと、Dに真偽判定だけではなく、多クラス分類の機能をもたせたものです。

画像はhttps://github.com/gitlimlab/ACGAN-PyTorchより
CIFAR-10でやってみる
手始めとして論文の通りの設定でCIFAR-10を生成してみました。CIFAR-10の訓練データ5万枚を使っているため、1クラスあたりのデータ数は5000枚となります。
サンプリング

クラスラベルも潜在空間の変数も乱数から出力したものです。そこそこ綺麗に出ているのがわかります。
潜在空間の補間
AC-GANの論文によると、GANが上手くいっているかどうかを確認する一つの方法として、「潜在空間の補間を行うこと」とありました。これを実行してみます。
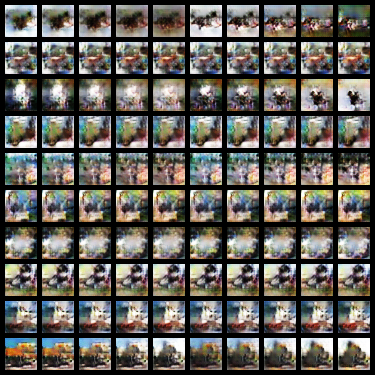
行方向でクラスラベルを固定し(0、1、2……)て任意の2つの画像を乱数で生成し、その2つの画像に対応する潜在空間を線形に補間し、対応する画像を生成します(列方向)。
出力画像がきれいかどうかはさておいて、このようにクラス単位で滑らかな補間ができれば上手くいっているということになります。
コード
AnimeFace Character Dataset(全種+論文と同じ)
こちらのAnimeFace Character Datasetを使い、論文と同じ設定で生成してみます。ただし、AnimeFace Character Datasetは176クラスで14490枚の画像があるため、1クラス平均82.3枚とCIFAR-10よりはかなり少ないデータセットになります。
サンプリング

ちょっと出力画像が粗い? ただしこれはネットワーク構造を見直すことで改善します(後述)。
潜在空間の補間

潜在空間の補間は上手く言っているように見えますが、実はクラス単位で同一の画像しか生成していないのではないかということに気づきます。
これは論文にかかれていたことなのですが、論文のImageNetによる実験では、大量のクラスを同一のネットワーク(AC-GAN)で訓練すると、出力画像の多様性が落ちてしまうという現象が確認されたそうです。ImageNetは1000個のクラスからなりますが、論文では10個のクラスを1つのネットワークとして訓練していました。これも後で試してみます。
コード
AnimeFace Character Dataset(全種+ResNetベース)
先程の全種のケースを、ネットワーク構造を変更して実験してみます。
変更点
- GのネットワークをResNetベースに変更する(詳細はコード参照)
- アップサンプリングのレイヤーをConvTransposeからPixelShufflerに変更する
- 損失関数をHinge関数に変更(GauGANの実装を参考にしました)
サンプリング

ネットワークをResNetベースにしたら明らかに綺麗になりました。ただし、多様性の面からは疑問があります(同じ画像を出力しているだけではないか)。
潜在空間の補間

このケースでは、潜在空間の補間がうまくいきませんでした。クラスのラベル(行方向)が効いていなく、それ以外のノイズ(横方向)で説明できてしまいます。データが少なすぎたのか、もしかしたら実装のどこかが良くなかったのかもしれません。
コード
AnimeFace Character Dataset(10種+論文と同じ)
オリジナルの設定に戻し、訓練するクラス数を10に減らします。具体的にはデータの多いクラス上位10個1を採用しました。
サンプリング

全種のクラスと比べて画質が若干良くなりました。論文に書いてあるとおり、AC-GANでは一度に訓練するクラス数が多すぎるのはよくないです。
潜在空間の補間

潜在空間の補間は少なくともクラス別の変数はうまく効いているというのがわかります。そこそこ形になっているのが5行目で、潜在空間の乱数によって背景のスタイルをコントロールできているのがわかります。
コード
AnimeFace Character Dataset(10種+ResNetベース)
最後にResNetベースで、クラス数10の場合を試してみました。
サンプリング

一部目の位置が怖い感じになっていますが、ぱっと見綺麗に言っているように見えます。ただ多様性の面が厳しそうですね。
潜在空間の補間

10種の場合よりかは、クラスの変数が効いているように見えます。しかし、キャラごとの違いが潜在空間の乱数で決まってしまい、class coditionalな生成は上手く行かなかったです。やはり1クラスあたりのデータ数が問題なのかもしれません。
コード
感想/まとめ
- CIFAR-10(1クラス5000)やImageNet(1クラス1300)のように、1クラスあたりのデータ数が多ければ、AC-GANでもかなりいい感じに生成できそう。AC-GAN自体は若干古い(2016年)モデルなので、最新形を使えばまだ伸びしろはある。
- AnimeFace Character Datasetでは1クラスあたりのデータ数が平均82.3枚で、画像そのものを綺麗に生成することはできたが、生成画像の多様性が課題。データ数が多いほど有利になるのはGANでも変わらない。
- そもそもクラス別にアノテーションされたアニメ絵の画像で、クラス数あたりそこそこの枚数があるデータセットというのを聞いたことがない(存在しない?)
- ResNetが生成画像の高画質化に非常に効いているので、WGANのようにGANの安定性を損失関数でカバーし、ネットワークやデータによる成功可否の依存性を打ち消せれば、GANはかなり有望だと思われる
-
木之本桜(カードキャプターさくら)、ララ・サタリン・デビルーク(ToLOVEる)、月村真由(ご愁傷さま二ノ宮くん)、向坂環(ToHeart2)、西連寺春菜(ToLOVEる)、天海春香(アイドルマスター)、宮村みやこ(ef)、めろんちゃん(メロンブックス)、スバル・ナカジマ(魔法少女リリカルなのはStrikerS)、日奈森あむ(しゅごキャラ!) ↩