AC-GANの論文を読んだのでメモがてらに解説書いていきます。発想としては非常にわかりやすいGANですが、考察が結構面白い論文でした。
AC-GANとは
GANのGeneratorの入力に画像のクラス情報を入れる(Coditional GAN)と同時に、Discriminatorの出力に通常の画像分類のような「多クラス分類」を入れます。通常のGANの損失関数にある「本物か偽物か」に加えて、「多クラス分類の損失項」を加えることで、よりバリエーションの多い画像出力を可能とする手法です。
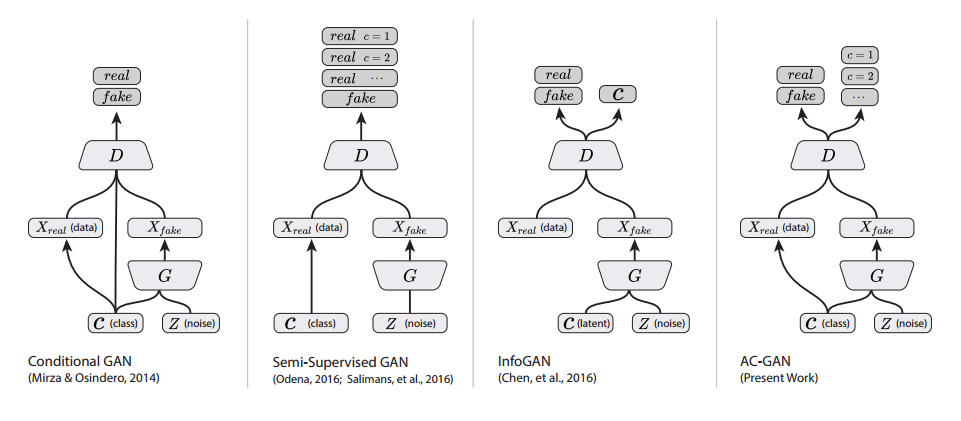
ACGANのPyTorch実装より。一番右がAC-GAN。
AC-GANの損失関数
論文3章に対応。これがAC-GAN損失関数であり、アイディアの中心となる部分です。
\begin{align}
L_S &= E[\log P(S=real|X_{real})] + E[\log P(S=fake|X_{fake})] \tag{1} \\
L_C &= E[\log P(C=c|X_{real})] + E[\log P(C=c|X_{fake})] \tag{2}
\end{align}
記号の表記:
- $S$はSourceで、Dを通したとき画像が本物(real)か偽物(fake)かを示します
- $P(S=real|X_{real})$はDの条件付き確率。$X_{real}$(データからの本物の画像)や$X_{fake}$(Gによる出力画像)が与えられたときに、Dが本物を返したかどうか($S=real$)の確率を表すものです。
- $C$はClassで、画像がどのクラスに属するかを示します。$C=c$はある画像はクラス$c$に属するという意味。条件付き確率も同様です。
DCGANの場合は、式(1)だけで最適化しますから、それに式(2)を加えたものがAC-GANと考えるとわかりやすいです。
論文によると、Dは$L_S+L_C$を最大化するように、Gは$L_C-L_S$を最大化するようにそれぞれ最適化します。DとGで$L_S$の符号が逆になっていますが、これはDCGANのような通常のGANにおいて、Dは$\min(\log D)$、Gは$\max(\log D)$と最小化/最大化が変わっているためと思われます。実装においては、符号は意識せずそのまま$L_S$と$L_C$を足しても構わないでしょう。
また、論文ではImageNetとCIFAR-10で実験をしていますが、ImageNetのような1000クラスもあるケースでは、ネットワークを同一にして1000クラスを一気に生成しようとすると出力画像の質が落ちるという現象が確認されています。そのため、論文では1000クラスを10クラス×100ケースに分割し、100ケースをそれぞれ個別に訓練しています。クラス数が多いケースではここが注意が必要です。
結果
論文の4章に対応します。ImageNetの実験では100ケースに分割し、バッチサイズ100で5万ミニバッチ間訓練したとのことです。ImageNetの訓練データでは、1クラス1300枚の画像があるので、10クラス1.3万枚=1エポック130ミニバッチになります。5万÷130=384.6エポック訓練したことになります。
そして、更にACGANでは出力画像のバリエーションを評価するための尺度を、アドホックな形でいくつか開発しています。これは後述。生成画像の識別性、多様性という2つの観点から論じています。
高解像度の画像を生成すると識別性が向上する
目標:単に高解像な画像じゃなくて、低解像度より画像分類での識別性が高い高解像度な画像を生成したい
**どうやって「識別性」を定義するの?**→ImageNetで訓練済みInceptionネットワークを使い、その精度を測定。
例えば解像度を16x16, 32x32, …と変えて、Bilinear補間で訓練済みInceptionの入力解像度に合わせて、クラス別の精度を測定してみると、次のようになります。

Realは元のImageNetのデータ、FakeはAC-GANで生成した偽物のシマウマです。本物の画像もそうですが、偽物の画像も生成解像度を上げていくと、Inceptionでの精度が上がっていきます(つまり識別性が向上する)。
さらに、解像度を横軸、縦軸をInceptionの精度としたときの、クラス別の結果のまとめです。
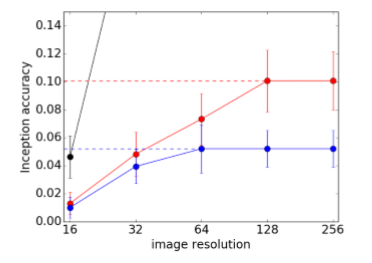
黒い線はGround Truth(Real)、赤い線は64x64のAC-GANでの生成、青い線は128x128のAC-GANの生成です。黒い線(Ground Truth)は高い解像度だとはるかに高い値なので、このグラフでは振り切れています。黒い線は識別性の上限というわけですね。
上記のシマウマの精度(Fakeでも76%)よりもだいぶ値が下がっている(赤い線でも10%)のは、シマウマの例は1つのクラスの精度であるのに対して、この線はクラス別の精度をすべてのクラスでまとめたものだからです。多くのクラスで上手く生成できなかった(識別性が乏しかった)のを意味するのだと思われます。この点は次の表を見ていくとわかります。
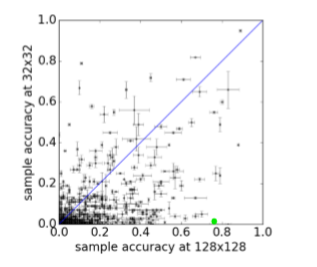
各点はImageNetのクラス別の精度です。縦軸が32x32の生成、横軸が128x128の生成です。ほとんどのクラスが128x128でも精度が0.0~0.2程度と低いことがわかります。シマウマは緑色の点で、たまたま上手く行ったクラスなのでしょう。
しかしながら、この表の対角線に線を引くと、84.4%のクラスが対角線の下に位置することがわかります。対角線より下なら128x128のほうがInceptionの精度が高い、上なら32x32のほうがInceptionの精度が高いということになるので、やはり高解像度の出力のほうがInceptionの精度が高くなり、識別性が増すということが言えます。同様のことを64x64と128x128で比較したところ、やはり128x128のほうが識別性が高かったそうです。
生成画像の多様性の測定
Inceptionの精度からは、モードが崩壊したかどうかは測定できません。なぜなら、1つのクラスに対して常に1種類の画像を生成すればInceptionの精度はとても高くなるからです。
人間に近いような感覚で、画像の類似性を測る指標としてはMS-SSIM(multiscale structural similarity)があります。MS-SSIMは画像の類似性を0~1で測る指標で、1のほうが類似性が高いということになります。このMS-SSIMを多様性の代用指標として使います。

上がAC-GANでの生成結果(偽物)、下が本物の画像です。右上のアーティーチョークはモード崩壊しているのがわかるでしょう。逆に言えば、低いMS-SSIMでは生成画像に多様性があり、高いMS-SSIMではモード崩壊しているということができます。
このMS-SSIMをどう計算したのかというと、クラス間でランダムの100個のペアを取り、そのペアのMS-SSIMを求めたとのことです。
本物の(訓練)画像はとても多様性があるため、低いMS-SSIMになります。すべてのクラスに対してMS-SSIMを求めたところ、本物の画像はMS-SSIMの最大値が0.25だったそうです。
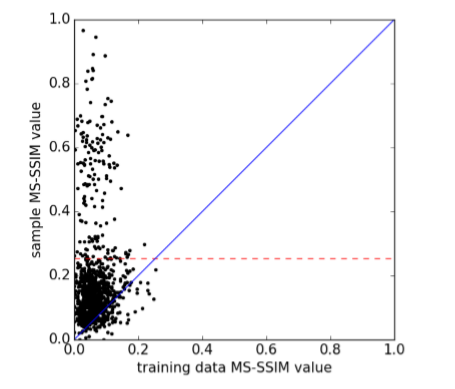
横軸が本物のMS-SSIM、縦軸がGANで生成された画像のMS-SSIMです。点はImageNetのクラス単位です。x=0.25が本物の画像のMS-SSIMの最大値です。これを偽物側に投射したものが、赤い点線です。これの意味することは、**偽物のMS-SSIMがこの赤い点線より低ければモード崩壊していない(GANが成功している)**ということができます。モード崩壊していないクラスは全体の84.7%だったそうです。MS-SSIMの統計量は以下の通りでした。
| MS-SSIM | 平均 | 標準偏差 |
|---|---|---|
| 本物 | 0.05 | 0.18 |
| 偽物 | 0.06 | 0.08 |
また訓練中のMS-SSIMをプロット位したものは以下の通りです。
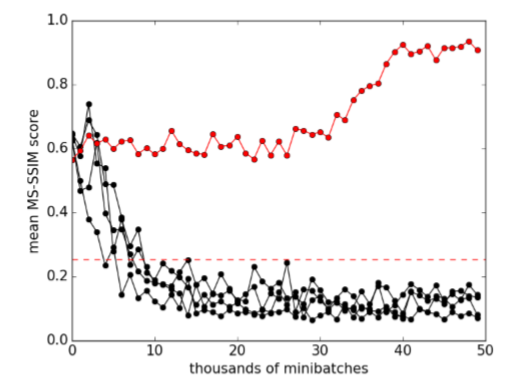
黒い線は上手く行っているクラス(モード崩壊していない)、赤い線はモード崩壊したクラスです。モード崩壊すると似たような画像しか返さなくなるので、MS-SSIMは急激に高くなります。
「識別性」と「多様性」の関係
Inceptionの精度と、MS-SSIMの間には弱いながらも逆相関があります(r2=-0.16)。
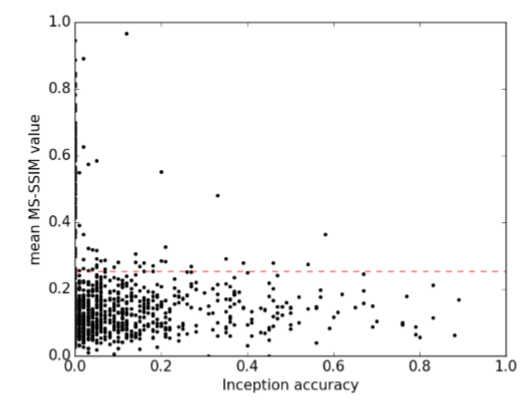
- 高い多様性(MS-SSIMが0.25未満)のクラスのうち78%は、Inceptionの精度が1%を超える
- 低い多様性(MS-SSIMが0.25以上)のクラスのうち74%は、Inceptionの精度が1%以下
→モード崩壊と低画質化は連動しているのではないか、と考えられる(従来の仮説と対照的)
以前の結果との比較
CIFAR-10でInception Scoreを計算したところ、この当時のSoTA(2016年の論文であることに注意)8.09±0.07より向上し、8.25±0.07を達成したとのことです。
訓練データへのオーバーフィッティングへの懸念
一つ懸念されるのは、AC-GANが訓練データに依存すぎている(オーバーフィッティングしている)ということです。ネットワークが訓練データを記憶していないかを検証するために、生成画像の最近傍探索を行ったとのこと。

上がAC-GANによる生成、下が本物です。生成画像がそれぞれ対応されているため、ネットワークはほとんど画像を記憶していないと考えられるとのことです。
オーバーフィッティングをより深く理解するには、潜在空間を補間してプロットするといいそうです。オーバーフィッティングモデルでは、潜在空間をプロットしたときに、
- 断片的な変動がある(滑らかな補間にならない)
- 潜在空間が意味のある画像に対応しない
といった現象が観測されます。AC-GANの場合の潜在空間のプロットは次のとおりです。(この図の上半分)

断片的な変動がなく、滑らかな補間であり、ちゃんと意味のある画像に対応しているから、オーバーフィッティングはしていないという理屈です。自分はこの切り口は面白いなと思いました。
この図の下半分は、潜在空間の乱数を固定して、鳥の個別のクラスを変えたものです。同一の乱数から生成させると、AC-GANのクラス変更はざっくり言うと「スタイル」の意味をなしているということができます。
クラスの分割と生成画像の画質の関係
1つのモデルあたり多くのクラスを同時に訓練すると、生成画像の質が落ちます。
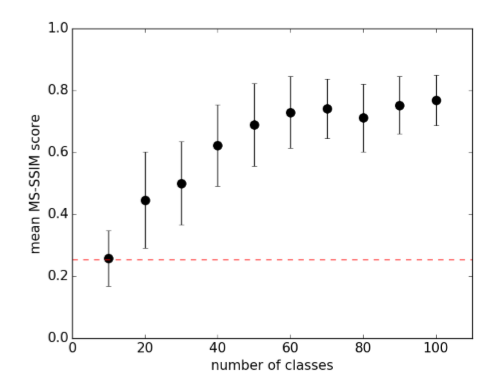
1つのモデルあたりのクラス数を横軸、縦軸をMS-SSIMとしたものです。MS-SSIMが高いとモード崩壊が懸念されます。クラス数を増やせば増やすほど、MS-SSIMが高くなっているので、モード崩壊が起きやすくなっていることが確認されます。この論文では1つのモデルあたり10クラスを採用しています。
また、MS-SSIMと識別性や画質は連動していると考えられるので、クラス数を増やすとMS-SSIMが高くなる、すなわち低画質化するということができます。
ネットワーク構成
論文のAppendix参照。かなりわかりやすくネットワーク構成書いてくれています。
個人的感想
この論文のConclusionでも述べられていることですが、AC-GANによる生成画像のInceptionの精度が全体ではたかが10.1%で、81%は本物の画像には遠く及ばなかったとのことです。AC-GANの議論は極めて有効ですが、この時代のGANでは上手く生成できなくても特に不思議なものではないということになります。
この論文はGoogle Brainの方が出したものですが、3年前のGoogle Brainをして81%は本物は遠く及ばなかったとのことですから、われわれが実際にAC-GANを実装して上手く行かなくても、特に恥ずかしい思いをする必要はなさそうです。
しかしながら、AC-GANの論文における、「識別性=Inceptionの精度」「多様性=SSIM」「オーバーフィッティング=潜在空間の補間」といった議論は普遍的に有効で、その点に価値がある論文ではないかなと思います。
そして、以降のGANでしきりに「モード崩壊への対策」が考えられることになりますが、その理由の一つになっているのが、この論文で書かれている「画質とモード崩壊は連動すると考える」ということではないかと思われます。
引用
A. Odena, C. Olah, J. Shlens. Conditional Image Synthesis With Auxiliary Classifier GANs. CVPR, 2016
https://arxiv.org/abs/1610.09585