2021年のディープラーニング論文を1人で読むAdvent Calendar11日目の記事です。今回紹介するのはGANのカスタマイズです。
GANというと乱数から画像を生成するモデルを1から訓練するものが想像されますが、今回はGもDもファインチューニングです。この論文では、スケッチ画像と写真という対応で訓練させていますが、特徴抽出のネットワークがあれば普遍的に応用できる研究です。カスタマイズされた派生モデル間の補間などかなり興味深いことも出てきます。見ていきましょう。
著者はカーネギーメロン大学とMITコンピュータ科学・人工知能研究所の方です。ICCV2021に採択されています。
- タイトル:Sketch Your Own GAN
- URL:https://openaccess.thecvf.com/content/ICCV2021/html/Wang_Sketch_Your_Own_GAN_ICCV_2021_paper.html
- 出典:Sheng-Yu Wang, David Bau, Jun-Yan Zhu; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 14050-14060
- プロジェクトページ:https://peterwang512.github.io/GANSketching/
- コード:https://github.com/peterwang512/GANSketching
問題設定
よくあるGAN:乱数から画像を生成
このGAN:訓練済みGANをファインチューニングして、ユーザーのスケッチをベースにポーズや構図をコントロールしたモデルを作る
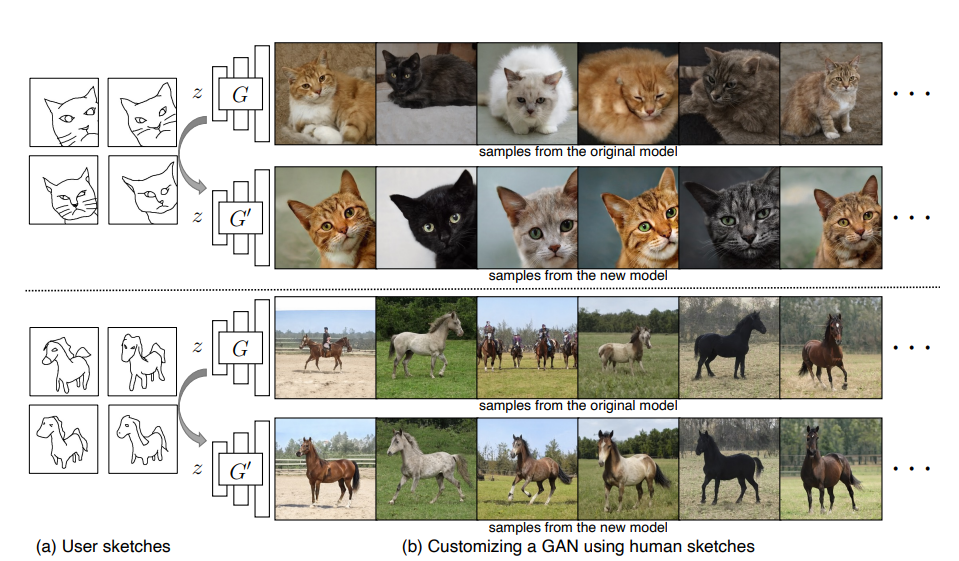
この図でいう$G'$というのがこの論文で作りたいモデルです。$G$は構図や向きが何でもありのGANですが、これを$G'$のようにスケッチで構図をある程度縛った画像を生成したいのです。これをするにはどうすればいいのですか?というのがこの論文の主題です。
大量の画像と、数枚~数十枚のスケッチがあれば良い
スケッチ→写真というと、Image to image translationの問題に属します。この手の問題は、スケッチと写真で1対1のペアが作られているPairedなデータセット、ペアを作っていないUnpairedなデータセットの2種類のケースに分類できます。この論文ではUnpairedなデータセットを想定しています。
教科書的なやり方だと、Pairedな例はPix2pix、Unpairedな例はCycleGANが挙げられます。一見CycleGANみたいなやり方をするのかと思われますが、写真→スケッチに戻すための訓練可能なネットワークやCycle Consistency Lossなどが必要ありません。CycleGANでやろうとすると、画像が数千枚あったとしたら、スケッチも同じぐらい必要になります。この論文は、画像は大量に使うが、スケッチは数枚~数十枚でうまくいくというのが特徴です。根本的に発想が異なる点はGANのファインチューニングにあるという点です。
また大きく異なるのが、スケッチを入力に入れないという点です。あくまでやるのはファインチューニングして構図を縛るということであって、スケッチを入力に入れて任意にコントロールではありません。構図の変更はモデルの再訓練が必要になります。6日目のスタイル変換の記事で出てきた「Per-Style-Per-Model」と発想は近いかもしれません。
モデル全体と訓練について
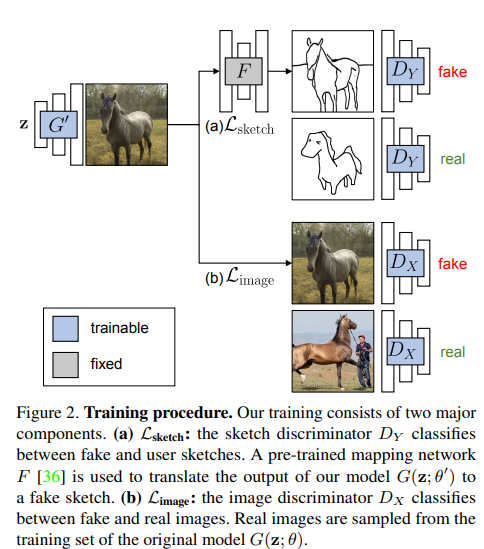
図のような比較的簡単なモデル構成になります。$G'$というのは乱数から画像を生成するGeneratorで、訓練済みGANをファインチューニングします。具体的にはStyleGAN2のマッピングのネットワークを再訓練したとのことです。位置づけ的にはStyleGAN2のカスタマイズであり、訓練済みStyleGAN2の活用という点では3日目の論文と似ているかもしれません。
スケッチと画像の分岐があります。スケッチ側は$F$という、訓練済みのスケッチの抽出ネットワークを使います。これはPhotosketchを利用しています。$F$は単なる特徴量の抽出として用い、再訓練しません。生成画像を$F$を通して得られた偽のスケッチと、本物のスケッチを使い敵対的なロス$\mathcal{L}_{sketch}$を得ます。
生成画像についても敵対的な訓練をします。これは普通のGANと一緒で、$\mathcal{L}_{image}$というロスになります。スケッチのみだと出力画像の画質や多様性が大きく落ちるとのことです。
また、2つのDiscriminator$D_X, D_Y$についても訓練済みネットワークを利用します。特に$D_Y$を訓練済みネットワークを利用せずに、ランダムに初期化すると大きく結果が悪くなるとのことです。オリジナルのGANのDを使うと書いてあったので、$D_X$はStyleGAN2のD、$D_Y$はPhotosketchのDを使うものと考えられます(PhotosketchもGANベース)。
全体の損失関数は次のようになります。
$$\mathcal{L}=\mathcal{L}_{sketch}+\lambda_{image}\mathcal{L}_{image}$$
ここで$\lambda_{image}$は0.7としています。
スケッチのデータについて
この論文では人間が描いたスケッチを使うことを想定していますが、人間が描いたものを使うと定量評価が困難になるため、訓練で使った写真をPhotosketchに通したものから、構図が近いものを30枚手動で選んだとのことです。
また、スケッチについてはData Augmentationを使用したほうが良いこともあるとのことです。Photosketchで機械的に生成した30枚のスケッチに対しては、必ずしもしなくてもいいとのことでしたが、人間が描いたスケッチの場合、スケッチのData Augmentationは有効に機能します。私見ですが、性能を上げるための増強というよりも、Photosketchと手描きのデータ分布のギャップを埋めるための増強という意味合いのほうが強いと思います。
定量評価
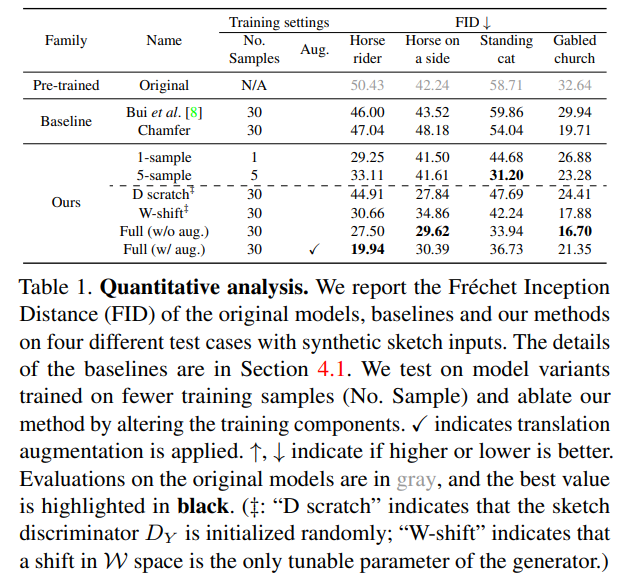
この定量評価では、他の研究との比較より、この研究での実装手法間の比較に注目すべきでしょう。Oursの中の「1-sample」「5-sample」というのは、スケッチのサンプル数です。当然ながらスケッチのサンプル数を増やせば増やすほど、高画質な画像が生成されます(FIDが低くなる)。
「D scratch」というのは、スケッチについてのDiscriminator$D_Y$をランダムに初期化した場合、つまり訓練済みDを使わない場合を示しています。このケースでは仮にスケッチのサンプル数が30あったとしても、訓練済みのDを使う+1サンプルのケースよりも劣る結果となっています。つまり、D、特に$D_Y$においても訓練済みのモデルを使うことは重要だということがわかります。
「W-shift」というのはG(StyleGAN2)の$\mathcal{W}$だけ訓練するということを意味します。ここでStyleGANの構造を振り返ると(以下の図はV1です)、
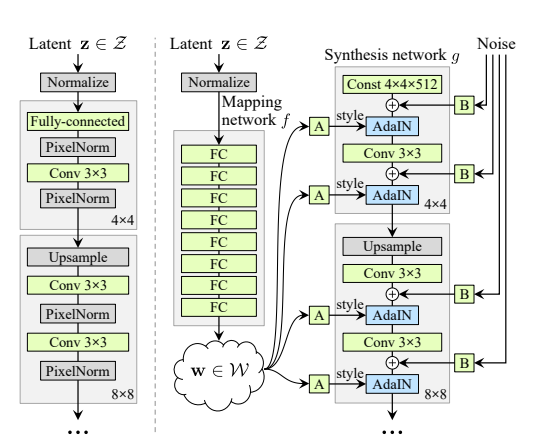
W-shiftというのは「A」のことを指していると思われますが、StyleGAN2自体が相当優秀なので、Wのシフトの部分のみを訓練すればいいということを言いたいのだと思われます。実際訓練するGのパラメーターを減らすと、FIDが落ちていることが確認できます。
Augmentationについては、このケース(Photosketchから機械的に生成した30枚のスケッチを訓練画像としたケース)の場合は、ないほうが良いこともありましたが、人間が描いたスケッチの場合はあったほうが良いです。

これは人間のスケッチ(具体的にはQuickdrawデータセット)を用いたものですが、Data Augmentationがない場合だと必ずしもポーズのアラインメントが取れていないケースがあります。スケッチに対するData Augmentationを入れることでこの問題を解決できます。
生成画像について敵対的な訓練を行う意義
また、生成画像についての敵対的な訓練($\mathcal{L}_{image}$)の意義についても見てみましょう。$\mathcal{L}_{image}$を論文では、「画像正則化(Image Regularization)」と呼んでいます。

「Same Iteration」というのは同一エポックでの生成画像、「Optimal Iteration」というのは各パターンで最良の結果です。Same Iterationのほうがわかりやすくて、一番上の$\mathcal{L}_{sketch}$だけの場合は、明らかに背景や馬のバリエーションがおかしいです。
$\mathcal{L}_{weight}$というのは、画像正則化ではなく、
$$\mathcal{L}_{weight}=|\theta'-\theta|_1$$
といわゆるL1正則化を適用したケースです。理想的にはL1正則化ではなく、画像正則化を適用したほうがより綺麗になります。画像正則化の場合は、生成画像について敵対的な訓練を行う必要があるため、$G$を訓練した画像データが手元にある必要があります。
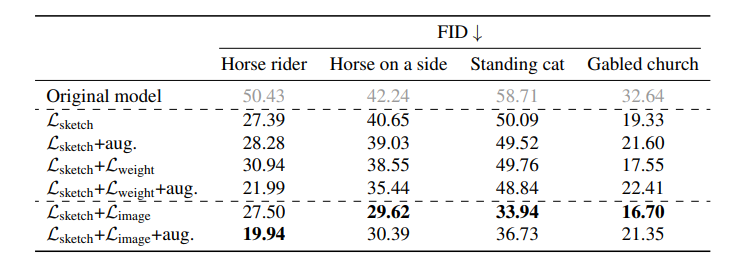
定量評価はこの通り。$\mathcal{L}_{sketch}+\mathcal{L}_{image}$がほとんどのケースで良いです。このケースではスケッチは機械的に作成したものなので、Data Augmentationの効果はそれほど現れていません。
応用例
潜在空間を主成分分析することで、猫に毛を足すというような演算ができます。これは既存の研究と同じ手法なので、詳細が気になる方は論文を参照してください。

また生成画像に対応する乱数(逆元)を計算することで、以下のような面白いこともできます。
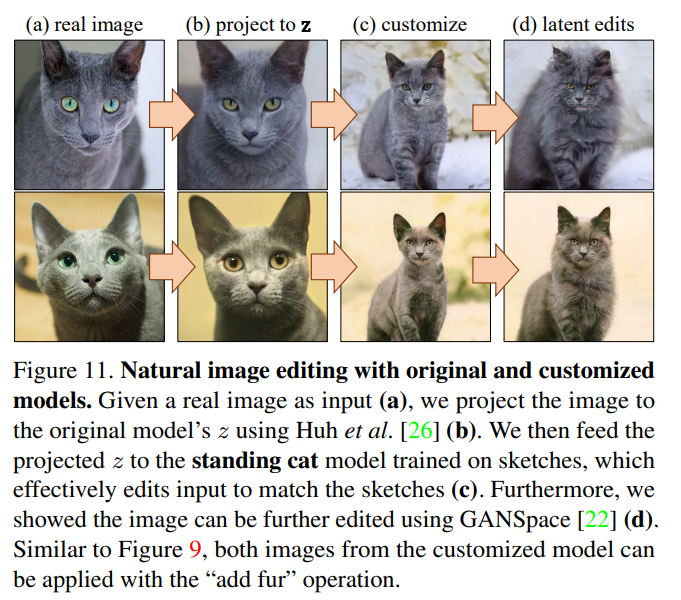
(a)は本物の画像です。(b)は元の(例:StyleGAN2)のモデルでの対応する逆元を計算し、画像を生成したものです。(c)はスケッチを使ってポーズをカスタマイズしたモデルに(b)で計算した乱数を与えたものです。ここで(b)と(c)の乱数は同一です。(b)と(c)の乱数が同一の空間にあることがどうやって保証されるのか不思議なところではありますが、「W-shift」の部分だけ訓練するという点がこれを保証しているのかもしれません。(d)は先程と同じ毛を付け足したものです。逆元計算についはこちらの研究を使っています。
実際に異なる2つのモデルで「$\mathcal{W}$の空間(ノイズ)」と「係数」それぞれの線形補間をした例が以下のとおりです。

Model 1, Model 2はそれぞれ異なるスケッチで訓練したモデルです。ノイズの補間も係数の補間もほとんど同じ結果を示しています。別のモデルをノイズをざっくりと流用しても変な出力はしないよということが言えるのではないでしょうか(はやりキーはW-shiftのみ訓練?)。
このように、逆元計算とノイズ操作でGANの出力結果をジャックしていくのが、3日目の論文とよく似ているのですが、最近のトレンドなんでしょうかね。
なお、モデルの訓練には最低3万ステップ必要なため、リアルタイムのモデル生成に関してはまだできないとのことです。ただ3万ステップ程度で済むなら結構すごいことだと自分は思います(まっさらな状態から訓練すると1桁違いそう)。
まとめ
単にスケッチからGANをコントロールする論文かと思いきや、StyleGAN2をFine tuneすることでGAN任意にカスタマイズできることを示したなかなか奥深い論文でした。結局Photosketchのような特徴抽出のネットワークがあればいいので、例えばこれをポーズ検出のネットワークに変えれば、任意のポーズで出力できるGANに変えられるかもしれません。そういう点ではかなり可能性のある研究だと思います。
3日目の論文でも見た通り、やはりStyleGAN2強いですね。あくまでこれは一過性のトレンドかもしれませんが、この傾向が続けばStyleGAN2がまるで訓練済みのResNetやVGGのようにコモディティ化するのではないか、と個人的には思っています。StyleGAN2を任意のデータで訓練できることは、あたかも訓練済みImageNetに相当するような価値を今後持ってくるかもしれません。
単に画像を生成して「存在しない人物を作った」「写真が証拠となる時代は終わった」で終わるのではなく、この論文のようなカスタマイズモデルの作成、逆元計算やノイズ操作のように、Disentangle性が重要視されているように思います。そういう点では、GANは新しいステージへと向かっているのかもしれません。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com