2021年のディープラーニング論文を1人で読むAdvent Calendarの6日目の記事です。今回はスタイル変換の論文ですが、512×512の解像度の合成を110FPSでできると主張する超高速なスタイル変換です。
この研究のキーとなっているのがラプラシアンピラミッドという、画像処理の古典的な解析手法(ディープラーニングが出る前からあった手法)という、温故知新感がある面白い論文です。また、下書きを作ってさらにそれをリファインメントするという(DraftingとRevision)、画家が実際に絵を描くときのプロセスを取り入れています。これとラプラシアンピラミッドの相性が非常に良いというわけです。Baiduと西安電子科技大学のメンバーが中心となった研究で、CVPR2021に採択されました。

- タイトル:Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer
- URL:https://openaccess.thecvf.com/content/CVPR2021/html/Lin_Drafting_and_Revision_Laplacian_Pyramid_Network_for_Fast_High-Quality_Artistic_CVPR_2021_paper.html
- 出典:Tianwei Lin, Zhuoqi Ma, Fu Li, Dongliang He, Xin Li, Errui Ding, Nannan Wang, Jie Li, Xinbo Gao; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 5141-5150
- コード:https://github.com/PaddlePaddle/PaddleGAN
PaddleGANは複数のGANがまとまったライブラリです。リポジトリから「LapStyle」などで検索すると当該のコードが出てきます。
ラプラシアンピラミッドの導入
画像ピラミッドは画像の簡易的な周波数分解です1。ラプラシアンピラミッドはガウシアンピラミッドの派生です。これのPyTorchの実装は私のブログに書いてあります。
ガウシアンピラミッド
まずは簡単なガウシアンピラミッドについて解説します。OpenCVでもできる処理で、こちらの記事をベースに書いています。
入力画像があるとします。ガウシアンピラミッドは次のプロセスを繰り返します。
- $(H, W)$の解像度を$(H/2, W/2)$にダウンサンプルする
- ダウンサンプルした画像にガウシアンぼかしをかける
これを繰り返します。縦横の解像度が半分、1/4のようにタイルしていくのでピラミッド状の出力になります。

解像度が下がっていくごとにぼやけているのが特徴です2。解像度を半分にするのは音で言えばサンプリングレートを半分にするのと似ていて、ナイキスト周波数が半分になるのとほぼイコールです。ガウシアンぼかしは別名ローパスフィルターとも呼ばれるので、一連の操作はローパスフィルターを連続的にかけるものと捉えられます。
ラプラシアンピラミッド
ガウシアンピラミッドの結果を利用するのがラプラシアンピラミッドです。ガウシアンピラミッドの各画像が$G_1, G_2, G_3, \cdots$と並んでいるものとしましょう。$G_2$の画像は$G_1$と比べて解像度が半分になっています。ラプラシアンピラミッドの画像$L_n$は以下のように定義します。定義はOpenCVの記事を参考にしました。
- $G_{n+1}$の画像を2倍にアップサンプリングする
- ガウシアンぼかしをかける
- $G_n$の画像から、2倍→ぼかしの画像を引く
これを繰り返します。実際どんなピラミッドが形成されるかというと次の通りです。出力結果はみやすさのためにMin-Maxで正規化しています。

全般的に輪郭に着目する傾向にありますね。ガウシアンピラミッドが周波数に応じてローパスフィルタをかけるものと捉えられるので、その差を取っているから、直感的にはラプラシアンピラミッドはバンドパスフィルタに近いですね。ラプラシアンピラミッドが近似的な周波数分解と言われるのはこういった背景です。
LapStyleの実装では、アップサンプリング、ダウンサンプリングにバイリニア法を使用し、ガウシアンぼかしは入っていませんでした。バイリニア法にカーネルがあるので、ガウシアンカーネルは入れなくても良いだろうという発想なのかもしれません。
モデルの概略
背景
スタイル変換といえばGatysらによるNeural Style Transferが有名ですが、これを皮切りに現在は2つの流派に分かれています。
- Per-Style-Per-Model : Auto Encoderなどスタイル変換ごとにモデルを訓練する方法です。精緻なスタイル変換ができますが、計算速度に難ありです。これをマルチスケールに拡張したものもあります。
- Arbitrary-Style-Per-Model:AdaINなど埋め込み空間を使ったスタイル変換です。計算速度に優れますが、全体の分布の調整をするため、局所的なパターンが変換できません。
この論文では「Drafting and Revision」という全く別のフレームワークを作ったと主張しています(実際はPer-Style-Per-Modelなんですけどね)。
モデル全体
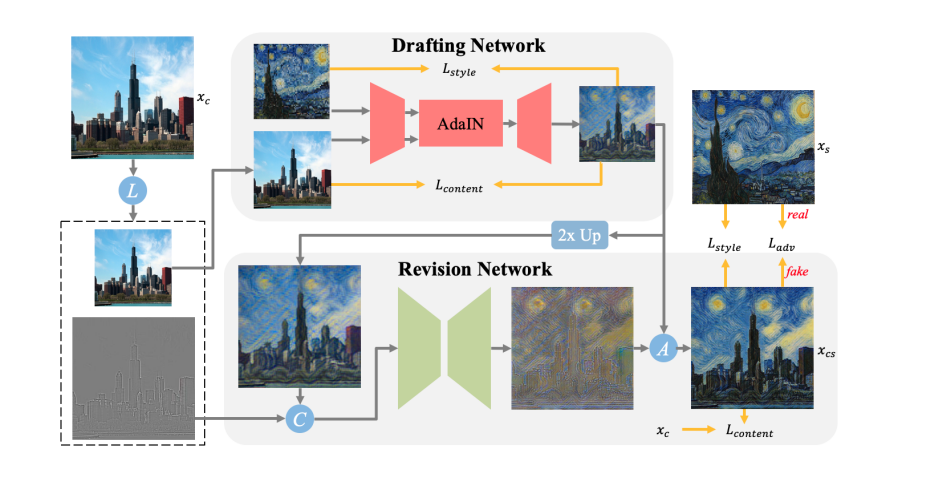
コンテンツ画像(塔の画像)を$x_c$とします。ネットワークに行く前に1段階のラプラシアンピラミッドを取り、${\bar{x}_c, r_c}$ができます(Lはラプラシアンピラミッドのオペレーターです)。$\bar{x}_c$はただ単に$x_c$の解像度を半分にしたもの、$r_c=x_c-Up(L(\bar{x}_c))$でまさにラプラシアンピラミッドの計算です。
Drafting Networkで$\bar{x}_c, \bar{x}_s$をEncoder→Decoderと食わせて$\bar{x}_{cs}$を得ます。ここでEncoderは訓練済みネットワークを利用し、訓練しません。$\bar{x}_{cs}$は$\bar{x}_c, \bar{x}_s$と$L_{style}, L_{content}$をそれぞれ計算します。
次に$\bar{x}_{cs}$を2倍にアップサンプリングし(ここでのアップサンプリングはニアレストネイバー法を使用しています)、ラプラシアンピラミッドの$r_c$とConcatします。これをRevision Networkに食わせて$r_{cs}$を得ます。
最終的に${\bar{x}_{cs}}$と$r_{cs}$でピラミッドの統合(Aのオペレーター)し、出力結果$x_{cs}$を得ます。これに対し、$L_{style}$と$L_{adv}$という2つの損失関数を適用します。ピラミッドの統合は、単にバイリニア法で拡大して次の解像度の$r_{cs}$と足すだけです。
出力ピクセルが512のときは、Revision Networkを2つ入れます。Drafting Networkは1回だけで、以降はRevision Networkの結果を再帰的に利用します。
Drafting Network
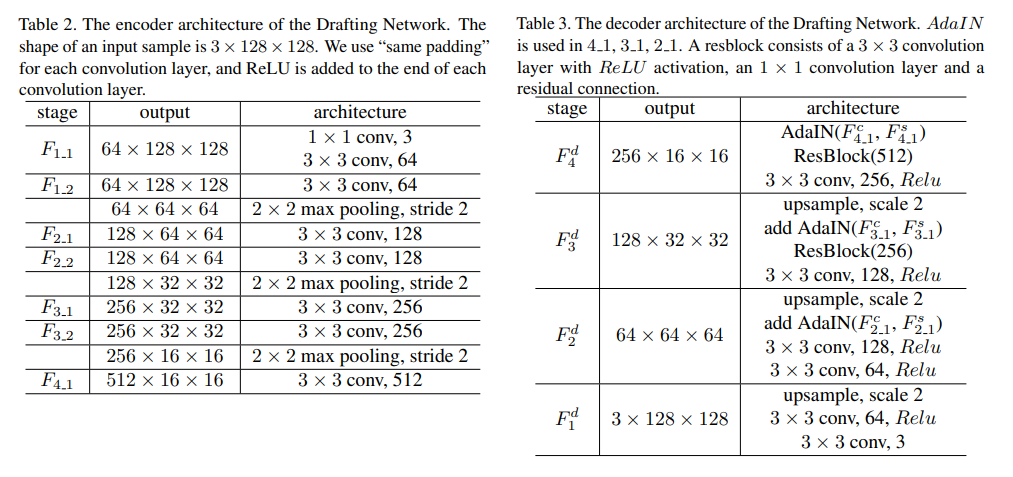
Drafting Networkのアーキテクチャーです。Encoderは訓練済みのVGG19を使用しています。これらの「2_1, 3_1, 4_1」の特徴量を抽出し、AdaINとしてSkip ConnectionでDecoderへ結んでいます。
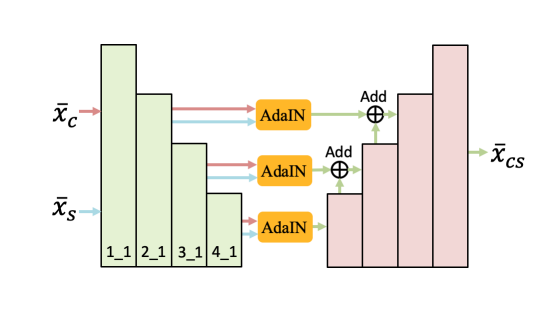
VGG19というと計算量が重い印象がありますが、解像度の低いレイヤーなのでそこまで問題にならないのでしょう。DecoderはResBlockやConvBlockを使った、U-Netライクなアーキテクチャーです。詳細コードはこちらにありますので、必要な方は参照してください。
Revision Network
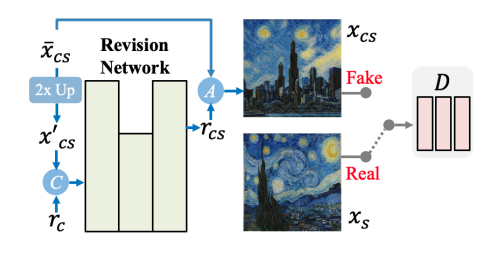
Revision Networkは2個のConv層からなるダウンサンプリング, 1個のRes Block, 2個のConv層からなるアップサンプリングからなる単純なモデルです。

Revision NetworkのDiscriminatorは、チャンネル数64で5層の3×3 Convからなるモデルです。SinGANのDiscriminatorを参考に作ったとのことです。1枚の画像のReal/Fakeを学習するのではなく、パッチ単位で学習します(PatchGAN)。Discriminatorを浅いモデルにした理由は、
- 訓練画像が1枚しかなく過学習を避けるため
- あくまでRevision Networkは局所的なパターンを学習するためなので、広域な特徴はいらない
損失関数
次に損失関数の各項を見ていきましょう
Style Loss
Neural Style Transferではグラム行列を計算していましたが、この論文ではrelaxed Earth Mover Distance (rEMD) という変わった計算をします。これはSTROTSSという先行研究で用いられていたものです。
VGG19の「1_1, 2_1, 3_1, 4_1, 5_1」を取り出し(バランスの関係で損失計算に使わないレイヤーもあります)

を計算します。コサイン距離を計算したあと、min-maxを計算します。Style Lossでは$l_r$と$l_m$の2つを計算し、どちらも最終的な損失関数で利用します。今のコサイン距離をmin-maxしたものが$l_r$です。
これに加えて、特徴量の大きさをコントロールするために、$l_m$の値を計算します。$l_m$は特徴量の平均差のL2ノルムと、共分散の差のL2ノルムを足したものです。
Content Loss
Content Lossは中間層の値のL2ノルムを取るPerceptual Lossです。
$$l_p = |norm(F_c)-norm(F_{cs})|_2$$
ここで$norm$はチャンネル単位のNormalizationです(ノルムとNormalizationの両方が出てきて紛らわしい)。ここで$F_c$や$F_{cs}$は中間層の値(実質的には各解像度の出力で)、$F_c$なら$\bar{x}_c, x_{c}$に対応します。この他に$l_{ss}$を導入し、
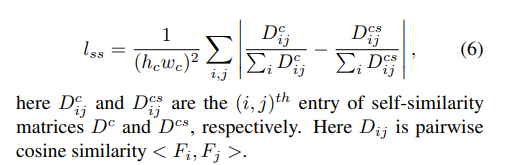
を計算します。$D_{ij}$は$F_i, F_j$のコサイン類似度です(Discriminatorの出力ではない)。
Drafting Networkのロス
$$L_{draft}=(l_p+\lambda_1\cdot l_{ss})+\alpha \cdot (l_m+\lambda_2\cdot l_r))=L_{content}+\alpha L_{style}$$
です。4項出てきますが、Content LossとStyle Lossの線形和です。バランスのコントロールのために、コサイン類似度の関係する$l_r, l_{ss}$はVGG19の「3_1, 4_1」のみ、$l_m, l_p$はVGG19の「1_1, 2_1, ……, 5_1」の値を使います。
論文では$\lambda_1=16, \lambda_2=3, \alpha=3$を使用しています。
Revusion Networkのロス
$$\min_{Rev}L_{base}+\beta\cdot \min_{Rev} \max_D L_{adv}(Rev, D)$$
とAdversarialなロスをいれます。論文では$\beta=1$を使用しています。
訓練の設定と結果
データセットと訓練
この訓練では、1つのスタイル画像と、大量のコンテンツ画像を入力データとして入れます。コンテンツ画像はMS-COCO、スタイル画像はWikiArtやフリー素材を使っています。
1つのスタイルには1つの訓練モデルが必要なので、全く新しいフレームワークと言っていますが「Per-Style-Per-Model」に属します(著者も結論で認めています)。ただ、AdaIN等「Arbitrary-Style-Per-Model」の発想は入っています。
Adamで学習率は1e-4、コンテンツ画像のバッチサイズは5、3万回反復させました。すべての実験のGPUはTitanX 1枚というなかなか優しいGPU要件です。
スタイル変換の結果

論文の図表の一部からです。512pxのような高解像度の生成ができています。

各ロスを外したときの結果です。これを見るとAdversarialなロスがかなり強く寄与しているように見えます。やはり時代はGAN。
512pxで110FPS?
読んでいる途中で「訓練中にVGGの特徴量をロスでいっぱい使っているし、Adversarialな訓練が入っているので、まっさらな状態から訓練して110FPSで生成完了するわけないよな」という疑問がとても湧いていました。実行速度は論文では次のような表になっています。
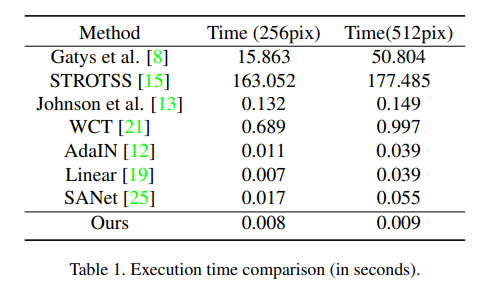
256pxで0.008秒、512pxで0.009秒というのが、120FPS、110FPSの根拠となっていますが、おそらくこれは推論のForeprop1回分ではないかと思います。よく本文を読むと「推論速度が速い理由は」と書いてあるので、そういうことなのでしょう。訓練時間を含めて110FPSを期待するとおそらくがっかりすると思います。
ただ、異なるコンテンツ画像に対しては追加訓練が不要なので、スタイル画像が同一である限りはこの推論速度は活かせるでしょう。推論だけならVGGの特徴量計算は最小限で済むので、リアルタイムを超える速度が出てもおかしくはないと思います。論文にも記載がありますが、Revision Networkが小さいので1024よりに更に大きな解像度への拡張が可能です。
ラプラシアンピラミッドの意義について
ラプラシアンピラミッドではなく、「解像度単位でRGB画像を直接入れたらどうなの?」という疑問もあるでしょう。
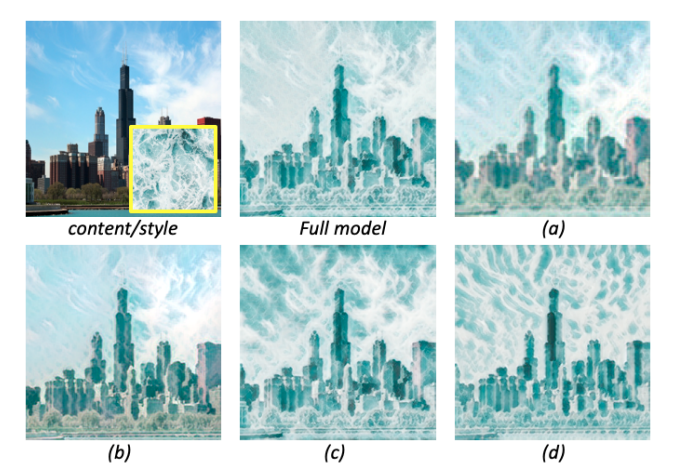
これを調べたのが(c)で、生成画像は256pxです。(c)はスタイルと雲が混同しているように見えます。(a)はDrafting Networkだけ、(b)はDrafting Networkを直接256pxで訓練、(d)はDrafting Networkなしでの結果です。
これは私の考えですが、256pxではなくもう少し大きな解像度だとラプラシアンピラミッドの有効性が出てくると思います。ラプラシアンピラミッドはあくまで差分なので、大域特徴はDrafting Networkで作って、あとはRevision Networkで差分を足していくというやり方のほうが、より自然に仕上がりと思います。また差分は、大域特徴と比べるとそこまで大事な情報ではないので、Revision Networkを軽量にできます。これはスループットの向上に寄与するでしょう(実際これを意識したモデルづくりになっています)。
まとめと感想
この記事ではラプラシアンピラミッドを使った、超高速なスタイル変換LapStyleについて紹介しました。高速であるとビデオのリアルタイムスタイル変換ができますし、性能に余裕があれば高解像度への拡張ができます。
幸い、Revision Networkが軽量なので、高解像度の拡張はそこまでボトルネックにならないと思われます。実際、256px→512pxの速度の落ち方が120FPS→110FPSだったので、頑張ればフルHDでリアルタイムぐらいは行けるのではないでしょうか。120FPSや110FPSは「ちょっと盛ってるかな?」という印象は拭えませんが、高解像度でリアルタイムのスタイル変換ができそうなのは意義があると思います。スタイルが共通なら、コンテンツが変わっても追加訓練はいらないので、スタイルごとに訓練モデルを複数用意しておいて…となると実サービスへの応用が見えてくると思われます。
この研究の面白いところは、ラプラシアンピラミッドという画像処理の古典的手法を、ディープラーニングベースのスタイル変換の生成クォリティの向上と、計算量削減の両方で利用している点です。Drafting Networkは、低解像度にして計算量を抑える分モデルを大きくし、大域特徴をちゃんと生成します。一方のRevision Networkは、ラプラシアンピラミッドを使って差分だけを軽いモデルでリファインし、解像度へのスケール可能性を良くしています。これは大きな貢献ではないかなと思います。このあたりが評価されて、CVPRで採択されたのではないかなと自分は見ています。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com