2021年のディープラーニング論文を1人で読むAdvent Calendar3日目の記事です。今回紹介するのはStyleGANの応用です。StyleGANといえばGANの中でもトップクラスに注目されているモデルで、2020年にはStyleGAN2が生まれました。
この研究はGANの訓練を一切せずに、パノラマ合成や、画像ブレンド、局所的なマルチモーダル画像変換など複数の画像合成タスクをこなすものです。高価なGPUがいらないので利用しやすい研究ではないかと思います。2021年11月現在はpreprintとなっています1。イリノイ大学とSnap社のメンバーによる論文です。
- タイトル:StyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN
- URL:https://arxiv.org/abs/2111.01619v1
- 出典:Min Jin Chong, Hsin-Ying Lee, David Forsyth; arXiv preprint arXiv:2111.01619
- コード:https://github.com/mchong6/SOAT
訓練済みStyleGANだけあればいい
まずはこちらの論文の画像をご覧ください。

何をやっているのかというと、上から
- パノラマ合成
- 1枚の画像からの合成。1つの画像を反転して合成(左)、1つの画像を並べて合成
- 特徴補間。Input 1が普通の山、Input 2が雪山です。1つ目は解像度を変えずに縦方向に特徴量を補間するもので、上に行くほど雪山っぽくなっています。2つ目は解像度を変えない横方向の補間で、右に行くほど雪山っぽくなっています。3つ目は横につなげた補間で、パノラマ合成と似た手法です。
- 連続的な転移。スタイル変換に近いですが、連続的な補間ができます。
- 局所的な画像の転移。眉~口のBounding Boxの中のパーツだけ置き換え、髪型は変わっていません。
- 属性転移。局所的な画像転移ではなく、「雰囲気だけ似せる」という感じでしょうか。
これらの複数の画像合成タスクを、訓練済みStyleGANだけで実装します(この研究ではStyleGAN2を使っています)。「Vanilla StyleGAN is all you need.」とすら書かれていますが、これを一切訓練なしでできるのはすごいですね。
パノラマ合成のコード
この論文非常に読みやすいだけでなく、コードが充実していて遊べる用のColab Notebookもあります。Notebookの一番上にあるパノラマ合成の例をとります。このコードを紐解くと何をやっているのか理解できると思います。これをコード1とします。

model_type = 'landscape' #@param ['church', 'face', 'landscape']
num_im = 5#@param {type:"number"}
random_seed = 90#@param {type:"number"}
plt.rcParams['figure.dpi'] = 300
mean_latent = load_model(generator, f'{model_type}.pt')
# pad determines how much of an image is involve in the blending
pad = 512//4
all_im = []
random_state = np.random.RandomState(random_seed)
# latent smoothing
with torch.no_grad():
z = random_state.randn(num_im, 512).astype(np.float32)
z = scipy.ndimage.gaussian_filter(z, [.7, 0], mode='wrap')
z /= np.sqrt(np.mean(np.square(z)))
z = torch.from_numpy(z).to(device)
source = generator.get_latent(z, truncation=truncation, mean_latent=mean_latent)
# merge images 2 at a time
for i in range(num_im-1):
source1 = index_layers(source, i)
source2 = index_layers(source, i+1)
all_im.append(generator.merge_extension(source1, source2))
# display intermediate generations
# for i in all_im:
# display_image(i)
b,c,h,w = all_im[0].shape
panorama_im = torch.zeros(b,c,h,512+(num_im-2)*256)
# We created a series of 2-blended images which we can overlay to form a large panorama
# add first image
coord = 256+pad
panorama_im[..., :coord] = all_im[0][..., :coord]
for im in all_im[1:]:
panorama_im[..., coord:coord+512-2*pad] = im[..., pad:-pad]
coord += 512-2*pad
panorama_im[..., coord:] = all_im[-1][..., 512-pad:]
display_image(panorama_im)
Generatorの出力画像解像度は256×256です。この出力をnum_im個並べてパノラマ合成します。num_im=5なら、出力解像度は縦が256、横が1280になりますね。
「# latent smoothing」と書かれたところから。まずは潜在空間用の乱数のサンプリングをしています。自然な合成にするために乱数にガウシアンフィルタを入れています(後述)。
潜在変数の取得
次のgenerator.get_latentの部分を見てみましょう。各層の乱数値を取得を目的としたものですが、この理解にはStyleGANのアーキテクチャを把握する必要があります。StyleGANの論文からの図です(実際に使っているのはStyleGAN2なので厳密には異なります)。
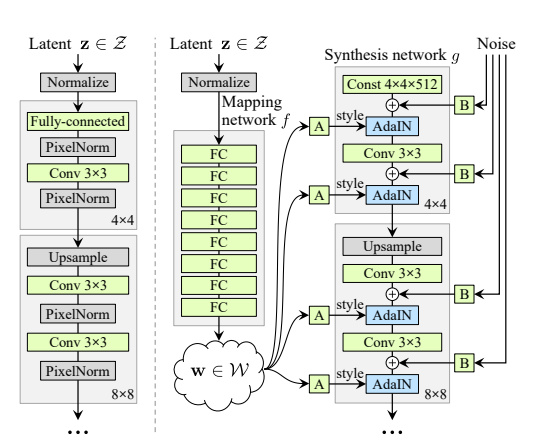
「Latent $\mathbb{z}$」というのが最初にサンプリングされたノイズです。これを複数のFCレイヤーでマッピングし、潜在空間の特徴量$\mathbb{w}$ができます。Conv層にはAdaINという条件付きのInstance Normがあり、$w$をこの条件付けとして利用しています。AdaINには学習可能なFCレイヤー2があるので、各Conv層で特徴量をアフィン変換して利用しています。このアフィン変換された各層の特徴量を取得しようとするのが、コード1のgenerator.get_latentです。
def get_latent(self, input, is_latent=False, truncation=1, mean_latent=None):
output = []
if not is_latent:
latent = self.style(input)
latent = latent.unsqueeze(1).repeat(1, self.n_latent, 1) #[B, 14, 512]
else:
latent = input
output.append(self.conv1.get_latent(latent[:, 0]))
output.append(self.to_rgb1.get_latent(latent[:, 1]))
i = 1
for conv1, conv2, to_rgb in zip(self.convs[::2], self.convs[1::2], self.to_rgbs):
output.append(conv1.get_latent(latent[:, i]))
output.append(conv2.get_latent(latent[:, i+1]))
output.append(to_rgb.get_latent(latent[:, i+2]))
i += 2
if truncation < 1 and mean_latent is not None:
output = [mean_latent[i] + truncation * (output[i] - mean_latent[i]) for i in range(len(output))]
return output
本論文(SOAT)でのgenerator.get_latentの実装です。StyleGANはPGGANのように解像度別の出力をしているので、解像度別にconv1, conv2, to_rgbの層が存在します。generator.get_latentでは、アフィン変換された特徴量を取得しています。
コード1に戻りましょう。次のindex_layersはサンプル単位の特徴量の切り出すための関数です。今num_im=5個分の各層の特徴量を一気に取得しましたので、これをサンプル単位に切り分けます。index_layersの実装は次の通りです。
def index_layers(w, i):
return [w[j][[i]] for j in range(len(w))]
i=0なら、最初のサンプルの各層の特徴量がリストとして返されます。
2つの画像をマージする
コード1に戻ります。今ここの部分を見ています。
# merge images 2 at a time
for i in range(num_im-1):
source1 = index_layers(source, i)
source2 = index_layers(source, i+1)
all_im.append(generator.merge_extension(source1, source2))
サンプル単位で特徴量をとったので、generator.merge_extensionでマージした画像を取得しています。ここが合成のコアとなる実装です。
def merge_extension(self, latent1, latent2):
noise = [getattr(self.noises, f'noise_{i}') for i in range(self.num_layers)]
device = self.input.input.device
out = self.input(latent1[0])
out1, _ = self.conv1(out, latent1[0], noise=noise[0])
out2, _ = self.conv1(out, latent2[0], noise=noise[0])
out = torch.cat([out1, out2], 3)
skip1 = self.to_rgb1(out, latent1[1])
skip2 = self.to_rgb1(out, latent2[1])
alpha = torch.zeros([skip1.size(3)])
pad = skip1.size(3)//4
alpha[-pad:] = 1
alpha[pad:-pad] = torch.linspace(0,1,alpha.size(0)-2*pad)
alpha = alpha.view(1,1,1,-1).expand_as(skip1).to(device)
skip = (1-alpha)*skip1 + alpha*skip2
i = 2
for conv1, conv2, noise1, noise2, to_rgb in zip(
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
):
out1, _ = conv1(out, latent1[i], noise=noise1)
out2, _ = conv1(out, latent2[i], noise=noise1)
alpha = torch.zeros([out1.size(3)])
pad = out1.size(3)//4
alpha[-pad:] = 1
alpha[pad:-pad] = torch.linspace(0,1,alpha.size(0)-2*pad)
alpha = alpha.view(1,1,1,-1).expand_as(out1).to(device)
out = (1-alpha)*out1 + alpha*out2
out1, _ = conv2(out, latent1[i+1], noise=noise2)
out2, _ = conv2(out, latent2[i+1], noise=noise2)
alpha = torch.zeros([out1.size(3)])
pad = out1.size(3)//4
alpha[-pad:] = 1
alpha[pad:-pad] = torch.linspace(0,1,alpha.size(0)-2*pad)
alpha = alpha.view(1,1,1,-1).expand_as(out1).to(device)
out = (1-alpha)*out1 + alpha*out2
skip1 = to_rgb(out, latent1[i+2], skip)
skip2 = to_rgb(out, latent2[i+2], skip)
alpha = torch.zeros([skip1.size(3)])
pad = skip1.size(3)//4
alpha[-pad:] = 1
alpha[pad:-pad] = torch.linspace(0,1,alpha.size(0)-2*pad)
alpha = alpha.view(1,1,1,-1).expand_as(skip1).to(device)
skip = (1-alpha)*skip1 + alpha*skip2
i += 3
image = skip.clamp(-1,1)
return image
やっていることはFore-propをマニュアルに追っているだけですが、層単位でアルファブレンドを入れています。論文のAppendixのこれが図で示されていました。こういう細かい実装を論文でケアしてくれるのが良いですね。
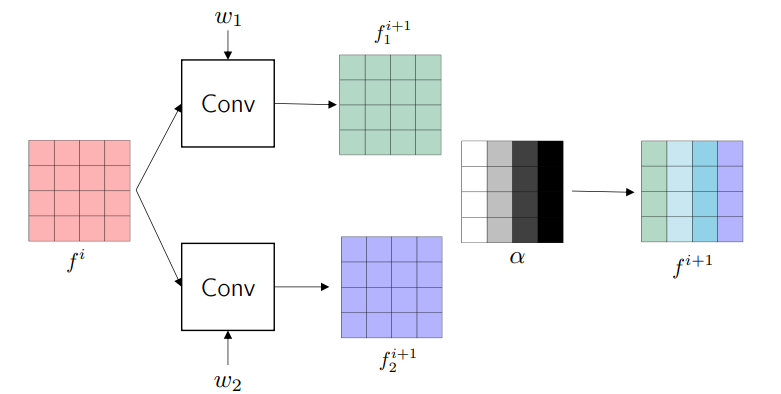
やっていることは層単位での横方向のアルファブレンドです。中間層でMixupするManifold Mixupと発想は近いですね。
コード1のgenerator.merge_extensionで、パノラマ写真の1サンプルの合成が終わったので、あとはタイルします。ここはただのペーストなので割愛します。これで実装のアウトラインが見えてきたのではないでしょうか。
SinGANとの比較
似たようなマルチタスクの合成手法として、ICCV2019においてBest Paper Awardを獲得したSinGANがあります。
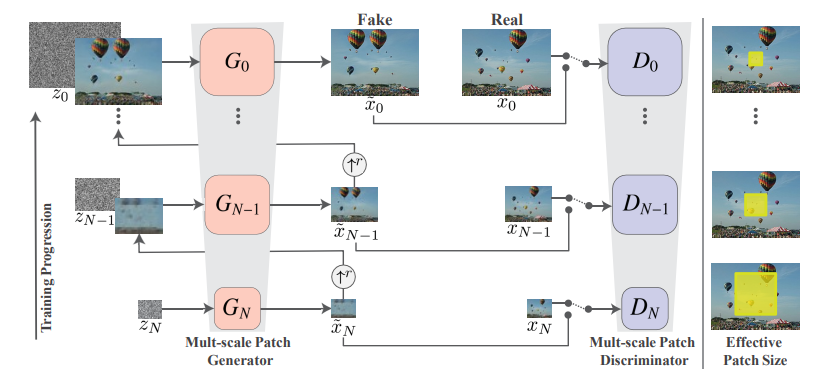
これはSinGANのアーキテクチャです。1つのネットワークで、パノラマ合成やスタイル変換といったマルチタスク、マルチモーダルな変換を行う手法として大いに注目されました。ただ、SinGANは画像を合成するたびに訓練が必要でした。
SOAT(本論文)がSinGANと大きく異なるのが、「訓練済みStyleGANだけでいい。中間層や潜在空間の値をいじればいいので、追加モデルも訓練いらない」という点です。計算コストの点でも圧倒的に優位ですし、もしかしたらCPUレベルでも合成できるかもしれません。個人的には発想はSOATのほうがわかりやすいです。
StyleGANを使った画像の演算
空間方向の合成
StyleGANはすべてConv層からなるので位置不変性が保証されます3。したがって中間層のアルファブレンドがそのまま空間方面に反映されます。
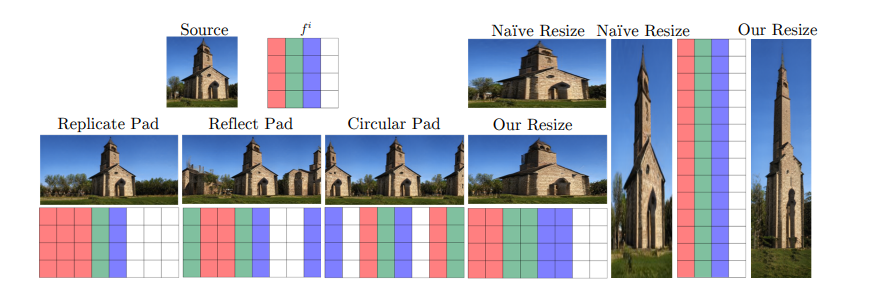
例えば空間方面の操作に変えれば、1枚の画像を引き伸ばしたり、反転させて合成ができます。ナイーブなリサイズ(例:バイリニア法)よりリアルな仕上がりになっています。
特徴補間
パノラマ合成の要領で、2つの画像を1つの画像として出力するようにブレンドすれば特徴補間ができます。

先行研究のSuzuki et alはこちらの論文です。縦方向、横方向ともに自然なブレンドになっていますね。特に波打ち際の合成はすごいです。
1枚の画像からの合成

1枚の画像を反転させて右にくっつけたり、反転画像との間でアルファブレンドすることもできます。これはSinGANとの比較ですが、遥かに自然な合成に成功しています。

40人の被験者による評価だと、1枚の画像からの合成、特徴補間ともに8割以上の人がこの研究を選んだとのことでした。
パノラマ合成
先程コードで見ましたが、パノラマ合成の考え方は次の通りです。
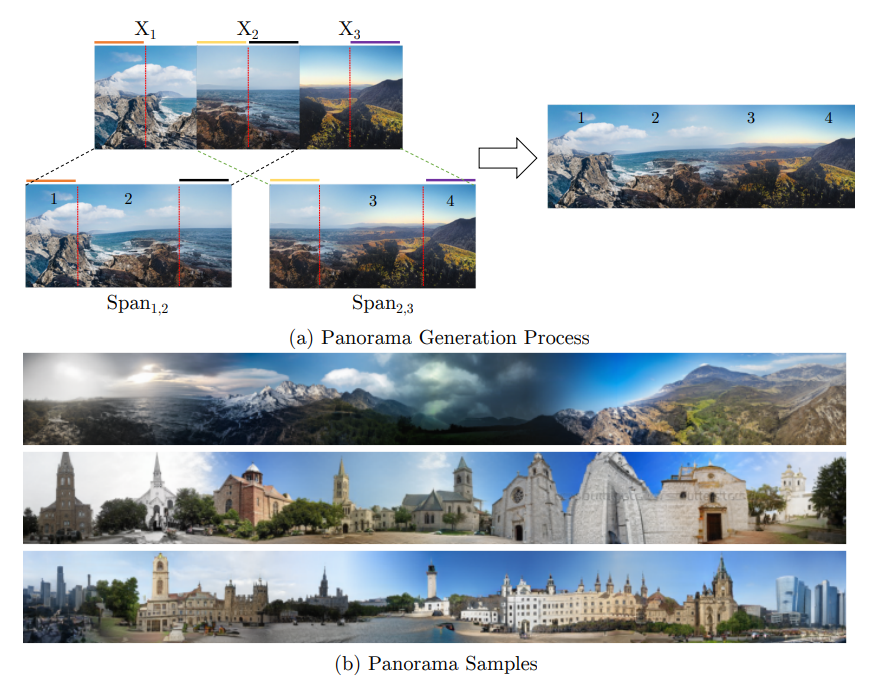
$X_1$と$X_2$は、それぞれ単体の画像として生成したときにこうなるという図です。1と2でパノラマを作るなら、1の左半分と2の右半分はそのまま使い、1の右と2の左をアルファブレンドで合成して出力します。複数の画像の場合も同様です。

パノラマ合成の場合は、ガウシアンフィルタを使って潜在空間の平滑化をします。これのあり・なしはかなり強烈に現れます。上のような合成画像は以前自分がOutpaintingのモデルを訓練したときによく見たのですが、自然な合成をするための秘訣はガウシアンフィルタなのかもしれません。
Image to image translationへの応用
SOATを使うとStyleGANだけでマルチモーダルなImage to image translationができます。face2disney, face2animeのケースでは、FFHQのデータセットで訓練したStyleGAN2をDisneyとDanbooru2018データセットでfine tuningしている点に注意してください。

「Invert」はGANの逆元です。通常のGANはノイズから画像を生成しますが、画像が与えられてそれにマッチするノイズを求められると便利なことが多々あります。このへんはぱしふぃんさんが記事を書いているので参照してみてください。
潜在変数の推定には学習が必要ですが、SOATのコードにprojector.pyが用意されており、潜在変数を推定できます。
(c)のLocal Translationは局所的なImage to image translationです。Bounding Boxはユーザーが与えます。潜在変数を推定してから合成したほうが、部分的に合成するよりも自然な変換になっているのがわかります。
GANの潜在変数は顔のポーズに大きく依存していることがわかっています。ポーズが異なると合成がうまく行かないため、ポーズについてのアラインメントを取ると良いとのことでした。アラインメントを取る方法は、StyleGANの最初の方のレイヤーはポーズを見ているという研究に基づき、$W+$の最初の2048次元を参照画像との間で合わせるとのことでした4。

まとめと感想
この論文は、訓練済みのStyleGAN2を使って、パノラマ合成から顔の編集、Image to image translation的なことまで基本的に訓練なしでできるというすごいものでした。逆元の計算をすると訓練がいりますが、それでもGeneratorの係数は固定のままなので、1からStyleGANを訓練するよりかは全然楽でしょう。リアルな画像の潜在変数を求めながら、訓練済みStyleGANを使って自由に画像を合成できたらかなり楽しいと思います。
GANのモデルは星の数ほどありますが、Disentangleの精緻さにおいてはStyleGANが一つ頭抜けていると言えます。この論文でもStyleGANのDisentangleについて記述ありますが、StyleGANのモデル構造、Disentangleについてうまく活用したのがこの論文の大きなポイントでしょう。
ただサンプリングしてリアルに存在しない画像を作り出すモデルとしてのStyleGANを超えて、中間層の値を「ハイジャック」し、複数の画像合成タスクに活用できるようにしたのが、この論文の大きな功績です。スタイル変換で使われるVGG16/19のように、訓練済みStyleGANのモデル自体にそのうち大きな意義が生まれてくるかもしれません。あくまで訓練済みのStyleGANを使っているだけなので、GANの訓練の不安定さは話は一切関係ありません。GANの応用としても活用が期待できるのではないでしょうか。
告知
このアドベントカレンダーが本になりました!
https://koshian2.booth.pm/items/3595424
Amazonでも扱いあります詳しくは👉 https://shikoan.com