はじめに
AdventCalender論文24日目担当のぱしふぃんです。
— ぱしふぃん (@pacifinapacific) December 21, 2019
なんとただの1枚絵をVtuberのモデルにできちゃうのです。ニコニコに上がっている解説動画では賞賛のコメントが多数寄せられていました。
これはすごい!ということで私も読んだのですが、データセットを作る段階ですごい労力を費やしているようでした。3dモデル1つ1つを目を閉じたり、開けたり、顔を傾けたりと差分をとり、ラベル付けしていくのはとても大変です。
「そんなラベル付けの手間を失くして似たようなことがやりたい!!」
その一つの可能性として今回StyleGANに着目してみます。StyleGANは滅茶苦茶綺麗な画像を生成できるモデルで、しかも基本的にUnsupervisedです。(生成するドメインを絞ることが多いので厳密には違うんだろうけど..)
少なくとも3dモデルを動かしてannotationするよりは良さそうです。
一回StyleGANを学習させてやって、その学習済みモデルを使うと一枚の顔画像を思い通りに操作できる,となったら素敵ですね。
というわけで今回私が紹介する論文はStyleGAN2の潜在変数の推定に関する論文です。StyleGANに関してはあまりにも有名なのでここでは詳細な説明は省きますが,こちらの資料がわかりやすくておすすめです。
(今回は論文の内容を正確に追うというより、自分が試した結果とかも交えながら書いていくので,気になったらぜひ元論文を読んでみてください!もちろん指摘や議論は歓迎です。)
まずはICCV2019にもアクセプトされた論文から紹介していきます!
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?3
潜在変数の推定って何?
StyleGANは要するにGANなのである入力をGeneratorに与えると,それに1対1に対応した画像を生成します。この入力を潜在変数(latent Varialble)と呼びます。ここで__潜在変数の推定とは,通常の潜在変数から画像を生成するFlowとは逆に,学習済みのGANにある画像を与えたとき、それを生成した潜在変数を発見することを言います。__ もし潜在変数が推定できたなら,これをもう一度Generatorに入れると元の画像を復元できます。これができるとなにが嬉しいかというと潜在変数をいじることで画像を気軽に操作できたり、未学習の特徴は復元できないことを利用して異常検知に応用できたりします。
StyleGANのどの潜在変数を推定するの?
実はStyleGANには潜在変数が複数存在します。
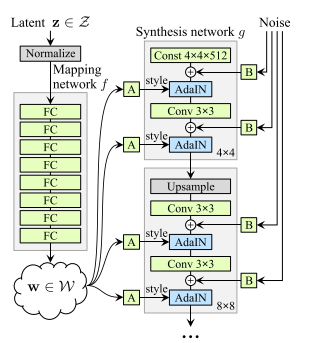
図 1 StyleGANのGenerator2
図1はStyleGANのGeneratorのネットワーク図ですが、これをみると潜在変数は左側のMapping Networkに入力する__z__と右側のSynthesis Networkに足している__Noise__があります。また__z__をMapping Networkに通した後の__w__も__z__を変換しているという意味で広義の潜在変数と言うことができます。
ではどの潜在変数を推定するかというと、この論文では最後の__w__のみを推定させています。
理由は__z__の次元が512次元で,__w__が18x512次元で__w__の方が自由度が高く表現力が高いこと、__Noise__に関しては肌質など細かい部分を表現するもので役割が異なっているためだと思います。(後の論文でNoiseの最適化にも取り組んでいます)
__w__を推定するので、前段階のMapping Networkは無視でき、これ以降Generatorと言ったらSynthesis Networkのことを指すことにします。
推定手法
GANの潜在変数の推定手法は一般的に2通りの方法が考えられます。一つ目はEncoder-Decoder方式で,画像から潜在変数を推定しGeneratorで復元させて,元の画像と一致するようにEncoderを学習させる方法。もう一つが__潜在変数の初期値を与えて、Generatorに入力し、元の画像と一致するように潜在変数をSGDで最適化する方法__です。前者のEncoder-Decoder方式は実験的に上手く行かないとされており、この論文でも後者の潜在変数を最適化する方法を取っています。ちなみに異常検知で有名なAnoGAN4もこの方法です。
擬似コードによるアルゴリズムは次のようになります。

図2 潜在変数推定のアルゴリズム3
潜在変数__w__を最初に初期化し、Generatorに入力。生成した画像が元画像と一致するようにMSEとPerceptual Lossを用いて__w__を更新することを繰り返します。
__w__が段々と最適化され再構成された画像が本来の画像に近づいて行く様子が次のgifで確認できると思います。
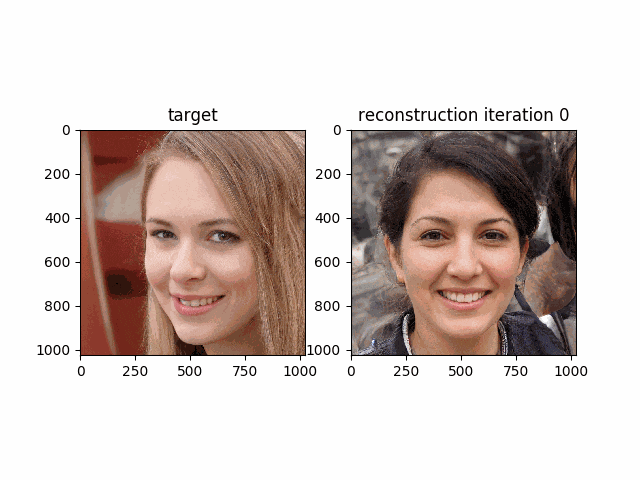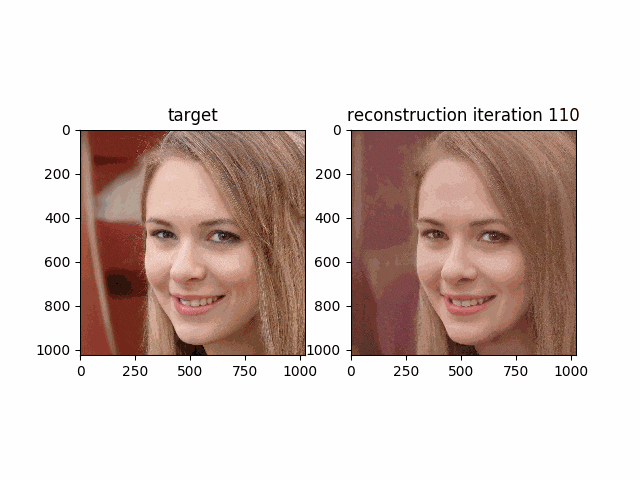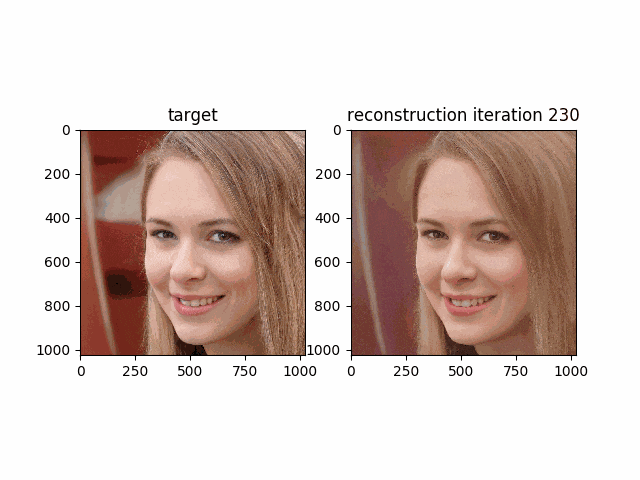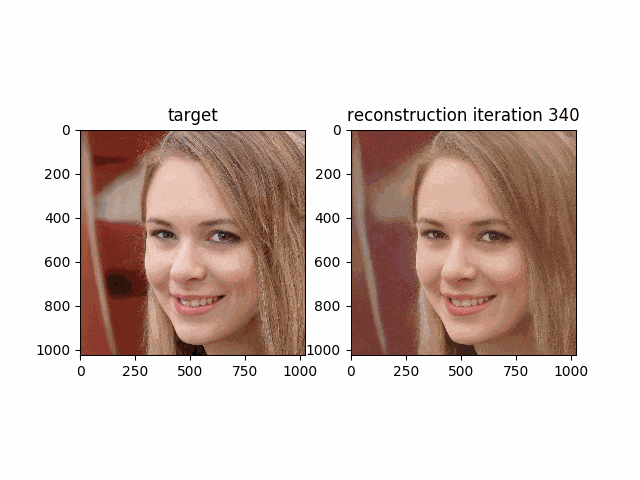
Morphing
よく学習されたGANは潜在変数を連続的に変化させてやると,画像も連続的に変化することが知られています。これを利用して、推定した潜在変数間を次式のように連続的に動かしてやると、画像がsmoothに変化するデモが作成できます。
$$w=\lambda w_{1}+(1-\lambda) w_{2}, \lambda \in(0,1)$$
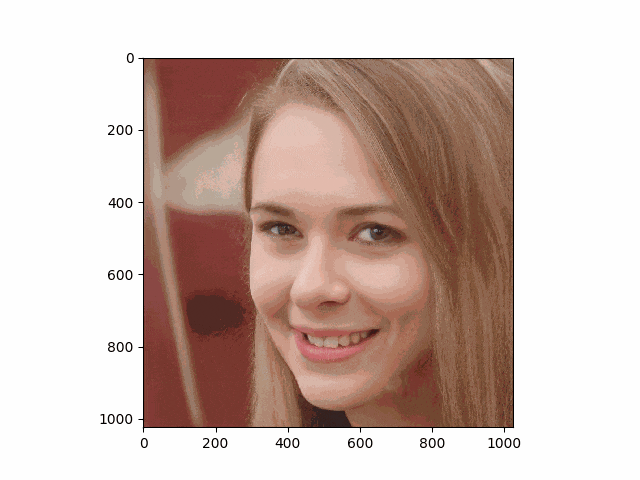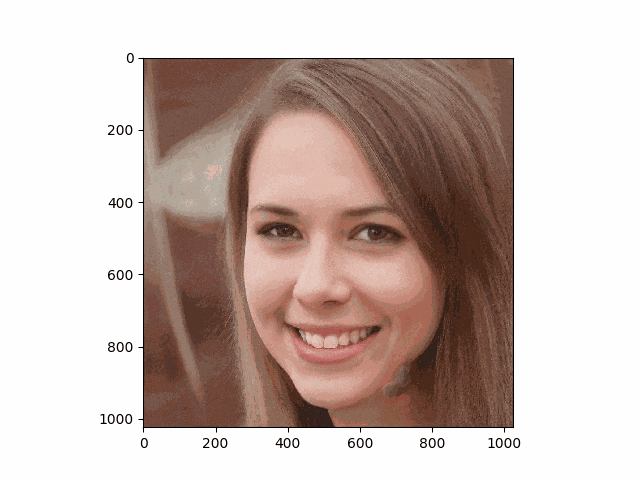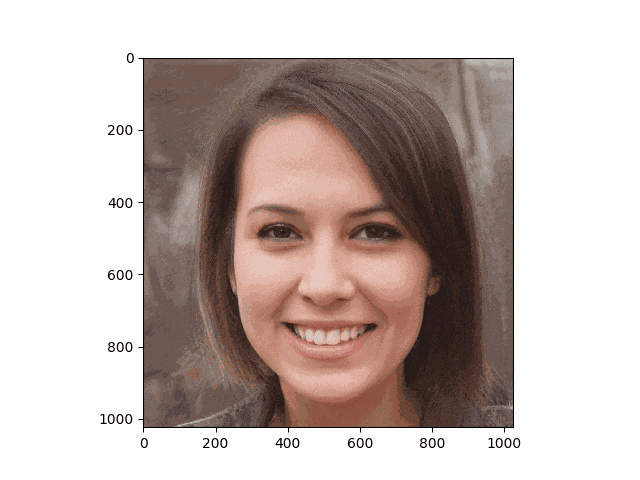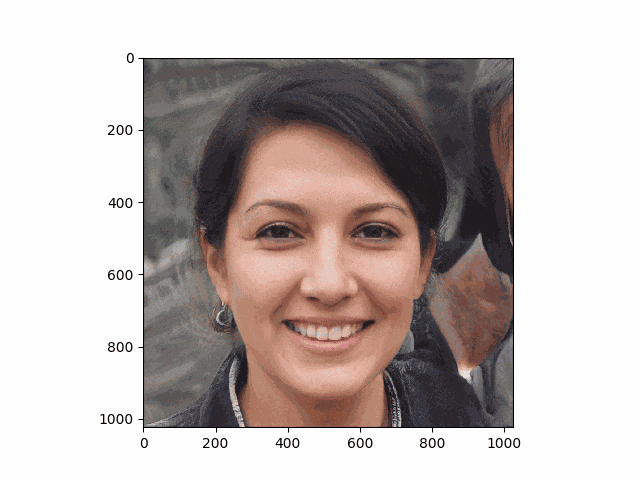
首元に変なartifactが見られますが、これはstylaganの公式pretrain重みを用いたときに起こり,推定アルゴリズムとは無縁のものだそうです。(最近出たstylegan V25では解消されるのかな?)
新規画像で試す
今までの動画はすべてStyleGANで生成された画像に対して行いました。しかし潜在変数推定の最大の利点は__StyleGANが生成していない画像にも適用できる__ところにあります。もし上手くいけば画像編集などにも応用が期待できそうです。
有村架純さんと橋本環奈さんで試したものが次のgifです。妙なテカリはありますが思ったより上手くいきました
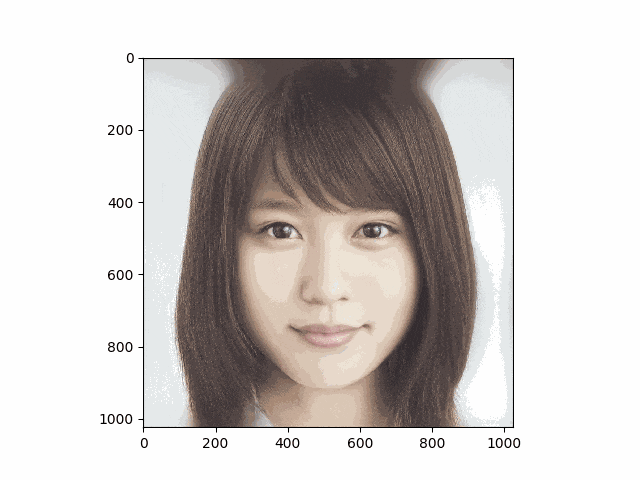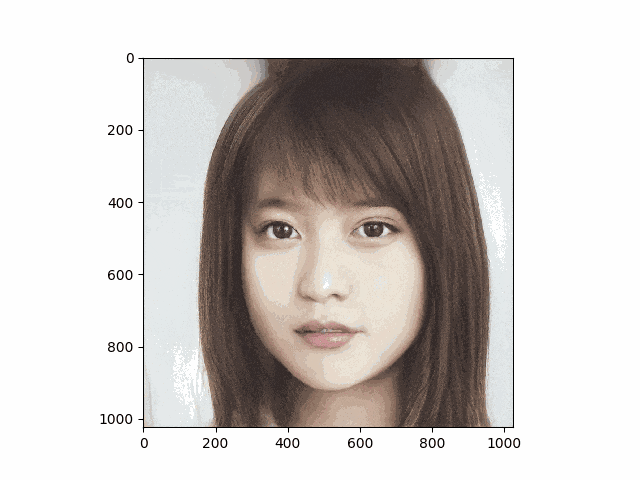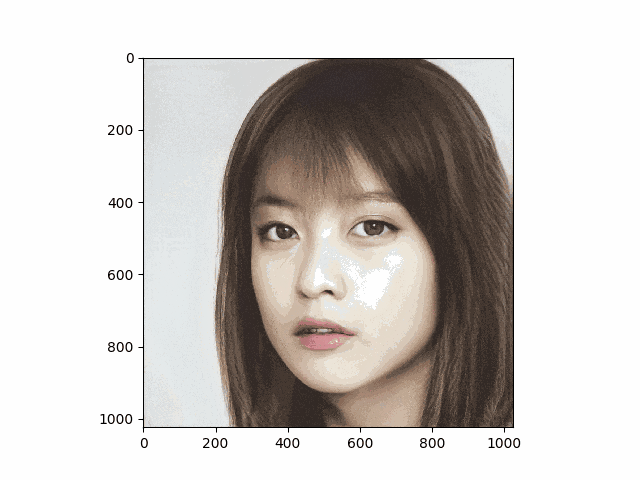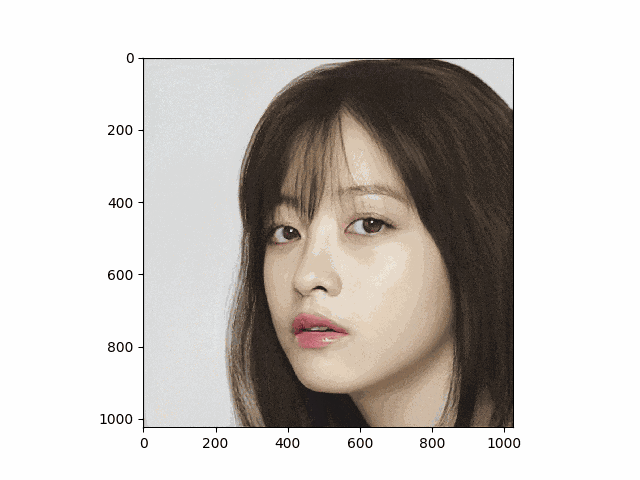
なおStyleGANの学習で使用されるデータセットはすべてalignされているため、試す際も同じようにalignしないと上手く生成できないことが多いです。
Image2StyleGAN++: How to Edit the Embedded Images?6
前の論文と同じ著者による続編です。この論文は__先の潜在変数推定のアルゴリズムを改良し、様々な画像編集に応用させています__
より正確に復元するためのアルゴリズムの改良
前の論文では画像を復元する際、__w__のみの最適化を行っていましたが、__Noise__に関しても最適化を行えばより細かい部分まで再現できるはずです。
よってアルゴリズムを少し改良し、今までの__w__最適化の後、__w__を固定し、__Noise__を同じようにMSE Lossを使って最適化させます。(w,__Noise__を同時に最適化するよりもこの順番が一番良いそうです。)

図3 論文Fig6より(a)target画像 (b)wのみの最適化 (c)w最適化後にNoise最適化 (d) (c)からさらにw最適化
図3が各最適化における復元画像の比較です。細かすぎてぱっと見違いがわかりませんが、(c)の__w__最適化の後に__Noise__を一回だけ最適化するのが一番PSNRが高いそうです。(d)は__w__,Noise,最適化の後さらにもう一回__w__を最適化した場合ですが,画像が平滑化されるため、何度も最適化を繰り返すのは良くなく、各一回だけの最適化をすべきとのこと。
Image Crossover
顔画像の一部にMaskをかけたものをターゲットイメージとすると潜在変数の部分的な最適化が可能になります。さらに,マスクをかけた場所を別の顔画像を使って最適化させると,2つの顔画像を自然な形で合成することができます。

図4 部分的なTarget画像
図4において、__画像A×Mask,画像B×(1-Mask)__としたものそれぞれでロスを計算すると次のような画像が作れます。

図5 image crossover
その他のアプリケーション
他にも元論文では画像にMaskをかけて最適化の仕方を少し変えてやることで様々な画像編集にトライしています。
Image Inpainting

図6 論文6Figより
Local style transfer

図7 論文6Figより
Unconstrained Facial Expression Transfer using Style-based Generator7
次はFacebook AIによる論文を紹介します。潜在変数により画像を気軽に操作できるので、それを利用して表情を交換することにチャレンジしています。
異なる損失関数を用いた潜在変数推定
Identityを保持したまま画像1の表情だけを別の顔画像2の表情に取り替えられたら便利です。
そのために潜在変数推定の際、Identityに関しては画像1で最適化を行い、表情に関しては画像2で最適化を行うことを考えます。
すると最適化の際の損失関数は次のように表すことができます。
$s_{0}=\arg \min D_{1}\left(g(s), I_{1}\right)+D_{2}\left(g(s), I_{2}\right)$
ここで$D1$,$D2$はそれぞれIdentity(論文中ではappearanceという語),表情(expression)の差を計算する損失関数です。
果たしてそんな損失関数があるのかという話ですが、ここでは近似的にappearanceに関してはStyle Loss,expressionに関してはContent Lossを用います。
このお気持ちですが、おそらくContent Lossの方は位置的な制約が強く、目や口などが同じ位置にないと値が大きくなります。一方StyleLossはContent Lossよりも位置的な制約が弱いので多少目や口などのパーツがピクセル間でずれていても許容され、Identityを保持しているかがより重要になるからだと思います。
ただし、これだけではappearance,expressionを綺麗に分離することはできません。$D1$,$D2$はあくまで近似的な損失関数になります。
そこで次のような考え方を使って潜在変数に制約をかけます。
18個の潜在変数の役割
潜在変数__w__は512次元のベクトルが18個あるのですが、この18個は生成段階において、それぞれ異なる解像度で入力されています。(図1参照)
4x4のときのlayerで最初の2個、8x8で次の2個,...1024x1024で最後の2個というように。すると各解像度における潜在変数の役割は異なることになります。すなわち解像度が低いlayerで入力される潜在変数は,顔の向きや形といった大域的な情報を操作し、解像度が高いlayerでは,目や口元といった局所的な情報を操作します。
これに着目すると,表情を操作する層を見つけ、その層の潜在変数だけをcontent lossで最適化し、それ以外の潜在変数に関してはstyle lossで最適化すれば、より明確にappearanceとexpressionを分けることができるはずです。
よって最終的な潜在変数$s_0$は別々に最適化した潜在変数,$s_1$,$s_2$を用いて次の式で表せます。
$s_0=αs_1+βs_2$ (ただし,$β=1-α$)
ここで$α$は$diag$(0,0,0,1,1,0,...,0)とするのが実験的に良いそうです。
試してみる
StyleGANで生成した画像と橋本環奈さんの表情を入れ替えてみます。

図8 表情交換 上段が元画像、下段がお互いの表情を入れ替えた画像
![]()
![]()
![]()
![]()
![]()
私の実装が悪いのかもしれませんが,styleGANで生成していない新規画像は難しそうです。
Interpreting the Latent Space of GANs for Semantic Face Editing 8
最後は追加学習なしとはいきませんが、StyleGANの潜在変数をどのように動かしたら,思い通りの編集ができるのか?ということにチャレンジした論文を紹介します。
潜在変数の意味的境界
上に挙げたmorphing動画などでも確認できますが,潜在変数を色々と動かしていくと、生成される画像の性別や年齢、poseといったものが連続的に変わっていきます。では潜在変数をどの方向に動かしたらposeや年齢といったものが自由に操作できるのでしょうか?
それを考えるために図9のようなモデルを考えてみましょう。
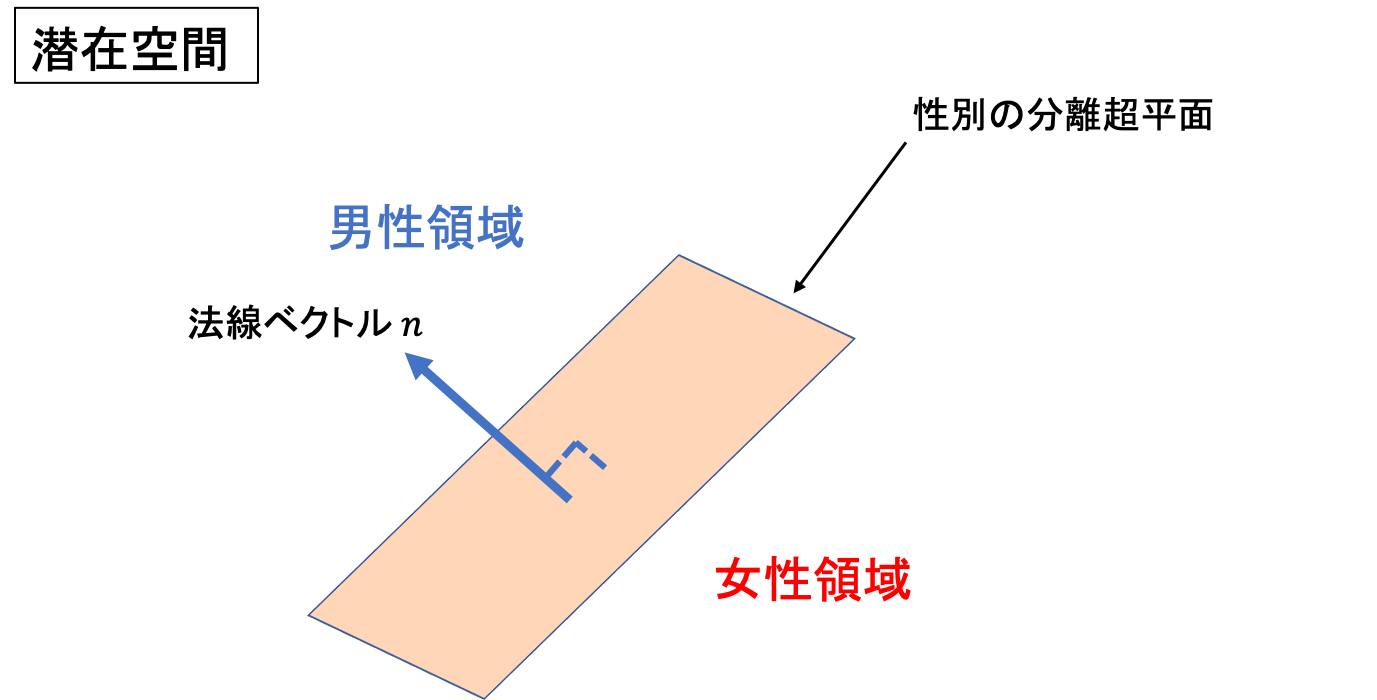
図9 潜在変数の意味的境界イメージ図
これは潜在変数が動く空間、潜在空間(latent space)をイメージしたものです。
もし潜在変数を動かして性別が連続的に変わっていくのだとしたら、性別が男性から女性に変わる境界面が存在するはずです。すなわち図7の__「性別の分離超平面」のこちら側にある潜在変数からは男性の画像が、超平面の向こう側にある潜在変数からは女性の画像が生成され、また境界面のすぐ近くではどちらとも言えない中性的な画像が生成されると考えられます。__
さてもしこのような境界面を見つけることができたら、その法線ベクトル__n__を定義してあげて、潜在変数を__n__と平行に動かしてあげれば性別を自由に操作できるのではないでしょうか
また同様のことは性別以外にも,smile,age,eyeglasses,poseと同じように各々の分離境界面を見つけてあげれば操作可能です。
分離境界面の決定
分離境界面の決定にはSVMを用います。StyleGANで生成した画像に対し、各属性でラベル付けしてあげて,潜在変数をよく分離できるような超平面を推定します。

図10 生成画像の超平面からの距離
SVMで得られた超平面で画像を評価すると図10のようになります。(Distanceは法線ベクトルと潜在変数の内積と定義しています。マイナスも含めているので厳密な距離ではないです)
これを見ると距離0付近、すなわち超平面の近くではどちらの属性とも言えない画像が、逆に遠くにははっきりと属性が認識できるような画像が分布していることがわかります。
Conditional manipulation
さて超平面が検出できたら,後はその法線方向に潜在変数を動かしてあげれば属性操作ができるわけですが、ここで一つ問題があります。それは各属性の法線ベクトルが直交しているとは限らないことです。
図11を見てください。

図11 age属性方向に潜在変数を動かしたときの生成画像
推定したage属性平面の法線方向に潜在変数を動かすと、ageだけでなく性別も変わってしまっています。
これは図12のように__各属性の法線が直交していないため__に起こります。ある属性を動かすと、他の属性の法線方向にも動いちゃうんですね。

図12 2つの属性の法線(n1,n2)が直交していない例
これを防いで1つの属性だけを変えるため、変更したい属性法線__n1__から,変更したくない属性法線__n2__の__n1__成分を減算します。(ようするに平面2に関して平行になるよう動かす)
これを新しいベクトルとすることで図13のように一つの属性だけを変えた画像が生成できます。

図13 性別を保持したままageの方向に潜在変数を動かしたときの生成画像
試してみる
私がStyleGANが生成した画像と新規画像で試した結果を載せます。
上から__gender,age,pose,eyeglasses,smile__の軸にそって生成したものです。
やはり新規画像に対しては性能はおちてしまいました。










図14 生成結果
実装
この記事で言及したいくつかのプログラムをpytorchで実装しました。
私のgithubにコードを挙げておきます。
またgoogle colaboratory上で試せるようにStyleGAN_editor.ipynbという.ipynb形式のものもありますので下記の注意事項を読んだ上でぜひ試してみてください。
注意事項
本当はgoogle colab上で上から実行していけば動くようにしたかったのですが,styleGANのpretrain重みとSVMのboundaryは自分でupできないので、用意していただく必要があります。
ノートブックのコメントに従ってhttps://github.com/NVlabs/stylegan と
https://github.com/ShenYujun/InterFaceGAN からそれぞれダウンロードしてください。
なお、colab上に重みファイルを直接アップロードするのは,かなり時間がかかるので,colabに慣れた人であればローカルでファイルを置いた後、google drive経由で上げるといった方法がオススメです。
また今回pytorchで実装していますが、公式の重みがtensorflowのため以下のコードを使わせていただいて,重みを変換しています。
https://github.com/lernapparat/lernapparat
まとめ
以上StyleGANの潜在変数推定に関する論文を紹介してきました。
やはり、StyleGANの生成していない新規の顔画像では全体的に性能が落ちてしまうようですね。
StyleGAN is All you needとか言いたかったんですが,これからの発展に期待といったところでしょうか。
ただ潜在変数の推定には2通りの発展の仕方があると思っています。一つは今回のように新規画像に対して適用するために用いる方向。もう一つは犯罪利用に使われる偽画像を見分けるために使用する方向です。後者はむしろ新規画像に対して性能が落ちてくれないと困るかもしれません。
どちらの応用先が今後トレンドになっていくかも注目して見ていきたいと思います。
最後まで読んでいただきありがとうございました
-
Talking Head Anime from a Single Image (https://pkhungurn.github.io/talking-head-anime/) ↩
-
Karras, T., Laine, S., & Aila, T. (2018). A Style-Based Generator Architecture for Generative Adversarial Networks. Retrieved from http://arxiv.org/abs/1812.04948 ↩ ↩2
-
Abdal, R., Qin, Y., & Wonka, P. (2019). Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? Retrieved from http://arxiv.org/abs/1904.03189 ↩ ↩2
-
Schlegl, T., Seeböck, P., Waldstein, S. M., Schmidt-Erfurth, U., & Langs, G. (2017). Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 10265 LNCS, 146–147. https://doi.org/10.1007/978-3-319-59050-9_12 ↩
-
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2019). Analyzing and Improving the Image Quality of StyleGAN. Retrieved from http://arxiv.org/abs/1912.04958 ↩
-
Abdal, R., Qin, Y., & Wonka, P. (2019). Image2StyleGAN++: How to Edit the Embedded Images? Retrieved from http://arxiv.org/abs/1911.11544 ↩ ↩2 ↩3 ↩4
-
Yang, C., Lim, S.-N., & Ai, F. (n.d.). Unconstrained Facial Expression Transfer using Style-based Generator. https://arxiv.org/abs/1912.06253 ↩
-
Shen, Y., Gu, J., Tang, X., & Zhou, B. (2019). Interpreting the Latent Space of GANs for Semantic Face Editing. Retrieved from http://arxiv.org/abs/1907.10786 ↩