序論
- サマリ
・公式sample codeから、バックエンドをv1に変更、eager modeをoffにする事で、tensor flow 2系でGradient Explainerを使用可能
import tensorflow.compat.v1.keras.backend as K
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
+notebookで動かす場合、上記を入れてもエラーが出ることがある。カーネルリスタート、ファイル開きなおし、モデル再読み込みだったりをしたら動く。
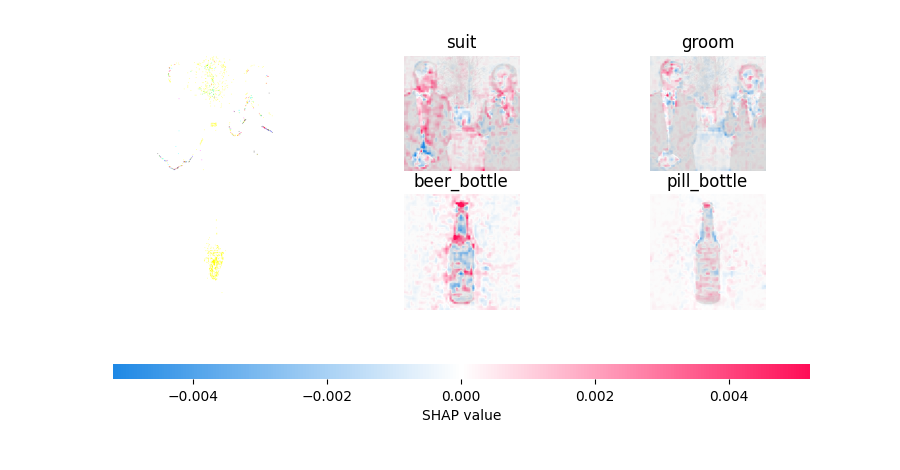
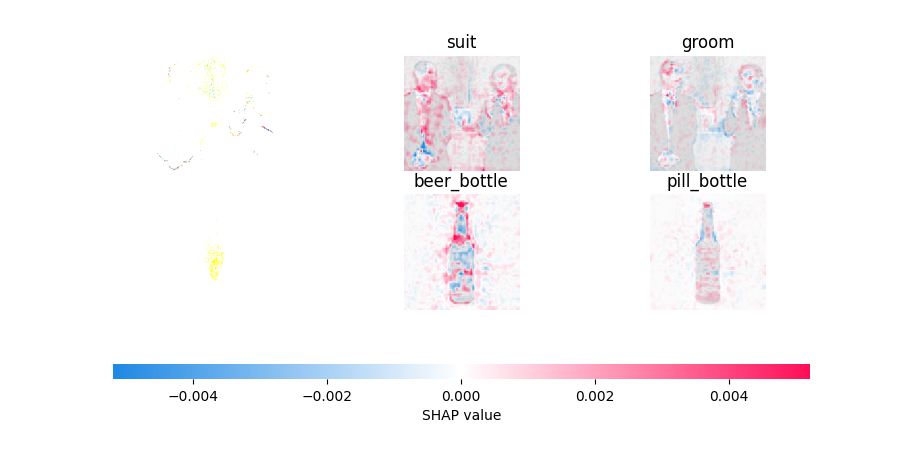
・SHAP公式チュートリアルでのGradient Explainer適用結果
(元画像表示がおかしくなってます、後々原因調査)
・オリジナルデータへのGradient Explainer適用結果@VGG16転移学習(抜粋)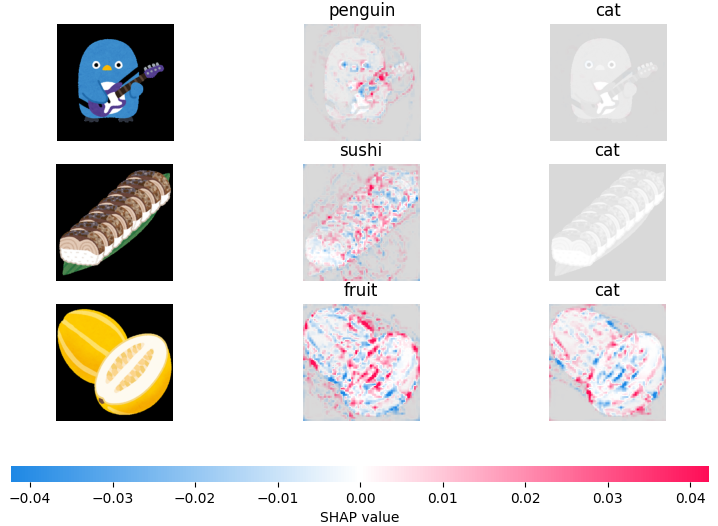
- イントロ
説明可能AI(XAI)とかいう言葉をよく見るようになってきました。
CNNなどを用いた画像処理系NNなんかでは、その出力結果の解釈に、しばしばGRAD-CAM
Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization; Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 618-626
(arXivだと2016年)
が使われている印象です。
一方、
SHAP
*原論文 : A Unified Approach to Interpreting Model
Predictions; 31st Conference on Neural Information Processing Systems, 2017
のGradient Explainerでも説明性を付与(言葉があっているか不明)、具体的には、分類結果に対してどの画素がどちらの方向(そのクラスであるorそのクラスではない)に貢献したかを可視化できるようですので、試してみました。
まずは公式チュートリアルそのままで、そのあとオリジナルデータセットを分類対象としたCNN分類器(VGG16学習済み重み転用)にSHAP Gradient Explainerを適用してみます。
不備等ございましたらご指摘いただければ幸いです。
【環境】
Python 3.7.2
TensoFlow 2.8.0
SHAP 0.41.0
*自分用備忘録です。やってみました的記事なので、詳しい解説は他の方の記事をご参照ください。
参考にさせていただいた記事
転移学習部分について、下記の記事を参考にしました。ありがとうございます。
KerasでVGG16のファインチューニングを試してみる
複数の画像をnumpy配列に読み込む
ImageDataGeneratorを使ってみた
SHAP Gradient Explainer チュートリアル
SHAP公式にチュートリアルがあります。
Explain an Intermediate Layer of VGG16 on ImageNet
これに基いて、CNN(VGG16)の中間層出力を可視化します。
- エラー対策
早々にエラー対策です。
tensor flow 2.X系で上記ページのsample codeを走らせると、下記エラーが出ると思います。
TypeError: Tensors are unhashable (this tensor: KerasTensor(type_spec=TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name='input_1'), name='input_1', description="created by layer 'input_1'")). Instead, use tensor.ref() as the key.
ここに対策が上がっています。
TypeError: Tensor is unhashable. Instead, use tensor.ref() as the key. in Keras Surgeon
backendをv1に、かつeager modeをoffにするとうまく動くようです。
具体的には、
import keras.backend as K を
import tensorflow.compat.v1.keras.backend as K
と変更し、
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
を追記してeager modeをoffにすれば動くようになります。
- 結果
可視化はできましたが、なぜか元画像の表示がおかしく、、、
赤:SHAP値が正, 青:SHAP値が負
赤い部分がクラスに対して正の働きをした画素(そのクラスであると判断する要素),
青い部分が負の働きをした画素(そのクラスではないと判断する要素)として考えています。
(個人的見解です。違っておりましたらご指摘ください。)
1行目のsuitについて見ると、人の顔部分とシャツ部分が主な判断根拠になっているかと思われます。
まぁ気を取り直して次に行きましょう次に
オリジナルデータに対するSHAP適用
VGG16ベースで転移学習させたCNNの中間層出力を可視化します。
ほぼ転移学習についてになってしまいましたが、ご愛嬌。
- 分類対象画像の準備
いらすとやさんの画像分類問題を考えます。
7種類の画像を各50枚用意しました。
各クラスについて、train:38枚、validation:8枚、test:4枚に分けました。
ImageDataGeneratorを使用する都合上、フォルダ構成は以下のようにしています。
current dict/
├ train/
│ ├ male/
│ │ ├ xxx.png
│ │ ├ yyy.png
│ │ ...
│ ├ female/
│ ├ dog/
│ ├ cat/
│ ├ penguin/
│ ├ fruit/
│ └ sushi/
│
├ valid/
│ ├ male/
│ │ ├ xxx.png
│ │ ├ yyy.png
│ │ ...
│ ├ female/
│ ├ dog/
│ ...
│
├ test/
│ ├ xxx.png
│ ├ yyy.png
│ ...
└[this_script.ipynb]
- VGG16の転移学習
必要なライブラリをインポートします。
(SHAP関連は後でインポートします。)
import tensorflow as tf
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Dense, Flatten, BatchNormalization, Dropout
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.applications.vgg16 import preprocess_input
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import glob
import os
train, validationデータフォルダのパスを指定しておきます。
クラス名のリストをos.listdir()で取得します。
(trainフォルダ直下に、クラス毎にフォルダを作っているのでこの処理でOKです。)
クラス数はlen()でとります。
train_dir = './train'
valid_dir = './valid'
#trainフォルダ内の全フォルダ名をリストとして読み込みます。
classes = os.listdir(train_dir)
#classes内の要素数をクラス数として読み込みます。
class_num = len(classes)
#クラス名リストとクラス数の確認です。
print(classes)
print(len(classes))
VGG16の構造と重みを読み込みます。
VGG16の19層目(block5_pool)からの出力をFlattenにかけてDense層へ渡せるようにし、Dense分類器を適当に追加します。
input sizeについては、image_rows, image_colsで縦横サイズを指定しています。カラー画像を対象とするので、チャンネル数は3としています。
#Dropout層のドロップアウト率
drop_rate = 0.2
#Dense層のユニット数
dim1 = 128
#入力する画像の縦(image_rows)、横(image_cols)を設定します。今回は(224, 224)
image_rows = 224
image_cols = 224
#include_top=FalseとすることでVGG16のFlatten以降のDense層を読み込まない設定にできます。
#weight="imagenet"とすることで、imagenetで訓練済みの重みを読み込みます。
#wight="None"でランダムな重みを読み込むこともできます。
#input_shape=(縦、横、チャンネル数)でネットワークへの入力画像サイズを指定できます。
vgg16 = VGG16(
weights="imagenet",
input_shape=(image_rows, image_cols, 3)
)
#vgg16.get_layer['任意の層名'、ここでは'block5_pool'].outputで、
#vgg16の'block5_pool'層の出力を取り出しています。
vgg16_mid = Model(
inputs=vgg16.input,
outputs=vgg16.get_layer('block5_pool').output
)
x = Flatten()(vgg16_mid.output)
x = BatchNormalization()(x)
x = Dropout(drop_rate)(x)
x = Dense(units=dim1, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(drop_rate)(x)
x = Dense(units=dim1*2, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(drop_rate)(x)
x = Dense(units=dim1*4, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(drop_rate)(x)
x = Dense(units=dim1*8, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(drop_rate)(x)
#分類問題なのでactivationはsoftmaxです。
output = Dense(units=class_num, activation='softmax')(x)
#Functional形式です。inputsには、vgg16_mid.inputを指定すればOKです。
model = Model(inputs=vgg16_mid.input, outputs=output)
19層目(Flattenの直前の層)までは重みを固定し、以降の層を学習する設定にします。
その後コンパイルしてモデル構築完了です。(ちょっとDenseを積みすぎた感じはします)
_*VGG16最後のconvolution層も学習するには(これをfine tuningと呼ぶのか?)、
for layer in model.layers[:19]: -> for layer in model.layers[:15]:とすれば可能です
#model.layers[:x]で、構築したモデルの各層(x層まで)にアクセス
#layer.trainable = Falseで学習をしない設定にできます。
for layer in model.layers[:19]:
layer.trainable = False
#compileは上記の学習設定後にする
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy']
)
#モデル構造確認
model.summary()
バッチサイズを設定し、ImageDataGeneratorをtrain,validationで別個に設定します。
train, validationともにrescaleをかけてあげて、画素値を0 - 1の範囲に収めます。
trainデータに対しては、拡大縮小/反転/回転処理などをランダムに適用するように設定しています。
validationデータに対してはrescaleのみの設定です。
ImageDataGeneratorの使い方に関しては、下手に私が書くよりも素晴らしい記事が既にありますので、ご参照ください。
ImageDataGeneratorを使ってみた
batch_size = 32
train_datagen = ImageDataGenerator(rescale=1./255,
zoom_range=0.2,
horizontal_flip=True,
rotation_range=90,
vertical_flip=True
)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(image_rows, image_cols),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_directory(
valid_dir,
target_size=(image_rows, image_cols),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
準備が終わりましたので、学習させます。ImageDataGeneratorでbatch_sizeを既に指定しているので、fit実行時には指定しません。(引数にbatch_size=xxと入れてしまうとエラーが出ます。)
とりあえずエポック数は大きく設定しておき、callbackでearly stoppingを設定しておきます。
callbackの設定はお好みで。
model_name = 'VGG16_1.h5'
#trainingは学習をするか、既存h5ファイルを読み込むかのflaagです。Trueで学習します
training = True
epochs = 200
if training == True:
history = model.fit(
train_generator,
validation_data=validation_generator,
epochs=epochs,
callbacks=[
tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=20, verbose=1, mode='auto'),
tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.001),
tf.keras.callbacks.ModelCheckpoint(filepath='VGG16_1_best.h5',monitor='val_loss',save_best_only=True)
]
)
model.save(model_name)
else:
model = load_model(model_name)
#model = load_model('VGG16_1_best.h5')
model.summary()
- Gradient Explainerの適用
学習が完了したら、ようやっとSHAPに入れます。
(前処理クッソ長くなりますがご容赦ください)
testフォルダ内の画像を整形し、リストXに格納します。
Xのshape = (枚数, image_rows, image_cols, 3)
このリストXの一部の画像をshap.GradientExplainer.shap_valuesの引数に渡すことになります。
またSHAPモデルの期待値計算用に、train画像から適当に変換した画像のリストYを作成します。
リストYは、shap.GradientExplainerの引数に渡すことになります。
変換の所については、透過pngを対象にImage.openでそのまま開くと、カラーチャンネルの形式がRGBAとなってしまうので、途中でRGBにしています。
またリサイズもかけています。
from PIL import Image
#test用画像をリスト化(name:X)します。X -> (testファイル数, image_rows, image_cols, 3)
image_dir = './test'
search_pattern = '*.png'
datas = []
for image_path in glob.glob(os.path.join(image_dir,search_pattern)):
data = Image.open(image_path).convert('RGB')
width, height = image_cols, image_rows
x_ratio = width / data.width
y_ratio = height / data.height
resize_size = (round(data.height*y_ratio), round(data.width * x_ratio))
data = data.resize(resize_size)
data = np.array(data)
data_expanded = np.expand_dims(data,axis=0)
datas.append(data_expanded)
X = np.concatenate(datas,axis=0)
#SHAP期待値計算用のファイルリストYを、train用画像から生成します。
#genは画像を生成するかどうかのflagです
gen = True
generate_dir = "generate"
#generateフォルダを作成します。
if os.path.isdir(generate_dir) == False:
os.mkdir(generate_dir)
generate_dir = './generate'
if gen == True:
#1枚ずつ画像を生成したいので、generate用ImageDataGeneratorのバッチサイズは1とします。
generate_batch = 1
#generatorの引数を設定します。ご自由に
generate_datagen = ImageDataGenerator(rescale=1./255,
zoom_range=0.2,
horizontal_flip=True,
rotation_range=90,
vertical_flip=True
)
generate_generator = generate_datagen.flow_from_directory(
train_dir,
#save_to_dirを指定することで、生成した画像を指定フォルダに保存できます。
save_to_dir=generate_dir,
target_size=(image_rows, image_cols),
batch_size=generate_batch,
class_mode='categorical',
shuffle=True
)
#for文で100枚画像を生成します。
for i in range(100):
generate = generate_generator.next()
search_pattern = '*.png'
datas = []
for image_path in glob.glob(os.path.join(generate_dir,search_pattern)):
data = Image.open(image_path).convert('RGB')
width, height = image_cols, image_rows
x_ratio = width / data.width
y_ratio = height / data.height
resize_size = (round(data.height*y_ratio), round(data.width * x_ratio))
data = data.resize(resize_size)
data = np.array(data)
data_expanded = np.expand_dims(data,axis=0)
datas.append(data_expanded)
Y = np.concatenate(datas,axis=0)
else:
search_pattern = '*.png'
datas = []
for image_path in glob.glob(os.path.join(generate_dir,search_pattern)):
data = Image.open(image_path).convert('RGB')
width, height = image_cols, image_rows
x_ratio = width / data.width
y_ratio = height / data.height
resize_size = (round(data.height*y_ratio), round(data.width * x_ratio))
data = data.resize(resize_size)
data = np.array(data)
data_expanded = np.expand_dims(data,axis=0)
datas.append(data_expanded)
Y = np.concatenate(datas,axis=0)
さてGradient Explainer実行です
import shap
import tensorflow.compat.v1.keras.backend as K
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
#Xに格納された画像全てを可視化対象にします。(計28枚)
to_explain = X[0:28]
# explain how the input to the 7th layer of the model explains the top two classes
#第7層目の出力を可視化をします。layers[]とmap2layerの層指定部分を7と設定します。
def map2layer(x, layer):
feed_dict = dict(zip([model.layers[0].input], [preprocess_input(x.copy())]))
return K.get_session().run(model.layers[layer].input, feed_dict)
e = shap.GradientExplainer((model.layers[7].input, model.layers[-1].output), map2layer(preprocess_input(Y.copy()), 7))
shap_values,indexes = e.shap_values(map2layer(to_explain, 7), ranked_outputs=2)
# get the names for the classes
#sample codeから、オリジナルデータのラベルリストに合わせてlambda式の部分を変更しています。
index_names = np.vectorize(lambda x: classes[x])(indexes)
# plot the explanations
shap.image_plot(shap_values, to_explain, index_names)
- 結果
こんなんでした。sample codeのほうでは元画像表示がおかしくなりましたが、こちらでは正常に表示できました。
validation accuracyが0.6後半そこそこのモデルだったので、ほとんど当たっていませんね。
両目と口の位置にSHAP valueが集中している場合が多く、分類に比較的大きな影響を及ぼしていそうです。それっぽいもの(両目と口らしきもの)があったら、dog、 catに分類されてしまってそうな挙動ですね。あとなんか見えないものを見ようとしている挙動が、、、

とはいえ、今回適当なDense層を噛ませただけなので、もっとちゃんとネットワーク構造を練ればうまくいきそうです。
あとはイラストである都合上、タッチやカラーリング、全体のデザインも似ているので、いらすとやさんのデータ自体が推測しにくいのもあるかもしれません。
結論
無事オリジナルデータセットに対して、Gradient Explainerによる中間層出力可視化ができました。(精度は度外視)
GRAD-CAMと比較して、各領域の予測値への貢献度が可視化されるので、より重要な形状?特徴?が直観的にわかりやすい感触です。
ご興味があれば皆さんも自前データセットでお試しください。
jupyter notebook上で、記載コードを1セル毎に実行していけばうまくいくんじゃないかなとふんわり思います。(責任逃れ)