はじめに
以前のスクレイピングのデモ記事にも書いた通り、私は「小説家になろう」が好きです。
300話を一気に読み切って続きが待ち遠しくなるなんてことがよくあります。
そういうときに困ったことがありまして…。
どうやら「小説家になろう」には公式の更新通知が実装されていないようなのです。
「毎日更新を確認するのが面倒くさい」
と感じ、自動更新通知システムを作ることにしました。
※今回は「小説家になろう」でデモを行っていますが、うまくいじれば他にもさまざまなことに活用できます。メール通知、可能性の広がりを感じますね。
やること
- Xserverの独自ドメインメールを利用して
- 「小説家になろう」内の指定した作品について
- 新しい話が公開されていればメールで通知するプログラムを
- 毎日18時に自動実行する
何ができるのか
以下のような通知メールが1日に1回、10日に1回などの任意のタイミングで送られてきます。
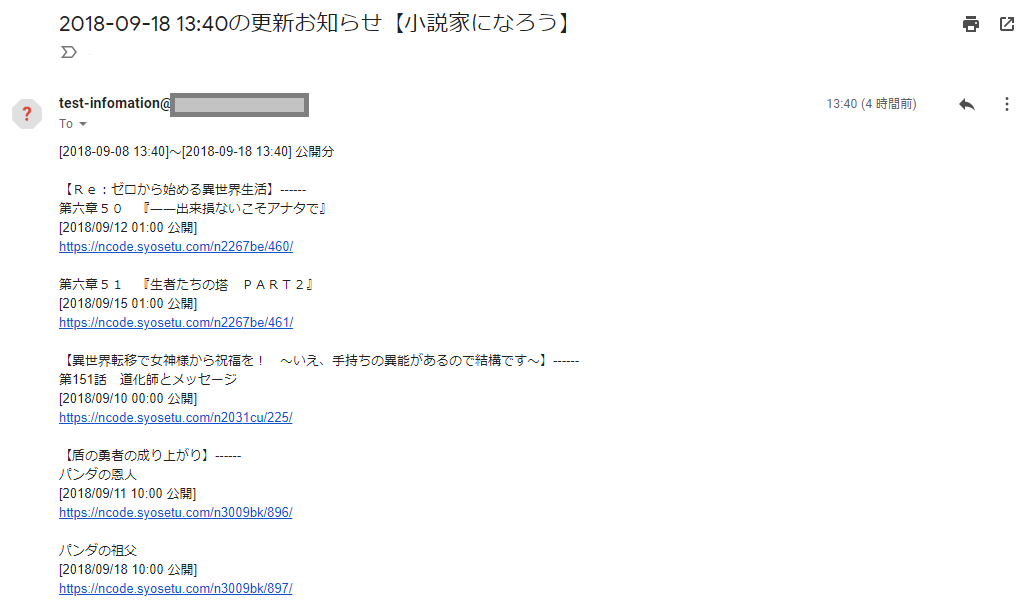
※新規公開がなければメールは来ません。毎日メールが来ると無視するようになってしまうので。
流れ
-
以下の機能を持つプログラムを作成
- 各作品ページをスクレイピングして情報を抽出
- 新しく公開された話があるかどうかを判定
- 抽出した情報からメールの件名・本文を生成
- メールを送信
毎日自動実行されるように設定
環境
- Windows10 64bit
- Python3.7
- beautifulsoup4 4.6.3
- Xserver上の独自ドメインメールを使用
前準備
- Xserver上の独自ドメインメール等、使用するメール環境を設定しておく
コード
0. logのためのおまじない
参考:ログ出力のための print と import logging はやめてほしい - Qiita
from logging import getLogger, StreamHandler, DEBUG
logger = getLogger(__name__)
handler = StreamHandler()
handler.setLevel(DEBUG)
logger.setLevel(DEBUG)
logger.addHandler(handler)
logger.propagate = False
1. 以下の機能を持つプログラムを作成
- 各作品ページをスクレイピングして情報を抽出
- 新しく公開された話があるかどうかを判定
- 抽出した情報からメールの件名・本文を生成
- メールを送信
import os
import sys
import time
import datetime
from urllib.request import urlopen
from bs4 import BeautifulSoup
import smtplib
from email.mime.text import MIMEText
from email.header import Header
作品ページのURLやメールサーバへの接続・認証用の変数を設定します。
メールサーバの認証にはメールアドレスやパスワード等の情報が必要ですが、ソースコードにベタ打ちするのは危険です。
今回はsys.argv[1]という形でコマンドライン引数から持ってくることにします。
# --------------------------------------
# 作品ページのURLを指定(コメントアウト・コメントインで指定できるようにしています)
url_list = [
"https://ncode.syosetu.com/n2267be/" # Re:ゼロから始める異世界生活
,
# "https://ncode.syosetu.com/n6316bn/" # 転生したらスライムだった件
# ,
"https://ncode.syosetu.com/n2031cu/" # 異世界転移で女神様から祝福を! ~いえ、手持ちの異能があるので結構です~
# ,
# "https://ncode.syosetu.com/n3009bk/" # 盾の勇者の成り上がり
,
"https://ncode.syosetu.com/n6475db/" # 私、能力は平均値でって言ったよね!
# ,
# "https://ncode.syosetu.com/n5881cl/" # 賢者の孫
]
# --------------------------------------
MAILADDRESS = sys.argv[1]
MY_SECRET_PASSWORD = sys.argv[2]
from_address = MAILADDRESS
to_address = sys.argv[3]
SMTP_SERVER = sys.argv[4]
PORT_NUMBER = int(sys.argv[5])
delay_days = 1 # 通知頻度(日)
メインの処理です。
スクレイピングとメール通知の2段階の処理がなされます。
def main():
"""
メイン処理
"""
new_stories = {}
# 各作品に処理を実行
for url in url_list:
html = urlopen(url)
print('access {} ...'.format(url))
bs_obj = BeautifulSoup(html,"html.parser")
time.sleep(2)
# 前回通知以降に更新された話のリストを抽出
new_story_list = []
for no in range(len(bs_obj.findAll("dd",{"class":"subtitle"})))[::-1]:
# 作品ページから指定した話の情報を抜き出す
story_info = get_story_info(bs_obj, no)
# 前回の通知よりも後に話が公開されたかどうかを判定
if is_new(story_info, delay_days):
new_story_list.append(story_info)
print("New: {}".format(story_info['url']))
else:
break
new_story_list = new_story_list[::-1]
novel_title = get_novel_title(bs_obj)
if new_story_list:
new_stories[novel_title] = new_story_list
if new_stories:
# メールの件名・本文を生成
mail_subject, mail_body = create_mail_text(new_stories)
# メール通知
send_mail(from_address, to_address, mail_subject, mail_body)
else:
print('最新話の公開はありません。')
1.1. 各作品ページをスクレイピングして情報を抽出
各作品ページから
- 作品名
- 話のタイトル
- 公開日時
- URL
を抽出します。
新しい話から順に抽出することで最低限の作業量に抑えます。
def get_novel_title(bs_obj):
"""
作品名を抽出
"""
novel_title = bs_obj.findAll("p",{"class":"novel_title"})[0].get_text()
return novel_title
def get_story_info(bs_obj, story_no):
"""
作品ページから指定した話の情報を抜き出す
"""
novel_title = get_novel_title(bs_obj)
story_url = "https://ncode.syosetu.com" + bs_obj.findAll("dd",{"class":"subtitle"})[story_no].findAll("a")[0].attrs["href"]
story_info = {
"title": bs_obj.findAll("dd",{"class":"subtitle"})[story_no].findAll("a")[0].get_text(),
"date": bs_obj.findAll("dt",{"class":"long_update"})[story_no].get_text().replace('\n', '').replace('(改)', ''),
"url": story_url,
"novel_title": novel_title,
}
return story_info
1.2. 新しく公開された話があるかどうかを判定
スクレイピング時の日時と各話の公開日時を比較し、前回の通知以降に公開された話があるかどうかを判定します。
def is_new(story_info, delay_days):
"""
前回の通知よりも後に話が公開されたかどうかを判定
"""
story_datetime = datetime.datetime.strptime(story_info["date"], '%Y/%m/%d %H:%M')
pre_scraping_datetime = datetime.datetime.now() - datetime.timedelta(days=delay_days) # 前回の通知時点
return story_datetime > pre_scraping_datetime
1.3. 抽出した情報からメールの件名・本文を生成
メール本文が見やすくなるように、抽出したデータをstr型に整えます。
def create_mail_text(new_stories):
today = datetime.datetime.now()
mail_subject = '{}の更新お知らせ【小説家になろう】'.format(today.strftime('%Y-%m-%d %H:%M'))
mail_body = '[{}]~[{}] 公開分\n\n'.format((datetime.datetime.now() - datetime.timedelta(days=delay_days)).strftime('%Y-%m-%d %H:%M'), today.strftime('%Y-%m-%d %H:%M'))
for new_story_title, new_story in new_stories.items():
mail_body += '【{}】------\n'.format(new_story_title)
for new in new_story:
mail_body += '{}\n[{} 公開]\n{}\n\n'.format(new['title'], new['date'], new['url'])
return mail_subject, mail_body
1.4. メールを送信
メールサーバとの接続を行い、メールを送信します。
※以下のコードはPORT_NUMBER = 465でSSLを利用する場合です。
ポート番号が587のTLSを利用する場合はコードが若干異なります。
def send_mail(from_address, to_address, mail_subject, mail_body):
"""
メール通知
"""
# サーバーと接続
smtp_obj =smtplib.SMTP_SSL(SMTP_SERVER, PORT_NUMBER)
smtp_obj.ehlo() # サーバーとの接続を確立
smtp_obj.login(MAILADDRESS, MY_SECRET_PASSWORD) # SMTPサーバーにログイン
# 日本語のメッセージを送信するための記述
charset = 'UTF-8'
mail_text = MIMEText(mail_body, 'plain', charset)
mail_text['Subject'] = Header(mail_subject.encode(charset), charset)
mail_text = mail_text.as_string()
# メール送信
try:
send_result = smtp_obj.sendmail(
from_address,
to_address,
mail_text)
print('Sending {}...'.format(to_address))
time.sleep(1)
finally:
smtp_obj.quit() # サーバーとの接続を切断
print('サーバーとの接続を切断。')
# メール送信失敗時の結果を表示
if send_result:
for key in send_result.keys():
print('{}へのメール送信失敗。'.format(key))
else:
print('送信したメール本文\n\nSubject: {}\n\nMessage: {}'.format(mail_subject, mail_body))
実行用
if __name__ == '__main__':
main()
毎日自動実行されるように設定
毎日自動で実行するための設定が必要です。
ここでは、ローカル環境で実行することとし、batファイルとタスクスケジューラを使用します。
1. batファイルを作成
batファイルとは、簡単にいうと
「コマンドプロンプトで実行するコマンドを羅列したファイル」
です。
ダブルクリックでそれぞれのコマンドを順番に実行できます。
メモ帳などのテキストエディタでコマンドを書き、拡張子を「.bat」で保存すれば完成です。
pipenvで構築した仮想環境内で実行するため、今回はbatファイルを以下のように作成します。
cd C:\Users\workspace\venv
pipenv run python C:\Users\workspace\venv\ScrapingMail\ScrapingMail.py information@xxxxx.com mail-password to-mailaddress@xxxxx.com server smtp-port
pause >nul
コマンドライン引数に
- 通知に使用するメールアドレス
- メールアドレスのパスワード
- 宛先メールアドレス
- メールサーバのSMTPサーバー名
- ポート番号
を含めて実行することで、Pythonプログラムにこれらの変数を渡します。
※pause >nulを入れておくことで、実行後すぐにコマンドプロンプトが終了してしまうことを防ぎます。
2. タスクスケジューラを設定
タスクスケジューラは任意のプログラムをスケジュールを組んで実行するためのツールです。1
設定方法は以下の記事をご覧ください。
「Python3のWindows環境における手動/自動実行方法+実行形式化まとめ。 | KodoCode」
以上で完了です。
まとめ
以上により、設定したタイミングに新規記事公開の確認が行われ、新規記事があった場合にはメールで通知が来ます。
毎日自分で更新を確認しにいくのは面倒ですよね。
本記事の設定さえしてしまえば、後は放置しておいても毎日通知が来るのでとても便利です。
ちょうど仕事も終わって一息つくころに通知が来るように設定し、快適な「小説家になろう」ライフを送りましょう。
これらのプログラムを活用すれば、他にもさまざまなことを自動でメール通知してくれるシステムを構築できます。
自動化の幅が広がりますね。
※ローカル環境での設定のため、PCの電源が切れていた場合はメール通知は来ません。
参考
コードは主に以下を参考にさせていただきました。
- 『Pythonクローリング&スクレイピング―データ収集・解析のための実践開発ガイド―』技術評論社
- 『退屈なことはPythonにやらせよう――ノンプログラマーにもできる自動化処理プログラミング』O'Reilly Japan
GitHub
ソースコードはGitHub上でも公開しています。
https://github.com/kokokocococo555/ScrapingMailer-demo
課題
- サーバ上やクラウド上で実行するシステムにすることで、ローカルのPCと切り離して運用する。
- 他の方も使えるように、Webサービス化・LINE bot化する。
注意
Webスクレイピングでは著作権等で気をつけるべきことがあります。
以下記事を参考に、ルール・マナーを意識しておきましょう。
関連記事【スクレイピング・自動化】
-
基本的なスクレイピング(
BeautifulSoup4) -
APIを利用したスクレイピング・データベースへの保存(
MongoDB)・データ分析の一歩(pandas) -
JavaScriptを用いたサイトのスクレイピング(
Selenium,PhantomJS) -
メール通知(
smtplib)・定期的なプログラムの自動実行(タスクスケジューラ) -
自動ログイン(
Selenium,ChromeDriver)
-
MacにはLaunchd、Linuxにはcronという似たようなツールが備わっているようです。 ↩