はじめに
YoutubeのAPIを用いて検索結果(動画の情報)をMongoDBに突っ込み、整形してcsvファイルに書き出したりpandasで分析したりします。
youtubeでの検索結果を視聴回数順やLike順にソートできるため、
「気になっているyoutuberがいるんだけど、どの動画を観ればいいか分からない!」
というときなどに便利ですね。
背景
最近、Web上の情報・データを取ってくる「クローリング・スクレイピング」がおもしろいなと思っています。
そこで、『Pythonクローリング&スクレイピング』という本を参考に実践中なのですが、今回はその一環です。
なぜバーチャルYouTuberの輝夜月さんの動画なのか。
それは、私が輝夜月さん大好きだからです。おもしろくて愛らしい。すてきです。
バーチャルYouTuberとして颯爽と登場した輝夜月さんの動画を観て、新時代の到来を感じましたよね。
なんてすごい時代になったんだ、と。
最近全然追えてないので、ちょうどいいなと思いまして。
やること
- YouTubeのAPIを用いて検索結果から動画情報を収集し、MongoDBに保存
- 保存したデータを整形してcsvに書き出し
- csvをpandasで読み込んでデータを分析
環境
- Windows10 64bit
- Python3.5
- MongoDB 4.0.2
前準備
- pandasが必要なのとJupyter Notebookが便利なので、Anacondaも入れておきましょう。
- YouTubeからAPIでデータを取ってくるために、GoogleでAPIキーの取得と設定も行いましょう。
- コードを実行する前にMongoDBをインストールし、起動させておく必要があります。
コード
1. YouTubeのAPIを用いて検索結果から動画情報を収集し、MongoDBに保存
import sys
from apiclient.discovery import build # pip install google-api-python-client
from pymongo import MongoClient, DESCENDING # pip install pymongo
YOUTUBE_API_KEY = '<APIキーを記入>'
query = '輝夜月' # 検索キーワード
max_pages=8 # データを収集するページ数
maxResults=50 # 1ページあたりの動画数
# max_pages * maxResults 分の動画の情報を取ってくる。大きすぎる設定だと途中でエラーが出ることも。
def main():
"""
メイン処理
"""
mongo_client = MongoClient('localhost', 27017) # MongoDBと接続
db = mongo_client.kaguya
collection = db.luna # kaguyaデータベース -> lunaコレクション
collection.delete_many({}) # 既存の全てのドキュメントを削除しておく
for items_per_page in search_videos(query, max_pages, maxResults):
save_to_mongodb(collection, items_per_page)
def search_videos(query, max_pages=10, maxResults=50):
"""
動画を検索してページ単位でlistをyieldする
"""
youtube = build('youtube', 'v3', developerKey = YOUTUBE_API_KEY)
search_request = youtube.search().list(
part='id',
q=query,
type='video',
maxResults=maxResults,
)
i = 0
while search_request and i < max_pages:
search_response = search_request.execute() # execute()で実際にHTTPリクエストを送信。APIのレスポンスを取得。
video_ids = [item['id']['videoId'] for item in search_response['items']]
videos_response = youtube.videos().list(
part='snippet,statistics',
id=','.join(video_ids)
).execute()
yield videos_response['items']
search_request = youtube.search().list_next(search_request, search_response)
i += 1
def save_to_mongodb(collection, items):
"""
MongoDBにアイテムのリストを保存
"""
for item in items:
item['_id'] = item['id']
for key, value in item['statistics'].items():
item['statistics'][key] = int(value)
result = collection.insert_many(items) # コレクションに挿入
print('Inserted {0} documents'.format(len(result.inserted_ids)), file=sys.stderr)
if __name__ == '__main__':
main()
2. 保存したデータをMongoDBから取り出し、整形してcsvに書き出す
csvファイルで保存しておけば、非エンジニアの方もExcelでソート等の分析ができて便利ですよね。
※Excelで普通に開くと文字化けします。以下サイトの手順で開きましょう。
「Excelで開くと文字化けするUTF-8のCSVを文字コードを変換せずに開く方法」
import csv
mongo_client = MongoClient('localhost', 27017)
db = mongo_client.kaguya
collection = db.luna # kaguyaデータベース -> lunaコレクション
# 列名(1行目)を作成
## [タイトル、URL、チャンネル名、公開日、視聴回数、Like数、Dislike数、コメント数(一部不正確?)、favorite数(不明)]
col_name = ['title', 'url', 'channelTitle', 'publishedAt']
statistics_keys = ['viewCount', 'likeCount', 'dislikeCount', 'commentCount', 'favoriteCount']
col_name.extend(statistics_keys)
sort_key = 'statistics.likeCount' # ひとまずLikeが多い順に保存
with open('youtube_result.csv', 'w', newline='', encoding='utf-8') as output_csv:
csv_writer = csv.writer(output_csv)
csv_writer.writerow(col_name) # 列名を記入
# データを整形しつつcsvに書き込んでいく
for item in collection.find().sort(sort_key, DESCENDING):
url = 'https://www.youtube.com/watch?v=' + item['_id']
row_items = [item['snippet']['title'], url, item['snippet']['channelTitle'], item['snippet']['publishedAt']]
# 値が入っていない部分を埋めるために統計量についてfor文を回す
for statistics_key in statistics_keys:
item['statistics'].setdefault(statistics_key, 0)
row_items.append(item['statistics'][statistics_key]) # 列名と同じ順番になるようにstatistics_keysでfor文を回す
csv_writer.writerow(row_items)
ちなみに、MongoDBのコレクションを利用すると「輝夜月の公式動画」のみを抽出することも可能です。
# 輝夜月の公式動画のみ抽出
# 視聴回数順にソートして表示
for item in collection.find({'snippet.channelTitle': 'Kaguya Luna Official'}).sort('statistics.viewCount', DESCENDING):
print(item['statistics']['viewCount'], item['snippet']['channelTitle'], item['snippet']['title'])
出力結果の一部がこちら
初期のころの動画の再生数が多いですね。1
3078789 Kaguya Luna Official 【Getting Over It】月ちゃんおこだよ!!!!!おこ
2949664 Kaguya Luna Official 【自己紹介】輝夜 月の特技がスゴイ!!!!
2677585 Kaguya Luna Official 必殺!あいさつきめてみたっス!!!!!!!!!!!!!!!!!!
2469026 Kaguya Luna Official 老化防止対策してないとかマ?!
……
3. csvをpandasで読み込んでデータを分析
import pandas as pd
# csvファイルを読み込む
df = pd.read_csv('youtube_result.csv')
# 「活発度」列を作る
## 再生数に対してどれだけのコメントが集まっているか
df['活発度'] = df['commentCount'] / df['viewCount']
# 「好感度」列を作る
## 再生数に対してどれだけLikeが集まっているか
df['好感度'] = df['likeCount'] / df['viewCount']
「活発度」 = 「コメント数」 / 「視聴回数」
「好感度」 = 「Like評価数」 / 「視聴回数」
としてみました。
視聴回数が多いほどコメントやLike評価も集まりやすいと考えられるため、より公平に比較できるように視聴回数で割ってみます。
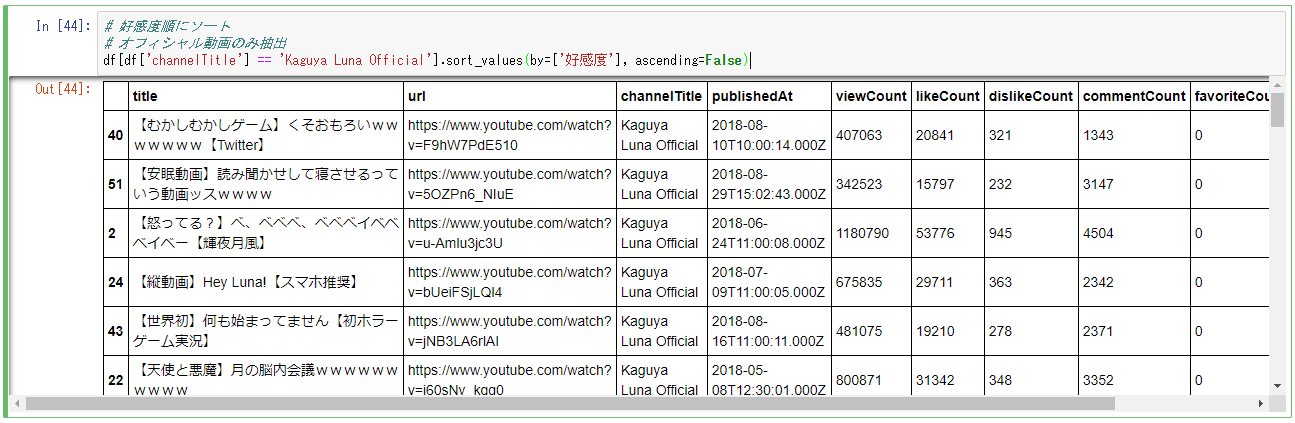
# 好感度順にソート
# オフィシャル動画のみ抽出
# Jupyter Notebook上で実行すると見やすいです
df[df['channelTitle'] == 'Kaguya Luna Official'].sort_values(by=['好感度'], ascending=False)
結果は以下のようなものとなりました(ぜひご自身で実行してみてください)。
比較的新しくて再生数がまだ少なめな動画ほど好感度が高い傾向にあるようですね。
好感度指標、使い勝手が微妙ですね……。
このように、pandasを使えば他にもいろいろな分析が可能です。
1度MongoDBやcsvに保存しているので、何度もYouTubeにアクセスする必要がなく、相手方への負荷も抑えられます。
がんばれば、いろいろおもしろいことが見えてきそうですね!
まとめ
APIを使うとこんなに手軽に情報を取ってくることができるのか……と驚きです。
バーチャルyoutuberが一般社会に広まりつつある今、ブームに乗り遅れないようにしたいもの。
しかし、今やVtuber戦国時代。動画全てを観てはいられません。
今回作ったコードを活用して、主要な動画をおさえていきましょう。
参考
コードは主に以下を参考にさせていただきました。
- 『Pythonクローリング&スクレイピング―データ収集・解析のための実践開発ガイド―』技術評論社
-
『退屈なことはPythonにやらせよう――ノンプログラマーにもできる自動化処理プログラミング』O'Reilly Japan
- csvの書き込みで参考にしました。
GitHub
JupyterNotebookをGitHub上で公開しています。
https://github.com/kokokocococo555/youtube-api-demo
課題
- MongoDBを利用する部分で
BulkWriteError: batch op errors occurredというエラーが出ることがある(途中まではデータベースに保存されている)- 動画が存在しない部分まで検索対象としていると出ることがある
- 対象数を減らせば問題なく完了することもあれば、それでもなおエラーが出ることも
- 対策不明。PCを再起動するとエラーが出ないこともある
- 誰でも使えるくらいの汎用性を持たせたい
- 今はAnacondaやMongoDB等の環境構築が大変で、そこそこできる人しか使えない
注意
Webスクレイピングでは著作権等で気をつけるべきことがあります。
以下記事を参考に、ルール・マナーを意識しておきましょう。
関連記事【スクレイピング・自動化】
-
基本的なスクレイピング(
BeautifulSoup4) -
APIを利用したスクレイピング・データベースへの保存(
MongoDB)・データ分析の一歩(pandas) -
JavaScriptを用いたサイトのスクレイピング(
Selenium,PhantomJS) -
メール通知(
smtplib)・定期的なプログラムの自動実行(タスクスケジューラ) -
自動ログイン(
Selenium,ChromeDriver)
-
私もこのころはまだ観てました…。新時代の到来を感じてめっちゃ興奮していたのを覚えています。 ↩