はじめに
最近自然言語処理の勉強をしていた際に
「自分用にコーパスデータを用意したいな」
と思い立ち、せっかくなので「小説家になろう」からテキストをスクレイピングしくることにしました。
小説家になろう、最近なぜか突然ハマってしまったのです……。
自然言語処理に限らず、機械学習の勉強や実践では「入力データをどう用意しよう問題」があるのではないかと考えています。
せっかく機械学習に興味を持っても、おもしろそうなデータが手元に無いために実践する気を失ってしまうケースも多いのではないでしょうか。
そこで、本記事がスクレイピングの参考になるだけでなく、初学者の方の自然言語処理への挑戦を手助けできれば良いなと思います。
何ができるのか
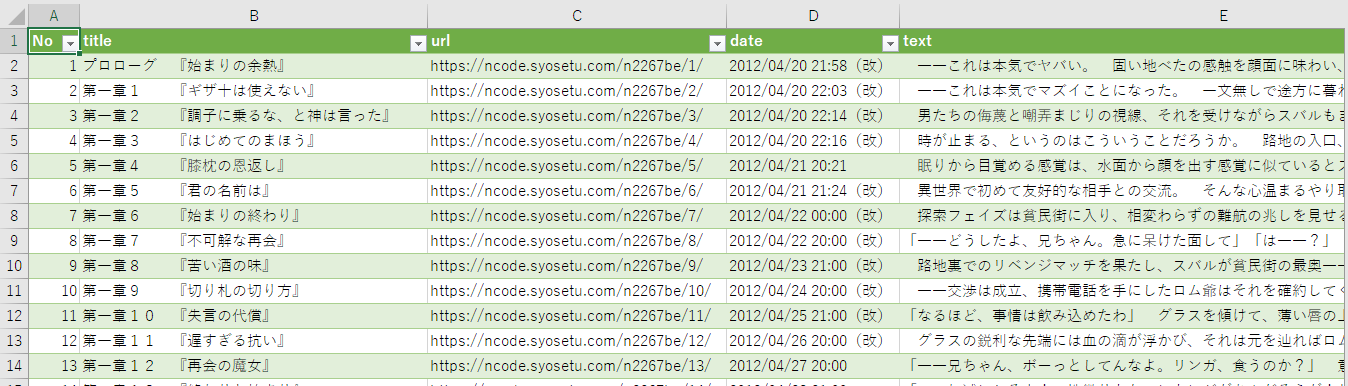
「小説家になろう」において複数作品を指定し、各作品ごとに
- 話数
- タイトル
- URL
- 公開日
- 本文
をcsv形式で保存できます。

環境
- Windows10
- Python3.5
- Jupyter notebookを使用
方針
- Python3でBeautifulSoupを使用
- 1作品まるごとスクレイピング
- 各話のタイトル、更新日時、URLといった情報も含め、各作品ごとにcsvファイルで保存1
注意
Webスクレイピングでは著作権等で気をつけるべきことがあります。
以下記事等を参考に、ルール・マナーを意識しておきましょう。
コード
※2018-08-07時点でスクレイピング可能なのを確認しました。
0. logのためのおまじない
参考:ログ出力のための print と import logging はやめてほしい - Qiita
from logging import getLogger, StreamHandler, DEBUG
logger = getLogger(__name__)
handler = StreamHandler()
handler.setLevel(DEBUG)
logger.setLevel(DEBUG)
logger.addHandler(handler)
logger.propagate = False
1. モジュールのインポート
import os
import time
import datetime
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
2. メイン処理
スクレイピングする作品をURLで指定します。
「ランキング一覧」から順にスクレイピング、なども可能です(後述します)。
def main():
"""
メイン処理
"""
# --------------------------------------
# 作品ページのURLを指定(コメントアウト・コメントインで指定できるようにしています)
url_list = [
"https://ncode.syosetu.com/n2267be/" # Re:ゼロから始める異世界生活
,
"https://ncode.syosetu.com/n6316bn/" # 転生したらスライムだった件
# ,
# "https://ncode.syosetu.com/n2031cu/" # 異世界転移で女神様から祝福を! ~いえ、手持ちの異能があるので結構です~
# ,
# "https://ncode.syosetu.com/n3009bk/" # 盾の勇者の成り上がり
# ,
# "https://ncode.syosetu.com/n6475db/" # 私、能力は平均値でって言ったよね!
# ,
# "https://ncode.syosetu.com/n5881cl/" # 賢者の孫
]
# --------------------------------------
# 各作品について処理
for url in url_list:
stories = []
bs_obj = make_bs_obj(url)
time.sleep(3)
url_list = ["https://ncode.syosetu.com" + a_bs_obj.find("a").attrs["href"] for a_bs_obj in bs_obj.findAll("dl", {"class": "novel_sublist2"})]
date_list = bs_obj.findAll("dt",{"class":"long_update"})
novel_title = bs_obj.find("p",{"class":"novel_title"}).get_text()
for s in r'\/*?"<>:|':
novel_title = novel_title.replace(s, '')
# 各話の本文情報を取得
for j in range(len(url_list)):
url = url_list[j]
bs_obj = make_bs_obj(url)
time.sleep(3)
stories.append({
"No": j+1,
"title": bs_obj.find("p", {"class": "novel_subtitle"}).get_text(),
"url": url,
"date": date_list[j].get_text(),
"text": get_main_text(bs_obj),
})
save_as_csv(stories, novel_title)
3. BeautifulSoupObjectを作成
何度も同じ処理を書きたくないので、URLにアクセスし、BeautifulSoupオブジェクトを作成する処理を関数化します。
def make_bs_obj(url):
"""
BeautifulSoupObjectを作成
"""
html = urlopen(url)
logger.debug('access {} ...'.format(url))
return BeautifulSoup(html,"html.parser")
4. 各話のコンテンツをスクレイピング
各話ページのBeautifulSoupObjectを使用し、コンテンツをスクレイピングします。
def get_main_text(bs_obj):
"""
各話のコンテンツをスクレイピング
"""
text = ""
text_htmls = bs_obj.findAll("div",{"id":"novel_honbun"})[0].findAll("p")
for text_html in text_htmls:
text = text + text_html.get_text() + "\n\n"
return text
5. csvファイルに保存
他記事のようにMongoDB等のデータベースに保存するのもよいでしょう。
def save_as_csv(stories, novel_title = ""):
"""
csvファイルにデータを保存
"""
# バックアップファイルの保存先の指定
directory_name = "novels"
# ディレクトリが存在しなければ作成する
if not os.path.exists(directory_name):
os.makedirs(directory_name)
# ファイル名の作成
today = datetime.datetime.now().strftime('%Y-%m-%d_%Hh%Mm')
csv_name = os.path.join(directory_name, '「{}」[{}].csv'.format(novel_title, today))
# 列名(1行目)を作成
col_name = ['No', 'title', 'url', 'date', 'text']
with open(csv_name, 'w', newline='', encoding='utf-8') as output_csv:
csv_writer = csv.writer(output_csv)
csv_writer.writerow(col_name) # 列名を記入
# csvに1行ずつ書き込み
for story in stories:
row_items = [story['No'], story['title'], story['url'], story['date'], story['text']]
csv_writer.writerow(row_items)
print(csv_name, ' saved...')
まとめ
無事、作品ごとにテキストデータを取ってくることができました。
これでようやく好きな作品の特徴を調べたり、作品同士を比較したりできます。
自然言語処理の夢が広がりますね!
今後の課題・ToDo
-
データをデータベースに保存する→ (2018.09.26追記)csvファイルに保存しました。データを辞書型で作成していますので、他記事のようにMongoDBに保存することも可能です。 テキストをどのタイミングでファイルに保存するか検討する-
「小説家になろう」サーバに負荷をかけないように、各話スクレイピングの合間にsleepを入れる- 2018-08-08 対応済
- 段落の設定等を再現できていない
- ルビの扱いを検討する
- 今後の自然言語処理に合わせてテキストの取り出し方等を調整する必要がある
参考
- Mitchell, R. (2015). Web Scraping with Python. O'Reilly.
- (ミッチェル, R. 黒川利明(訳)嶋田健志(技術監修)(2016). PythonによるWebスクレイピング オライリー・ジャパン)
- ログ出力のための print と import logging はやめてほしい - Qiita
- Webスクレイピングの注意事項一覧 - Qiita
- Webスクレイピングの法律周りの話をしよう! - Qiita
GitHub
ソースコードをGitHub上で公開しています。
https://github.com/kokokocococo555/crawling-scraping/tree/master/narouscraping
「ランキング一覧」から順にスクレイピングするコード
main()のurl_listと以下のコードを入れ替えればOKです。
# ランキングページのURL
url = "https://yomou.syosetu.com/rank/isekailist/type/monthly_2/"
bs_obj = make_bs_obj(url)
time.sleep(2)
novels = bs_obj.findAll("div",{"class":"ranking_list"})
novel_ranking = []
for i in range(len(novels)):
novel_ranking.append({
"No": i+1,
"novel_title": novels[i].find("a").get_text(),
"novel_url": novels[i].find("a").attrs["href"],
"novel_point": novels[i].find("span",{"class":"point"}).get_text(),
})
url_list = [novel["novel_url"] for novel in novel_ranking]
関連記事【スクレイピング・自動化】
-
基本的なスクレイピング(
BeautifulSoup4) -
APIを利用したスクレイピング・データベースへの保存(
MongoDB)・データ分析の一歩(pandas) -
JavaScriptを用いたサイトのスクレイピング(
Selenium,PhantomJS) -
メール通知(
smtplib)・定期的なプログラムの自動実行(タスクスケジューラ) -
自動ログイン(
Selenium,ChromeDriver)