概要
Python製のワークフロー管理システムPrefectで簡単なワークフローを作りながら使用方法や幾つかの機能を確認していきたいと思います。
尚、この分野ではApache Airflowがメジャーかと思います。Airflowとの比較についてはこちらのブログ(Why Not Airflow?)に書かれているので参考にして下さい。
Prefectの特徴
- 単発手動実行のワークフローが実装しやすいが、スケジュール実行も普通にできる。
- Pythonの関数を定義していくことでワークフローを自然に構築できる。
- タスク間のデータのやり取りが簡単にできる。
- ワークフロー実行時に動的にワークフローを構成できる。
- ワークフロー上のデータをパラメータ化して実行時に値を指定できる。
- ローカルでのデバッグがしやすい。
- 本番運用はマネージドサービス(Prefect Cloud)を使用した方が良いが、一応自前でホスティングして運用できる。
基本的な使い方
インストール
$ pip install prefect
hello world
Prefectでは、Pythonの関数に@taskデコレータを付けるだけでワークフローのタスクを作ることができます。
また、Flowをコンテキストマネージャとしたwithブロックの中で、通常の関数呼び出しのようにタスクを実行していくだけでワークフローが構築されます。
そして最後にFlowのrun()メソッドを呼ぶことで実際にワークフローが開始されます。
以下は、get_nameとhelloという2つのタスクを作って順番に実行するだけのワークフローとなります。
from prefect import Flow, task
@task
def get_name():
return "world"
@task
def hello(who):
print("hello, {}!".format(who))
with Flow("HelloWorld") as flow:
who = get_name()
hello_world = hello(who)
flow.run()
これを実行すると以下のようにタスクが順番に実行されているのがわかります。
$ python hello_world.py
[2020-11-29 10:47:10+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'HelloWorld'
[2020-11-29 10:47:10+0900] INFO - prefect.TaskRunner | Task 'get_name': Starting task run...
[2020-11-29 10:47:10+0900] INFO - prefect.TaskRunner | Task 'get_name': Finished task run for task with final state: 'Success'
[2020-11-29 10:47:10+0900] INFO - prefect.TaskRunner | Task 'hello': Starting task run...
hello, world!
[2020-11-29 10:47:10+0900] INFO - prefect.TaskRunner | Task 'hello': Finished task run for task with final state: 'Success'
[2020-11-29 10:47:10+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
パラメータ化
タスクで使用する値をFlow実行時にパラメータとして与えることができます。パラメータ化にはParameterクラスを使います。
以下では、パラメータ名nameとしてget_nameの引数をパラメータ化し、Flow実行時にname="koji"としてパラメータの値を指定してFlowを実行しています。
from prefect import Flow, task, Parameter
@task
def get_name(name):
return name
@task
def hello(who):
print("hello, {}!".format(who))
with Flow("HelloWorld") as flow:
name = Parameter("name")
who = get_name(name)
hello_world = hello(who)
flow.run(name="koji")
$ python parameterize.py
[2020-11-29 11:03:19+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'HelloWorld'
[2020-11-29 11:03:19+0900] INFO - prefect.TaskRunner | Task 'name': Starting task run...
[2020-11-29 11:03:19+0900] INFO - prefect.TaskRunner | Task 'name': Finished task run for task with final state: 'Success'
[2020-11-29 11:03:19+0900] INFO - prefect.TaskRunner | Task 'get_name': Starting task run...
[2020-11-29 11:03:19+0900] INFO - prefect.TaskRunner | Task 'get_name': Finished task run for task with final state: 'Success'
[2020-11-29 11:03:19+0900] INFO - prefect.TaskRunner | Task 'hello': Starting task run...
hello, koji!
[2020-11-29 11:03:19+0900] INFO - prefect.TaskRunner | Task 'hello': Finished task run for task with final state: 'Success'
[2020-11-29 11:03:19+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
明示的に依存関係を定義する
タスクの返り値を次のタスクの引数に指定することでタスク間の依存関係を構成してきました。一方、タスク間でデータの受け渡しが無い場合でも依存関係を構成したいときは、下流タスクが依存する上流タスクを明示的に指定してあげる必要があります。
以下のように、task1 -> task2の順に実行したい場合、task2(upstream_tasks=[上流タスクの結果])のようにして下流タスクを呼び出します。
from prefect import task, Flow
@task
def task1():
print("hello")
@task
def task2():
print("world")
with Flow("Dependencies") as flow:
t1 = task1()
task2(upstream_tasks=[t1])
flow.run()
動的にFlowを構成
タスクのmapメソッドを使うことで、実行時に上流タスクから渡された値に応じて動的にタスクを生成してFlowを構成することができます。
mapメソッドには、リストを返すタスクの結果を引数として指定します。そうするとリストの各要素ごとにタスクを実行することになります。
以下は実行ごとにランダムな長さのリストを生成して、リストの値をそれぞれ2乗したものの合計を出力します。ここで、値を2乗するタスクsquaredが生成される数が実行ごとに異なります。
from random import randint
from prefect import task, Flow
@task
def random_list():
return [i for i in range(randint(1, 10))]
@task
def squared(x):
return x ** 2
@task
def sum_up(l):
print(f"Squared results: {l}")
print(f"Sum: {sum(l)}")
with Flow('DynamicFlow') as flow:
l = random_list()
squared_res = squared.map(l)
sum_res = sum_up(squared_res)
flow.run()
尚、mapで実行されるタスクは可能であれば並列実行されるようです。
$ python dynamic_flow.py
[2020-12-02 18:11:53+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'DynamicFlow'
[2020-12-02 18:11:53+0900] INFO - prefect.TaskRunner | Task 'random_list': Starting task run...
[2020-12-02 18:11:53+0900] INFO - prefect.TaskRunner | Task 'random_list': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:53+0900] INFO - prefect.TaskRunner | Task 'squared': Starting task run...
[2020-12-02 18:11:53+0900] INFO - prefect.TaskRunner | Task 'squared': Finished task run for task with final state: 'Mapped'
[2020-12-02 18:11:53+0900] INFO - prefect.TaskRunner | Task 'squared[0]': Starting task run...
[2020-12-02 18:11:53+0900] INFO - prefect.TaskRunner | Task 'squared[0]': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[1]': Starting task run...
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[1]': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[2]': Starting task run...
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[2]': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[3]': Starting task run...
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[3]': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[4]': Starting task run...
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[4]': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[5]': Starting task run...
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'squared[5]': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'sum_up': Starting task run...
Squared results: [0, 1, 4, 9, 16, 25]
Sum: 55
[2020-12-02 18:11:54+0900] INFO - prefect.TaskRunner | Task 'sum_up': Finished task run for task with final state: 'Success'
[2020-12-02 18:11:54+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
条件分岐
Flow実行時の各タスクの結果に応じて実行の流れを制御したい場合、制御フロー構成用の関数を使います。
まず、タスクの返り値がTrueの場合とFalseの場合のそれぞれに応じて実行するタスクを分岐させたい場合はifelseを使います。
from random import randint
from prefect import task, Flow
from prefect.tasks.control_flow.conditional import ifelse
@task
def check_even():
return randint(0, 10) % 2 == 0
@task
def even():
print("It's Even!!")
@task
def odd():
print("It's Odd!!")
with Flow("IfElseFlow") as flow:
cond = check_even()
result = ifelse(cond, even, odd)
flow.run()
$ python ifelse.py
[2020-11-29 11:33:39+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'BranchFlow'
[2020-11-29 11:33:39+0900] INFO - prefect.TaskRunner | Task 'check_even': Starting task run...
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'check_even': Finished task run for task with final state: 'Success'
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'as_bool': Starting task run...
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'as_bool': Finished task run for task with final state: 'Success'
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'CompareValue: "True"': Starting task run...
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | SKIP signal raised: SKIP('Provided value "False" did not match "True"')
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'CompareValue: "True"': Finished task run for task with final state: 'Skipped'
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'CompareValue: "False"': Starting task run...
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'CompareValue: "False"': Finished task run for task with final state: 'Success'
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'even': Starting task run...
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'even': Finished task run for task with final state: 'Skipped'
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'odd': Starting task run...
It's Odd!!
[2020-11-29 11:33:40+0900] INFO - prefect.TaskRunner | Task 'odd': Finished task run for task with final state: 'Success'
[2020-11-29 11:33:40+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
ifelseはTaskの結果がTrue/Falseによって分岐しますが、任意の値によって分岐するswitchも用意されておりswitch(cond, {"結果1": task1, "結果2": task2, "結果3": task3, ...)のように書けます。
また、各分岐先ごとに複数のTaskを指定したい場合はcaseを使ってFlowを定義します。
from prefect import task, Flow, Parameter
from prefect.tasks.control_flow.case import case
@task
def a_or_b_or_c(num):
i = num % 3
return ["a", "b", "c"][i]
@task
def proc_a1():
print("processing a1")
return "a1"
@task
def proc_a2():
print("processing a2")
return "a2"
@task
def proc_b():
print("processing b")
return "b"
@task
def proc_c():
print("processing c")
return "c"
@task
def cleanup(res):
print(f"cleanup {res}")
with Flow("CaseFlow") as flow:
num = Parameter("num")
cond = a_or_b_or_c(num)
with case(cond, "a"):
res_a1 = proc_a1()
res_a2 = proc_a2()
print_a = cleanup([res_a1, res_a2])
with case(cond, "b"):
res_b = proc_b()
print_b = cleanup(res_b)
with case(cond, "c"):
res_c = proc_c()
print_c = cleanup(res_c)
flow.run(num=6)
$ python -i case.py
[2020-12-02 18:48:54+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'CaseFlow'
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'num': Starting task run...
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'num': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'a_or_b_or_c': Starting task run...
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'a_or_b_or_c': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'case(a)': Starting task run...
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'case(a)': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'case(b)': Starting task run...
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | SKIP signal raised: SKIP('Provided value "a" did not match "b"')
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'case(b)': Finished task run for task with final state: 'Skipped'
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'case(c)': Starting task run...
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | SKIP signal raised: SKIP('Provided value "a" did not match "c"')
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'case(c)': Finished task run for task with final state: 'Skipped'
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'proc_a1': Starting task run...
processing a1
[2020-12-02 18:48:54+0900] INFO - prefect.TaskRunner | Task 'proc_a1': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'proc_b': Starting task run...
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'proc_b': Finished task run for task with final state: 'Skipped'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'proc_a2': Starting task run...
processing a2
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'proc_a2': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'cleanup': Starting task run...
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'cleanup': Finished task run for task with final state: 'Skipped'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'List': Starting task run...
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'List': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'proc_c': Starting task run...
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'proc_c': Finished task run for task with final state: 'Skipped'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'cleanup': Starting task run...
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'cleanup': Finished task run for task with final state: 'Skipped'
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'cleanup': Starting task run...
cleanup ['a1', 'a2']
[2020-12-02 18:48:55+0900] INFO - prefect.TaskRunner | Task 'cleanup': Finished task run for task with final state: 'Success'
[2020-12-02 18:48:55+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
Flowの成功・失敗の条件
事前準備 -> 本処理 -> 後片付け のようなワークフローにおいて、本処理が成功するしないに関わらず必ず後片付けを実行してほしいという場合が多いかと思います。そのような場合、後片付けのタスクのトリガー条件を「上流タスクの成功」ではなく「上流タスクの終了(成功・失敗を問わない)」に指定します。タスクのトリガー条件は@task(trigger=トリガー条件)で指定します。以下では、all_finished(依存関係にある全上流タスクが完了した場合)を指定しています。一つでも成功した場合に実行開始するany_successfulなど他にもいくつか条件が使えるので柔軟にフローを制御できると思います。
ここで1つ問題なのが、必ず後片付けのタスクが実行されてしまうということは本処理が失敗してもワークフロー自体が成功ステータスで完了するということです。(後片付けが失敗しない限り)
本来、本処理の成功・失敗だけがワークフローの成功・失敗の条件となってほしいところです。そのようなときは、Flowの成否に関与するタスクをset_reference_tasks()メソッドで指定します。
from prefect import task, Flow, Parameter
from prefect.engine import signals
from prefect.triggers import all_finished
@task
def create_instance():
return "ready"
@task
def maybe_failed(success, ready):
if success: return "finished"
else: raise signals.FAIL(message="Failed!!")
@task(trigger=all_finished)
def cleanup(finished):
print("Clean Up!")
with Flow("WithCleanup") as flow:
success = Parameter("success")
ready = create_instance()
finished = maybe_failed(success, ready)
cleanup(finished)
flow.set_reference_tasks([finished])
flow.run(success=False)
signals.FAILをraiseすることによって、意図的に本処理であるmaybe_failedタスクを失敗させています。
その場合でもcleanupタスクは実行され(そして成功し)、Flow自体は失敗となります。
$ python with_cleanup.py
[2020-11-29 13:27:09+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'WithCleanup'
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'create_instance': Starting task run...
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'create_instance': Finished task run for task with final state: 'Success'
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'success': Starting task run...
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'success': Finished task run for task with final state: 'Success'
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'maybe_failed': Starting task run...
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | FAIL signal raised: FAIL('Failed!!')
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'maybe_failed': Finished task run for task with final state: 'Failed'
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'cleanup': Starting task run...
Clean Up!
[2020-11-29 13:27:09+0900] INFO - prefect.TaskRunner | Task 'cleanup': Finished task run for task with final state: 'Success'
[2020-11-29 13:27:09+0900] INFO - prefect.FlowRunner | Flow run FAILED: some reference tasks failed.
ワークフローの可視化とデバッグ
Flowのグラフを画像ファイルとして出力
関数呼び出しスタイルでワークフローを構築していると全体の流れをグラフ表示して確認したくなります。
そんなときはFlowのvisualize()メソッドでワークフロー全体のグラフを画像ファイルとして出力できます。
出力ファイル形式はPDFやPNG等 Graphvizでサポートされている形式をサポートしています。
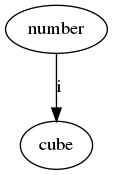
以下Flowのグラフを出力してみます。
from prefect import Flow, task
@task
def number():
return 2
@task
def cube(i):
print(i ** 3)
with Flow("Debug") as flow:
n = number()
cube(n)
ここからはFlowの定義だけで、Flowに対する操作はREPLで行うようにします。
以下を実行するとカレントディレクトリにdebug.pngというPNGファイルが出力されます。
formatを指定しないとデフォルトのPDF形式で出力されます。
$ python -i debug.py
>>> flow.visualize(filename='debug', format='png')
出力されたグラフ
タスクのMock化によるデバッグ
Flowのデバッグをするときは、REPLやJupyter Notebookのようなインタラクティブ環境で試行錯誤したほうが効率が良いです。
REPL上でFlowを実行(run())した後、特定のタスクの完了ステータスや返り値をマニュアルで指定したうえで再実行したりできます。このようにMock化したタスクは実行されずにステータスと返り値を下流に渡すだけなので時間の掛かるタスクをMock化すると効率よくデバッグできます。
また、タスク自体をその場で定義した別のタスクに入れ替えて再実行することもできます。
$ python -i debug.py
# まずは普通に実行
>>> flow.run()
[2020-11-30 12:13:30+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'Debug'
[2020-11-30 12:13:30+0900] INFO - prefect.TaskRunner | Task 'number': Starting task run...
[2020-11-30 12:13:30+0900] INFO - prefect.TaskRunner | Task 'number': Finished task run for task with final state: 'Success'
[2020-11-30 12:13:31+0900] INFO - prefect.TaskRunner | Task 'cube': Starting task run...
8
[2020-11-30 12:13:31+0900] INFO - prefect.TaskRunner | Task 'cube': Finished task run for task with final state: 'Success'
[2020-11-30 12:13:31+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
<Success: "All reference tasks succeeded.">
>>> from prefect.engine.state import Success, Failed
# タスクnumberのインスタンスを取得
>>> target_task = flow.get_tasks(name="number")[0]
# タスクnumberを完了ステータスSuccess、返り値10としてMock化して再実行
>>> dummy_states = {target_task: Success("Dummy Success", 10)}
>>> flow.run(task_states=dummy_states)
[2020-11-30 12:15:05+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'Debug'
[2020-11-30 12:15:05+0900] INFO - prefect.TaskRunner | Task 'cube': Starting task run...
1000
[2020-11-30 12:15:05+0900] INFO - prefect.TaskRunner | Task 'cube': Finished task run for task with final state: 'Success'
[2020-11-30 12:15:05+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
<Success: "All reference tasks succeeded.">
# タスクnumberを完了ステータスFailed、返り値10としてMock化して再実行
>>> dummy_states = {target_task: Failed("Dummy Failed", 10)}
>>> flow.run(task_states=dummy_states)
[2020-11-30 12:15:28+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'Debug'
[2020-11-30 12:15:28+0900] INFO - prefect.TaskRunner | Task 'cube': Starting task run...
[2020-11-30 12:15:28+0900] INFO - prefect.TaskRunner | Task 'cube': Finished task run for task with final state: 'TriggerFailed'
[2020-11-30 12:15:28+0900] INFO - prefect.FlowRunner | Flow run FAILED: some reference tasks failed.
<Failed: "Some reference tasks failed.">
# numberタスクを新たに作成するfixed_numberタスクに入れ替えて再実行する
>>> @task
... def fixed_number(): return 5
...
>>> flow.replace(target_task, fixed_number)
>>> flow.run()
[2020-11-30 12:16:50+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'Debug'
[2020-11-30 12:16:50+0900] INFO - prefect.TaskRunner | Task 'fixed_number': Starting task run...
[2020-11-30 12:16:50+0900] INFO - prefect.TaskRunner | Task 'fixed_number': Finished task run for task with final state: 'Success'
[2020-11-30 12:16:50+0900] INFO - prefect.TaskRunner | Task 'cube': Starting task run...
125
[2020-11-30 12:16:50+0900] INFO - prefect.TaskRunner | Task 'cube': Finished task run for task with final state: 'Success'
[2020-11-30 12:16:50+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
<Success: "All reference tasks succeeded.">
簡単なワークフローを組んでみる
以下のようなGCPと連携するタスクから構成されるワークフローをローカルで実装してみます。
- EmbulkでGCSバケット上のCSVファイルをBigQueryにロードする。
- ロードされたデータに対してBigQueryのクエリを実行して新たなテーブルを作成する。
今回テスト用のサンプルデータとしてBigQuery Public Dataのaustin_bikeshareのデータセットを使います。
このデータセットはbikeshare_trips(トランザクション)とbikeshare_stations(マスタ)の2つのテーブルがあるので、これらをCSVファイルとしてGCS上に保存した上で、上記2ステップのワークフローを実行してみます。
GCP環境等 準備
GCPプロジェクトをmy-prefect-labとして作成してサービスアカウントやGCS、BigQueryの環境を準備します。
# GCPへのアクセスで使用するサービスアカウントを作成して必要なロールを割当てる
gcloud iam service-accounts create prefect-admin --display-name="prefect-admin"
gcloud projects add-iam-policy-binding my-prefect-lab \
--member="serviceAccount:prefect-admin@my-prefect-lab.iam.gserviceaccount.com" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding my-prefect-lab \
--member="serviceAccount:prefect-admin@my-prefect-lab.iam.gserviceaccount.com" \
--role="roles/bigquery.dataOwner"
gcloud projects add-iam-policy-binding my-prefect-lab \
--member="serviceAccount:prefect-admin@my-prefect-lab.iam.gserviceaccount.com" \
--role="roles/bigquery.jobUser"
# サービスアカウントのクレデンシャルをkey.jsonとして保存しておく
gcloud iam service-accounts keys create ./key.json \
--iam-account prefect-admin@my-prefect-lab.iam.gserviceaccount.com
# ロード対象データを保存するGCSバケットを作成
gsutil mb gs://my-prefect-lab-bucket
# ロード先のBigQueryデータセットを作成
bq mk --dataset my-prefect-lab:etl_data
今回使用するデータをGCSのバケットに保存しておく。
bq extract \
--destination_format CSV \
--compression GZIP \
--field_delimiter ',' \
--print_header=true \
bigquery-public-data:austin_bikeshare.bikeshare_trips \
gs://my-prefect-lab-bucket/20201130/bikeshare_trips.gz
bq extract \
--destination_format CSV \
--compression GZIP \
--field_delimiter ',' \
--print_header=true \
bigquery-public-data:austin_bikeshare.bikeshare_stations \
gs://my-prefect-lab-bucket/20201130/bikeshare_stations.gz
GCSからBigQueryへロードするためのEmbulkコンフィグを用意しておきます。(ロード対象ファイルごとにコンフィグファイルを作成)
今回は環境変数$DATEを使って実行日付(YYYYmmdd)をGCSのパスやBigQueryテーブル名に埋め込んでいます。
in:
type: gcs
bucket: my-prefect-lab-bucket
path_prefix: {{ env.DATE }}/bikeshare_trips
auth_method: json_key
json_keyfile: ./key.json
decoders:
- {type: gzip}
parser:
type: csv
newline: LF
charset: UTF-8
delimiter: ','
quote: '"'
escape: '"'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: trip_id, type: long}
- {name: subscriber_type, type: string}
- {name: bikeid, type: string}
- {name: start_time, type: timestamp, format: '%Y-%m-%d %H:%M:%S UTC'}
- {name: start_station_id, type: long}
- {name: start_station_name, type: string}
- {name: end_station_id, type: string}
- {name: end_station_name, type: string}
- {name: duration_minutes, type: long}
out:
type: bigquery
auth_method: json_key
json_keyfile: ./key.json
mode: replace
project: my-prefect-lab
dataset: etl_data
table: bikeshare_trips_{{ env.DATE }}
in:
type: gcs
bucket: my-prefect-lab-bucket
path_prefix: {{ env.DATE }}/bikeshare_stations
auth_method: json_key
json_keyfile: ./key.json
decoders:
- {type: gzip}
parser:
type: csv
newline: LF
charset: UTF-8
delimiter: ','
quote: '"'
escape: '"'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: station_id, type: long}
- {name: name, type: string}
- {name: status, type: string}
- {name: latitude, type: double}
- {name: longitude, type: double}
- {name: location, type: string}
out:
type: bigquery
auth_method: json_key
json_keyfile: ./key.json
mode: replace
project: my-prefect-lab
dataset: etl_data
table: bikeshare_stations_{{ env.DATE }}
PrefectのBigQueryタスクも使うので追加でインストールしておきます。
$ pip install prefect[gcp]
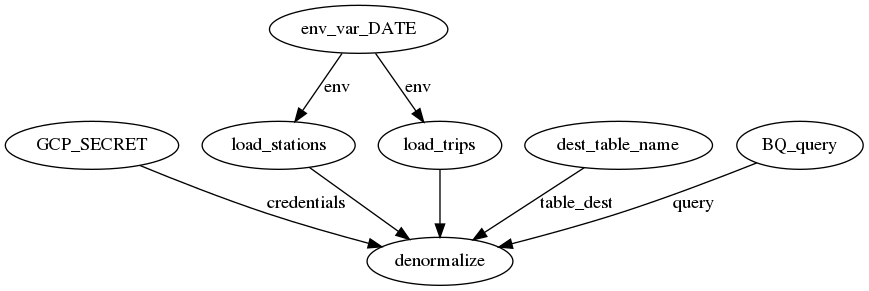
ワークフローの実装
今回のワークフローでは、最初のGCSからBigQueryへのロードはShellTaskを使ってshellでEmbulkを実行します。その後のBigQueryでのクエリの実行(2つのテーブルをjoinしてテーブル生成)ではBigQueryTaskを実行します。
Embulkで使う環境変数$DATEの値やBigQueryのクエリで使う日付(いずれもYYYYmmdd形式)は、prefect.contextというオブジェクトのtoday_nodash(Prefectが設定する'-'無しのFlow実行日付)から取得します。
また、BigQueryへのクエリ実行で使うクレデンシャルは環境変数$GCP_SECRETから取得するようにします。
import json
import prefect
from prefect import Flow, task
from prefect.tasks.shell import ShellTask
from prefect.tasks.secrets.env_var import EnvVarSecret
from prefect.tasks.gcp.bigquery import BigQueryTask
load_stations = ShellTask(
name="load_stations",
command="embulk run bikeshare_stations.yml.liquid && echo bikeshare_stations_${DATE}"
)
load_trips = ShellTask(
name="load_trips",
command="embulk run bikeshare_trips.yml.liquid && echo bikeshare_trips_${DATE}"
)
gcp_secret = EnvVarSecret(
name="GCP_SECRET",
cast=lambda s: json.loads(s)
)
denormalize = BigQueryTask(
name="denormalize",
project="my-prefect-lab",
dataset_dest="etl_data"
)
@task(name="env_var_DATE")
def get_env_vars():
return {'DATE': prefect.context.today_nodash}
@task(name="BQ_query")
def denormalize_query():
return f"""
SELECT
trips.*,
start_stations.latitude AS start_latitude,
start_stations.longitude AS start_longitude,
end_stations.latitude AS end_latitude,
end_stations.longitude AS end_longitude
FROM
`my-prefect-lab.etl_data.bikeshare_trips_{prefect.context.today_nodash}` AS trips
INNER JOIN
`my-prefect-lab.etl_data.bikeshare_stations_{prefect.context.today_nodash}` AS start_stations
ON
trips.start_station_id = start_stations.station_id
INNER JOIN
`my-prefect-lab.etl_data.bikeshare_stations_{prefect.context.today_nodash}` AS end_stations
ON
SAFE_CAST(trips.end_station_id AS INT64) = end_stations.station_id
"""
@task(name="dest_table_name")
def get_dest_table_name():
return f"denormalized_{prefect.context.today_nodash}"
with Flow("local-etl") as flow:
env = get_env_vars()
stations = load_stations(env=env)
trips = load_trips(env=env)
query = denormalize_query()
credentials = gcp_secret()
table_dest = get_dest_table_name()
denormalize(
query=query,
table_dest=table_dest,
credentials=credentials,
flow=flow,
upstream_tasks=[stations, trips]
)
このフローをflow.visualizeでグラフにしてみると以下のようになります。
BigQueryのクエリ実行には、先程作成したService Accountのクレデンシャル(key.json)を使うので環境変数GCP_SECRETに設定したうえで実行します。
$ export GCP_SECRET=$(cat key.json)
$ python -i local_etl.py
>>> flow.run()
実行が成功するとBigQuery上にmy-prefect-lab.etl_data.denormalized_YYYYmmdd(YYYYmmddは実行日付)というテーブルができているかと思います。
Prefect Server
ここまでは、PrefectをPythonライブラリとして実行していましたが、Flowをサーバに登録して実行管理をすることもできます。チームでワークフローを管理したりスケジュール実行したりする場合に便利です。また、Web UIも備えており、GUIを使ってFlowを実行したりリアルタイムでFlowの実行状況やログなどを確認できます。
ローカルにPrefect Serverを立てて先のlocal_etl.pyのFlowを登録・実行してみます。
pipでPrefectをインストールしている場合prefectコマンドが使えるようになっているのでこれを使っていきます。(Dockerもインストールされている必要があります。)
# Local Server実行の為のコンフィグを~/.prefect/backend.tomlへ設定する
$ prefect backend server
# Prefect Server群を起動する
$ prefect server start
# 実際にFlowを実行するLocal Agentを起動する(BigQueryアクセスに使う環境変数を設定して実行)
$ GCP_SECRET=$(cat key.json) prefect agent local start
Prefectプロジェクトを作成する。
$ prefect create project first_project
Prefect ServerにFlowを登録する。
$ prefect register flow --file local_etl.py --name local-etl --project first_project
登録したFlowを実行する。
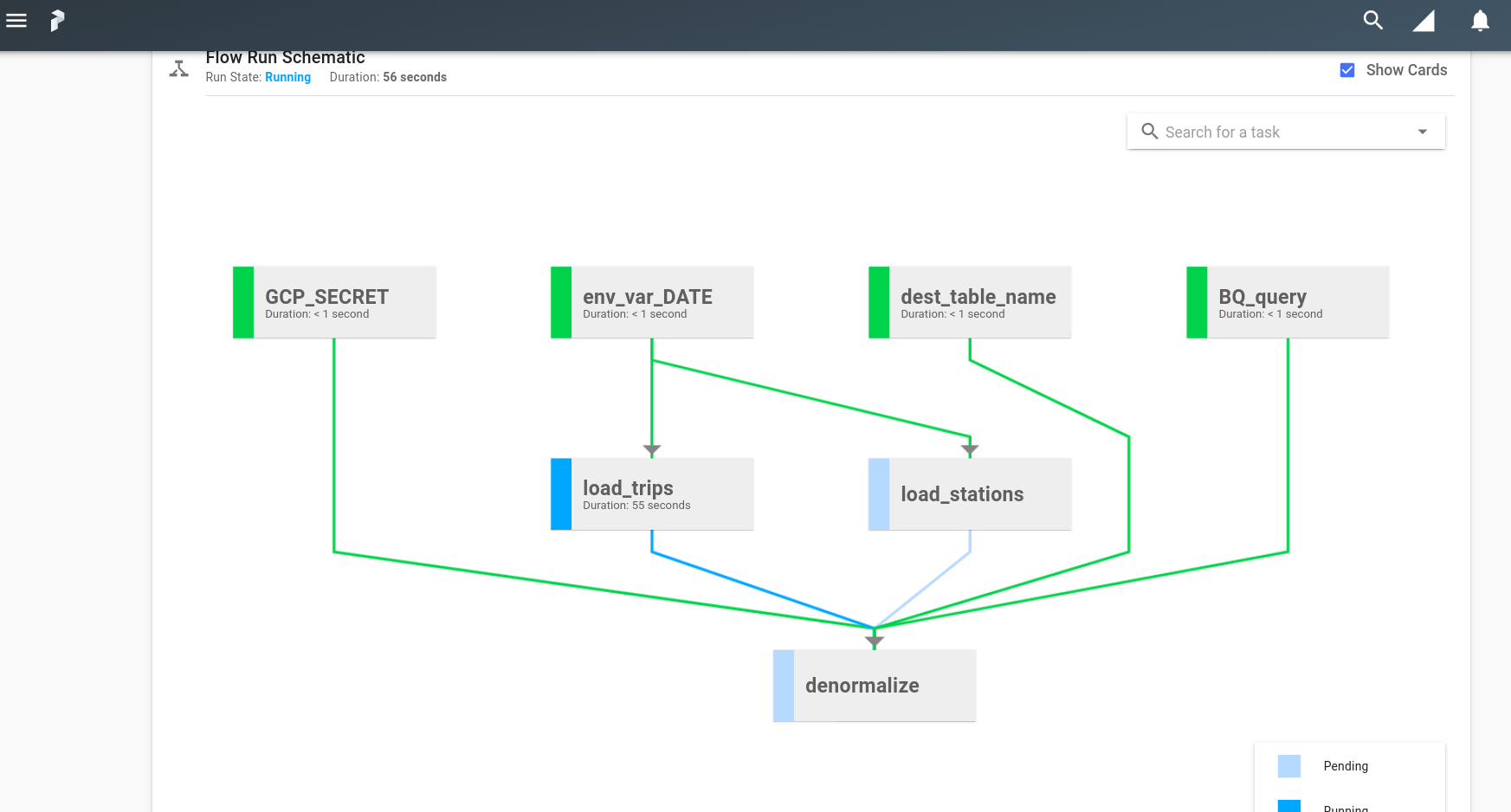
$ prefect run flow --name local-etl --project first_project --watch
Flow Run: http://localhost:8080/flow-run/93dfbdcc-a7bd-42ce-aa0d-9dc5fcc52909
Pending -> Scheduled -> Submitted -> Running -> Success
コマンド実行後に表示されるURL(http://localhost:8080/flow-run/... )にWebブラウザでアクセスすることで進行状況をリアルタイムで確認することができます。
ちなみに、Prefect Serverは複数のサーバ(WebUI, GraphQL, API, RDBMS等)で構成されています。先のコマンドではDocker Composeでローカルに全サーバを稼働させています。
現在(2020年12月)時点で、公式のデプロイ環境としては上記Docker Composeによるシングルノード環境かマネージドサービス(Prefect Cloud)しかないようです。
本番運用をしたいのであればPrefect Cloudを使うのが良いと思います。(特にOSS版はWeb UIのユーザ認証機能や秘匿情報管理機能が無いので)
ただ、シングルノード環境用のdocker-compose.yamlを参考にすればk8s環境にもデプロイできます。
スケジュール実行について
Flow作成時に引数としてscheduleを指定すると、スケジュール実行が可能となります。
例えば、Flowを登録したタイミングから一日1回実行したい場合は以下のように指定します。
schedule = IntervalSchedule(interval=timedelta(days=1))
with Flow('scheduled-flow', schedule=schedule) as flow:
# flow definition
スケジューリングはこのFlowをregister()したタイミングから開始します。この場合だとregister()した日の次の日の同じ時間に実行が開始します。
scheduleには他にも色々なスケジューリング方法が用意されています。
また、prefect.context.todayなどの日付を参照してスケジュール実行するFlowにおいて、過去の日付に遡ってFlowを実行(backfill)したい場合、以下のようにprefect.contextの値を変更してFlowを実行することで実現できます。
>>> from datetime import date, timedelta
# 今日から5日分前までを実行する
>>> for d in range(5):
... with prefect.context(today=str(date.today() - timedelta(days=d))):
... flow.run(context=prefect.context)
ワークフローをk8s上で実行する
ワークフロー構成
Prefectには各種サードパーティサービス向けのタスクが用意されています。
そこで、先程のlocal_etl.pyのFlowにおけるEmbulkの実行をk8sのJobとして実行するように変更してみます。
ワークフローの構成は、Embulk実行をShellTaskからk8s Jobタスク(prefect.tasks.kubernetes.job.RunNamespacedJob)に変更するだけとなります。
尚、タスク実行のためにk8sクラスタを作成するので、ついでにPrefect Serverもk8sにデプロイして使用することにします。今回はGKE上に環境を構築してFlowを実行しました。構成や構築方法は本記事の最後にAppendixとして記載しておきますので環境構築の参考にして頂ければと思います。
Embulkのコンテナイメージを準備
k8sのJobで使用するEmbulk実行用コンテナイメージを作成し、プライベートコンテナレジストリ(今回はGCRを使用)に登録しておきます。
FROM openjdk:8-jdk-stretch
RUN curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar" && \
chmod +x ~/.embulk/bin/embulk
RUN ~/.embulk/bin/embulk gem install embulk-input-gcs embulk-output-bigquery
ENV PATH $PATH:/root/.embulk/bin
docker build -t prefect_embulk:latest .
docker tag prefect_embulk gcr.io/my-prefect-lab/embulk:latest
gcloud auth configure-docker
docker push gcr.io/my-prefect-lab/embulk:latest
実装
k8sのJobを実行するprefect.tasks.kubernetes.job.RunNamespacedJobタスクには、スケジュールしたいJobのマニフェストをdictで渡してあげる必要がありますので、別途用意したマニフェストファイル(load_stations_job.yaml等)を読み込んで設定します。また、Embulkコンフィグ内で実行日付として環境変数$DATEを参照しているので、マニフェストのspec.template.spec.containers[].envに{'name': 'DATE', 'value': prefect.context.today_nodash}を設定しています。
import json
import yaml
import prefect
from prefect import Flow, task
from prefect.tasks.kubernetes.job import RunNamespacedJob
from prefect.tasks.secrets.env_var import EnvVarSecret
from prefect.tasks.gcp.bigquery import BigQueryTask
from prefect.environments import KubernetesJobEnvironment
from prefect.environments.storage import GCS
load_stations = RunNamespacedJob(
name="load_stations",
namespace="default",
kubernetes_api_key_secret=None
)
load_trips = RunNamespacedJob(
name="load_trips",
namespace="default",
kubernetes_api_key_secret=None
)
gcp_secret = EnvVarSecret(
name="GCP_SECRET",
cast=lambda s: json.loads(s)
)
denormalize = BigQueryTask(
name="denormalize",
project="my-prefect-lab",
dataset_dest="etl_data"
)
stations_conf = yaml.load(open(f"./load_stations_job.yaml", "r"), Loader=yaml.FullLoader)
trips_conf = yaml.load(open(f"./load_trips_job.yaml", "r"), Loader=yaml.FullLoader)
@task
def stations_k8s_config():
stations_conf['spec']['template']['spec']['containers'][0]['env'] = [{'name': 'DATE', 'value': prefect.context.today_nodash}]
return stations_conf
@task
def trips_k8s_config():
trips_conf['spec']['template']['spec']['containers'][0]['env'] = [{'name': 'DATE', 'value': prefect.context.today_nodash}]
return trips_conf
@task(name="BQ_query")
def denormalize_query():
return f"""
SELECT
trips.*,
start_stations.latitude AS start_latitude,
start_stations.longitude AS start_longitude,
end_stations.latitude AS end_latitude,
end_stations.longitude AS end_longitude
FROM
`my-prefect-lab.etl_data.bikeshare_trips_{prefect.context.today_nodash}` AS trips
INNER JOIN
`my-prefect-lab.etl_data.bikeshare_stations_{prefect.context.today_nodash}` AS start_stations
ON
trips.start_station_id = start_stations.station_id
INNER JOIN
`my-prefect-lab.etl_data.bikeshare_stations_{prefect.context.today_nodash}` AS end_stations
ON
SAFE_CAST(trips.end_station_id AS INT64) = end_stations.station_id
"""
@task(name="dest_table_name")
def get_dest_table_name():
return f"denormalized_{prefect.context.today_nodash}"
k8s = KubernetesJobEnvironment(
job_spec_file="/app/job_spec.yaml",
metadata={"image": "prefecthq/prefect:all_extras"}
)
gcs = GCS(bucket="my-prefect-lab-flows", add_default_labels=False)
with Flow("k8s-etl", environment=k8s, storage=gcs) as flow:
stations_job = stations_k8s_config()
trips_job = trips_k8s_config()
stations = load_stations(body=stations_job)
trips = load_trips(body=trips_job)
query = denormalize_query()
credentials = gcp_secret()
table_dest = get_dest_table_name()
denormalize(
query=query,
table_dest=table_dest,
credentials=credentials,
flow=flow,
upstream_tasks=[stations, trips]
)
Flow作成時の引数にenvironmentとstorageを指定しています。
storageはFlowがpickle化されて保存されるストレージを指定します。ローカルサーバ実行環境でFlowをregisterしていた時はデフォルトで~/.prefect/flow配下にFlowのpickleが保存され、実行時はローカルで稼働しているエージェントがそのpickleを取得して実行していました。今回はエージェントもk8sのPODとして稼働させているので、GKEからアクセスしやすいGCS上にFlowを保存するようにしています。
environmentはFlowを実際に実行する環境を定義するもので、今回指定しているKubernetesJobEnvironmentは引数のjob_spec_fileに指定したマニフェストに定義されているJobとしてFlowが実行されることになります。そのため、実行時に必要な環境変数$GCP_SECRETはこちらに定義しておきます。Jobで使用するコンテナイメージはKubernetesJobEnvironment作成時の引数metadataで指定しています。
apiVersion: batch/v1
kind: Job
metadata:
name: my-prefect-job
labels:
identifier: ""
spec:
template:
metadata:
labels:
identifier: ""
spec:
restartPolicy: Never
containers:
- name: flow-container
image: ""
command: []
args: []
env:
- name: GCP_SECRET
value: ""
$GCP_SECRETの値(key.json)はyqコマンドで埋め込んでおきます。
$ yq write job_spec.yaml spec.template.spec.containers[0].env[0].value "$(cat key.json | tr -d '\n')" -i
RunNamespacedJobタスクで実行されるJobのマニフェストも作成しておきます。embulk run実行時に使うEmbulkコンフィグ(bikeshare_statoins.yml.liquid)はk8sのConfigMapとして事前に登録したものをマウントするようにします。GCPのクレデンシャル(key.json)もk8sのSecretとして事前に登録したものをマウントします。
apiVersion: batch/v1
kind: Job
metadata:
name: load-stations-job
spec:
completions: 1
parallelism: 1
backoffLimit: 5
template:
spec:
containers:
- name: embulk-container
image: gcr.io/my-prefect-lab/embulk:latest
command: ["sh", "-c"]
args: ["embulk run /config/bikeshare_stations.yml.liquid"]
volumeMounts:
- name: config-volume
mountPath: /config
- name: secret-volume
mountPath: /secret
volumes:
- name: config-volume
configMap:
name: embulk-config
items:
- key: bikeshare_stations.yml.liquid
path: bikeshare_stations.yml.liquid
- name: secret-volume
secret:
secretName: gcp-credentials
items:
- key: key.json
path: key.json
restartPolicy: Never
load_trips_job.yamlも同様に作成します。
Embulkコンフィグをk8sのConfigMapへ、GCPクレデンシャルをk8sのSecretへ登録しておきます。
$ kubectl create configmap --save-config embulk-config --from-file=./bikeshare_stations.yml.liquid --from-file=./bikeshare_trips.yml.liquid
$ kubectl create secret generic --save-config gcp-credentials --from-file=./key.json
最後に、prefectコマンドを実行するホスト側の~/.prefect/backend.tomlに、Flowの登録・実行をリクエストするAPIサーバのURLを設定しておきます。APIサーバはGraphQLのクエリのエンドポイントを提供しているApolloとなります。今回はApolloをGAEにデプロイしてURLはhttps://apollo-dot-my-prefect-lab.uc.r.appspot.comでアクセスできるようにしました。
backend = "server"
[server]
host = "https://apollo-dot-my-prefect-lab.uc.r.appspot.com"
endpoint = "${server.host}"
[cloud]
api = "${${backend}.endpoint}"
graphql = "${cloud.api}/graphql"
準備が整ったのでFlowを登録して実行してみます。
# Prefectプロジェクトを作成する
$ prefect create project k8s_project
# Flowを登録する
$ docker run -it --rm -v $(pwd):/app -v $HOME/.prefect:/root/.prefect -e GOOGLE_APPLICATION_CREDENTIALS=/app/key.json -w /app prefecthq/prefect:all_extras prefect register flow --file k8s_etl.py --name k8s-etl --project k8s_project
# 登録したFlowを実行する
$ prefect run flow --name k8s-etl --project k8s_project --watch
Flowの登録をDockerコンテナprefecthq/prefect:all_extras上で実行している理由は、Flowの実行環境と同じ環境でFlowをpickle化するためです。(PythonやPrefectのバージョンが異なるとFlowのrun()でエラーになります。)
以上で、k8s上でのFlow実行ができました。
ここまで見てきたように、PrefectはPythonライブラリとして使うことで小さめのワークフローをすぐに実装・実行できるというお手軽さもありながら、
クラウドサービスと連携したりスケジュール実行したりといった本格的な使い方もできるので今後も動向を追っていきたいと思います。
Appendix: Prefectをk8sへデプロイする手順
今回以下の様な構成でGCP上にPrefect Serverを構成しました。
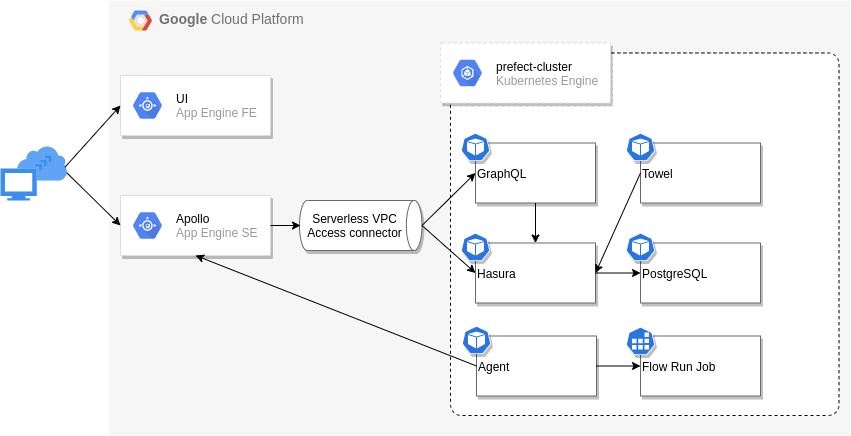
クラスタ名prefect-clusterとしてGKEクラスタを作成し各サーバをデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
labels:
app: postgres
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
initContainers:
- name: remove-lost-found
image: busybox
command: ["sh", "-c"]
args: ["rm -rf /var/lib/postgresql/data/lost+found"]
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgres-data
containers:
- image: postgres:11
name: postgres
ports:
- containerPort: 5432
env:
- name: POSTGRES_USER
value: "prefect"
- name: POSTGRES_PASSWORD
value: "test-password"
- name: POSTGRES_DB
value: "prefect_server"
args:
- -c
- max_connections=150
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgres-data
volumes:
- name: postgres-data
persistentVolumeClaim:
claimName: postgres-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: v1
kind: Service
metadata:
name: postgres-clusterip
spec:
type: ClusterIP
selector:
app: postgres
ports:
- name: "postgres-port"
port: 5432
apiVersion: apps/v1
kind: Deployment
metadata:
name: hasura
labels:
app: hasura
spec:
replicas: 1
selector:
matchLabels:
app: hasura
template:
metadata:
labels:
app: hasura
spec:
containers:
- image: hasura/graphql-engine:v1.3.0
name: hasura
ports:
- containerPort: 3000
env:
- name: HASURA_GRAPHQL_DATABASE_URL
value: "postgresql://prefect:test-password@postgres-clusterip:5432/prefect_server"
- name: HASURA_GRAPHQL_ENABLE_CONSOLE
value: "true"
- name: HASURA_GRAPHQL_SERVER_PORT
value: "3000"
- name: HASURA_GRAPHQL_QUERY_PLAN_CACHE_SIZE
value: "100"
- name: HASURA_GRAPHQL_LOG_LEVEL
value: "warn"
---
apiVersion: v1
kind: Service
metadata:
name: hasura-clusterip
spec:
type: ClusterIP
selector:
app: hasura
ports:
- name: "hasura-port"
port: 3000
---
apiVersion: v1
kind: Service
metadata:
name: hasura-ilb
annotations:
cloud.google.com/load-balancer-type: "Internal"
spec:
type: LoadBalancer
selector:
app: hasura
ports:
- protocol: TCP
port: 3000
targetPort: 3000
apiVersion: apps/v1
kind: Deployment
metadata:
name: graphql
labels:
app: graphql
spec:
replicas: 1
selector:
matchLabels:
app: graphql
template:
metadata:
labels:
app: graphql
spec:
containers:
- image: prefecthq/server:latest
name: graphql
ports:
- containerPort: 4201
command: ["bash", "-c"]
args: ["${PREFECT_SERVER_DB_CMD} && python src/prefect_server/services/graphql/server.py"]
env:
- name: PREFECT_SERVER_DB_CMD
value: "prefect-server database upgrade -y"
- name: PREFECT_SERVER__DATABASE__CONNECTION_URL
value: "postgresql://prefect:test-password@postgres-clusterip:5432/prefect_server"
- name: PREFECT_SERVER__HASURA__ADMIN_SECRET
value: "hasura-secret-admin-secret"
- name: PREFECT_SERVER__HASURA__HOST
value: "hasura-clusterip"
---
apiVersion: v1
kind: Service
metadata:
name: graphql-ilb
annotations:
cloud.google.com/load-balancer-type: "Internal"
spec:
type: LoadBalancer
selector:
app: graphql
ports:
- protocol: TCP
port: 4201
targetPort: 4201
apiVersion: apps/v1
kind: Deployment
metadata:
name: towel
labels:
app: towel
spec:
replicas: 1
selector:
matchLabels:
app: towel
template:
metadata:
labels:
app: towel
spec:
containers:
- image: prefecthq/server:latest
name: towel
command: ["python"]
args: ["src/prefect_server/services/towel/__main__.py"]
env:
- name: PREFECT_SERVER__HASURA__ADMIN_SECRET
value: "hasura-secret-admin-secret"
- name: PREFECT_SERVER__HASURA__HOST
value: "hasura-clusterip"
# GKEクラスタを作成
gcloud container clusters create prefect-cluster \
--zone=us-central1-a \
--enable-ip-alias \
--create-subnetwork name=prefect-subnet,range=10.5.0.0/20 \
--cluster-ipv4-cidr=10.0.0.0/14 \
--services-ipv4-cidr=10.4.0.0/20 \
--scopes=https://www.googleapis.com/auth/devstorage.read_write
# kubectlのcontextを設定
gcloud container clusters get-credentials --zone us-central1-a prefect-cluster
# 各サーバをデプロイ
kubectl apply -f postgres.yaml
kubectl apply -f hasura.yaml
kubectl apply -f graphql.yaml
kubectl apply -f towel.yaml
GAE上のApolloとGKE上のGraphQL、HasuraがVPC内で通信できるようにServerless VPC Access connectorを作成します。
# Serverless VPC accessのAPIを有効にする
gcloud services enable vpcaccess.googleapis.com
# Serverless VPC connectorを作成する
gcloud compute networks vpc-access connectors create prefect-connector \
--network default \
--region us-central1 \
--range 10.8.0.0/28
# 作成したconnectorを確認する
gcloud compute networks vpc-access connectors describe prefect-connector --region us-central1
UIサーバをGAEのFlexible Environmentへデプロイするのに必要なファイルを用意します。
FROM nginx:stable
ENV PREFECT_SERVER__APOLLO_URL=https://apollo-dot-my-prefect-lab.uc.r.appspot.com/graphql
RUN apt-get update && apt-get install jq -y
COPY ./ui/dist /var/www
COPY ./ui/nginx.conf /etc/nginx/conf.d/default.conf
COPY ./ui/start_server.sh /start_server.sh
RUN chmod a+x /start_server.sh
COPY ./ui/intercept.sh /intercept.sh
RUN chmod a+x /intercept.sh
STOPSIGNAL SIGINT
CMD ["/intercept.sh"]
env: flex
runtime: custom
UIサーバをGAEへデプロイします。
$ git clone https://github.com/PrefectHQ/ui.git
$ docker run -it --rm -v $(pwd)/ui:/app -w /app node:10.16.0 bash -c "npm ci && npm run build"
# 上記Dockerfileとapp.yamlを作成してデプロイ
$ gcloud app deploy
ApolloをGAEのStandard Environmentへデプロイするのに必要なファイルを用意します。
GAE SEを使うのはVPC経由でGKEと接続するためのServerless VPC Access connectorをサポートしているためです。
runtime: nodejs10
service: apollo
env_variables:
APOLLO_API_PORT: 8080
HASURA_API_URL: http://10.5.0.5:3000/v1alpha1/graphql
PREFECT_API_URL: http://10.5.0.6:4201/graphql/
PREFECT_API_HEALTH_URL: http://10.5.0.6:4201/health
PREFECT_SERVER__TELEMETRY__ENABLED: true
GRAPHQL_SERVICE_HOST: http://10.5.0.6
GRAPHQL_SERVICE_PORT: 4201
vpc_access_connector:
name: "projects/my-prefect-lab/locations/us-central1/connectors/prefect-connector"
ApolloをGAEにデプロイします。
$ git clone https://github.com/PrefectHQ/server.git
$ cd server/services/apollo
$ docker run -it --rm \
-v $(pwd):/apollo \
-w /apollo \
node:10.15.0-slim \
sh -c "npm ci && npm run build && chmod +x post-start.sh"
# 上記app.yamlを作成してデプロイ
$ gcloud app deploy
PrefectのWeb UIとAPIサーバをインターネットに晒したくないのでとりあえずFirewallでアクセス制御しておきます。Cloud IAPを使ってユーザ認証によるアクセス制御をしたかったのですがAPIサーバでのIAP適用方法がわからず断念しました。
GKEノードからGAEへのアクセスを許可しているのは、GKE上のPrefectエージェントからインターネット経由でApolloへアクセスするためです。(実行可能FlowのポーリングやFlow実行ステータスの連携に使います)
gcloud app firewall-rules update default --action=DENY
gcloud app firewall-rules create 1 --action=ALLOW --source-range='<GKEノード1のIPアドレス>/32'
gcloud app firewall-rules create 2 --action=ALLOW --source-range='<GKEノード2のIPアドレス>/32'
gcloud app firewall-rules create 3 --action=ALLOW --source-range='<GKEノード3のIPアドレス>/32'
gcloud app firewall-rules create 4 --action=ALLOW --source-range='<prefectコマンドを実行するホストのIPドレス>/32'
Prefectエージェントをk8sにデプロイします。
# Prefectエージェント用のマニフェストを生成する
$ prefect agent kubernetes install --api https://apollo-dot-my-prefect-lab.uc.r.appspot.com --service-account-name default --rbac > agent.yaml
# 生成されたagent.yamlのRoleのrules[0].resourcesにjobs/statusを追加してからapplyする。
$ kubectl apply -f agent.yaml
# Flow登録用のGCSバケットを作成する
$ gsutil mb gs://my-prefect-lab-flows
# Prefectにdefaultテナントを作成する
$ prefect server create-tenant --name default --slug default
以上でデプロイは完了となります。