Openpose
・Github: CMU-Perceptual-Computing-Lab/openpose
・Qiita: OpenPoseを動かしてみた。
普通のRGBカメラ画像からヒトのスケルトン推定を検出するアルゴリズム。
非商用ならfreeに利用可能。
デモ動画は既に色々と出回っているけれど、出力される数値データも眺めたい。
installの注意点
・ 公式ドキュメントOpenPose - Installation and FAQ
CUDA, cuDNN, OpenCVが必要。
特にCUDAを入れる時に注意が必要。
表玄関からUbuntuを選ぶと、CUDA9になってそもそも14.04には入らない。CUDA Toolkit Archiveから探します。NVIDIAドライバも表玄関から行ってUbuntu14.04を選ぶとnvidia384.90になるけどこれだとログインループになって手も足も出ない。結局手元の環境ではnvidia-375を入れ直したら大丈夫だった。あとnouveauを止めてGUIに入る必要があるので、基本言語を英語にしておかないとダウンロードに移動できなくて詰む。
以上、愚痴でした。
・ ubuntu14.04にcuda8.0をインストールする
・ UbuntuにCUDAを入れようとしたらハマった
サンプルデータ
綺麗なお姉さんのバレエの動作(ソロ)
Rアドカレ用サンプル動画https://t.co/V30s722et0
— kilometer (@kilometer00) 2017年12月17日
HELLGRAU (Teaser, 2016), AugenZeugeKunst, Youtube, CC BY 3.0
はい、綺麗。
骨格推定
インストールしてしまえばあとは簡単。
./build/examples/openpose/にあるopenpose.binを走らせる。
骨格推定デモ動画を見るには、
openpose.bin --video input.avi
手と顔も追跡した動画を見るには、
openpose.bin --video input.avi --face --hand
結果を動画に保存したければ、1
openpose.bin --video input.avi --write_video output.avi
結果を数値で取り出したければ、
openpose.bin --video input.avi --write_keypoint_json output/
フレームごとにjsonファイルがだーっと吐き出される。
出力ファイル名は、input_右詰12桁のframe番号_keypoints.jsonという形式。
別にRでやらなくてもいいけれど出力結果の解析
使ったパッケージ
library(jsonlite) # json形式ファイルの読み込み
library(stringr) # 文字処理用
library(tidyverse) # データ処理全般
library(magick) # 画像処理全般
前処理
最近、かの有名なパイハラ(Python使え使えハラスメント)のしわ寄せでRを打っていないのでストレス?解消にRで出力データを確認。2
手元では{jsonlite}というパッケージを使ってjsonを読み込んでいる。
dat <- fromJson("hoge.json")
> str(dat) # データ構造(structure)の確認
List of 2
$ version: num 1
$ people :'data.frame': 2 obs. of 4 variables: # ←ヒトは2人?
..$ pose_keypoints :List of 2
.. ..$ : num [1:54] 770.88 182.04 0.89 772.77 254.3 ...
.. ..$ : num [1:54] 461.75 234.76 0.43 467.64 291.59 ...
..$ face_keypoints :List of 2 # 今回はbodyだけなのでここは空っぽ
.. ..$ : list()
.. ..$ : list()
..$ hand_left_keypoints :List of 2 # 今回はbodyだけなのでここは空っぽ
.. ..$ : list()
.. ..$ : list()
..$ hand_right_keypoints:List of 2 # 今回はbodyだけなのでここは空っぽ
.. ..$ : list()
.. ..$ : list()
people=2っぽい。2人分の骨格が入っていそうだ。
54データですか。そうですか。1人あたり54?うーん。
 (公式fig)
(公式fig)
18点x3データですね。デカいデカい小さい、デカいデカい小さい、という繰り返しなので、1 keypointあたり[X座標, Y座標, 確率]の組み合わせだろうとアタリがつく。ソースたどって確かめてもいいけどユルフワなのでアタリをつけて画像に書き込んでみる方が早い。
とりあえず整形
# pose整形用関数を準備
shape_pose <- function(x){ # リスト各要素に以下を適用して
matrix(x, 18, 3, byrow = T) %>% # ・ 行列に整形(3列x18行)
data.frame() %>% # ・ data.frameに変換
rename(X = X1, Y = X2, prob = X3) %>% # ・ カラム名変更
mutate(pos = 1:nrow(.) -1)} # ・ 公式と同じポイント名をつける
# pose整形関数の適用
dat <- fromJson("hoge.json") %$% people %$% pose_keypoints %>% # 対象データの抽出
map_df(shape_pose) %>% # 抽出されたlist全てにshape_poseを適用
bindrows() %>%
mutate(pose = ifelse(pos == 0, 1, 0) %>% cumsum()) %>% # 骨格の番号カラムを作る
nest(-pose) # 骨格でネスト
出力はこうなる3
> dat
# A tibble: 2 x 2
pose data
<dbl> <list>
1 1 <tibble [18 x 4]>
2 2 <tibble [18 x 4]>
> str(dat)
'data.frame': 2 obs. of 4 variables:
$ pose : num 1 2
$ data :List of 2
..$ :'data.frame': 18 obs. of 4 variables:
.. ..$ X : num 769 773 726 657 589 ...
.. ..$ Y : num 182 254 250 270 280 ...
.. ..$ prob: num 0.897 0.888 0.836 0.849 0.797 ...
.. ..$ pos : num 0 1 2 3 4 5 6 7 8 9 ...
..$ :'data.frame': 18 obs. of 4 variables:
.. ..$ X : num 462 466 426 350 0 ...
.. ..$ Y : num 233 293 292 305 0 ...
.. ..$ prob: num 0.359 0.68 0.63 0.183 0 ...
.. ..$ pos : num 0 1 2 3 4 5 6 7 8 9 ...
dataカラムに収納されている情報はこんな感じ。
> dat$data[[2]]
# A tibble: 18 x 4
X Y prob pos
<dbl> <dbl> <dbl> <dbl>
1 461.771 232.800 0.3594960 0
2 465.682 293.461 0.6804240 1
3 426.468 291.566 0.6301710 2
4 350.221 305.281 0.1833150 3
5 0.000 0.000 0.0000000 4
6 508.757 293.507 0.6204490 5
7 0.000 0.000 0.0000000 6
8 0.000 0.000 0.0000000 7
9 444.112 444.132 0.4048150 8
10 0.000 0.000 0.0000000 9
11 0.000 0.000 0.0000000 10
12 506.657 442.167 0.4024210 11
13 510.664 530.215 0.0504986 12
14 0.000 0.000 0.0000000 13
15 453.945 224.951 0.3927820 14
16 473.430 223.037 0.4212350 15
17 444.035 230.880 0.3697570 16
18 489.129 227.041 0.4641870 17
取れていない点には0が入る。
骨格の特徴量を取り出したいときはこんな感じにする。
dat %>%
mutate(pointN = map_dbl(data, ~ sum(.$prob > 0))) %>% # 取れているpos数
mutate(meanP = map_dbl(data, ~ mean(.$prob[.$prob > 0]))) # 取れているposの平均prob
# A tibble: 2 x 4
pose data pointN meanP
<dbl> <list> <dbl> <dbl>
1 1 <tibble [18 x 4]> 18 0.8415053 # ←ちゃんと取れてそう
2 2 <tibble [18 x 4]> 12 0.4149625 # ←なんか怪しい
group_byからのdoを長く使っていたのだけど、nestからのmap4を勉強中です。
利点は、元の1次情報を保持し続ける事ができるという事だと思っています。
画像に書き込む
Rの画像ハンドル系パッケージは色々ある。
個人的には{EBImage}が好きだけどこれはBioconductor謹製という事もあり5、最近はCRANに上がっている{magick}にスイッチしようとしている。
まずffmpegでframeごとのpng画像を掃き出しておく。
で、パスを整理して、jsonに対応するpngを読み込む。
jsonファイル名は、input_右詰12桁のframe番号_keypoints.jsonという形式だった。
30frame/secなら10世紀分ぐらいの動画データならラベルに困らないはず。
pngファイル名はimage_右詰N桁のframe番号.pngだとすると(Nはffmpegの設定でいじれる)、こんな感じ。
dat_img <- str_split("hoge.json", "_")[[1]][2] %>% # frame番号だけ取り出す: 文字列
as.numeric() %>% # 数値に変換
formatC(width = N, flag = 0) %>% # N桁に整形しなおす
str_c(pass_png_fold, "image_", ., ".png") %>% # img側のパスを作る
image_read() # magick::image_read
{magick}では、画像を見るには普通にplotを使えばいい。
で、上から線や点を重ねるのを普通のplotと同じ要領でlinesやpointsで出来るのがイイ。
泣きながら map , pmapを使ったpose描画関数を作るとこんな感じ。
2重で回すからカオスってる。まぁ、関数分けろよって話ですね。
一応動く。
# 結ぶ点と色のdata.frameを用意
pose <- data.frame(p1 = c(0, 2, 5, 2, 5, 3, 7, 1, 1, 9, 9, 11, 13),
p2 = c(1, 1, 1, 3, 6, 4, 6, 8, 11, 8, 10, 12, 12),
col = c("pink", rep("red", 6), rep("blue", 2), rep("green", 4)),
stringsAsFactors = F)
# poseを書き込む関数を定義
ad_pose <- function(dat, dat_img, pose, lwd = 3){
img_h <- image_info(dat_img)$height # 画像の高さ
map(dat, function(dat){ # 骨格ごとのloop
dat_pos <- dat %>%
mutate(Y = img_h - Y) %>% # Y座標反転(原点の問題)
mutate_at(1:2, funs(ifelse(. == 0, NA, .))) # 取れてないposは描かない
# 入力されたposeデータフレームの指定要素に対して順に以下の操作で使う
pmap(pose, function(p1, p2, col){ # poseの行ごとloop
dat_pos %>%
filter(pos %in% c(p1, p2)) %>% # 該当2点を取り出す
select(X, Y) %>% # X,Yだけにする
lines(col = col, lwd = lwd) # 線を描く
}) # poseのloop終わり
points(dat_pos$X, dat_pos$Y) # 点も描こうか
}) # 骨格のloop終わり
invisible() # 返り値いらん
}
これを使って、
img_w <- image_info(dat_img)$width
img_h <- image_info(dat_img)$height
png("hoge.png", width = img_w * 2, height = img_h) # 作図デバイスを所定の解像度で開く
par(mar = rep(0.1, 4), mfrow = c(1,2)) # 余白と画面分割の指定
plot(dat_img) # 元の画像左
plot(dat_img) # 元の画像右
ad_pose(dat$data, dat_img, pose) # 書き込み
dev.off() # 作図デバイスを閉じる

はい、影も取ってる。
1人しか写っていない事が担保されているならprobabilityがmaxな骨格だけを選べばOKか。
そうでないなら、前frameからの位置変化量などからノイズ骨格を取り除く必要がありそうです。
ここでnest されていた元の座標情報がモノを言うはず。
ひとまず今回は、probがmaxなposeを抽出しておく。
dat_i <- dat %>%
mutate(meanP = map_dbl(data, ~ mean(.$prob[.$prob > 0]))) %>%
filter(meanP == max(meanP)) %$%
data %>%
data.frame() %>%
mutate(frame = i)
時系列データにする
得られた数値を時系列データにしたいわけですが、ただし、frameごとに独立のdetectionをしているので、frame(T)のpose群と、frame(T+1)のpose群の対応づけられるラベルが無い。
最近傍のposeを取るのがbetterでしょうか。画面上のpixel座標しかないので、ヒトが動いたのかカメラが動いたのかわからないという難点があります。シーンが切り替わるタイミングでもすっ飛びそうですね6。カメラアングルが固定ならそれなりにイケそうです。絶対座標系に依存しないパラメータとしては、関節の角度があります。
今回のサンプルでも、カメラアングルは色々と変わるので姿勢パラメータとして関節角度を抽出してみた。
nest() %>% mutate(hoge = map(data, function(dat){sin(hogehoge)})みたいな感じでsin/cosを抜き出して描画するとこんな感じ。7
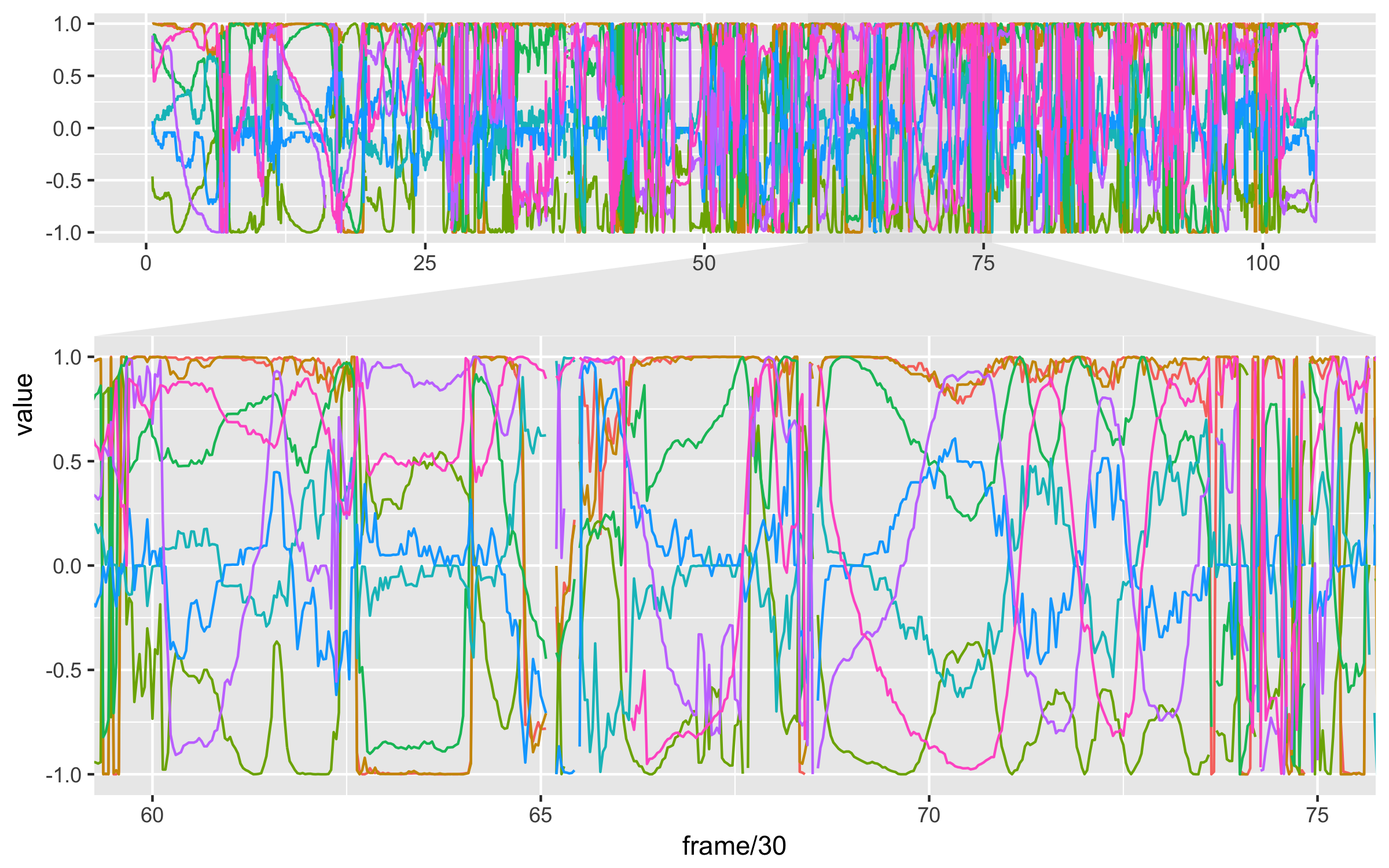
連続した動きの塊と、それを繋ぐ動作に分解できそうですね。
これはガウス過程案件でしょうか。
Rアドカレ用解析結果https://t.co/BweHpWuNBf
— kilometer (@kilometer00) 2017年12月17日
まとめ
・OpenPoseでモーショントラッキングを簡単実装。
・CUDA気をつけよう。
・Rで画像使うなら{magick}お勧め。
・まだmapは修行中。
手元の環境
OS: Ubuntu14.04
GPU: GeForce1080Ti NVIDIA 2枚
CUDA-8, cuDNN-7, R v3.4.0
使ったRの情報
> sessionInfo()
R version 3.4.0 (2017-04-21)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS 10.13.1
locale:
[1] ja_JP.UTF-8/ja_JP.UTF-8/ja_JP.UTF-8/C/ja_JP.UTF-8/ja_JP.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggforce_0.1.1 bindrcpp_0.2 magrittr_1.5 magick_1.2
[5] forcats_0.2.0 dplyr_0.7.4 purrr_0.2.4 readr_1.1.1
[9] tidyr_0.7.2 tibble_1.3.4 ggplot2_2.2.1 tidyverse_1.2.1
[13] stringr_1.2.0 jsonlite_1.5