今回はCNNの精度や汎化性能を向上するにはどうするかということで第二弾としてBatchNormaliztionについて書いていきます。
第一弾は下記を書きました。
Tensorflow・kerasで構築したCNNの性能改善を行ってみる(その1 Dropout)
前提/環境
前提となる環境とバージョンは下記となります。
・Anaconda3
・Python3.7.7
・pip 20.0
・TensorFlow 2.0.0
この記事ではJupyter Notebookでプログラムを進めていきます。コードの部分をJupyter Notebookにコピー&ペーストし実行することで同様の結果が得られるようにしています。
BatchNormaliztionとは
今回はBatchNormaliztionという手法についてです。BatchNormaliztionとは簡便に一言で表現すると各層に渡されるデータを平均0,分散1のする、標準正規分布に変換していまうことです。
CNNなどで層を深くすると学習が進まなくなるという問題があります、これは最初はデータにたいしてデータのスケールを合わせるなどの処理をしましたが途中の活性化関数を通っていくことでデータのスケールが崩れていきます。これらによりデータの型よりなどが勾配消失問題などにつながり学習が進まなくなっていくということが発生します。BatchNormaliztionは途中の段階でデータを正規化してしまうということで、問題を回避する手法となります。
BatchNormaliztionはデータのスケール変換などで勾配消失などの問題を回避するほかに、Dropoutとどうようにオーバーフィッティングに対する効果もあるといわれています。
BatchNomaliztionの実装
今回も第一弾と同様にCNNのベースのモデルに層を追加する方針とします。
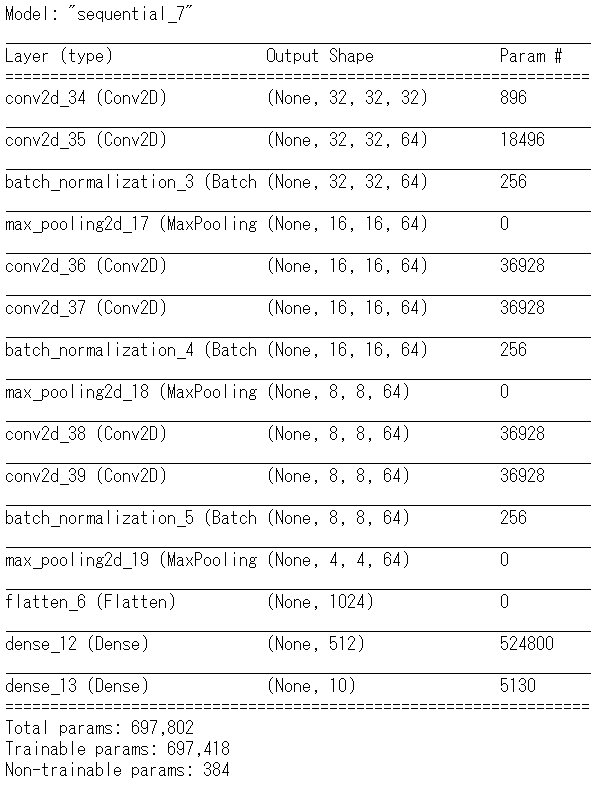
BatchNormaliztionを追加するときには下記のソースを記載します。
from tensorflow.keras.layers import BatchNormalization
model.add(BatchNormalization())
__注意__インポートの一文は最初のほうに記載すると2度目以降のBatchNormaliztionメソッド追加じに記載は必要ありません。
実際に10エポックを行ってみました。
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 400s 10ms/sample - loss: 1.3217 - accuracy: 0.5365 - val_loss: 1.4230 - val_accuracy: 0.5263
Epoch 2/10
40000/40000 [==============================] - 437s 11ms/sample - loss: 0.8555 - accuracy: 0.6988 - val_loss: 1.0776 - val_accuracy: 0.6246
Epoch 3/10
40000/40000 [==============================] - 494s 12ms/sample - loss: 0.6822 - accuracy: 0.7599 - val_loss: 1.1807 - val_accuracy: 0.6395
Epoch 4/10
40000/40000 [==============================] - 532s 13ms/sample - loss: 0.5515 - accuracy: 0.8064 - val_loss: 0.9556 - val_accuracy: 0.7014
Epoch 5/10
40000/40000 [==============================] - 544s 14ms/sample - loss: 0.4410 - accuracy: 0.8460 - val_loss: 0.9527 - val_accuracy: 0.7202
Epoch 6/10
40000/40000 [==============================] - 446s 11ms/sample - loss: 0.3327 - accuracy: 0.8841 - val_loss: 0.8538 - val_accuracy: 0.7412
Epoch 7/10
40000/40000 [==============================] - 486s 12ms/sample - loss: 0.2635 - accuracy: 0.9071 - val_loss: 0.8302 - val_accuracy: 0.7722
Epoch 8/10
40000/40000 [==============================] - 457s 11ms/sample - loss: 0.1935 - accuracy: 0.9317 - val_loss: 1.2839 - val_accuracy: 0.7080
Epoch 9/10
40000/40000 [==============================] - 462s 12ms/sample - loss: 0.1595 - accuracy: 0.9447 - val_loss: 0.9806 - val_accuracy: 0.7707
Epoch 10/10
40000/40000 [==============================] - 461s 12ms/sample - loss: 0.1380 - accuracy: 0.9506 - val_loss: 0.9174 - val_accuracy: 0.7790
Dropout、BatchNormaliztionなど対応していない場合に比べ、幾分accuracyは高まっているのと、オーバーフィッティングについても緩和されているように思えます。少ないエポック数でも効果が出ていると思います。
まとめ
Dropoutは必要がないという議論などもあるようですが、組み合わせたほうが効果がありそうです。実際に組み込んだうえで比較してみたいと思います。