この記事は前回までにCNNを構築して精度や分類までを行いました、そのCNNの精度や汎化性能を向上するにはどうするか?ということで書いていきます。
前回までの記事はこちら
Tensorflow・kerasでCNNを構築して画像分類してみる(概要編)
Tensorflow・kerasでCNNを構築して画像分類してみる(実装編1)
Tensorflow・kerasでCNNを構築して画像分類してみる(実装編2)
Tensorflow・kerasでCNNを構築して画像分類してみる(実装編3)
評価するCNNについて
前回までの記事から今回は層を付け足して下記のモデルで性能や対策の効果を確認していきたいと思います。下記の構造を持つモデルを利用します。
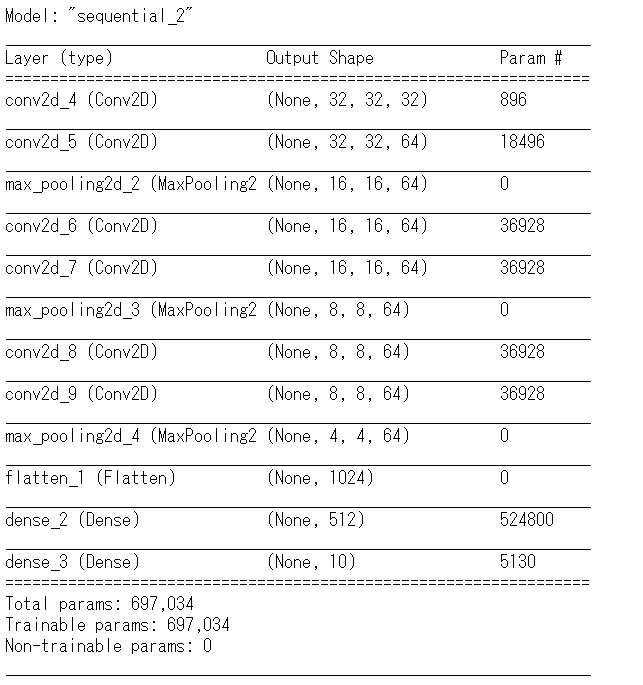
前回のモデルに畳み込み層を追加しました。畳み込み層とプーリング層が3セット重ねた構造のシンプルなモデルとします。
このモデルの評価
このモデルの訓練を行います。モデルの訓練のエポック数を10として実行しました。下記が結果となります。層を増やしエポック数を増加させて実行した結果、訓練データの正解率は9割となりましたが、訓練データの一部の検証データに対してはlossが高まり、精度も上がらずという状態となりました。
この結果としては訓練データに対して最適化が行き過ぎた状態といえます。、これを__オーバーフィッティング__といいます。正解率を上げるため訓練のエポック数を単純に増加させると、未知のデータに対する正解率などに影響がでることがわかります。
結果
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 285s 7ms/sample - loss: 0.5416 - accuracy: 0.8069 - val_loss: 0.8120 - val_accuracy: 0.7261
Epoch 2/10
40000/40000 [==============================] - 285s 7ms/sample - loss: 0.4540 - accuracy: 0.8394 - val_loss: 0.8334 - val_accuracy: 0.7397
Epoch 3/10
40000/40000 [==============================] - 286s 7ms/sample - loss: 0.3764 - accuracy: 0.8652 - val_loss: 0.8761 - val_accuracy: 0.7313
Epoch 4/10
40000/40000 [==============================] - 312s 8ms/sample - loss: 0.3063 - accuracy: 0.8921 - val_loss: 1.0356 - val_accuracy: 0.7279
Epoch 5/10
40000/40000 [==============================] - 314s 8ms/sample - loss: 0.2588 - accuracy: 0.9082 - val_loss: 1.0430 - val_accuracy: 0.7329
Epoch 6/10
40000/40000 [==============================] - 310s 8ms/sample - loss: 0.2227 - accuracy: 0.9213 - val_loss: 1.1775 - val_accuracy: 0.7270
Epoch 7/10
40000/40000 [==============================] - 309s 8ms/sample - loss: 0.1964 - accuracy: 0.9313 - val_loss: 1.2174 - val_accuracy: 0.7212
Epoch 8/10
40000/40000 [==============================] - 308s 8ms/sample - loss: 0.1739 - accuracy: 0.9402 - val_loss: 1.3176 - val_accuracy: 0.7268
Epoch 9/10
40000/40000 [==============================] - 304s 8ms/sample - loss: 0.1680 - accuracy: 0.9421 - val_loss: 1.3693 - val_accuracy: 0.7352
Epoch 10/10
40000/40000 [==============================] - 308s 8ms/sample - loss: 0.1643 - accuracy: 0.9433 - val_loss: 1.4427 - val_accuracy: 0.7305
上記のモデルの性能を評価した結果はこちらです。大体7割というところです。
Test accuracy: 0.7213
このモデルでエポック数を増加させて精度向上をしていくことを考えると、オーバーフィッティングに対する対策が必要となります。
CNNのオーバーフィッティング対策
オーバーフィッティング対策としてDropoutという手法を用います。Dropoutは訓練データに対する過剰な適応を防ぐ手法です。ニューラルネットワークのニューロンの一部をランダムに除外することで、訓練中のニューラルネットワークの形を変形させ毎回異なるニューラルネットワークで訓練を進めます。そうすることでランダムに異なるパラメーターで学習を進めることになります。
今回はDropoutの手法を組み込んで効果を確認したいと思います。
モデルの改良(Dropoutの追加)
モデルの途中にDropout処理を追加します。今回は畳み込み層の後に追加する形とします。
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.25))
Dropout処理を追加した後のモデル構造は下記となります。
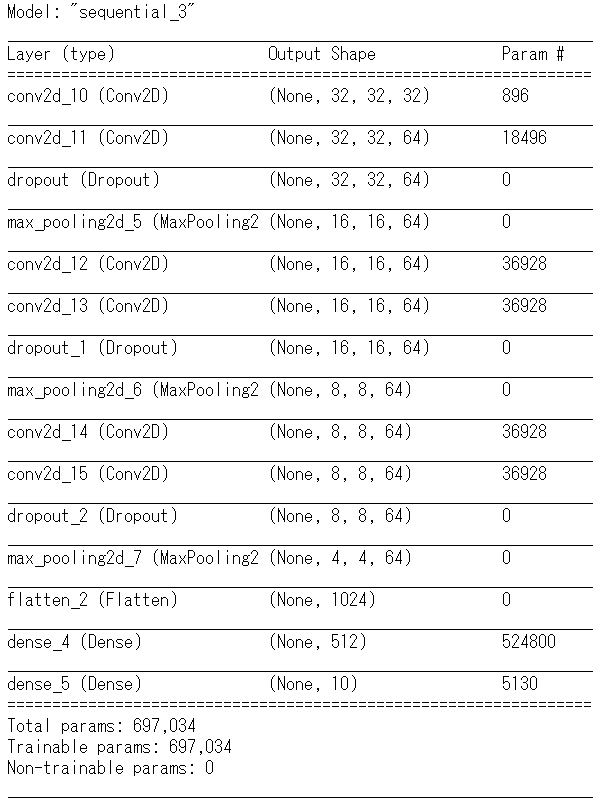
上記のモデルで訓練を行ってみます。条件はモデルにDropout処理を追加した以外には変更していません。
結果
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 359s 9ms/sample - loss: 1.5391 - accuracy: 0.4377 - val_loss: 1.2259 - val_accuracy: 0.5686
Epoch 2/10
40000/40000 [==============================] - 375s 9ms/sample - loss: 1.0496 - accuracy: 0.6260 - val_loss: 1.0295 - val_accuracy: 0.6498
Epoch 3/10
40000/40000 [==============================] - 375s 9ms/sample - loss: 0.8598 - accuracy: 0.6946 - val_loss: 0.9309 - val_accuracy: 0.6763
Epoch 4/10
40000/40000 [==============================] - 385s 10ms/sample - loss: 0.7430 - accuracy: 0.7373 - val_loss: 0.8399 - val_accuracy: 0.7102
Epoch 5/10
40000/40000 [==============================] - 370s 9ms/sample - loss: 0.6615 - accuracy: 0.7676 - val_loss: 0.7734 - val_accuracy: 0.7318
Epoch 6/10
40000/40000 [==============================] - 432s 11ms/sample - loss: 0.5928 - accuracy: 0.7927 - val_loss: 0.7355 - val_accuracy: 0.7466
Epoch 7/10
40000/40000 [==============================] - 362s 9ms/sample - loss: 0.5348 - accuracy: 0.8090 - val_loss: 0.7495 - val_accuracy: 0.7408
Epoch 8/10
40000/40000 [==============================] - 365s 9ms/sample - loss: 0.4895 - accuracy: 0.8242 - val_loss: 0.7240 - val_accuracy: 0.7525
Epoch 9/10
40000/40000 [==============================] - 374s 9ms/sample - loss: 0.4421 - accuracy: 0.8439 - val_loss: 0.7101 - val_accuracy: 0.7555
Epoch 10/10
40000/40000 [==============================] - 370s 9ms/sample - loss: 0.4197 - accuracy: 0.8529 - val_loss: 0.6981 - val_accuracy: 0.7560
上記の結果を見るとlossとaccuracyについては訓練の進み方が緩やかになっているものの、val_loss、val_accuracyについては改善がみられます。特にval_lossについてはDropoutのない状態に比べると改善されており、val_accuracyについても着実に正解率が向上しています。
テストデータに対する正解率評価を見ます。
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('\nTest accuracy:', test_acc)
結果
Test accuracy: 0.7535
テストデータでの正解率に対しても、0.7213から若干ですが向上が見られます。少ないエポック数での数値に改善がみられているということで効果が見えました。
数値毎を見ると大きな向上はないものの、__オーバーフィッティングに対する効果があると考えられます。一番大きな効果はエポック数を増やしてもオーバーフィッティングとなることを抑えることができる(エポック数数を増やして正解率をあげられる余地ができた)ということ__です。
まとめ
少ないエポック数ではあるのですが、オーバーフィッティングに対してDropoutの効果はあると思います。