本記事はFringe81アドベントカレンダー2018の17日目の投稿です。
データ量多くても変わらないコードで実行できる分散型データ処理を追い求めてScioに行き着きました。
前回に続き手軽に実行できるScioでのデータ処理について書きます!
Scioとは?
ScioはApacheBeamおよびDataflowのScala版APIです。
音楽配信サービスで有名なSpotifyが主導で開発しています。
付加機能が充実していて本家のJava版より簡潔に実装、実行できるためオススメです。
REPLは手元で手軽に書けて、直ぐにリモートDataflow実行も出来るのでお手軽にデータ処理を書くために使えます。
作るモノ
BigQueryの一般公開データセットとしてアクセスできる
StackOverflowの質問データ(タイトル)に対し、word-countを実行して情報を付加して新規tableへ書き出す処理をGCPのDataflowでフル実行します。
コードは基本的に前回と同じものを使うので解説は前回記事を参考にしていただければと思います。
リモート実行用の変更については後ほど解説します。
Scio-REPLのススメ!
Scio-REPLは手元で軽い処理をサッと書くのに使い勝手が良いです。
手元PCでのローカル実行とGCPでのリモート実行も簡単に切り替えられます。
バッチの必要なく一回だけ実行して済むような処理はScio-REPLで作ってしまうのが早いです!
リモートモードで起動
java -jar scio-repl-0.5.6.jar --project=[project-id] --stagingLocation=gs://[gcs上のtmpディレクトリ指定] --runner=DataflowRunner
実行するコード
リモート実行する場合は、
sc:(ScioContext)の文脈上で処理する必要があります。そのため、「sc.close」も必要です。
@BigQueryType.fromQuery("SELECT id,title,0 AS wordcount FROM `bigquery-public-data.stackoverflow.posts_questions`")
class Row
sc.typedBigQuery[Row]().map(r => Row(r.id, r.title, r.title.map(_.split("[^a-zA-Z']+").length))).saveAsTypedBigQuery("[project-id]:out.wcquestions")
sc.close
実行
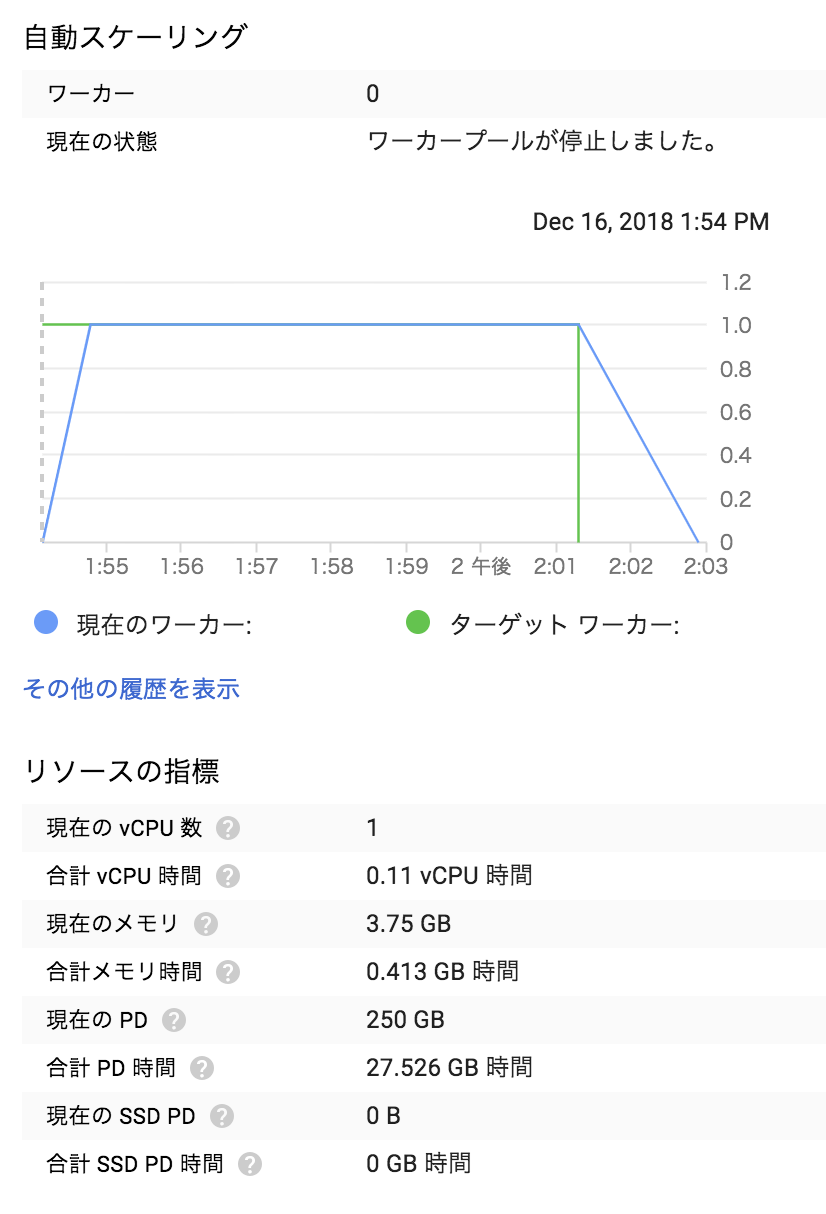
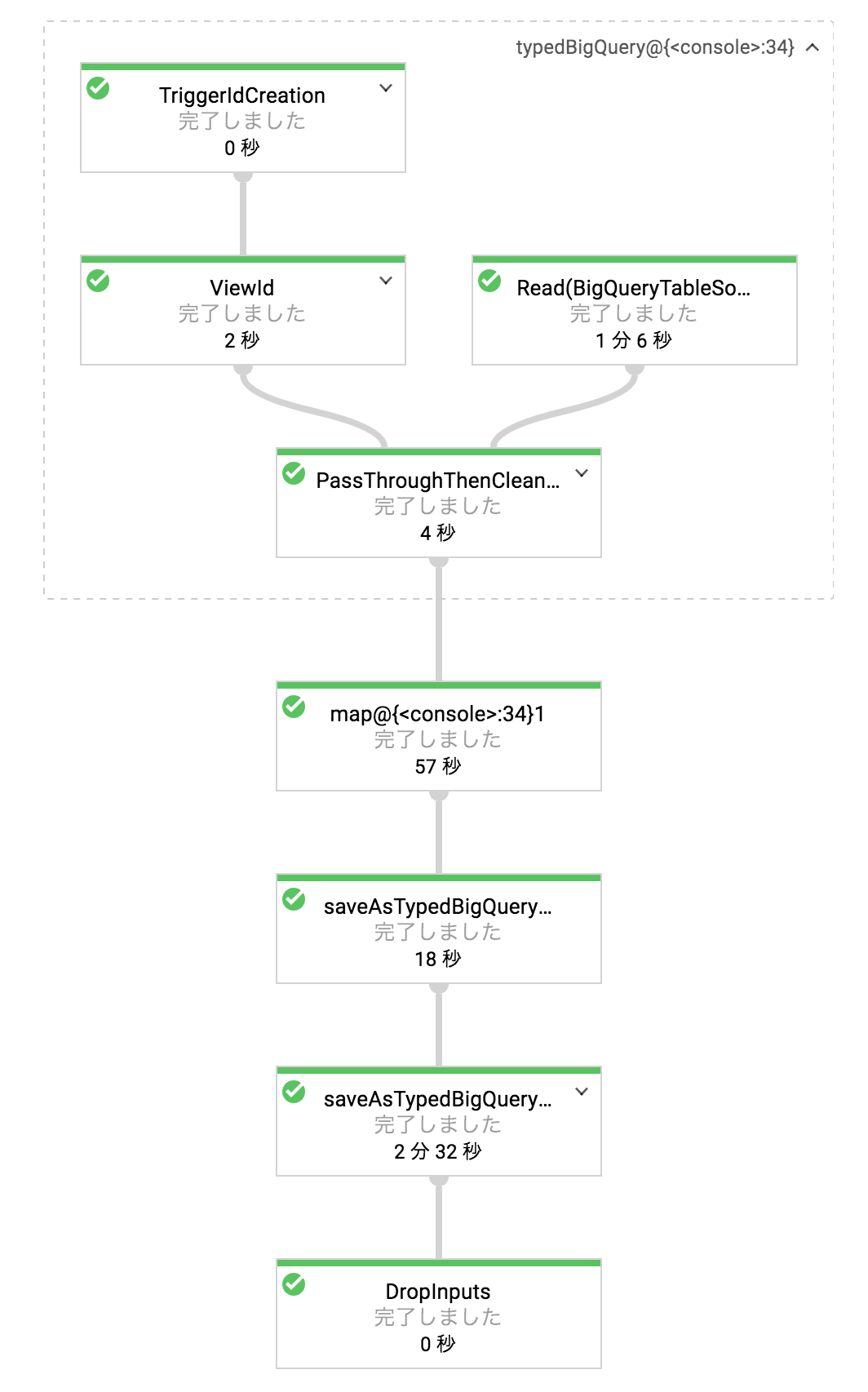
stackoverflowのパブリックデータ:bigquery-public-data:stackoverflow.posts_questions、1,600万件(約25GB)分をリモート実行した結果です。(ローカル実行しようとするとtimeout等で実行厳しい量です...)
全処理が約9分で終わりました。
Scio-REPLの使いところについて
25GB、1600万件のデータ処理というローカルで実行するにはチト厳しいデータ処理をサクッと実行できました。
調査やレポート作成などでバッチ化するまでもないけど重めのデータ処理をする必要がある場合に、ちょうどいい実行環境と思います。
課題
ワーカーノードがスケールせず1台で処理完了してしまいました。
もう少し工夫すればもっと効率的にスケールできると思うので、この点に関してのは引き続き調べて行きたいと思います。