ディープラーニングの性能向上方法
ディープラーニングは、データへのアノテーション(ラベル付け)作業が大変ですね。ディープラーニングの性能向上を少ないデータのアノテーションで実現するための手法は多くあります。この記事では、それらを自分なりにまとめます。
性能向上手法の一覧
手法は、以下です(随時追加していきます)。大きく分けると、データを拡張する方法と、教師無し(アノテーションされてないラベルのないデータ)を活用する方法と、教師有りデータを生成する手法の3つがあるのではないかと思います(ここの分類はちょっと自信ないです…手法の分類で変なところありましたら、コメントなどいただけると助かります)。
データ拡張
- データ水増し(Data Augmentation)
教師無しデータ活用
- 転移学習(ファインチューニング)
- 能動学習
- 半教師あり学習
- 自己教師あり学習
- 弱教師あり学習
教師有りデータ生成
- シミュレータ使用
- 見えないマーカーを使用
順に説明していきます。
データ拡張
データ拡張に関しては、データ水増し(Data Augmentation)に全てまとめました。水増しといっても、画像を反転させる Flip、ノイズを混ぜる手法、一部をマスクするCut Outや、一部にランダムなノイズを加えるRandom Erasing、複数の画像を混ぜ合わせる Mixup、水増ししたデータを混ぜ合わせるAugMixなど、様々な手法があります。
以下の図が一番よくまとまっていると思います。
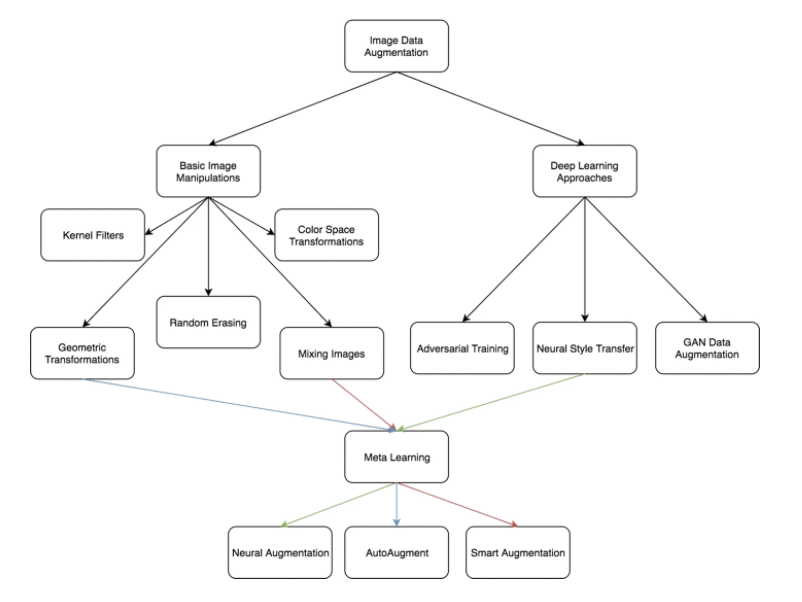
データ拡張: 機械学習向けの画像データセットを10倍に水増しする方法より引用
また、画像ではよく使われる左右反転でも、自然言語だと画像のように左右反転させると全く意味が変わってしまうケースがあったりと、使用される領域(ドメイン)によっても、手法を注意して選ぶ必要があります。
具体的にどのような画像の操作をするかの一例と、実際の処理方法に関しては、以下記事参照ください。
TensorFlowのObject Detection APIのData Augmentationで何をやっているか動かして確認
PyTorchでデータ水増し(Data Augmentation)する方法
データ水増し手法の補足情報
以下は、各手法の補足です。
敵対的生成ネットワーク(GAN)
GANにより生成した画像を、教師データとして使うケース
Pre-training without Natural Images
Data Augmentationとは違う区分けになるのかもしれませんが、数式から生成した画像を教師データとして使い、特徴量抽出部の事前学習をする試みです。教師データの画像の著作権の問題を回避するのが目的の1つのようです。
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty
AugMixの論文
教師無しデータ活用
教師の無いデータを活用する手法です。基本的には、教師有りのデータが別にある前提となります。ここでポイントは、教師ありのデータが対象のデータとは別のドメインのものでも構わないことですね。すでに世の中に大量にある教師ありデータ(データセット)を使うことで、追加でのアノテーション作業を極力少なくしようというのが基本的なコンセプトです。
この手法は、色々あって、若干混沌としているようにも見えましたが、個人的によくまとまっていると感じた図を2つ挙げます。
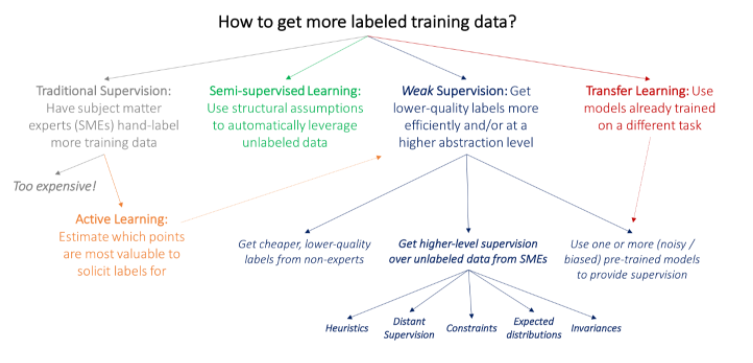
Weak Supervision: A New Programming Paradigm for Machine Learningより引用
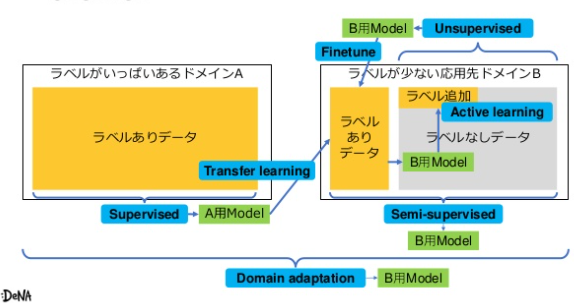
Semi supervised, weakly-supervised, unsupervised, and active learningより引用
初見だと、余計に分けが分からないかもしれませんが、一つづつ意味を理解すると、この図がだんだん凄く見えてきます(多分)。
転移学習(ファインチューニング)
学習済のモデルをベースに、再学習させる方法です。最終層だけを付け替えて、その前段の層のパラメータは学習させない場合を転移学習と呼びます。
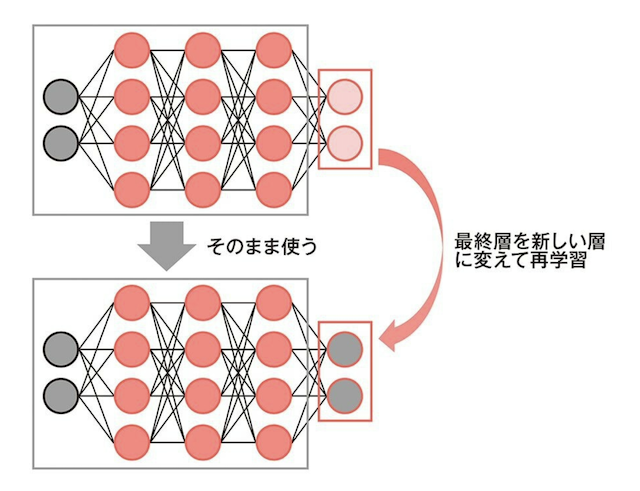
「からあげ先生のとにかく楽しいAI自作教室」より引用
前段の特徴量抽出層のパラメータまで再学習させる場合をファインチューニングと呼びます。区別しないで使っている人も結構います。
能動学習
教師あり(アノテーション済み)、教師無し(アノテーショなし)の両方のデータがあった場合、教師無しのデータから、学習に効果的なデータを選んで追加でアノテーションする方法です。ディープラーニングより、SVMでイメージした方が分かりやすいと思います。
以下のような分類の場合、境界線上にあるデータを多くアノテーションして学習させるのが重要なことが直感的に分かります(逆に、境界から遠いデータをたくさん学習させても効果はなさそうです)。
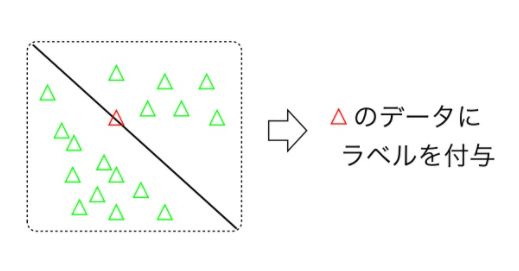
能動学習セミナーのスライドより引用
半教師あり学習
教師あり学習と教師無し学習の中間みたいな方法です。教師無しのデータをうまく活用して、性能をあげる方法です。能動学習との違いが分かりづらいですが、人に対して「このデータをアノテーションして」と提案するのが能動学習、そういった提案せず、与えられたデータでうまいことやろうとするのが、半教師あり学習のようです。
ポイントポイントで確認してくれるけど、ちょっとうっとおしい良い子ちゃんが能動学習・いい感じにやってくれるけど、ほっとくとやばい方向に突き進むモーレツタイプが半教師あり学習とイメージすると良いかもしれません。
たくさん手法があるようです。以下関連情報です。
半教師あり学習のこれまでとこれから
半教師あり学習に関してまとまった記事です
半教師付き学習(Google Colab Notebook)
「Consistency Regularization」という手法のGoogle Colabでの実践例です。
自己教師あり学習
教師の無いラベルに対して、擬似的なラベルをつける(勝手にアノテーションする)のが、自己教師あり学習です。半教師あり学習の1手法という位置付けと理解しましたが、注目されているようなので項目分てみました。以下参考記事です。
自己教師学習(Self-Supervised Learning)
自己教師付き学習(Google Colab Notebook)
A Simple Framework for Contrastive Learning of Visual Representations
脱・人力アノテーション!自己教師あり学習による事前学習手法と自動運転への応用
弱教師あり学習
教師データがあまり信頼できないできないケースでの学習をさすようです。教師データを作った人がいいかげんだったとか、何らかの理由で間違いが含まれていそうとか、そういうときでも以下に性能をあげるかという、結構泥臭い問題設定のようです。弱い教師信号ということで、弱教師あり学習とよぶそうです。昼間から酒飲んでアノテーションしてるやばい教師を想像すると覚えやすいかもしれません。
さまざまな手法があるようです。詳細は割愛します。以下参考になりそうなリンクを列挙します。
Weak Supervision: A New Programming Paradigm for Machine Learning
A brief introduction to weakly supervised learning
Weakly supervised object detection(WSOD) Slide(CVPR 2018)
Weakly Supervised Object Detection
EM-DD : An Improved Multiple-Instance Learning Technique(日本語解説)
教師ありデータ生成
「教師ありデータが無いならつくっちゃえばいいじゃないの!」というマリー・アントワネット的発想(?)です。
シミュレータ使用
シミュレータをつくってしまい、そこから教師データを作る方法です。以下のようなイメージですね

Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real Worldより引用
この手法であれば、ピクセル単位でアノテーションが必要なセマンティックセグメンテーションでも恐るに足らずです。ただ、シミュレータを作るコストが大きすぎるので、トータルで楽になるかは謎です。また、シミュレータと実世界のギャップという大きな問題もあります。
このギャップを埋める技術は「Domain Randomization」などの手法が研究されています。
論文読み:Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
私もUnityで教師データ生成にチャレンジしてみました。以下記事参照ください。
見えないマーカーを使用
人間の眼には見えない、特殊な光でのみ反応するマーカーをつけてアノテーションデータを取得するという斬新な手法です。

不可視マーカー(Invisible marker)を用いたセグメンテーションマスクの自動アノテーション手法より引用
特殊なマーカーとライトという機材は必要なものの、シミュレータを作るよりは楽にアノテーションができそうです。斬新な発想です。日本のAIベンチャーの雄、Preferred Networksの研究です。
まとめ
少ないアノテーションコストでディープラーニングの性能を上げる方法を自分なりにまとめてみました。たくさんありますし、まだまだ増えそうですね。自分が実際に使ったことあるのは、データ水増しと転移学習くらいでしょうか。現実的な環境だと、まずは安定させるといった地味な方法も重要です。参考:ディープラーニングの画像認識性能向上のための泥臭いテクニック。
そのうち、これらの手法も、全部ニューラルネットワークのモデルに組み込まれて、あんまり考えなくて良くなるのかなと思う一方で、ドメイン(領域)ごとに必要な前処理が異なる点もあるので、よほど大きなブレイクスルーがなければ、当分はこういった技術を目的に合わせて使い分ける必要があるかもしれないなと感じたりしています。
宣伝「からあげ先生のとにかく楽しいAI自作教室」
AIの初心者向け本「からあげ先生のとにかく楽しいAI自作教室」を執筆しました。Google Colaboratoryを使って、実際に動かしながらAIを学べる本になっています。
ディープラーニングのモデルを1からつくって、この記事で紹介した中で代表的な手法(データ水増し、転移学習)を実際に実践して試すような内容もありますので、よろしければ是非。以下、本の紹介記事へのリンクです。
AI初心者向けの独学本「からあげ先生のとにかく楽しいAI自作教室」を執筆しました
変更履歴
- 2021/05/03 Unityでの教師データ生成に関して追記