概要
TOPPERS/箱庭では、様々なロボットがありますが、これらのロボットを強化学習できる環境を準備しました。
Python使って、Unity上のロボットの強化学習で試してみたいと思われる方にはお役に立てる環境と思います!
ちなみに、PythonからChatGPTのAPI使って、箱庭ロボットを動かすこともできます。
ロボットの種類
箱庭で利用できるロボットとしては以下があります。
- 荷物運搬ロボット
- ETロボコン競技用ロボット(HackEV)
- EV3 ベースの電車モデル
- EV3 ベースの信号モデル
- TurtleBot3
- TurtleBot3 Burger
- TurtleBot3 waffle
- ドローンモデル
荷物運搬ロボット

本記事で、強化学習用に用意したもので、利用可能です。
ETロボコン競技用ロボット(HackEV)

ET ロボコン競技用ロボットと同じモデルです。荷物運搬ロボットと同じ通信インタフェースですので、強化学習可能です。
EV3 ベースの電車・信号モデル
こちらは、電車のレール上を走るロボットと信号用のロボットです。通信インタフェースはEV3ベースですので、これまでのものと同じです。
電車モデル

信号モデル

TurtleBot3
ROSで制御するロボットとして有名なロボットです。
通信インタフェースはROS2ベースです。
こちらのロボットになると、カメラデータやレーザスキャナがついているので、強化学習の対象の幅が広がりそうです。
解説記事はこちら。
TurtleBot3 Burger

TurtleBot3 Waffle

ドローンモデル
こちらは、簡単なドローンのモデルです。
前提とする環境
現時点では、以下の環境を想定しております。
Unity
- Unity Hub
- Unity Hub 3.4.1
- Unity
- Unity 2021.3.7f1
-
Blender
- Blender v2.9.3以降
なお、Unityおよび Unity Hub, Blender はインストールされていることを前提として解説します。
Windows環境
- Windows10 Home, Windows 11
- WSL2/WSLg/Ubuntu20.0.4
- WSL2/Docker Engine
Mac環境
- Intel系 Mac:対応済み
- Arm系 Mac:対応済み
- Python:v3.10
Linux環境
- Ubuntu: 対応済み
- 導入手順はこちらです!
箱庭強化学習アーキテクチャ
箱庭上での強化学習のアーキテクチャは下図の通りです。
エージェント側をPythonプログラムで作成して、ロボットを強化学習します。
環境側は、「箱庭環境」です。箱庭環境に対して、エージェントが[アクション]を実行すると、アクション実行した結果として、[観測]と[報酬]が返ります。

このオペレーションを繰り返すことで強化学習ができます。なお、エージェント側と箱庭環境は、シミュレーション時間同期をしていますので、ここで学習したプログラムを実機ロボット用の開発言語(C言語等)に変換すれば、タイミングレベルでの精度が保証された学習済みプログラムを実機ロボットに適用できます(はずです)。
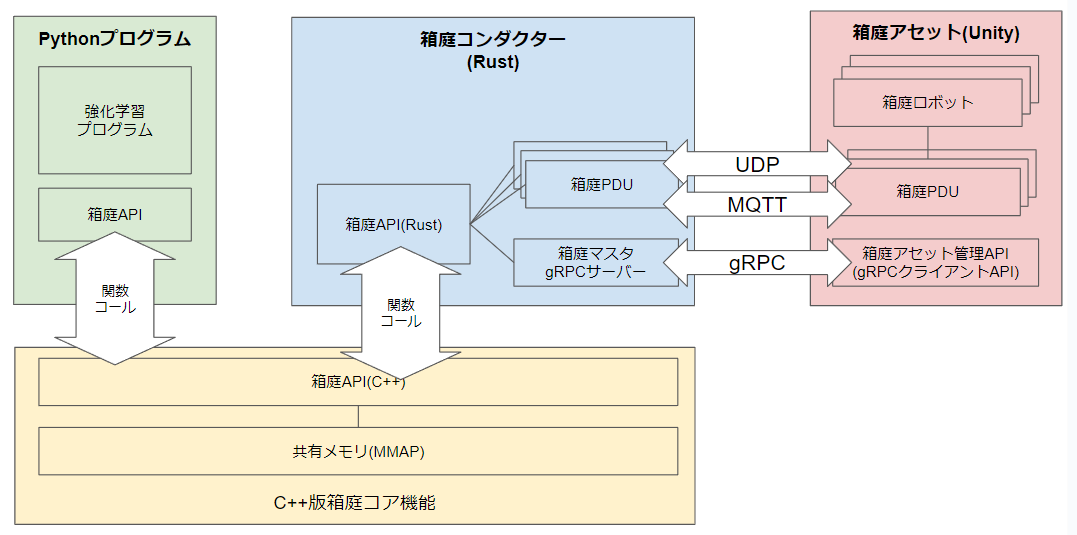
Windows版の実装レベルのアーキテクチャは下図の通りです。
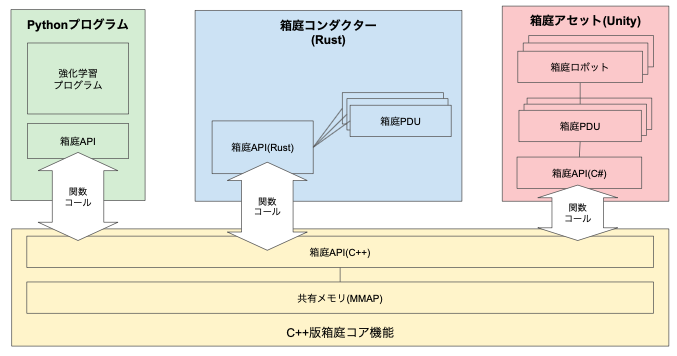
Mac/Linux版のアーキテクチャは下図の通りです。
以下、各コンポーネントの役割です。
- Pythonプログラム
- 強化学習用のプログラムです
- 箱庭コンダクター
- 箱庭アセット管理および箱庭アセット間のプロキシ通信を行います
- Windows版では、Unityと箱庭コンダクターは UDP/gRPC 通信で接続していますが、
- Linux/Mac版では、箱庭コア機能と関数コールさせることで通信オーバーヘッドを低減させています。
- 箱庭アセット(Unity)
- Unity上のロボットのシミュレーションを実現します
- Unity上のロボット配置やロボット周辺環境をUnity機能を利用して自由に変更できます
インストール手順
OS 毎に若干インストール手順が異なりますので、以下をご参照ください。
Windows の方向け
Mac の方向け
箱庭環境
さて、ここからUnity上で実現している箱庭環境の説明をします。
まず、Unity上のロボットは下図のものです。
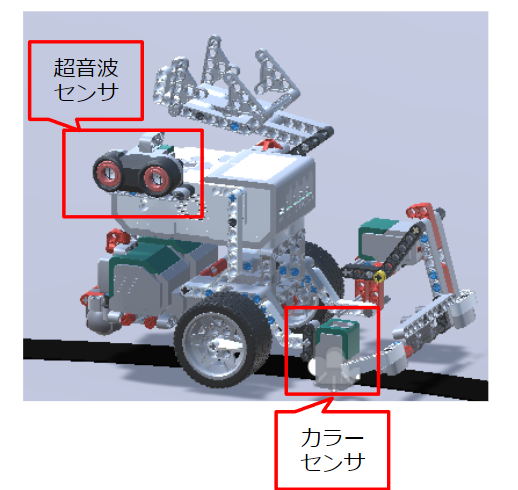
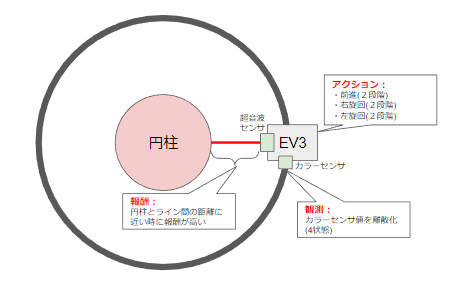
今回の強化学習用のサンプルとして利用するセンサは以下の2個にしています。
- 超音波センサ
- 中央の円柱との距離を計測するために利用します。
- ここで計測された値をもとにして、報酬計算します。
- ライントレース上近くにロボットが走っている場合に最大の報酬になるようにします。
- カラーセンサ
- ライントレース用のセンサです。
- カラーセンサの値は連続値で0~100の値をとります。
- 白色に近いと 0 の値を返し、黒色だと 100 の値を返します。
また、ロボットを移動させるために、モーターを使います。
モーター操作としては、簡略化して以下のオペレーションを用意することにしました。
- 前に進む(スピードは2段階程度)
- 右に曲がる(スピードは2段階程度)
- 左に曲がる(スピードは2段階程度)
強化学習プログラム
強化学習用のサンプルプログラムを以下に用意しました。
強化学習としては、Qテーブルを利用しています(以下、参考にした情報です)。
サンプルプログラム(ai_qtable.py)の骨子部分は以下のもので、学習モデル(model変数)を別の学習アルゴリズムに変更すれば、箱庭環境上で様々なアルゴリズムをお試しすることができると思います。
- 2023/01/29 午後
- QテーブルをCSVファイルとして保存する機能を追加しました
- また、起動時にQテーブルファイルがあった場合は、ロードする機能も追加しました
- ※学習したモデルを保存しておきたくなりました
#get ai model
model = qtable_model2.get_model(env.robo().num_states(), env.robo().num_actions())
model.load('./dev/ai/qtable_model.csv')
#do simulation
robo = env.robo()
for episode in range(100):
total_time = 0
done = False
state = 0
total_reward = 0
while not done and total_time < 4000:
action = model.get_action(state)
next_state, reward, done, _ = env.step(action)
total_reward = total_reward + reward
model.learn(state, action, reward, next_state)
state = next_state
total_time = total_time + 1
env.reset()
model.save('./dev/ai/qtable_model.csv')
print("episode=" + str(episode) + " total_time=" + str(total_time) + " total_reward=" + str(total_reward))
なお、「報酬」、「観測」、「アクション」を変更したい場合は、以下のプログラムを編集してください。
- 報酬
- reward()
- 超音波センサの計測結果から報酬を計算します
- 超音波センサは、0~255の値を返します。
- ライントレース上にロボットがいる場合は、120くらいの値になります。
- reward()
- 観測
- state()
- 観測した状態を返します
- num_states()
- 観測状態数を返します
- state()
- アクション
- action()
- ロボットのモーター操作を実行します
- num_actions()
- アクション数を返します
- action()
強化学習の実行手順
OS 毎に実ル手順が異なりますので、以下をご参照ください。
Windows の方向け
Mac の方向け
デモ
以下、デモです。
荷物運搬ロボット
学習中の状態
学習済み状態
HackEV
こちらは、報酬をカラーセンサにして強化学習させたものです。
hako_robomodel_ev3.py の変更点は以下の2関数です。
def rewaord(self, obserbation):
o = obserbation[1]['color_sensors'][0]['reflect']
min = 00.0
size = 100.0
#0 -1
ret_o = (o - min) / size
if ret_o <= 0.5:
return 10 * (1 - ret_o), False
else:
self.out_count = self.out_count + 1
if self.out_count < 300:
return -1, False
else:
self.out_count = 0
return -10, True
def state(self, obserbation):
o = obserbation[1]['color_sensors'][0]['reflect']
min = 0.0
size = 100.0
#0 -1
ret_o = (o - min) / size
#print("ret_o=" + str(ret_o))
return (int)((ret_o * 30.0) / 10.0)
トラブルシューティング
Windows の方向け
Mac の方向け